







简介
ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的用于在线分析处理查询(OLAP :Online Analytical Processing)MPP架构的列式存储数据库(DBMS:Database Management System),能够使用 SQL 查询实时生成分析数据报告。ClickHouse的全称是Click Stream,Data WareHouse。
何为MPP架构
MPP (Massively Parallel Processing),即大规模并行处理,随着大数据时代的到来,和传统数仓的发展,hive和spark在数据加工和分析场景中被大量应用,但是由于他们的响应速度不是很快所以只适合做离线数据分析。此时clickhouse应运而生。
clickhouse核心
多主架构,MPP架构
- 多主架构
clickhouse集群采用多主架构,既每个节点都可以当做主节点来使用,这种架构使得ck的使用更加灵活,同时也解决了单点问题,即使单个分片内互为备份的两个节点,都可以同时向外提供服务,而且所有节点没有明确的主次之分,功能相同。 - MPP
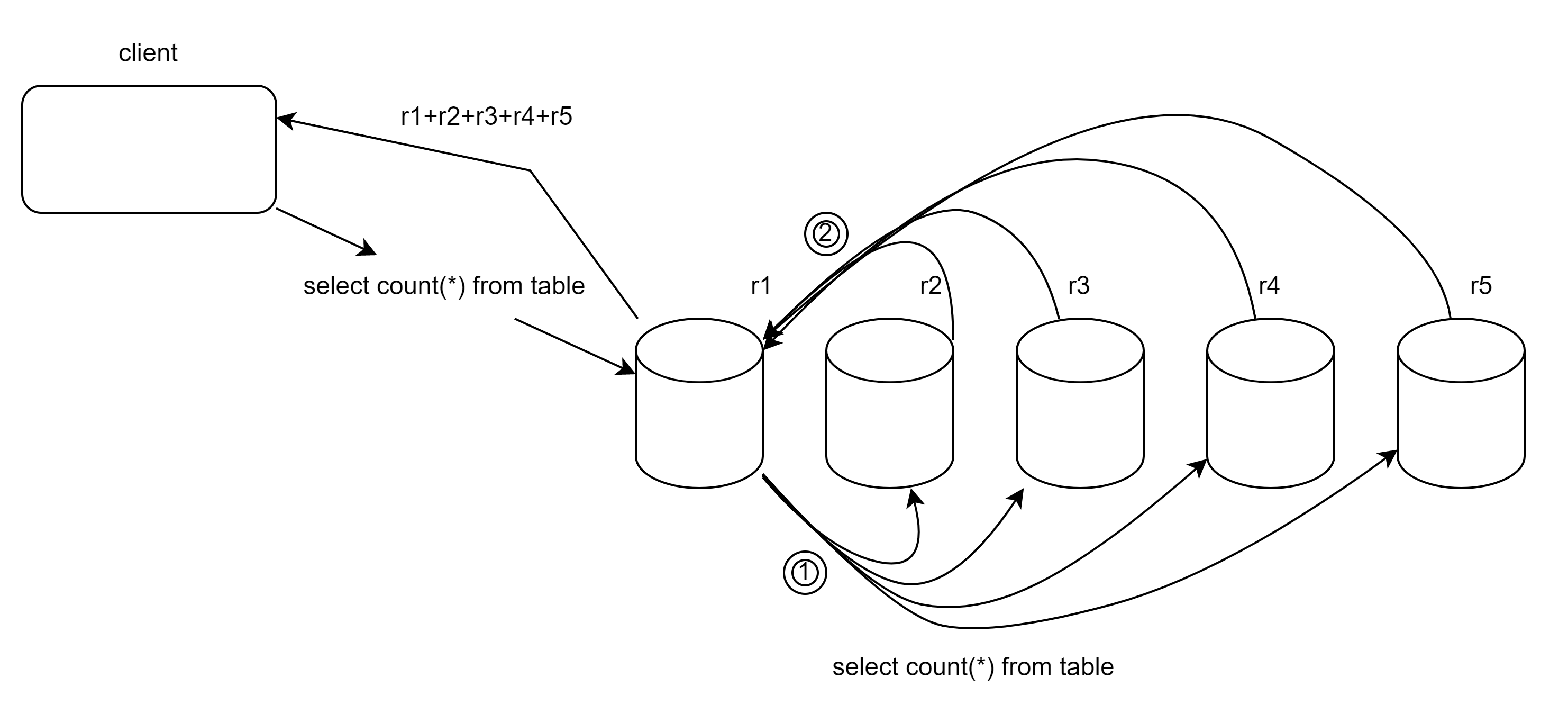
MPP即大规模并行处理,比如10个分片单节点的ck集群,在其中的一个节点提交一个聚合查询,他会首先对查询做差分,然后把他们分发到其他的9个分片节点上,各分片节点并行处理,最后结果统一汇报给master节点,master汇集结果后返回给client。这样分担了节点的压力,是数据分析更高效,同时又能做到无限的扩展,只要有钱!
列示存储
作为为数据计算,数据分析而生的数据库,ck采用列示存储,因为大数据分析场景下,更多的数据分析是需要全表扫描,这样就体现了列示存储的优势,是需要扫描所依赖的那一列数据,解决掉额外的能耗。
表引擎
ck支持丰富的表引擎如:MergeTree系列引擎,内存类引擎,外部存储类引擎等等,每种引起都由自己适合的数据分析场景,后面会抽出一个章节专门讲ck表引擎的场景选择。
数据分片与分布式查询
ck数据可以按照指定的方式进行分片,如果使用随机函数rand()进行分片,他会随机的把每条数据分布到不同的节点上,如果使用Hash函数对某一列进行分片,比如客户号,他会对客户号进行hash计算,根据得到的hash进行分片,更直白一些也就是相同客户号的数据会被分配到同一个节点。
分布式查询也就是上面所讲到的,把一条任务分发到所有的节点上,并行运算再统一汇总,最后返回client.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









