







特大注意:java连接的hbase都是单机版本的在192.168.244.134上。
伪集群的在192.168.244.133上
mysql是有锁的。
hive不能说是数据库,是OlAP的。
对大数据进行实时的读写操作的时候,我们用到hbase的。
hbase可以随机写的,hive不支持随机写。
hdfs是不支持随机写的。
基本是k和v存储。
hbase主要是实现了c和a的。
---
hbase加了时间戳了,做update。
删除的话就是,也加时间戳,标记是删除。
hbase允许10亿行和百万列。
一、HBase支持随机写
HBase的读写操作还是借助HDFS完成,要完成随机写,根本上还是需要符合HDFS的特性!
HDFS只支持追加写!
随机的操作: Update+Delete 借助 追加写+时间戳(版本号)
只允许客户端查询时返回时间戳最新的数据!
二、 HBase支持海量数据的实时读写
①分布式
②索引,LSM树
③kv
④吃内存
⑤列式存储
⑥布隆过滤器(查询)
三、HBase是什么
HBase是基于hadoop的数据库!
提供一个十亿级行*百万级列级别的表存储,对表中的数据提供实时的随机读写操作!
hbase可以做实时的读写。
10亿万级别的行 百万级别的列 可以的。
---01-04---
hive没有数据是存的\n。
hbase没有的话存的是什么都不存的。
---05---
都有的key都是排序的,我们可以二分查找的。
hbase是分布式的,你可以启动多个regionserver的。
服务端是接受客户端的读写请求的,如果客户端的并发度很高,则需要增加服务端的节点。regionServer,多添加regionServer可以提高系统的扛并发的能力的。
优缺点。
Hbase不支持表的关联操作,是nosql的。
列的存储,同一个列,以region存在不同的服务器,减少负担。

查数据都是通过regionServer查询的。
---06---
直播吧实时查询数据的。
hbase适合实时场景并且是高并发的,不适合分析。
hive适合分析,但是不适合做随机的写入操作。
hive适合读写,但是不适合分析。
phonex引擎,弥补缺点。
namespace是相当于数据库。
默认的情况下按照字典的顺序排序和检索的。
列族定义的越少越好的。

hbase是一个key但是value是多个版本的。
一个region下的列族构成stroe对象。
数据模型:
建表只声明列族,列是插入数据指定的。
一个region只能对应一个regionServer,但是一个regionServer可以对应多个region。

region分配给regionerver的,一个region对应一个regionserver,一个regionServer多个region。
---07---
几个列族就有几个store。
hbase的安装,目前我先不安装了,弄下一个简单的。

一个regionServer挂了,mater就会把region分给新的regionServer。

元数据是存在zookeeper里面的。
---08---
安装:我们用自己的最简单的新,先不安装了。
hbase先学习下,就不安装了,我之前在安装过伪分布式的,在192.168.244.133这个机器上,这个是在本地的。
https://blog.csdn.net/qq_28764557/article/details/109913185
---09-13---
看下浏览器的页面:http://192.168.244.133:60010/master-status
http://192.168.244.134:16010/master-status

第一个是命名空间,第二个是表名。
默认是两张表,第一个是保存用户表和region的对应信息,第二个是用户自己创建的namaspace的信息。
都是存在hdfs上的,进入hdfs上:

可以看到启动了三个resigonServer。
1.默认有两张系统表
hbase:meta: 保存的是用户的表和region的对应信息
hbase:namespace: 保存的是用户自己创建的namespace的信息
2.hbase中的对象的表现形式
namespace库以目录的形式存放在 /HBase/data中
表是以子目录的形式存在在 /HBase/data/库名 中
region也是以子目录的形式存在 /HBase/data/库名/表名 中
列族也是以子目录的形式存在 /HBase/data/库名/表名/region 中
数据以文件的形式存放在 /HBase/data/库名/表名/region/列族 目录中看下系统表在hsfs上是怎么存储的?
打开hdfs:http://192.168.244.133:50070/explorer.html#/

对我们最有用的就是data这个目录。


这个代表mate表和namaespace表。
一般数据才是文件,剩下都是目录。
我们看下什么是region

如何验证呢?

region是时间戳。

1是版本号
1588230740是region
列族:

看图:库是hbase 表是meta region是188... 列族是info。
列族有store对象,列族的数据就是文件。

列名是动态生成的。
列名是动态生成的。
---14---

加入到环境变量。
![]()
HBase是什么
HBase是基于hadoop的数据库!
提供一个十亿级行*百万级列级别的表存储,对表中的数据提供实时的随机读写操作!---15---
命令:举例,命令是分组的
输入help:


---16---
表操作:


第一个命令:list
第二个命令:help create
第三个命令:

第四个命令:list_namespace
第五个命令:list_namespace_tables 'hbase' 其中hbase是namespace
第六个命令:create_namespace 'ns1'
第七个命令:create 'ns1:t1' ,'cf1','cf2' 其中t1是表 cf1 cf2是列族
第八个命令:
![]()
第九个命令:增加列族要改变表的状态
![]()
第十个命令:统计表的行数

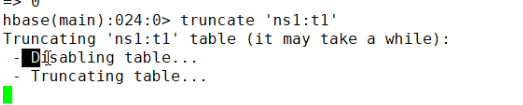
第十一个命令:清空表
第十二个命令:get_splits 'ns1_t1' 查看表切分了几个region

第十三个命令:



第十四个命令:
disable 'ns1:t1'
drop 'ns1:t1'
drop_namespace 'ns1'
---17---

第一个命令:
我们先描述下表:


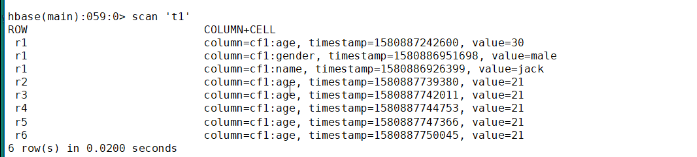
解读下这句话:t1是表名,r1是rowKey,cf1是列族,name是列,jack是值。

put存在是插入,不存在是更新。

第二个命令:按照时间戳去更新的 旧的数据是还在的 没有删除 重写的话可能会删除的

第三个命令:

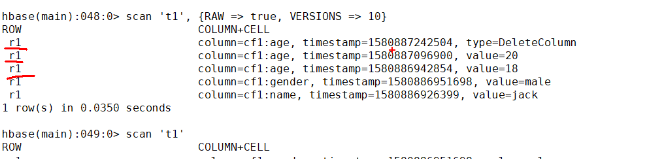
第四个命令:scan指定表名称,会把表的数据都扫描出来的。

RAW为true会扫描到原始的数据,VERSIONS=>10代表是10个版本的数据。
---18---
scan的高级用法:
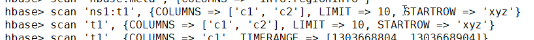


---19---
get是一种特殊的scan

---20---
第一步要找regionServer。

我们看下t1表的region是只有一个的。
这里点进去。

看到regionServer。

第一个箭头是regionServer的region。
一个scan请求会拆分成若干个get请求的。

看到列族。

我们载点进去发现是没有数据的。说明是在写的缓存中的。
WAL是预写日志,是用来崩溃恢复数据的。
每个regionServer都会构建一个WAL对象的。



之后:
挂掉了一个regionServer之后master还是会给你分配的。
之前的数据是在MemStore里面的,再次是否能够查询到呢?
刷写表的数据到staorFile:
---22---
宏观写流程:


我们这个表可以查看region在哪个regionServer中。


流程:

对于第一条,我们看下zookeeper的配置。
程序启起来之后,会在zookeeper创建一个叫做hbase的节点。

---23---
微观的写流程:
1.写流程,
try {
// ------------------------------------
// STEP 1. Try to acquire as many locks as we can, and ensure
// we acquire at least one.
尝试获取尽可能多的锁,至少得获取一个
// ----------------------------------
// ------------------------------------
// STEP 2. Update any LATEST_TIMESTAMP timestamps
跟新任意最近的时间,在插入记录时,timestamp是可选的,一旦不提供,使用服务器最近的时间戳来作为
timestamp
// ----------------------------------
// CP(coprocessor): 协处理器(类似mysql中的trigger(触发器))。 通常有两个方法! 一个方法是在被触发之前做xxx事
// 另一个方法是在触发之后做xxx事!
// calling the pre CP hook for batch mutation
// ------------------------------------
// STEP 3. Build WAL edit
构建WAL对象
// ----------------------------------
// -------------------------
// STEP 4. Append the final edit to WAL. Do not sync wal.
将最新的编辑操作添加到WAL对象的buffer(WAL对象内存中的一块区域)中,buffer中新添加的
数据暂时先不同步到wal的磁盘日志文件中!
// -------------------------
获取最新的MVCC(multi-version concurency control)号
// ------------------------------------
// Acquire the latest mvcc number
// ----------------------------------
// ------------------------------------
// STEP 5. Write back to memstore
// Write to memstore. It is ok to write to memstore
// first without syncing the WAL because we do not roll
// forward the memstore MVCC.
讲数据写入到memstore,当前我们的数据只是在WAL对象的buffer中,还没有sync到磁盘文件!
此时就把数据写入到memstore,是完全没问题的!因为我们还没有滚动mvcc版本号!
The MVCC will be moved up when
// the complete operation is done. These changes are not yet
// visible to scanners till we update the MVCC. The MVCC is
// moved only when the WAL sync is complete.
只有当讲WAL中的buffer中的数据同步到磁盘文件后,MVCC号才会滚动!
在MVCC没有滚动期间,向memstore中写的数据,scanner是查不到的!
// ----------------------------------
// -------------------------------
// STEP 6. Release row locks, etc.
把行锁释放!
// -------------------------------
// -------------------------
// STEP 7. Sync wal.
讲WALbuffer中的数据sync到磁盘
// -------------------------
if (txid != 0) {
syncOrDefer(txid, durability);
}
doRollBackMemstore = false;
// calling the post CP hook for batch mutation
// 调用协处理器的后置钩子程序
// ------------------------------------------------------------------
// STEP 8. Advance mvcc. This will make this put visible to scanners and getters.
移动mvcc版本号,移动之后,scan和get操作就可以查询到此条数据
// ------------------------------------------------------------------
if (writeEntry != null) {
mvcc.completeAndWait(writeEntry);
writeEntry = null;
} else if (isInReplay) {
// ensure that the sequence id of the region is at least as big as orig log seq id
mvcc.advanceTo(mvccNum);
}
for (int i = firstIndex; i < lastIndexExclusive; i ++) {
if (batchOp.retCodeDetails[i] == OperationStatus.NOT_RUN) {
batchOp.retCodeDetails[i] = OperationStatus.SUCCESS;
}
}
// ------------------------------------
// STEP 9. Run coprocessor post hooks. This should be done after the wal is
// synced so that the coprocessor contract is adhered to.
// ------------------------------------
if (!isInReplay && coprocessorHost != null) {
for (int i = firstIndex; i < lastIndexExclusive; i++) {
// only for successful puts
if (batchOp.retCodeDetails[i].getOperationStatusCode()
!= OperationStatusCode.SUCCESS) {
continue;
}
Mutation m = batchOp.getMutation(i);
if (m instanceof Put) {
coprocessorHost.postPut((Put) m, walEdit, m.getDurability());
} else {
coprocessorHost.postDelete((Delete) m, walEdit, m.getDurability());
}
}
}
success = true;
return addedSize;
} finally {
// if the wal sync was unsuccessful, remove keys from memstore
// 在第七步,讲wal buffer中的数据同步到磁盘失败时,回滚已经写入到memstore中的cell,同时保持MVCC不变
if (doRollBackMemstore) {
for (int j = 0; j < familyMaps.length; j++) {
for(List<Cell> cells:familyMaps[j].values()) {
rollbackMemstore(cells);
}
}
if (writeEntry != null) mvcc.complete(writeEntry);
} else {
this.addAndGetGlobalMemstoreSize(addedSize);
if (writeEntry != null) {
mvcc.completeAndWait(writeEntry);
}
}
}当前的客户端可能接受多个客户端的同时写的请求的。需要加锁。
协处理器。
自定义协处理器:https://blog.csdn.net/qq_38007708/article/details/90339985
总结: 向region中写入数据时
①获取到锁
②生成数据的时间戳
③构建WAL对象
④讲数据写入到WAL的buffer中
⑤讲数据写入到memstore中
⑥将数据从WAL的buffer,sync到磁盘
⑦如果成功,滚动MVCC,客户端可见,写成功
⑧否则,回滚之前已经写入到memstore中的数据,写入失败先写WAL再写memstore。
丢数据:WAL持久化失败则回滚就是写失败了。
---24---















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









