







GoogLeNet团队提出了Inception网络结构,就是构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构。
一、Inception V1
通过设计一个稀疏网络结构,但是能够产生稠密的数据,既能增加神经网络表现,又能保证计算资源的使用效率。谷歌提出了最原始Inception的基本结构:
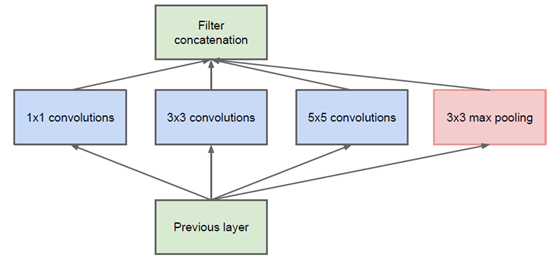
该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。
网络卷积层中的网络能够提取输入的每一个细节信息,同时5x5的滤波器也能够覆盖大部分接受层的的输入。还可以进行一个池化操作,以减少空间大小,降低过度拟合。在这些层之上,在每一个卷积层后都要做一个ReLU操作,以增加网络的非线性特征。
然而这个Inception原始版本,所有的卷积核都在上一层的所有输出上来做,而那个5x5的卷积核所需的计算量就太大了,造成了特征图的厚度很大,为了避免这种情况,在3x3前、5x5前、max pooling后分别加上了1x1的卷积核,以起到了降低特征图厚度的作用,这也就形成了Inception v1的网络结构,如下图所示:
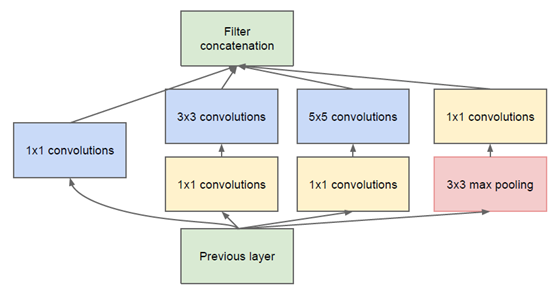
1x1的卷积核有什么用呢?
1x1卷积的主要目的是为了减少维度,还用于修正线性激活(ReLU)。比如,上一层的输出为100x100x128,经过具有256个通道的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256,其中,卷积层的参数为128x5x5x256= 819200。而假如上一层输出先经过具有32个通道的1x1卷积层,再经过具有256个输出的5x5卷积层,那么输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256= 204800,大约减少了4倍。
二、Inception V2
GoogLeNet设计的初衷就是要又准又快,而如果只是单纯的堆叠网络虽然可以提高准确率,但是会导致计算效率有明显的下降,所以如何在不增加过多计算量的同时提高网络的表达能力就成为了一个问题。
Inception V2版本的解决方案就是修改Inception的内部计算逻辑,提出了比较特殊的“卷积”计算结构。
1、卷积分解(Factorizing Convolutions)
大尺寸的卷积核可以带来更大的感受野,但也意味着会产生更多的参数,比如5x5卷积核的参数有25个,3x3卷积核的参数有9个,前者是后者的25/9=2.78倍。因此,GoogLeNet团队提出可以用2个连续的3x3卷积层组成的小网络来代替单个的5x5卷积层,即在保持感受野范围的同时又减少了参数量,如下图:
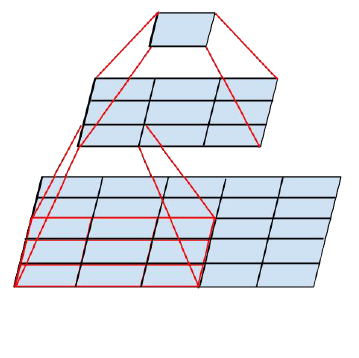
那么这种替代方案会造成表达能力的下降吗?通过大量实验表明,并不会造成表达缺失。
可以看出,大卷积核完全可以由一系列的3x3卷积核来替代,那能不能再分解得更小一点呢?GoogLeNet团队考虑了nx1的卷积核,如下图所示,用3个3x1取代3x3卷积:
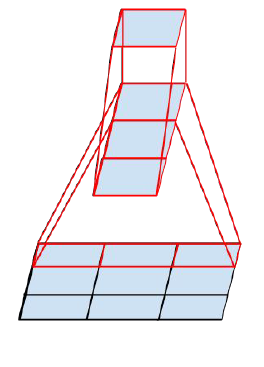
因此,任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。GoogLeNet团队发现在网络的前期使用这种分解效果并不好,在中度大小的特征图(feature map)上使用效果才会更好(特征图大小建议在12到20之间)。
2、降低特征图大小
一般情况下,如果想让图像缩小,可以有如下两种方式:
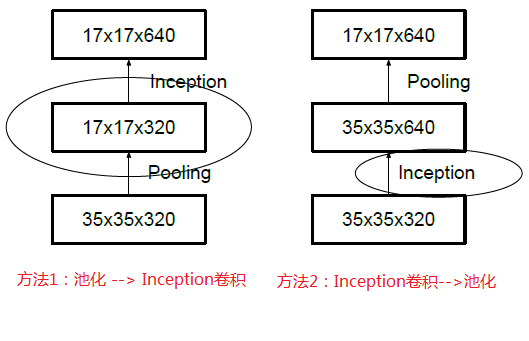
先池化再作Inception卷积,或者先作Inception卷积再作池化。但是方法一(左图)先作pooling(池化)会导致特征表示遇到瓶颈(特征缺失),方法二(右图)是正常的缩小,但计算量很大。为了同时保持特征表示且降低计算量,将网络结构改为下图,使用两个并行化的模块来降低计算量(卷积、池化并行执行,再进行合并)
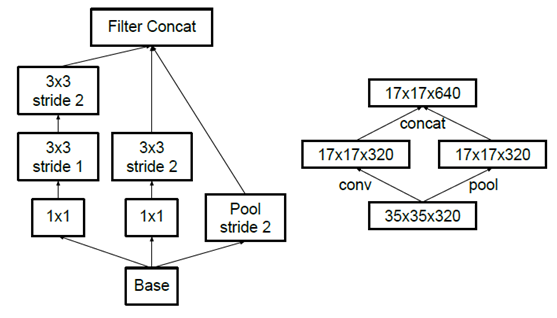
三、Inception V3
Inception V3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加速计算,又可以将1个卷积拆成2个卷积,使得网络深度进一步增加,增加了网络的非线性(每增加一层都要进行ReLU)。
另外,网络输入从224x224变为了299x299。
四、Inception V4
Inception V4研究了Inception模块与残差连接的结合。ResNet结构大大地加深了网络深度,还极大地提升了训练速度,同时性能也有提升。
Inception V4主要利用残差连接(Residual Connection)来改进V3结构。
ResNet的残差结构如下:
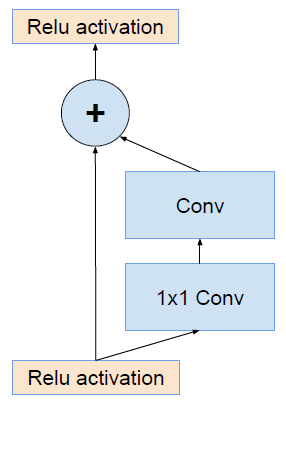
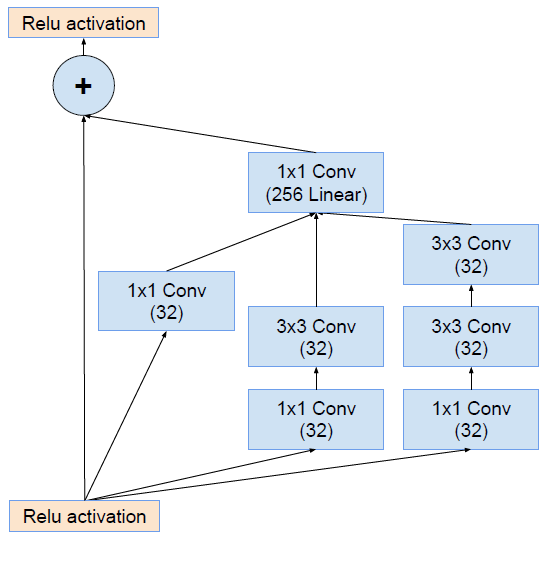
将该结构与Inception相结合:
原文地址:https://my.oschina.net/u/876354/blog/1637819















 2927
2927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









