







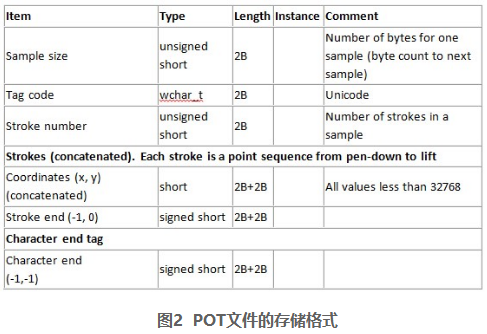
在读取手写藏文字符数据集的时候,下载下来的文件是.pot文件,一开始以为是ppt的模块文件,后来发现ppt打不开这种文件,重读官网数据集说明,发现了下图:
图片来自http://www.csdata.org/en/p/19/
可以看出来,这个pot文件是自定义的文件格式,里面的数据按2B存储,因此读数据也要每次两个字节这样来读
with open(filename,'rb',True) as f:
content = f.read()
由图可知,每个pot文件中的每个藏文字符的坐标点结束后的坐标是(-1,-1),每个藏文字符的每个笔画结束后的坐标是(-1,0)。b'\xff\xff\xff\xff'正是-1,-1
allData = content[:]
characters = allData.split(b'\xff\xff\xff\xff')[:-1]
for character in characters:
count += 1
code = int.from_bytes(character[2:4],byteorder='little') #两个字节两个字节的读
codes.append(code)
pointBytes = character[6:]
length = len(pointBytes)
print(code)
points = []
for i in range(math.ceil(length/2)):
points.append(int.from_bytes(pointBytes[2*i:2*i+2],byteorder='little'))
#两个字节两个字节的读
pl = np.array(points).reshape(-1,2)
#一笔一笔地将藏文字符画出来
plt.figure(count)
ac = plt.gca()
op = []
for p in pl:
if(p[0]==65535):
op = np.array(op)
ac.set_xlim([op[:,0].min()-40,op[:,0].max()+40])
ac.set_ylim([op[:,1].min()-40,op[:,1].max()+40])
plt.plot(op[:,0],op[:,1],c='r',linewidth='1')
op = []
else:
p[1] = -1*p[1]
op.append(list(p))
plt.show()















 434
434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









