






SpringCloudAlibaba学习
Nacos学习
Naming Configuration 前两个字母, Service
是什么?
- 一个更易于构建云原生应用的动态服务发现,配置管理和服务管理中心
- Dynamic Naming and Configuration Service
- Nacos就是注册中心+配置中心的组合 Eureka+Config+Bus
能干吗?
- 替代Eureka做服务注册中心
- 替代Config做服务配置中心
去哪下?
各种注册中心比较
| 服务注册与发现框架 | CAP模型 | 控制台管理 | 社区活跃度 |
|---|---|---|---|
| Eureka | AP | 支持 | 低 |
| Zookeeper | CP | 不支持 | 中 |
| Consul | CP | 支持 | 高 |
| Nacos | AP | yes | high |
安装并允许Nacos
- 本地Jdk 8 + Maven环境
- 从官网去下载 https://github.com/alibaba/Nacos
- 在windows环境下,解压安装包,直接允许bin目录下的 startup.cmd
- 运行成功之后直接访问 http://localhost:8848/nacos 就可以看到
基于Nacos的服务提供者
- 新建一个项目,由于这个是一个微服务,所以我们可以创建一个父项目来进行统一的版本管理
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu</groupId>
<artifactId>cloud2021</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>cloudalibaba-provider-payment9001</module>
<module>cloudalibaba-provider-payment9002</module>
<module>cloudalibaba-consumer-nacos-order83</module>
<module>cloudalibaba-config-nacos-client3377</module>
</modules>
<!--统一管理jar包和版本-->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<junit.version>4.12</junit.version>
<log4j.version>1.2.17</log4j.version>
<lombok.version>1.16.18</lombok.version>
<mysql.version>8.0.18</mysql.version>
<druid.verison>1.1.16</druid.verison>
<mybatis.spring.boot.verison>1.3.0</mybatis.spring.boot.verison>
</properties>
<!--子模块继承之后,提供作用:锁定版本+子module不用写groupId和version-->
<dependencyManagement>
<dependencies>
<!--spring boot 2.2.2-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.2.2.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring cloud Hoxton.SR1-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring cloud alibaba 2.1.0.RELEASE-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.1.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- MySql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- Druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid.verison}</version>
</dependency>
<!-- mybatis-springboot整合 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis.spring.boot.verison}</version>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>
<!--junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
<!-- log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<fork>true</fork>
<addResources>true</addResources>
</configuration>
</plugin>
</plugins>
</build>
</project>
- 需要导入nacos的包,声明一下可以被发现
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
- 需要写配置文件,声明这是一个需要被管理的服务,需要被哪个地址进行管理,需要被管理哪些东西
server:
port: 9001
spring:
application:
name: nacos-payment-provider
cloud:
nacos:
discovery:
server-addr: localhost:8848 #配置Nacos地址
management:
endpoints:
web:
exposure:
include: '*'
- 主启动类也要使用注解声明一下,这个服务可以作为一个客户端被Nacos发现
@EnableDiscoveryClient
@SpringBootApplication
public class PaymentMain9001 {
public static void main(String[] args) {
SpringApplication.run(PaymentMain9001.class, args);
}
}
- 业务类我们可以写一个方法进行测试,将本机的端口暴露出去
@RestController
public class PaymentController
{
@Value("${server.port}")
private String serverPort;
@GetMapping(value = "/payment/nacos/{id}")
public String getPayment(@PathVariable("id") Integer id)
{
return "nacos registry, serverPort: "+ serverPort+"\t id"+id;
}
}
- 启动这个服务提供者,发现nacos控制台可以看到,安装同样的方式,我们再来一个9002的服务提供者,它们的服务名字都一样,但是端口却不一样,也就是说这是两个端口,这两个端口都可以提供同一个服务,
- 接下来是服务消费者
<dependencies>
<!--SpringCloud ailibaba nacos -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>com.atguigu.springcloud</groupId>
<artifactId>cloud-api-commons</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
- 配置文件
server:
port: 83
spring:
application:
name: nacos-order-consumer
cloud:
nacos:
discovery:
server-addr: localhost:8848
service-url:
nacos-user-service: http://nacos-payment-provider
- 这个主启动类和提供者差不多
@EnableDiscoveryClient
@SpringBootApplication
public class OrderNacosMain83 {
public static void main(String[] args) {
SpringApplication.run(OrderNacosMain83.class, args);
}
}
- 在服务调用者这里,我们可以使用一个模板进行调用,这个模板去调用提供者的方法,首先它们应该知道提供者的服务名称,然后还有它们的端口,自己需要准备参数,这些我们都可以获取到,我们还需要得到返回值,
- 由于提供者有很多个,我们需要确定到底使用的是哪一个,这也是一个问题,这个时候需要使用到负载均衡策略,
@Configuration
public class ApplicationContextConfig {
@Bean
@LoadBalanced
public RestTemplate getRestTemplate() {
return new RestTemplate();
}
}
- 往容器中注入的这个Bean上面又声明了LoadBalanced注解,这表明我们的RestTemplate使用了一种负载均衡策略
- 然后我们在消费者端就可以轮流调用提供者提供的服务了
@RestController
@Slf4j
public class OrderNacosController {
@Resource
private RestTemplate restTemplate;
@Value("${service-url.nacos-user-service}")
private String serverURL;
@GetMapping(value = "/consumer/payment/nacos/{id}")
public String paymentInfo(@PathVariable("id") Long id) {
return restTemplate.getForObject(serverURL + "/payment/nacos/" + id, String.class);
}
}
- Nacos 其实是可以支持CP或者AP的,这两者之间可以相互切换
- C是所有节点在同一时间看到的数据是一致的,而A的定义是所有的请求都会收到响应
- 如果不需要存储服务级别的信息且服务实例是通过nacos-client注册,并能够保持心跳上报,那么就可以选择AP默认当前主流的服务如SPring Cloud和Dubbo服务,都适合用于AP模式,AP模式为了服务的可能性而减弱了一致性,因此AP模式下只支持注册临时实例
- 如果需要在服务级别编写或存储配置信息,那么CP是必须的, k8s和DNS服务则适用于CP模式
- CP模式下支持注册持久化实例,此时则是以Raft协议为集群运行模式该模式下注册实例之前需先注册服务,如果服务不存在,则会返回错误
- curl -X PUT ‘$NACOS_SERVER:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=CP’
Nacos作为服务配置中心
我们可以在Nacos上搭建自己的配置文件,在自己的服务中声明自己想要使用哪个即可
- 依赖引入
<dependencies>
<!--nacos-config-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--nacos-discovery-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--web + actuator-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--一般基础配置-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
- 配置文件需要配置两个
- 为什么需要两个呢?
- Nacos 和SpringCloud-config一样,在项目初始化时,需要先去配置中心进行配置拉取,然后才能保证项目的正常启动
- 配置文件的加载存在优先顺序, bootstrap优先级高于application
- 在远程配置的配置文件的命名格式都需要遵循一定的规则,要不然时无法获取到的
server:
port: 3377
spring:
application:
name: nacos-config-client
cloud:
nacos:
discovery:
server-addr: localhost:8848 #服务注册中心地址
config:
server-addr: localhost:8848 #配置中心地址
file-extension: yaml #指定yaml格式的配置
# application.yaml
spring:
profiles:
active: dev
# ${spring.application.name}-${spring.profile.active}.${spring.cloud.nacos.config.file-extension}
# nacos-config-client-dev.yml
- 主启动类无变化
@EnableDiscoveryClient
@SpringBootApplication
public class NacosConfigClientMain3377 {
public static void main(String[] args) {
SpringApplication.run(NacosConfigClientMain3377.class, args);
}
}
- 然后我们暴露一个端口,就可以看到在远程配置文件上面的信息,并且我们也可以设置自动刷新,这样当远程修改的时候,我们这个端口可以立即看到
@RestController
@RefreshScope
public class ConfigClientController {
@Value("${config.info}")
private String configInfo;
@GetMapping("/config/info")
public String getConfigInfo() {
return configInfo;
}
}
- 主要有以下一些方面可以可以更换配置文件,
- spring.application.name 项目的名称
- spring.profile.active 项目的环境,一般有dev test等
- spring.cloud.nacos.config.file-extension 项目的扩展文件名
- 此外,还有group,namespace等
server:
port: 3377
spring:
application:
name: nacos-config-client
cloud:
nacos:
discovery:
server-addr: localhost:8848 #服务注册中心地址
config:
server-addr: localhost:8848 #配置中心地址
file-extension: yaml #指定yaml格式的配
group: TEST_GROUP
namespace: 76fce2f9-7d68-4729-a7d5-b6861295483d
# ${spring.application.name}-${spring.profile.active}.${spring.cloud.nacos.config.file-extension}
# nacos-config-client-dev.yml
- 以上的这些信息可以唯一确定一个配置文件
Nacos持久化配置
这样一个微服务项目的配置文件一般都比较重要,如果万一挂掉了呢,所以我们需要非常谨慎的去处理配置信息,Nacos默认自带的嵌入式数据库,derby,
- 我们也可以使用MySQL对配置文件进行持久化
- 在config配置文件下有sql脚本,专门建立配置文件的数据表信息,
- 修改application.properties ,咋i最后面加上一些信息
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://localhost:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
db.user=root
db.password=123456
- 下次就可以去mysql数据库里面找响应的消息了,
- 如果要做持久化,我们仅仅需要一个mysql可能还不够,我们还需要高可用,把Nacos做一个集群,一个挂了另外一个可以顶上,它们共同使用一个mysql或者一个mysql的集群,
- 我们模拟一下使用场景, 1个Nginx,+3个Nacos注册中心 + 1个Mysql
- 我们先确定3台Nacos机器的不同服务端口号
- 然后修改cluster.conf, 上面列出这个集群中所有的Nacos机器,
- 再编写 Nacos的启动脚本 startup.sh ,使我们可以以不同的端口启动
- 修改内容有些乱七八糟的,这里就不想再罗列出来了,等会儿说一个更加合适的方法
- 另外我们的nginx也需要进行配置一下,然后暴露出来一个端口,监听集群里面的端口,然后负载均衡的分配给这些端口里面某一个确定的端口
upstream cluster{
server 127.0.0.1:3333;
server 127.0.0.1:4444;
server 127.0.0.1:5555;
}
server{
listen 1111;
server_name localhost;
location /{
proxy_pass http://cluster;
}
- 启动nginx和我们的集群里面的端口即可
- 我们在客户端修改一下服务器的ip,修改为我们nginx暴露出来的端口即可
- 或者我们复制三个nacos,然后它们的cluster.xml 都是一样的,然后再把各自的端口修改一下,全部启动即可
Sentinel学习
Sentinel 主要提供 流量控制,熔断降级,系统负载保护,
可以理解为和Hystrix 的功能一致,但是这个比较优秀的是它可以 进行配置,
我们都知道,一般都是约定大于配置,配置大于编码,这就是它比较优秀的地方,可以再很多场景下面进行详细的配置
- 服务使用中的各种问题:
- 服务雪崩
- 服务降级
- 服务熔断
- 服务限流
- Sentinel分为两个部分
- 核心库,不依赖任何框架库,能够运行于所有Java运行环境,同时对Dubbo、 SpringCloudd等框架也有比较好的支持
- 控制台,基于SpringBoot开发,打包后可以直接运行,不需要web服务器
- 我们去官网上面下载jar包,就可以使用java命令进行运行了,不过运行时需要注意,确保jdk8,8080端口不能被占用,然后就可以访问了
- 假设现在nacos和sentinel都已经启动了,现在我们每创建一个微服务里面的接口都需要被监控到,
- 需要做如下配置,我们现在创建一个8401端口的服务,看一下具体情况,
pom
<dependencies>
<dependency>
<groupId>com.atguigu.springcloud</groupId>
<artifactId>cloud-api-commons</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>4.6.3</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
配置文件
server:
port: 8401
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
server-addr: localhost:8848
sentinel:
transport:
dashboard: localhost:8080
port: 8719 #默认8719,假如被占用了会自动从8719开始依次+1扫描。直至找到未被占用的端口
management:
endpoints:
web:
exposure:
include: '*'
主启动类
@EnableDiscoveryClient
@SpringBootApplication
public class MainApp8401 {
public static void main(String[] args) {
SpringApplication.run(MainApp8401.class, args);
}
}
然后我们建立一个测试的接口类进行测试
@Slf4j
@RestController
public class FlowLimitController {
@GetMapping("/testA")
public String testA() {
return "------testA";
}
@GetMapping("/testB")
public String testB() {
return "------testB";
}
@GetMapping("/testD")
public String testD() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("testD 测试");
return "------testD";
}
}
- 由于Sentinel采用的懒加载的模式,我们需要被管理的接口除了再配置文件上声明过以外,还需要自己访问一次才可以进行管理,这样也是为了节省资源吧

流控模式的详细信息
- 资源名,也就是相当于我们访问的接口的名字
- 针对来源:sentinel可以针对调用者进行限流,填写微服务名字,默认是default,不区分来源
- 阈值类型 :
- QPS 每秒钟请求数量,当调用该api的QPS到达阈值的时候就会进行限流
- 线程数:当调用该api的线程数到达阈值的时候,进行限流
- 这两个怎么区分呢, 一个主机可以有很多个线程,这些线程可以同时调用一个api,QPS相当于在外部进行拦截,线程数相当于在系统的内部进行拦截
- 是否集群:现在先不考虑集群
- 流控模式:
- 直接:api达到限流条件时,直接限流
- 关联:当关联的资源达到阈值时,会限流自己
- 链路:只记录指定链路上的流量
- 流控效果
- 直接:直接失败,抛出异常
- 预热:阈值除以 cold Factor(默认为3),经过预热时长后才会达到阈值,默认每秒钟可以接收3个请求,逐步增加,经过预热时长之后,逐步升至设定的QPS阈值
- 预热比较适合的应用场景时在秒杀系统开启的瞬间,会有很多流量上来,很有可能把系统打死,预热方式就是为了保护系统,慢慢的把流量放进来,慢慢把阈值增长到设置的阈值
- 排队等待:让请求以均匀1的速度通过,对应的是漏桶算法,该方式主要用于处理间隔性突发的流量,例如消息队列,,在某一秒有大量的请求到来,而接下来几秒则处于空闲状态,我们希望系统能够在接下来的空闲时间逐渐处理这些请求,而不是一下子拒绝掉
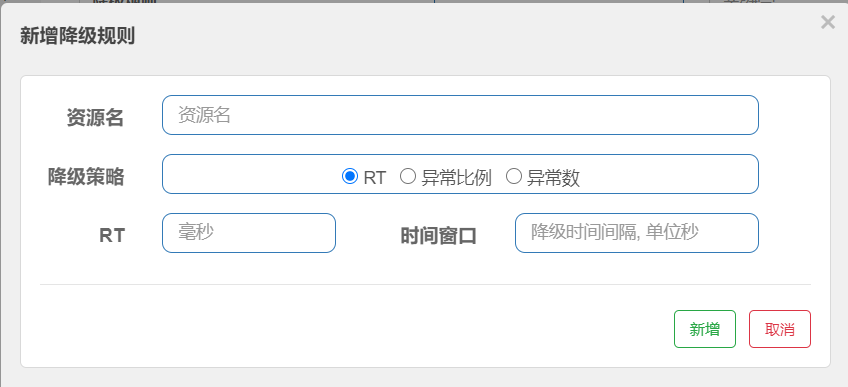
降级规则
- 降级策略 RT 平均响应时间,超出阈值,且在时间窗口内通过的请求大于5同时满足时触发
- 异常比例: QPS大于5 且异常比例(秒级统计) 超过阈值,触发降级,时间窗口结束后关闭降级
- 异常数,异常数超过阈值(分钟统计) 触发降级,时间窗口结束后,关闭降级
- 我们在学习Hystrix的时候,知道它时是有一个半开的状态的,半开的状态系统自动去检车是否请求有异常,没有异常就关闭断路器恢复使用,有异常则继续打开断路器不可以用,但是这里是没有半开这个状态的

热点参数限流
- 热点,就是我们经常访问的数据,很多时候我们希望统计某一个热点数据中访问频次最高的数据,并对其访问进行限制,
- 热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流,热点参数限流可以看作是一种特殊的流量控制,仅对包含热点参数的资源调用生效
- Sentinel利用LRU策略统计最佳最常访问的热点参数,结合令牌桶算法来进行参数级别的流量防控,热点参数限流支持集群模式
@GetMapping("/testHotKey")
@SentinelResource(value = "testHotKey")
public String testHotKey(@RequestParam(value = "p1",required = false) String p1,
@RequestParam(value = "p2",required = false) String p2) {
//int age = 10/0;
return "------testHotKey";
}
- 我们这样写我们的接口,然后配置热点规则,当第一个参数的QPS超过1的时候就会进行报错,这个时候如果还是要继续访问就会返回错误页面,这个错误页面看着很不美观,我们也可以自己设置
@GetMapping("/testHotKey")
@SentinelResource(value = "testHotKey",blockHandler = "deal_testHotKey")
public String testHotKey(@RequestParam(value = "p1",required = false) String p1,
@RequestParam(value = "p2",required = false) String p2) {
//int age = 10/0;
return "------testHotKey";
}
//兜底方法
public String deal_testHotKey (String p1, String p2, BlockException exception){
return "------deal_testHotKey,o(╥﹏╥)o";
}
- 这个时候如果访问的频率违背了我们定义的热点规则,就会按照我们自定义的兜底方法来进行处理
- 但是如果我们不违背自己在Sentinel上面定义的热点规则,那么就什么事情也没有
- 我们定义的热点规则还可以支持高级配置,在原本的规则基础上,当参数类型和参数值确定了,再使用另外一套规则,使用不同的限流阈值
- 热点参数需要注意:参数类型必须是基本类型或者String
- @SentinelResource(value = “testHotKey”,blockHandler = “deal_testHotKey”) 这个处理的是Sentinel控制台配置违规的情况,有blockHandler方法配置的兜底方法,但是如果是方法内部运行时异常是无法控制的
系统规则

Sentinel 系统自适应限流从整体维度对应用入口流量进行控制,结合应用的 Load、CPU 使用率、总体平均 RT、入口 QPS 和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
- 系统规则是从应用基本的入口流量进行控制,从load ,CPU使用率, 平均RT,入口QPS,和并发线程数等几个维度监控应用指标,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性
- load是一个结果,如果根据load的情况来调节流量的通过率,那么就始终有延迟,也就意味着通过率的任何调整,都会过一段时间才能看到结果,当前通过率是使load恶化的一个动作,那么也至少要过1s之后才可以观测到,同理,如果当前通过率调整时让load好转的当作,也需要1s之后才能继续调整,这样就浪费了系统的处理能力,所以我们看到的曲线,总是会有抖动
- 总的来说,load不适合我们做及时的调整,,我们应该根据系统能够处理的请求,和允许进来的请求,来做平衡,而不是根据一个间接的指标来 load 做限流,最终我们追求的目标是,在系统不被拖垮的情况下,提高系统的吞吐率,而不是load一定要低于某个阈值,
- CPU usage 当系统CPU使用率超过阈值即触发系统保护 ,比较灵敏
- 平均RT:当单台机器上所有入口流量的平均RT达到阈值即触发系统保护,单位是毫秒
- 并发线程数:所有入口流量的并发线程数达到阈值即触发系统保护
- 入口QPS:所有入口流量的QPS达到阈值即触发系统保护
按资源名称限流和按照Url地址进行限流
@GetMapping("/byResource")
@SentinelResource(value = "byResource", blockHandler = "handleException")
public CommonResult byResource() {
return new CommonResult(200, "按资源名称限流测试OK", new Payment(2020, "serial001"));
}
@GetMapping("/rateLimit/byUrl")
@SentinelResource(value = "byUrl")
public CommonResult byUrl()
{
return new CommonResult(200,"按url限流测试OK",new Payment(2020,"serial002"));
}
这两个方式其实都一样
自定义限流逻辑处理
原来的限流逻辑有一些缺点:
- 系统默认的,没有体现我们的业务要求
- 依照现有的条件我们自定义处理方法和业务方法都在一个类里面,耦合度太高,不太好
- 每个业务方法都有一个兜底方法,不太合适
- 全局统一的处理方法没有体现
@GetMapping("/byResource")
@SentinelResource(value = "byResource",
blockHandlerClass = CustomerBlockHandler.class,
blockHandler = "handleException")
public CommonResult byResource() {
return new CommonResult(200, "按资源名称限流测试OK", new Payment(2020, "serial001"));
}
public class CustomerBlockHandler {
public static CommonResult handleException(BlockException e){
return new CommonResult(2000,"客户自定义限流处理信息");
}
}
- 按照上面的方法,我们就可以在一个统一的类里面写一些静态的方法,然后所有的兜底都在里面
- 需要注意的是,如果原来的方法有参数,那么兜底的方法也一定要有参数
Sentinel整合ribbon+openFeign+fallback
- 创建两个服务提供者项目,
- 然后消费者项目创建,
@RestController
@Slf4j
public class CircleBreakerController {
public static final String SERVICE_URL = "http://nacos-payment-provider";
@Resource
private RestTemplate restTemplate;
@RequestMapping("/consumer/fallback/{id}")
//@SentinelResource(value = "fallback") //没有配置
//@SentinelResource(value = "fallback",fallback = "handlerFallback") //fallback只负责业务异常
//@SentinelResource(value = "fallback",blockHandler = "blockHandler") //blockHandler只负责sentinel控制台配置违规
@SentinelResource(value = "fallback",
fallback = "handlerFallback",
blockHandler = "blockHandler",
exceptionsToIgnore = {IllegalArgumentException.class})
public CommonResult<Payment> fallback(@PathVariable Long id) {
CommonResult<Payment> result = restTemplate.getForObject(SERVICE_URL + "/paymentSQL/" + id, CommonResult.class, id);
if (id == 4) {
throw new IllegalArgumentException("IllegalArgumentException,非法参数异常....");
} else if (result.getData() == null) {
throw new NullPointerException("NullPointerException,该ID没有对应记录,空指针异常");
}
return result;
}
//fallback
public CommonResult handlerFallback(@PathVariable Integer id, Throwable e) {
Payment payment = new Payment(id, "null");
return new CommonResult<>(444, "兜底异常handlerFallback,exception内容 " + e.getMessage(), payment);
}
//blockHandler
public CommonResult blockHandler(@PathVariable Integer id, BlockException blockException) {
Payment payment = new Payment(id, "null");
return new CommonResult<>(445, "blockHandler-sentinel限流,无此流水: blockException " + blockException.getMessage(), payment);
}
}
- 原理上是 fallback会管理服务内部出现异常的回执,被限流降级而抛出的异常只会进入blockHandler处理逻辑
- 具体的套路就是我们访问规则出错,使用blockHandler里面的方法,访问内部出错,使用fallback里面的回执方法,如果一直访问内部都出错,那么就用 blockHandler的方法,因为它首先是违反了我们定义的访问规则,然后再在内部出错的
- 我们之前学习过Feign,现在再来回顾一遍,顺便将这个项目改造一下
在服务消费者引入feign
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
在配置文件上面开启对feign的支持
#对Feign的支持
feign:
sentinel:
enabled: true
远程调用,并声明降级方法
@FeignClient(value = "nacos-payment-provider",fallback = PaymentFallbackService.class)
public interface PaymentService
{
@GetMapping(value = "/paymentSQL/{id}")
public CommonResult<Payment> paymentSQL(@PathVariable("id") Integer id);
}
@Component
public class PaymentFallbackService implements PaymentService {
@Override
public CommonResult<Payment> paymentSQL(Integer id) {
return new CommonResult<>(44444, "服务降级返回,---PaymentFallbackService", new Payment(id, "errorSerial"));
}
}
在主启动类声明启用Feign远程调用
@EnableDiscoveryClient
@SpringBootApplication
@EnableFeignClients
public class OrderNacosMain84 {
public static void main(String[] args) {
SpringApplication.run(OrderNacosMain84.class, args);
}
}
- 熔断框架的比较
| | Sentinel | Hystrix | resilience4j |
| — | — | — | — |
| 隔离策略 | 信号量隔离(并发线程数限流) | 线程池隔离/信号量隔离 | 信号量隔离 |
| 熔断降级策略 | 基于响应时间,异常比率,异常数 | 基于异常比率 | 基于异常比率,响应时间 |
| 实时统计实现 | 滑动窗口 LeapArray | 滑动窗口,基于 RxJava | Ring Bit Buffer |
| 动态规划配置 | 支持多种数据源 | 支持多种数据源 | 有限支持 |
| 扩展性 | 多个扩展点 | 插件的形式 | 的接口形式 |
| 基于注解的支持 | 支持 | 支持 | 支持 |
| 限流 | 基于QPS,支持基于调用关系的限流 | 有限的支持 | Rate Limiter |
| 流量整形 | 支持预热模式,匀速器模式,预热排队模式 | 不支持 | 简单的Rate Limiter模式 |
| 系统自适应保护 | 支持 | 不支持 | 不支持 |
| 控制台 | 提高开箱即用的控制台,可配置规则,查看秒级监控,机器发现 | 简单的监控查看 | 不提高控制台,可对接其他监控系统 |
规则持久化
一旦我们重启应用,Sentinel规则就会消失,生产环境需要将配置规则进行持久化,
可以将限流配置规则持久化进 Nacos 保存,只要刷新 8401 某个rest地址,sentinel控制台的流控规则就能看到,只要Nacos里面的配置不删除,针对 8401 上 Sentinel上的 流控规则持续有效
- 我们发现我们指定的规则在外面的服务停止之后再上来就没有了,针对这种情况,外面可以将外面的配置作为一个配置文件存储到nacos上面,而nacos外面前面已经学习过,它将信息存储到了数据库里面,所以外面就相当于间接的把配置信息存储到了数据库上面
- 下次登录就会发现以前配置过的规则
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
配文件,需要声明外面存储到了哪个nacos声明,存储的格式,名字,组名,规则
server:
port: 8401
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
server-addr: localhost:8848
sentinel:
transport:
dashboard: localhost:8080
port: 8719 #默认8719,假如被占用了会自动从8719开始依次+1扫描。直至找到未被占用的端口
datasource:
ds1:
nacos:
server-addr: localhost:8848
dataId: cloudalibaba-sentinel-service
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow
management:
endpoints:
web:
exposure:
include: '*'
spring:
cloud:
sentinel:
datasource:
ds1:
nacos:
server-addr:localhost:8848
dataid:${spring.application.name}
groupid:DEFAULT_GROUP
data-type:json
rule-type:flow
外面配置过一个规则之后,配置的格式大致如此
[
{
"resource": "/retaLimit/byUrl",
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]
resource: 资源名称,可以看作是我们的接口什么的
limitApp: 来源应用
grade: 阈值类型,0表示线程数,1表示QPS
count: 单机阈值
strategy: 流控模式:0表示直接,1表示关联,2表示链路
controlBehavior: 流控效果,0表示快速失败,1表示预热,2表示排队
clusterMode: 表示是否集群
分布式事务问题
Seata是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务,Seata将为用户提供了AT,TCC,SAGA和XA事务模式
AT模式
- 前提是基于本地ACID事务的关系型数据库,Java应用,通过JDBC访问数据库
- 通过两个阶段提交协议:
- 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源
- 二阶段,提交异步化,回滚通过一阶段的回滚日志进行反向补偿
- 写隔离:
- 一阶段本地事务提交之前,需要确保先拿到全局锁,
- 拿不到全局锁就无法提交本地事务,
- 拿全局锁的尝试被限制在一定范围内,超过范围将放弃,并回滚本地事务,释放本地锁,
- 例子 一阶段:
- 解析SQL,得到SQL的类型,表,条件等相关信息,
- 查询前镜像:根据解析得到的条件信息,生成查询语句,定位数据,得到要更新这一行的数据的镜像
- 执行业务SQL,更新这条记录,
- 查询后镜像,根据前镜像的结果,通过主键定位数据,得到之后的镜像,
- 插入回滚日志,把前后镜像数据以及业务SQL相关的信息组成一条回滚日志记录,插入到UNDO_LOG表中,
- 提交之前,向TC注册分支,去申请要修改记录的全局锁,
- 本地事务提交,业务数据的更新和前面步骤中生成的UNDO_LOG 一并提交
- 将本地事务提交的结果上报给TC
- 二阶段-回滚
- 收到TC的分支回滚请求,开启一个本地事务,执行如下操作
- 通过XID和BranchID查找相应的UNDO_LOG 记录
- 数据校验:拿UNDO_LOG中的后镜像与当前数据进行比较,如果有不同,说明数据被当前全局事务之外的动作做了修改,这种情况需要根据配置策略来做处理
- 根据UNDO_LOG 中的前镜像和业务SQL的相关信息生成执行回滚的语句
- 然后提交本地事务,并把本地事务的执行结果上报给TC
- 二阶段-提交
- 收到TC的分支提交请求,把请求放入一个异步任务的队列中,马上返回提交成功的结果给TC,
- 异步任务阶段的分支提交请求将异步和批量的删除相应UNDO_LOG记录
TCC模式
上一步AT模式的全局事务整体式两阶段提交,全局事务时由若干分支事务组成,分支事务 要满足两阶段提交的模型要求,即每个分支事务都具备自己的两个阶段
- 一阶段 prepare行为 : 在本地事务中,一并提交业务数据更新和相应回滚日志记录
- 二阶段 commit 或 rollback行为 : commit行为,马上成功结束,自动异步批量清理回滚日志
- 二阶段 rollback : 通过回滚日志,自动生成补偿操作,完成数据回滚
分布式事务的处理过程: ID+三组件模型
- 全局唯一的事务ID
- TC: Transaction Coordinator 事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚
- TM:Transaction Manager 控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议
- RM:Resource Manager 控制分支事务,负责分支注册,状态汇报,并接收事务协调器的指令,驱动分支(本地)事务dd1提交和回滚
处理过程
- TM向TC申请开启一个全局事务,全局事务创建成功,并生成一个全局唯一的XID
- XID在微服务调用链路的上下文中传播
- RM向TC注册分支事务,将其纳入XID对应全局事务的管辖,
- TM向TC发起针对XID的全局提交或回滚决议
- TC调度XID管辖的全部分支事务完成提交或回滚请求
这个太新了,我决定放弃!!!以后再来

















 2920
2920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









