










一、背景
在内核逻辑里增加内核栈的获取和记录是相对比较简单的,且已经在之前的博客里多次使用过。而有时候,我们不仅需要在内核逻辑里记录一个内核事件发生时的内核堆栈,还需要知道这个时刻用户态在执行什么逻辑,以方便进行问题根因的综合定位。
在之前的博客 观测指定内存上是否被读写,若触发条件打印调用栈_gdb 抓取signal6的调用堆栈-CSDN博客 里的第三章里,我们提到了会在将来的博客里讨论如何在内核逻辑里抓取内核逻辑发生时的当前任务的用户栈的情况,在这篇博客里,我们会给出几种获取方法。
二、perf_callchain_user函数
这个perf_callchain_user函数是在跟踪perf的内核代码时发现的一个函数,因为perf众所周知它是能抓内核态栈的符号及用户态栈的符号的,所以,perf的逻辑里在内核态里也肯定有相关的逻辑。下面我们从perf_prepare_sample这个perf的sample数据搜集的调用点出发,往下去找如何最终调用函数来抓取用户栈的。
有关perf_prepare_sample函数的相关的前面的调用链见之前的博客 perf原理介绍-CSDN博客 里的 3.2.1 里的说明。
2.1 从perf_prepare_sample到perf_callchain_user的调用链
我们以linux 6.5内核版本为例,perf_prepare_sample里如下图,调用了perf_sample_save_callchain函数:
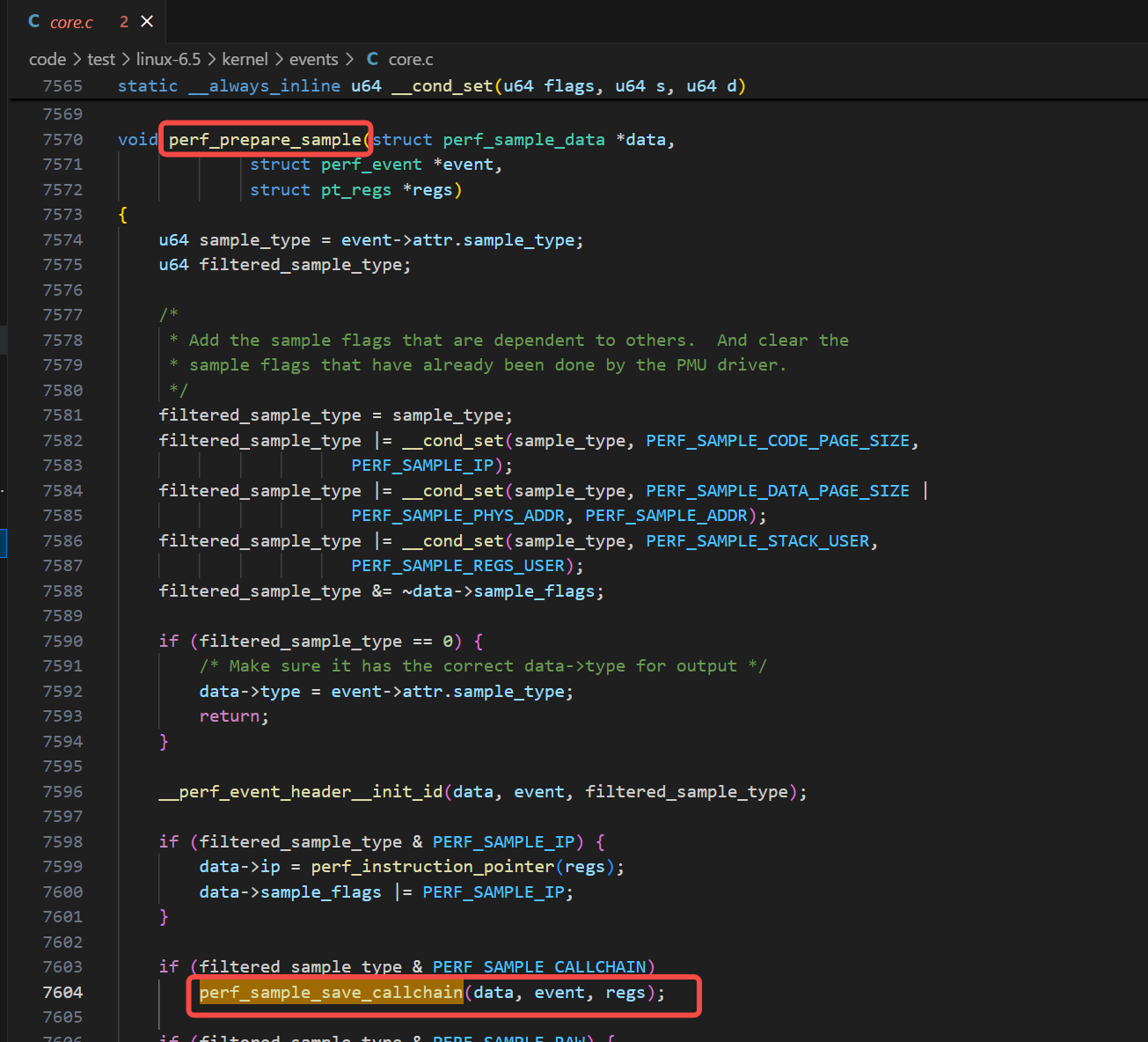
继而,perf_sample_save_callchain调用了perf_callchain:
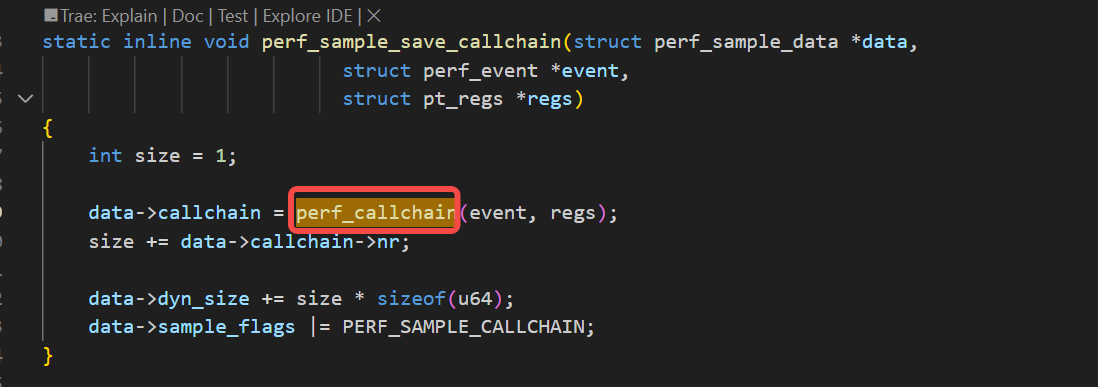
继而,perf_callchain调用了get_perf_callchain函数:
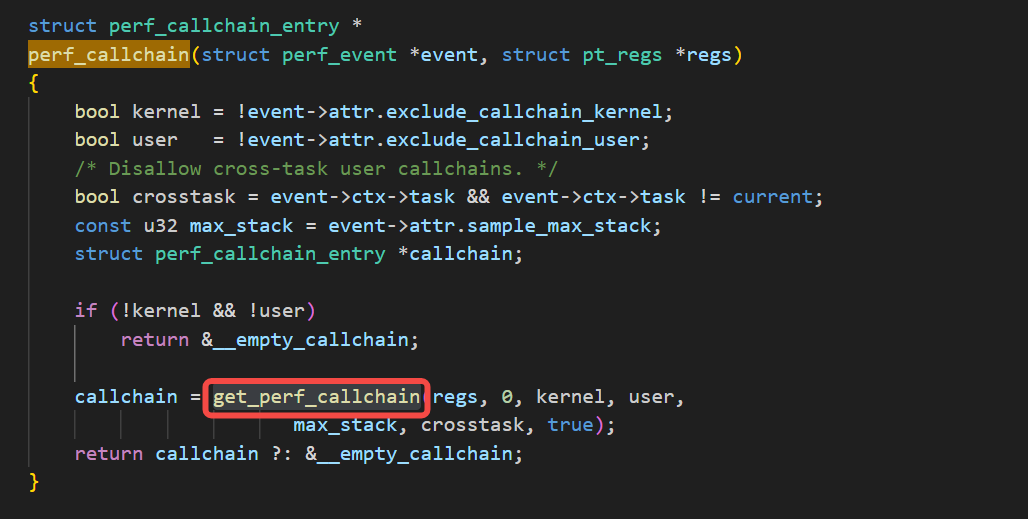
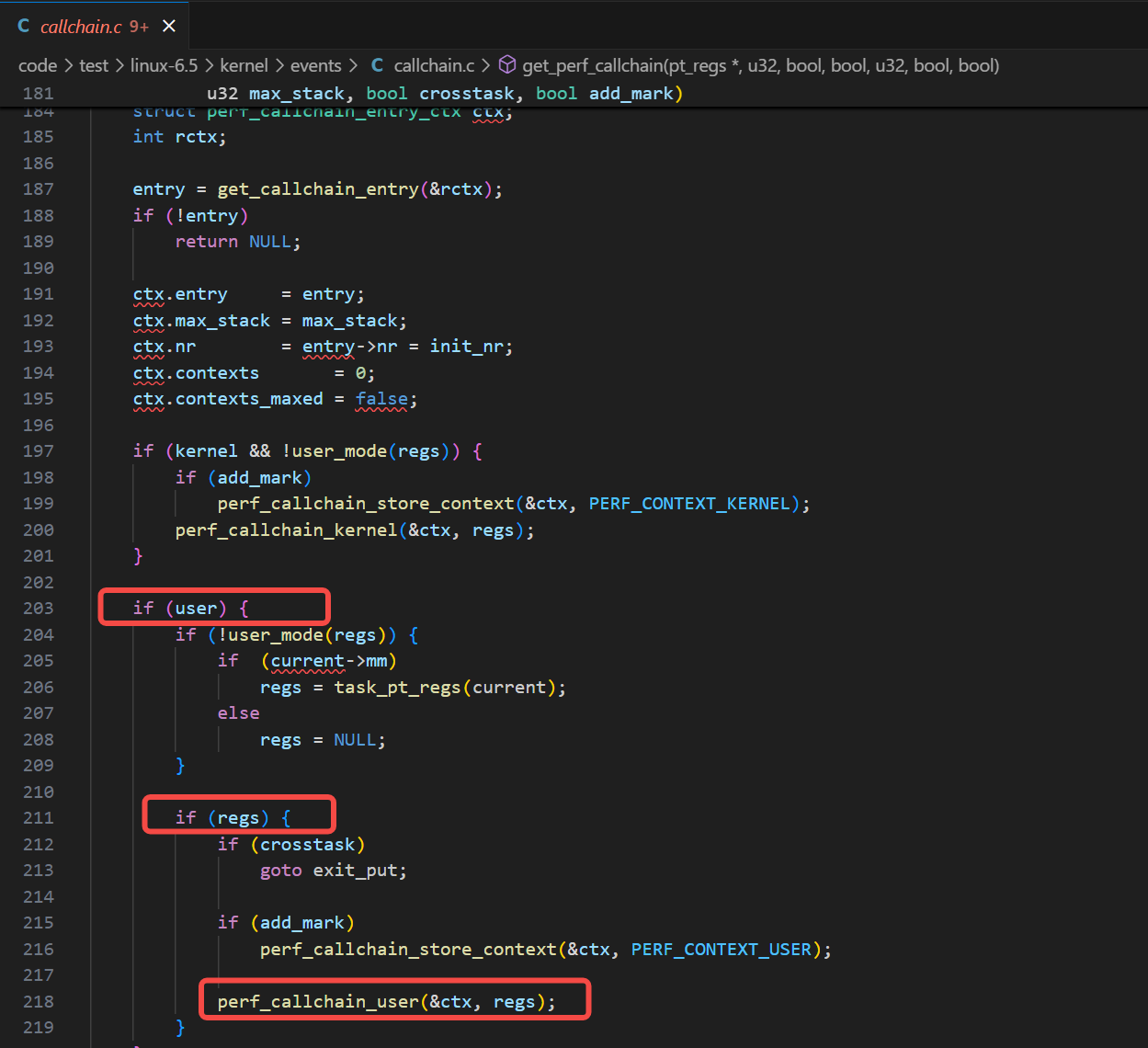
而get_perf_callchain函数根据当前采样的配置参数,来决定是否调用perf_callchain_user来进行用户栈的抓取:
2.2 如何使用perf_callchain_user函数
使用perf_callchain_user函数的例子的核心源码如下:
void init_get_perf_callchain_func(void)
{
int ret;
struct kprobe kp;
memset(&kp, 0, sizeof(kp));
kp.symbol_name = "perf_callchain_user";
kp.pre_handler = NULL;
kp.addr = NULL; // 作为强调,提示使用symbol_name
ret = register_kprobe(&kp);
if (ret < 0) {
printk("register_kprobe fail!\n");
return;
}
printk("register_kprobe succeed!\n");
_perf_callchain_user = (void*)kp.addr;
unregister_kprobe(&kp);
}
static void get_user_stack(
struct pt_regs *regs, struct task_struct *t)
{
struct perf_callchain_entry_ctx ctx;
bool buser = false;
int i;
struct userstack_entry *entry;
u64 timestart, timestop;
struct perf_callchain_entry* pentry = _pentry[smp_processor_id()];
if (t->pid == 0) {
return;
}
if (t->flags & PF_KTHREAD) {
return;
}
//printk(KERN_INFO "currcpu[%d]currpid[%d]pid[%d]addr[0x%lx] value is changed\n",
// smp_processor_id(), current->pid, watchpid, va);
//dump_stack();
//printk(KERN_INFO "Dump stack from sample_hbp_handler\n");
if (regs) {
int j;
for (j = 0; j < 1; j++) {
buser = user_mode(regs) ? true : false;
//printk("regs usermode[%d]\n", buser?1:0);
ctx.entry = pentry;
ctx.max_stack = PERF_MAX_STACK_DEPTH;
ctx.nr = pentry->nr = 0;
ctx.contexts = 0;
ctx.contexts_maxed = false;
timestart = getmonons();
_perf_callchain_user(&ctx, regs);
timestop = getmonons();
printk("_perf_callchain_user timespan=%llu\n", timestop - timestart);
if (pentry->nr == 1) {
for (i = 0; i < pentry->nr; i++) {
printk("cpu[%d]nr[%d]i[%d]pid[%d]comm[%s]buser[%u]_perf_callchain_user-ip[0x%llx]\n",
smp_processor_id(), pentry->nr, i, t->pid, t->comm, buser?1:0,
pentry->ip[i]);
}
}
}
}
else {
printk("regs is NULL\n");
}
}上面源码是先通过kprobe获取perf_callchain_user的函数指针,然后再调用perf_callchain_user进行用户栈获取。该函数的耗时在一般的性能还行的cpu上的消耗在100ns到700ns不等。函数层级越多自然就越耗时。
2.3 用户栈的抓取根据体系结构不同会有不同的表现
在我当前的x86平台上,用户栈的抓取如果是陷入内核态时抓取陷入内核态前的用户栈信息的话,它是可能抓得非常不全的(这一点我做了实验,用下面第三章讲到的stack_trace_save_user函数也是一样的可能抓不全的情况),如下图:
但是在arm64上可能表现得抓取得更全一些。
三、ftrace的userstack抓取及stack_trace_save_user
3.1 通过ftrace里的userstack功能来抓取
要注意并不是所有平台的默认配置都是支持这个userstack的ftrace抓取的,这个抓取不像perf那么一定能工作。
抓取的脚本如下:
#!/bin/bash
if [ -n "$1" ]; then
sleeptime=$1
else
echo "no input sleep time"
sleeptime=10
fi
#echo 1 > /sys/kernel/tracing/events/sched/sched_wakeup_new/enable
#echo 1 > /sys/kernel/tracing/events/sched/sched_process_exec/enable
#echo 1 > /sys/kernel/tracing/events/sched/sched_process_fork/enable
#pkill testwakeaff
echo 1 > /sys/kernel/tracing/events/sched/enable
echo 1 > /sys/kernel/tracing/events/irq/enable
#echo 1 > /sys/kernel/tracing/events/block/enable
#echo 1 > /sys/kernel/tracing/events/writeback/folio_wait_writeback/enable
echo 80960 > /sys/kernel/tracing/buffer_size_kb
echo 4096 > /sys/kernel/tracing/buffer_size_kb
echo 1 > /sys/kernel/tracing/options/record-tgid
echo 1280 > /sys/kernel/tracing/saved_cmdlines_size
echo 1 > /sys/kernel/tracing/options/stacktrace
echo 1 > /sys/kernel/tracing/options/userstacktrace
echo 1 > /sys/kernel/tracing/options/sym-userobj
#echo 1 > /sys/kernel/tracing/options/func_stack_trace
echo > /sys/kernel/tracing/trace
echo 1 > /sys/kernel/tracing/tracing_on
#mkdir -p record
sleep $1
echo 0 > /sys/kernel/tracing/tracing_on
#cat /sys/kernel/tracing/snapshot > record/snapshot.txt
cat /sys/kernel/tracing/trace > trace.txt
上面脚本里有关内核栈的抓取是:

有关用户栈的抓取是:

上图里的userstacktrace是捞取用户栈的调用链的pc,上图里的sym-userobj可以提供更多的有关elf路径及offset的信息。
3.2 跟踪ftrace的userstack功能,跟踪到stack_trace_save_user函数
我们跟踪ftrace如何抓取用户栈的逻辑就可以跟到是stack_trace_save_user函数,继而调用arch_stack_walk_user函数。
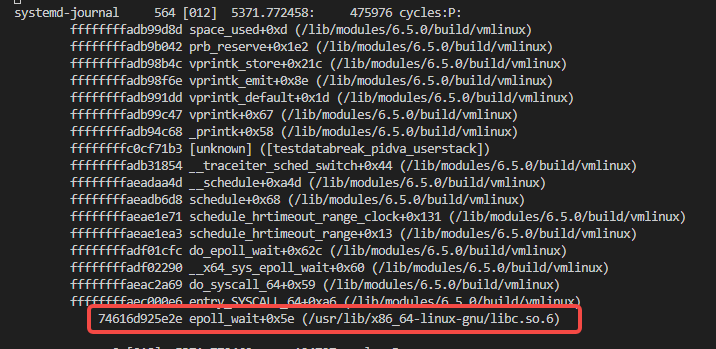
我们搜索userstacktrace字符串可以搜到如下内容:
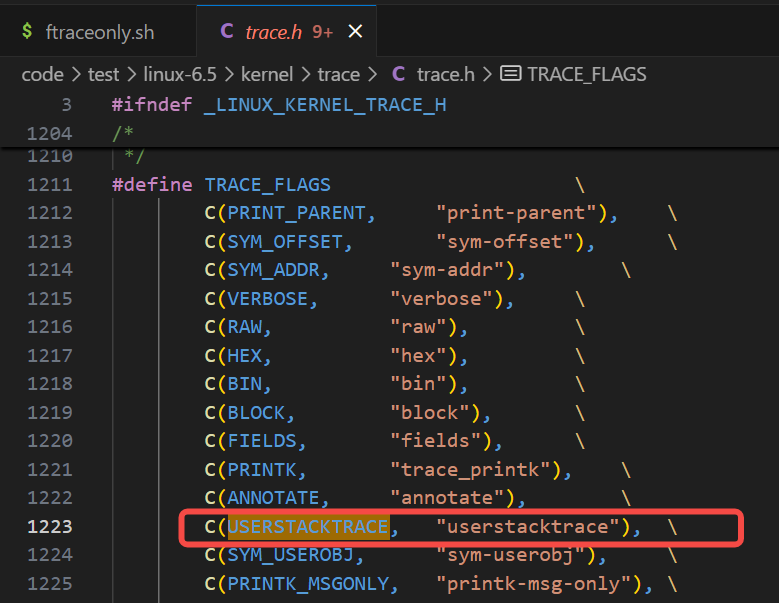
然后搜索USERSTACKTRACE,不设置全字符匹配(允许截断匹配):
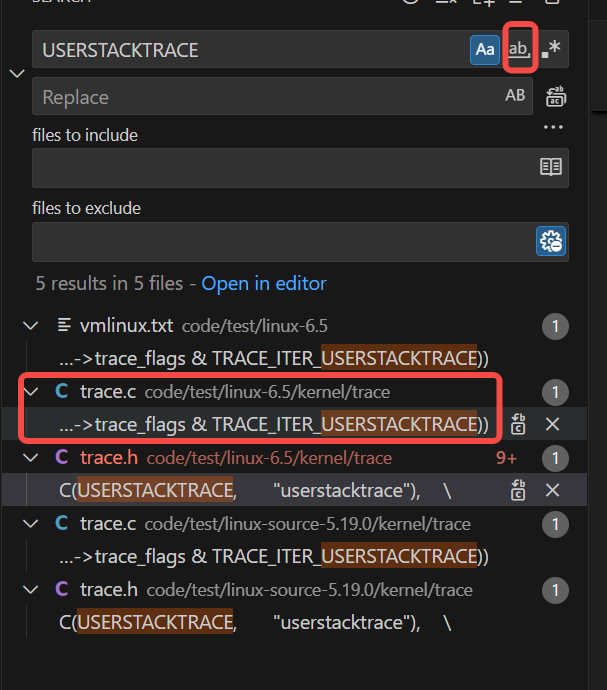
上图里的trace.c里的源码如下,ftrace_trace_userstack函数:
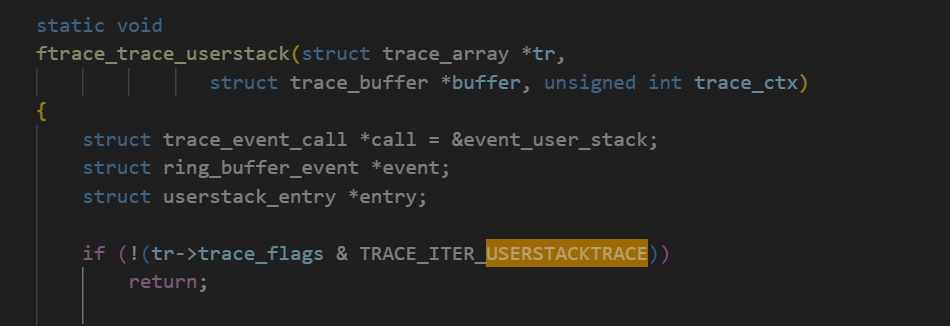
如上图,判断不需要打userstack的话就返回,如果需要打就走到stack_trace_save_user的逻辑了:
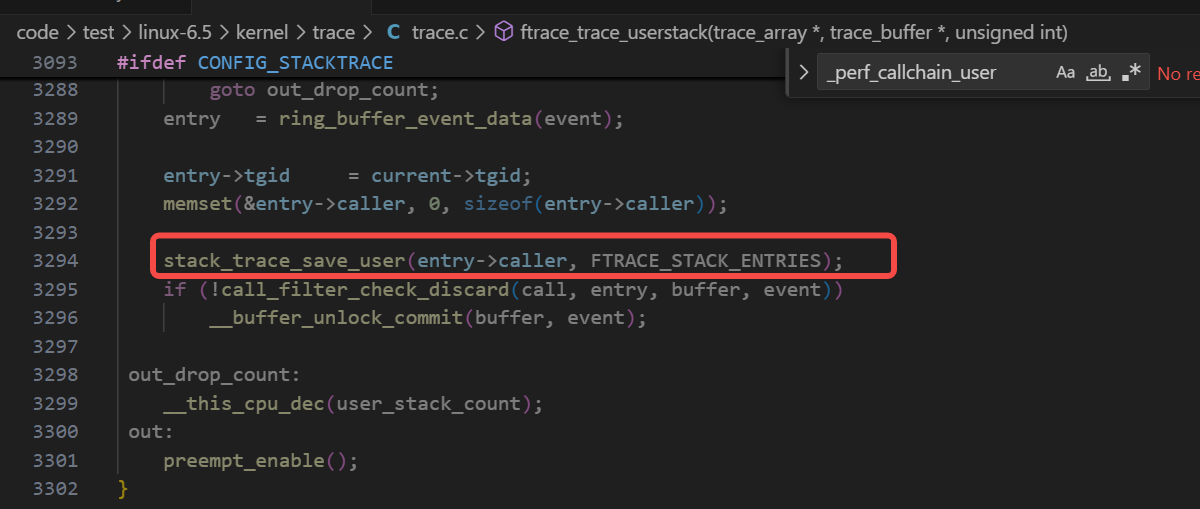
3.3 stack_trace_save_user函数进一步分析
stack_trace_save_user函数,如下图调用了arch_stack_walk_user函数:
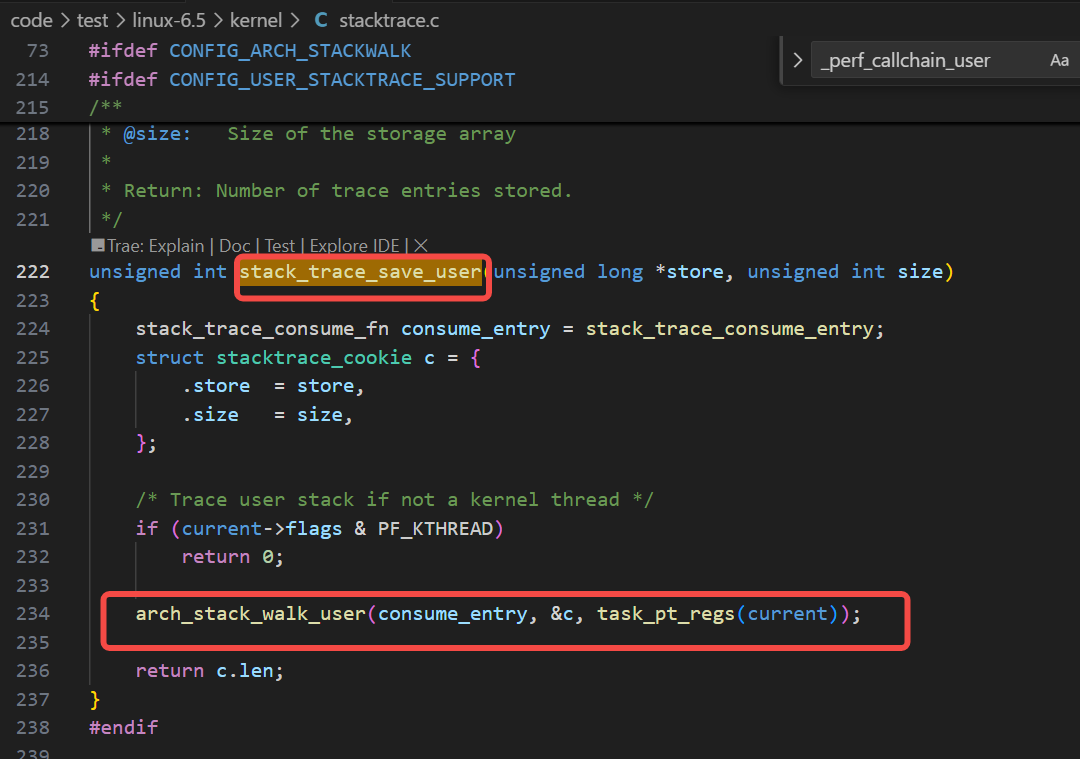
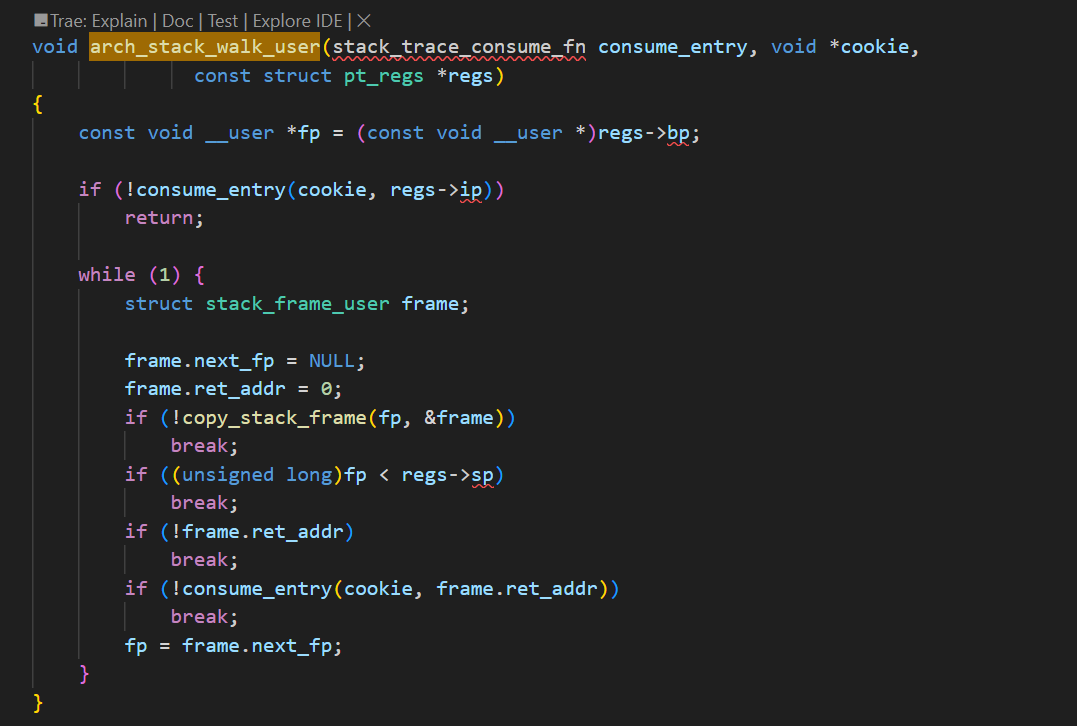
而arch_stack_walk_user函数是根据不同arch进行不同的实现的,对于x86平台而言,如下实现:
3.4 ftrace的打印elf路径及偏移的相关逻辑细节
这块逻辑细节的关键函数是seq_print_user_ip,我们看一下seq_print_user_ip函数被调用的地方及相关逻辑:
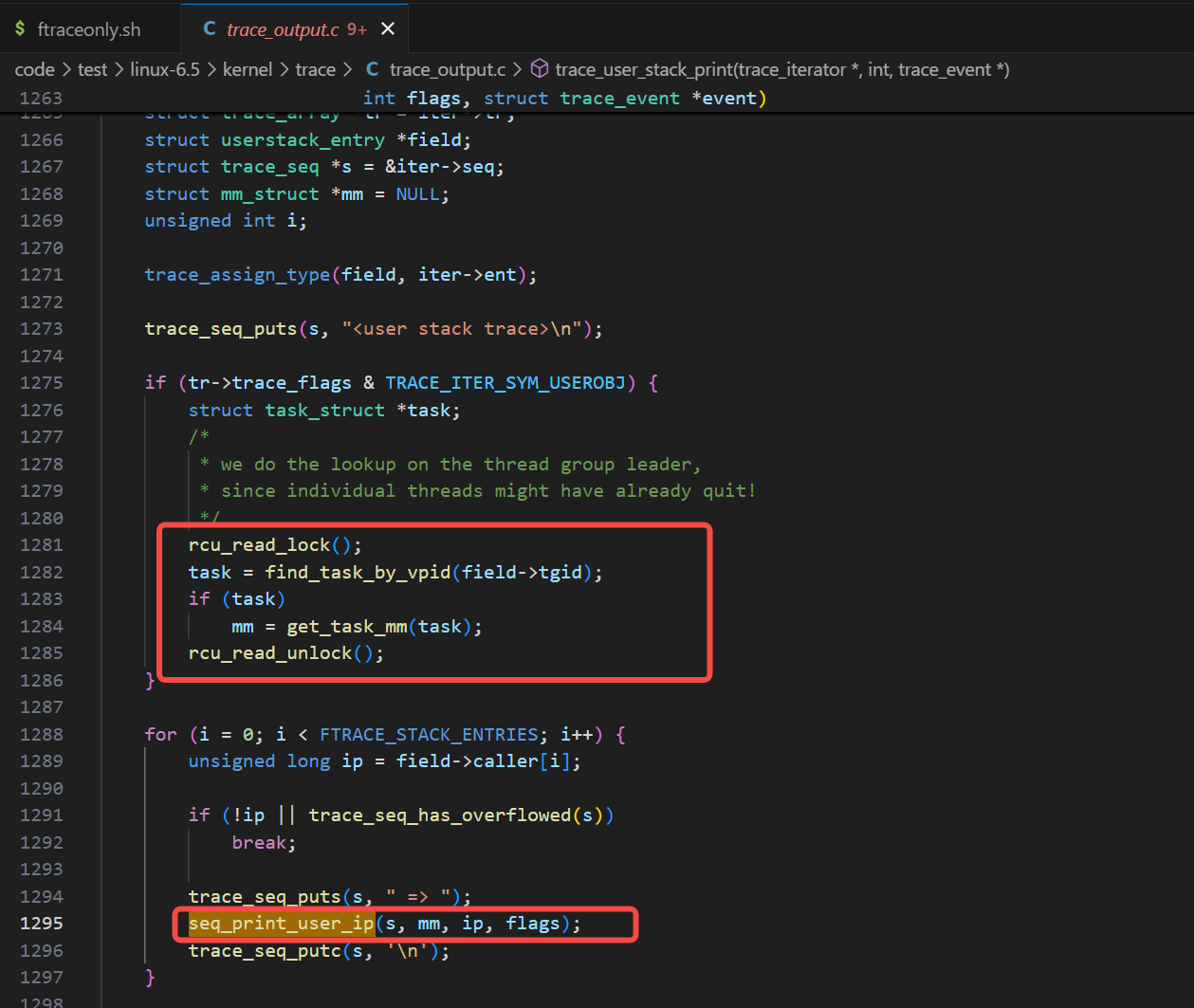
如上图可以看到,显示通过进程id拿到对应task的struct mm_struct* mm,然后传入给seq_print_user_ip函数,我们看seq_print_user_ip函数是如何实现的:
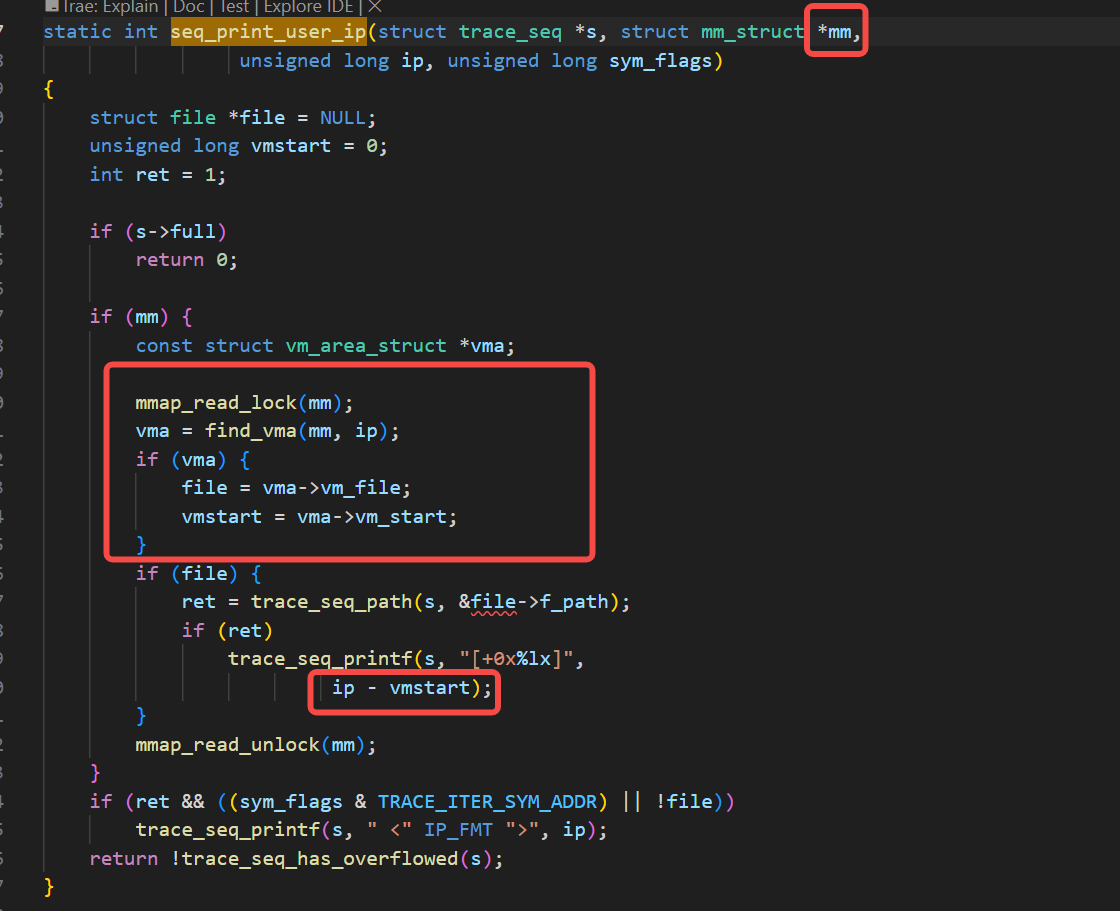
可以如上图看到,它的实现还是比较清晰易懂的,根据mm找ip这个va对应的vm_area_struct条目,再根据找到的vm_area_struct条目算出offset,并打印条目对应的文件路径f_path及offset。
3.5 通过stack_trace_save_user函数来抓取用户栈
下面是根据上面 2.2 一节里的源码,加上stack_trace_save_user函数来抓取用户栈后的代码:
void init_get_perf_callchain_func(void)
{
int ret;
struct kprobe kp;
memset(&kp, 0, sizeof(kp));
kp.symbol_name = "perf_callchain_user";
kp.pre_handler = NULL;
kp.addr = NULL; // 作为强调,提示使用symbol_name
ret = register_kprobe(&kp);
if (ret < 0) {
printk("register_kprobe fail!\n");
return;
}
printk("register_kprobe succeed!\n");
_perf_callchain_user = (void*)kp.addr;
unregister_kprobe(&kp);
}
void init_stack_trace_save_user_func(void)
{
int ret;
struct kprobe kp;
memset(&kp, 0, sizeof(kp));
kp.symbol_name = "stack_trace_save_user";
kp.pre_handler = NULL;
kp.addr = NULL; // 作为强调,提示使用symbol_name
ret = register_kprobe(&kp);
if (ret < 0) {
printk("register_kprobe fail!\n");
return;
}
printk("register_kprobe succeed!\n");
_stack_trace_save_user = (void*)kp.addr;
unregister_kprobe(&kp);
}
static void get_user_stack(
struct pt_regs *regs, struct task_struct *t)
{
struct perf_callchain_entry_ctx ctx;
bool buser = false;
int i;
struct userstack_entry *entry;
u64 timestart, timestop;
struct perf_callchain_entry* pentry = _pentry[smp_processor_id()];
if (t->pid == 0) {
return;
}
if (t->flags & PF_KTHREAD) {
return;
}
//printk(KERN_INFO "currcpu[%d]currpid[%d]pid[%d]addr[0x%lx] value is changed\n",
// smp_processor_id(), current->pid, watchpid, va);
//dump_stack();
//printk(KERN_INFO "Dump stack from sample_hbp_handler\n");
if (regs) {
int j;
for (j = 0; j < 1; j++) {
buser = user_mode(regs) ? true : false;
//printk("regs usermode[%d]\n", buser?1:0);
ctx.entry = pentry;
ctx.max_stack = PERF_MAX_STACK_DEPTH;
ctx.nr = pentry->nr = 0;
ctx.contexts = 0;
ctx.contexts_maxed = false;
timestart = getmonons();
_perf_callchain_user(&ctx, regs);
timestop = getmonons();
printk("_perf_callchain_user timespan=%llu\n", timestop - timestart);
if (pentry->nr == 1) {
for (i = 0; i < pentry->nr; i++) {
printk("cpu[%d]nr[%d]i[%d]pid[%d]comm[%s]buser[%u]_perf_callchain_user-ip[0x%llx]\n",
smp_processor_id(), pentry->nr, i, t->pid, t->comm, buser?1:0,
pentry->ip[i]);
}
}
pentry->nr = 0;
timestart = getmonons();
pentry->nr = _stack_trace_save_user((unsigned long*)pentry->ip, PERF_MAX_STACK_DEPTH);
timestop = getmonons();
printk("stack_trace_save_user timespan=%llu\n", timestop - timestart);
if (pentry->nr == 1) {
for (i = 0; i < pentry->nr; i++) {
printk("cpu[%d]nr[%d]i[%d]pid[%d]comm[%s]buser[%u]stack_trace_save_user-ip[0x%llx]\n",
smp_processor_id(), pentry->nr, i, t->pid, t->comm, buser?1:0,
pentry->ip[i]);
}
}
}
}
else {
printk("regs is NULL\n");
}
}大家可以去上面代码里找stack_trace_save_user相关的逻辑。
实测下来stack_trace_save_user的函数性能和perf_callchain_user的函数性能是一致的。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











