






最近在学习大数据相关的知识,学到了HBase,对其中的随机实时读写不是很明白,从网上翻了翻文章,有两篇不错的,粘贴过来分享给大家。
第二篇文章在这:
Apache HBase I/O - HFile - Cloudera Blog
以下是英文翻译:
介绍
Apache HBase 是 Hadoop 开源、分布式、版本化存储管理器,非常适合随机、实时读/写访问。
等等?随机,实时读/写访问? 这怎么可能? Hadoop 不就是一个顺序读/写、批处理系统吗? 是的,我们在谈论同一件事,在接下来的几段中,我将向您解释 HBase 如何实现随机 I/O、它如何存储数据以及 HBase 的 HFile 格式的演变。
Apache Hadoop I/O 文件格式
Hadoop 带有 SequenceFile[1] 文件格式,您可以使用它来附加键/值对,但由于 hdfs 仅附加功能,该文件格式不允许修改或删除插入的值。唯一允许的操作是追加,如果你想查找指定的键,你必须通读文件直到找到你的键。
如您所见,您被迫遵循顺序读/写模式……但是如何在此基础上构建像 HBase 这样的随机、低延迟读/写访问系统?
为了帮助您解决这个问题,Hadoop 有另一种文件格式,称为 MapFile[1],它是 SequenceFile 的扩展。 MapFile 实际上是一个包含两个 SequenceFile 的目录:数据文件“/data”和索引文件“/index”。 MapFile 允许您附加排序的键/值对和每 N 个键(其中 N 是可配置的间隔),它在索引中存储键和偏移量。这允许非常快速的查找,因为不是扫描所有记录,而是扫描条目较少的索引。一旦你找到了你的块,你就可以跳到真正的数据文件中。
MapFile 很好,因为您可以快速查找键/值对,但仍然存在两个问题:
如何删除或替换键/值?
当我的输入未排序时,我无法使用 MapFile。
HBase 和 MapFile
HBase Key 包括:行键、列族、列限定符、时间戳和类型。

为了解决删除键/值对的问题,想法是使用“类型”字段将键标记为已删除(墓碑标记)。解决替换键/值对的问题只是选择较晚的时间戳(正确的值在文件末尾附近,append 仅表示最后插入的在末尾附近)。
为了解决“无序”键问题,我们将最后添加的键值保留在内存中。当您达到阈值时,HBase 会将其刷新到 MapFile。通过这种方式,您最终将排序的键/值添加到 MapFile。
HBase 正是这样做的[2]:当您使用 table.put() 添加值时,您的键/值将添加到 MemStore(在引擎盖下 MemStore 是一个已排序的 ConcurrentSkipListMap)。当达到 per-memstore 阈值 (hbase.hregion.memstore.flush.size) 或 RegionServer 为 memstores (hbase.regionserver.global.memstore.upperLimit) 使用过多内存时,数据将作为新的 MapFile 刷新到磁盘上.
每次刷新的结果都是一个新的 MapFile,这意味着要找到一个键,您必须在多个文件中进行搜索。这需要更多资源并且可能更慢。
每次发出 get 或 scan 时,HBase 都会扫描每个文件以查找结果,为了避免跳过太多文件,有一个线程会检测何时达到一定数量的文件(hbase.hstore.compaction 。最大限度)。然后它会尝试在称为压缩的过程中将它们合并在一起,该过程基本上会创建一个新的大文件作为文件合并的结果。
HBase 有两种类型的压缩:一种称为“次要压缩”,它只是将两个或多个小文件合并为一个,另一种称为“主要压缩”,它选择区域中的所有文件,合并它们并执行一些清理。在主要压缩中,删除的键/值被删除,这个新文件不包含墓碑标记,并且所有重复的键/值(替换值操作)都被删除。
在 0.20 版本之前,HBase 使用 MapFile 格式来存储数据,但在 0.20 中引入了新的 HBase 特定 MapFile (HBASE-61)。
HFile v1
在 HBase 0.20 中,MapFile 被 HFile 取代:HBase 的特定映射文件实现。这个想法与 MapFile 非常相似,但它增加了比普通键/值文件更多的功能。支持元数据和索引等功能现在保存在同一个文件中。
数据块包含作为 MapFile 的实际键/值。对于每个“块关闭操作”,第一个键被添加到索引中,并在 HFile 关闭时写入索引。
Meta 块旨在保存大量数据,其键为字符串,而 FileInfo 是一个简单的 Map,首选用于键和值都是字节数组的小信息。 Regionserver 的 StoreFile 使用 Meta-Blocks 来存储 Bloom Filter,以及用于 Max SequenceId、Major compaction key 和 Timerange 信息的 FileInfo。如果密钥不存在(布隆过滤器)、文件太旧(最大序列 ID)或文件太新(时间范围)而无法包含我们正在查找的内容,则此信息可用于避免读取文件为了。

HFile v2
在 HBase 0.92 中,HFile 格式略有更改 (HBASE-3857) 以提高存储大量数据时的性能。 HFile v1 的主要问题之一是您需要在内存中加载所有单体索引和大型布隆过滤器,而为了解决这个问题,v2 引入了多级索引和块级布隆过滤器。因此,HFile v2 具有改进的速度、内存和缓存使用率。

这个 v2 的主要特点是“内联块”,其思想是将索引和布隆过滤器每个块分开,而不是将整个文件的整个索引和布隆过滤器放在内存中。通过这种方式,您可以将所需的内容保存在 ram 中。
区块头现在包含一些信息:“Block Magic”字段被替换为“Block Type”字段,该字段描述了区块“Data”、Leaf-Index、Bloom、Metadata、Root-Index等的内容。另外三个添加了字段(压缩/未压缩大小和偏移 prev 块)以允许快速向后和向前搜索。
数据块编码
由于键已排序并且通常非常相似,因此可以设计出比通用算法更好的压缩。
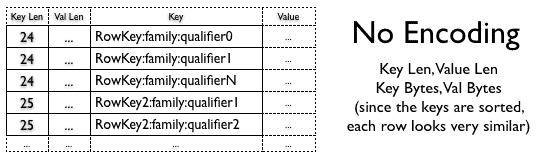
HBASE-4218 试图解决这个问题,在 HBase 0.94 中,您可以在几种不同的算法之间进行选择:前缀和差异编码。
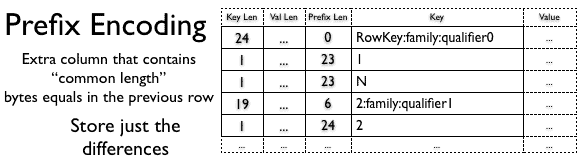
Prefix Encoding 的主要思想是只存储公共前缀一次,因为行已排序并且开头通常相同。

Diff Encoding 进一步推动了这一概念。 Diff Encoder 不是将密钥视为不透明的字节序列,而是拆分每个密钥字段,以便以更好的方式压缩每个部分。这是列族存储一次。如果键长度、值长度和类型与前一行相同,则省略该字段。此外,为了增加压缩,存储的时间戳存储为与前一个的差异。
请注意,此功能默认关闭,因为写入和扫描速度较慢,但缓存了更多数据。要启用此功能,您可以设置 DATA_BLOCK_ENCODING = PREFIX |差异 |表信息中的 FAST_DIFF。
HFile v3
HBASE-5313 包含一项建议,以重构 HFile 布局以改进压缩:
在块开始时将所有键打包在一起,在块结束时将所有值打包在一起。通过这种方式,您可以使用两种不同的算法来压缩键和值。
使用 XOR 与第一个值压缩时间戳,并使用 VInt 而不是 long。
此外,正在研究柱状格式或柱状编码,请查看 Doug Cutting 的 AVRO-806 中的柱状文件格式。
正如您可能看到的,进化的趋势是更加了解文件包含的内容,以获得更好的压缩或更好的位置感知,从而转化为更少的数据从磁盘写入/读取。更少的 I/O 意味着更快的速度!















 3990
3990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









