







最短路径算法
1. Dijkstra算法(迪克斯特拉算法-求单源最短路径)
算法描述:
1.将所有顶点标记为未访问。创建一个未访问顶点的集合。
2.为每个顶点分配一个临时距离值
(1)初始顶点将其距离设置为0
(2)其余结点默认距离为∞
3.每次选择最小临时距离的未访问顶点,作为新的当前顶点
4.对于当前顶点,遍历其所有未访问的邻居,并更新它们的临时距离为更小
5.当前顶点的邻居处理完成后,把它从未访问集合中删除
算法实现:
顶点类:
package com.zsh.图.domain;
import java.util.List;
import java.util.Objects;
/**
* @version v1.0
* @ClassName: Vertex
* @Description:顶点类
* @Author: zsh
*/
public class Vertex {
public String name; //顶点的名称
public List<Edge> edges; //顶点关联的边
public boolean visited = false; //用来记录是否被访问过
public int inDegree; //记录顶点的入度
public int status; // 0表示未访问,1表示访问中用来检测环,2表示已访问
public int dist = INF; //距离,默认不指定的时候是∞
public Vertex pre = null; //当前顶点的来时的顶点
private static Integer INF = Integer.MAX_VALUE; //∞
public Vertex(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<Edge> getEdges() {
return edges;
}
public void setEdges(List<Edge> edges) {
this.edges = edges;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Vertex vertex = (Vertex) o;
return Objects.equals(name, vertex.name);
}
@Override
public int hashCode() {
return Objects.hash(name);
}
@Override
public String toString() {
return "Vertex{" +
"name='" + name + '\'' +
", dist=" + dist +
'}';
}
}
边集类
package com.zsh.图.domain;
/**
* @version v1.0
* @ClassName: Edge
* @Description: 边类
* @Author: zsh
*/
public class Edge {
public Vertex linked; //终点指向的顶点
public int weight; //权重
public String name; //边的名字
public boolean removed; //标记该边是否已经被移除
public Edge(Vertex linked, int weight) {
this.linked = linked;
this.weight = weight;
}
public Edge(Vertex linked) {
this(linked, 1);
this.removed = false;
}
public Edge(Vertex linked,String name) {
this(linked, 1);
this.name = name;
this.removed = false;
}
}
实现类:
package com.zsh.图.algorithm;
import com.zsh.图.domain.Edge;
import com.zsh.图.domain.Vertex;
import java.util.ArrayList;
import java.util.List;
/**
* @version v1.0
* @ClassName: Dijkstra
* @Description:迪克斯特拉算法(单源最短路径)
* @Author: zsh
*/
public class Dijkstra {
public static void main(String[] args) {
Vertex v1 = new Vertex("v1");
Vertex v2 = new Vertex("v2");
Vertex v3 = new Vertex("v3");
Vertex v4 = new Vertex("v4");
Vertex v5 = new Vertex("v5");
Vertex v6 = new Vertex("v6");
v1.edges = List.of(new Edge(v3, 9), new Edge(v2, 7), new Edge(v6, 14));
v2.edges = List.of(new Edge(v4, 15));
v3.edges = List.of(new Edge(v4, 11), new Edge(v6, 2));
v4.edges = List.of(new Edge(v5, 6));
v5.edges = List.of();
v6.edges = List.of(new Edge(v5, 9));
List<Vertex> graph = List.of(v1, v2, v3, v4, v5, v6);
dijkstra(graph, v1);
}
/**
* 迪克斯特拉算法
* @param graph
* @param source
*/
public static void dijkstra(List<Vertex> graph, Vertex source) {
// 1.将所有顶点标记为未访问,创建一个未访问的集合
ArrayList<Vertex> list = new ArrayList<>(graph);
// 2. 为每个顶点分配一个临时距离值
source.dist = 0;
while (!list.isEmpty()) {
// 3. 选取最小临时距离的未访问顶点,作为新的当前结点
Vertex cur = chooseMinDistVertex(list);
// 4. 更新当前顶点邻居距离
updateNeighboursDist(cur);
// 5.移除当前结点
list.remove(cur);
cur.visited = true;
}
printInfo(graph);
}
// 打印信息
private static void printInfo(List<Vertex> graph) {
List<List<Vertex>> path = getPath(graph);
int i = 0;
for (List<Vertex> paths : path) {
System.out.println(graph.get(i).name+" "+paths + " "+ graph.get(i).dist);
i++;
}
}
/**
* 收集每个顶点来时的路径信息
* @param graph
* @return
*/
private static List<List<Vertex>> getPath(List<Vertex> graph) {
List<List<Vertex>> res = new ArrayList<>();
for (Vertex vertex : graph) {
List<Vertex> list = new ArrayList<>();
Vertex pre = vertex.pre;
while (pre != null) {
list.add(pre);
pre = pre.pre;
}
res.add(list);
}
return res;
}
/**
* 更新邻居顶点的距离
* @param cur
*/
private static void updateNeighboursDist(Vertex cur) {
for (Edge edge : cur.edges) {
Vertex neigh = edge.linked;
//如果还没有访问过邻居顶点才进行后续操作
if (!neigh.visited) {
int dist = cur.dist + edge.weight;
if (dist < neigh.dist) {
neigh.dist = dist; //更新距离
neigh.pre = cur; //更新来时的顶点信息
}
}
}
}
/**
* 选取一个距离最小的顶点
* @param list
* @return
*/
private static Vertex chooseMinDistVertex(ArrayList<Vertex> list) {
Vertex min = list.get(0);
for (int i = 1; i < list.size(); i++) {
if (list.get(i).dist < min.dist) {
min = list.get(i);
}
}
return min;
}
}
在上述代码实现中,我们发现在选取距离最小顶点里,对顶点集合进行了从头到尾的遍历,时间复杂度为O(n),我们可以用小根堆(优先级队列)对代码进行优化,使时间复杂度降低到O(logn)。改进的代码如下:
package com.zsh.图.algorithm;
import com.zsh.图.domain.Edge;
import com.zsh.图.domain.Vertex;
import java.util.*;
/**
* @version v1.0
* @ClassName: Dijkstra2
* @Description:
* @Author: zsh
*/
public class Dijkstra2 {
public static void main(String[] args) {
Vertex v1 = new Vertex("v1");
Vertex v2 = new Vertex("v2");
Vertex v3 = new Vertex("v3");
Vertex v4 = new Vertex("v4");
Vertex v5 = new Vertex("v5");
Vertex v6 = new Vertex("v6");
v1.edges = List.of(new Edge(v3, 9), new Edge(v2, 7), new Edge(v6, 14));
v2.edges = List.of(new Edge(v4, 15));
v3.edges = List.of(new Edge(v4, 11), new Edge(v6, 2));
v4.edges = List.of(new Edge(v5, 6));
v5.edges = List.of();
v6.edges = List.of(new Edge(v5, 9));
List<Vertex> graph = List.of(v1, v2, v3, v4, v5, v6);
dijkstra(graph, v1);
}
/**
* 迪克斯特拉算法
* @param graph
* @param source
*/
public static void dijkstra(List<Vertex> graph, Vertex source) {
// 1.创建一个小顶堆
PriorityQueue<Vertex> queue = new PriorityQueue<>(Comparator.comparingInt(value -> value.dist));
// 2. 为每个顶点分配一个临时距离值
source.dist = 0;
for (Vertex vertex : graph) {
queue.offer(vertex);
}
while (!queue.isEmpty()) {
// 3. 选取最小临时距离的未访问顶点,作为新的当前结点
Vertex cur = queue.peek();
// 4. 更新当前顶点邻居距离
updateNeighboursDist(cur,queue);
// 5.移除当前结点
queue.remove(cur);
cur.visited = true;
}
printInfo(graph);
}
// 打印信息
private static void printInfo(List<Vertex> graph) {
List<List<Vertex>> path = getPath(graph);
int i = 0;
for (List<Vertex> paths : path) {
System.out.println(graph.get(i).name+" "+paths + " "+ graph.get(i).dist);
i++;
}
}
/**
* 收集每个顶点来时的路径信息
* @param graph
* @return
*/
private static List<List<Vertex>> getPath(List<Vertex> graph) {
List<List<Vertex>> res = new ArrayList<>();
for (Vertex vertex : graph) {
List<Vertex> list = new ArrayList<>();
Vertex pre = vertex.pre;
while (pre != null) {
list.add(pre);
pre = pre.pre;
}
res.add(list);
}
return res;
}
/**
* 更新邻居顶点的距离
*
* @param cur
* @param queue
*/
private static void updateNeighboursDist(Vertex cur, PriorityQueue<Vertex> queue) {
for (Edge edge : cur.edges) {
Vertex neigh = edge.linked;
//如果还没有访问过邻居顶点才进行后续操作
if (!neigh.visited) {
int dist = cur.dist + edge.weight;
if (dist < neigh.dist) {
neigh.dist = dist; //更新距离
neigh.pre = cur; //更新来时的顶点信息
queue.offer(neigh); //将新的顶点信息重新放到堆中
}
}
}
}
}
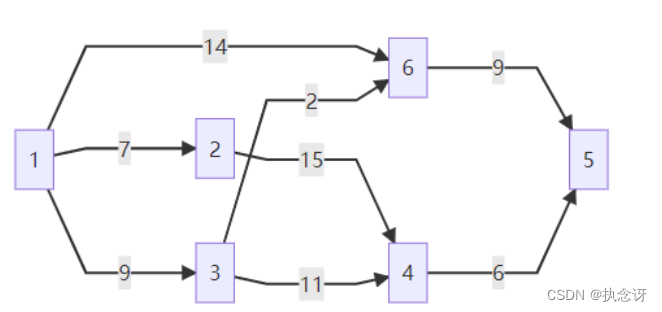
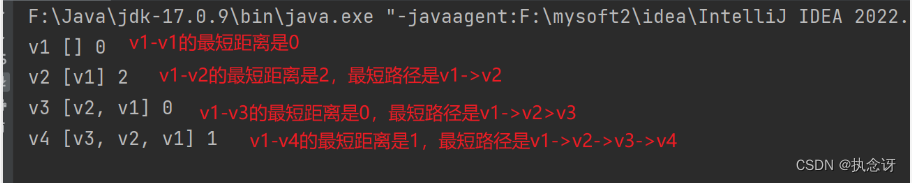
用上述代码实现上图从V1顶点寻找到各个顶点的最短路径。运行结果如下所示:
在这里插入图片描述

Dijkstra算法存在的缺点:
1.无法处理带有负权边的图: 迪克斯特拉算法要求所有边的权重都为非负值。如果图中存在负权边,该算法可能产生不正确的结果。负权边可能导致算法陷入无限循环,因为每次迭代都会选择具有最小距离的节点,而负权边可以使得路径长度无限减小。
2.不适用于含有负权环的图: 如果图中存在负权环,迪克斯特拉算法也会失败。负权环是一个环路,使得环路上的所有边的权重之和为负数。在这种情况下,算法可能会陷入循环,因为它会不断尝试通过负权环来减小路径长度。
3.时间复杂度相对较高: 尽管迪克斯特拉算法在许多情况下表现良好,但其时间复杂度为O(V2)或O(V2 + E),其中V是节点数,E是边数。在稠密图中,这可能导致算法的运行时间较长。优先队列的使用可以将时间复杂度优化到O((V + E) * logV),但在特定情况下,其他算法如Bellman-Ford可能更具竞争力。
4.只适用于正权图: 迪克斯特拉算法设计用于解决非负权图的问题,因此在负权图上可能无法得到有意义的结果。
2.Bellman-Ford算法(-求单源最短路径,可以计算带负权边的图)
算法思想:
1.将起始节点的最短路径估计值设为0,其他节点的最短路径估计值设为无穷大。起始节点的前驱节点为空。
2.进行n-1轮松弛操作。在每一轮中,遍历图中的所有边,尝试通过当前已知的最短路径来改进目标节点的最短路径估计值。如果存在更短的路径,则更新目标节点的最短路径估计值和前驱节点。
3.检测负环,在进行n-1轮松弛操作后,如果还能进行松弛操作,则说明存在负环。这是因为在负权环中,可以无限次地绕环而降低路径长度。
算法实现:
package com.zsh.图.algorithm;
import com.zsh.图.domain.Edge;
import com.zsh.图.domain.Vertex;
import java.util.ArrayList;
import java.util.List;
/**
* @version v1.0
* @ClassName: BellmanFord
* @Description:
* @Author: zsh
*/
public class BellmanFord {
public static void main(String[] args) {
// 出现负边
Vertex v1 = new Vertex("v1");
Vertex v2 = new Vertex("v2");
Vertex v3 = new Vertex("v3");
Vertex v4 = new Vertex("v4");
v1.edges = List.of(new Edge(v2, 2), new Edge(v3, 1));
v2.edges = List.of(new Edge(v3, -2));
v3.edges = List.of(new Edge(v4, 1));
v4.edges = List.of();
List<Vertex> graph = List.of(v1, v2, v3, v4);
// 负环情况
/* Vertex v1 = new Vertex("v1");
Vertex v2 = new Vertex("v2");
Vertex v3 = new Vertex("v3");
Vertex v4 = new Vertex("v4");
v1.edges = List.of(new Edge(v2, 2));
v2.edges = List.of(new Edge(v3, -4));
v3.edges = List.of(new Edge(v4, 1), new Edge(v1, 1));
v4.edges = List.of();
List<Vertex> graph = List.of(v1, v2, v3, v4);*/
bellmanFord(graph, v1);
}
/**
* 贝尔曼-福特算法
*
* @param graph 图的集合
* @param source 源点
*/
private static void bellmanFord(List<Vertex> graph, Vertex source) {
source.dist = 0;
int size = graph.size();
/*n个顶点需要进行n-1轮检查即可,设置成n轮是为了检测负环*/
for (int i = 0; i < size; i++) {
// 遍历所有的顶点
for (Vertex s : graph) {
// 遍历所有的边
for (Edge edge : s.edges) {
// 得到邻居顶点
Vertex e = edge.linked;
//如果距离是∞就先不处理
if (s.dist != Integer.MAX_VALUE && s.dist + edge.weight < e.dist) {
if (i == size - 1) {
throw new RuntimeException("检测出负环");
}
e.dist = s.dist + edge.weight;
e.pre = s;
}
}
}
}
List<List<String>> list = getInfo(graph);
for (int i = 0; i < graph.size(); i++) {
System.out.println(graph.get(i).name + " " + list.get(i)+" "+graph.get(i).dist);
}
}
/**
* 获取来时的路径
*
* @param graph
* @return
*/
private static List<List<String>> getInfo(List<Vertex> graph) {
List<List<String>> res = new ArrayList<>();
for (Vertex vertex : graph) {
List<String> list = new ArrayList<>();
Vertex pre = vertex.pre;
while (pre != null) {
list.add(pre.name);
pre = pre.pre;
}
res.add(list);
}
return res;
}
}
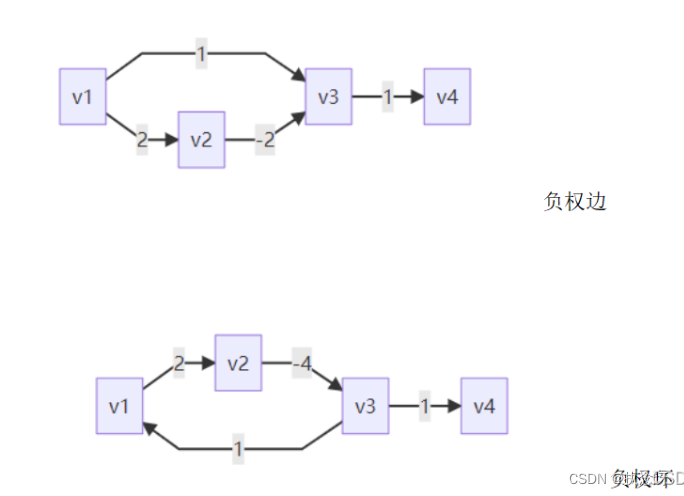
对上述一个带负权边和负权环的例子进行测试,结果如下:

通过两个运行结果我们可以发现Bellman-Ford算法也可解决带负权边的问题,但是只能检测出是否带有负权环,而不能对负权环的问题进行正确的求解。
3.Floyd-Warshall算法(弗洛伊德算法-求多源最短路径)
算法思想:
1.初始化建立一个二维数组dist,其中dist[i][j]表示节点i到节点j的最短路径长度。如果节点i到节点j没有直接的边相连,则dist[i][j]为无穷大。另外,对角线上的元素dist[i][i]为0。
2.对于每一对节点i和j,以及可能的中间节点k,检查是否存在一条路径从i到j,经过k可以缩短路径的长度。更新dist[i][j]为更短的路径长度。
3.经过上述的迭代之后,dist数组中包含了所有节点对之间的最短路径长度。
Floyd算法的时间复杂度为O(V^3),其中V是图中节点的数量。相比于迪克斯特拉算法和贝尔曼-福特算法,Floyd算法的主要优势在于它可以一次性计算出所有节点对之间的最短路径,适用于稠密图。然而,对于大规模的稀疏图,其运行时间可能相对较长。
算法实现:
package com.zsh.图.algorithm;
import com.zsh.图.domain.Edge;
import com.zsh.图.domain.Vertex;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* @version v1.0
* @ClassName: FloydWarshall
* @Description:弗洛伊德算法(多源最短路径)
* @Author: zsh
*/
public class FloydWarshall {
public static void main(String[] args) {
Vertex v1 = new Vertex("v1");
Vertex v2 = new Vertex("v2");
Vertex v3 = new Vertex("v3");
Vertex v4 = new Vertex("v4");
v1.edges = List.of(new Edge(v3, -2));
v2.edges = List.of(new Edge(v1, 4), new Edge(v3, 3));
v3.edges = List.of(new Edge(v4, 2));
v4.edges = List.of(new Edge(v2, -1));
List<Vertex> graph = List.of(v1, v2, v3, v4);
floydWarshall(graph);
}
private static void floydWarshall(List<Vertex> graph) {
int size = graph.size();
int[][] dist = new int[size][size]; //用来存放各个结点的距离
Vertex[][] pre = new Vertex[size][size]; //用来记录上一个顶点
// 1.初始化
for (int i = 0; i < size; i++) {
Vertex v = graph.get(i);
// 将当前遍历顶点的邻居顶点放入到map中
Map<Vertex, Integer> map = v.edges.stream().collect(Collectors.toMap(edge -> edge.linked, edge -> edge.weight));
for (int j = 0; j < size; j++) {
Vertex u = graph.get(j);
if (v == u) {
dist[i][j] = 0;
} else {
// 如果不是同一个顶点,如果两个顶点想通,用权重表示距离,否则距离为∞
dist[i][j] = map.getOrDefault(u, Integer.MAX_VALUE);
pre[i][j] = map.get(u) == null ? null : v;
}
}
}
// 2.借路到其他顶点
// 借助的结点vk
for (int k = 0; k < size; k++) {
// 第i行
for (int i = 0; i < size; i++) {
// 第j列
for (int j = 0; j < size; j++) {
if (dist[i][k] != Integer.MAX_VALUE &&
dist[k][j] != Integer.MAX_VALUE &&
dist[i][k] + dist[k][j] < dist[i][j]) {
dist[i][j] = dist[i][k] + dist[k][j]; //如果借助k顶点后路径距离更小,重新赋值
pre[i][j] = pre[k][j];
}
}
}
print(dist);
}
System.out.println(isornotCircle(dist));
print(pre);
}
/**
* 检查是否有负环
* 如果在对角线处发现负数,证明有负环
* @param dist
* @return
*/
private static boolean isornotCircle(int[][] dist) {
int row = dist.length;
for (int i = 0; i < row; i++) {
if (dist[i][i] < 0) {
return true;
}
}
return false;
}
/**
* 打印来时的顶点
*
* @param pre
*/
private static void print(Vertex[][] pre) {
System.out.println("-------------");
for (Vertex[] row : pre) {
System.out.println(Arrays.stream(row).map(v -> v == null ? "null" : v.name)
.map(s -> String.format("%5s", s))
.collect(Collectors.joining(",", "[", "]")));
}
}
/**
* 打印数据表
*
* @param dist
*/
private static void print(int[][] dist) {
System.out.println("-------------");
for (int[] row : dist) {
System.out.println(Arrays.stream(row).boxed()
.map(x -> x == Integer.MAX_VALUE ? "∞" : String.valueOf(x))
.map(s -> String.format("%2s", s))
.collect(Collectors.joining(",", "[", "]")));
}
}
}

运行结果如下所示:

最小生成树算法
4. Prim算法
算法思想:
Prim算法是一种用于构建最小生成树的贪心算法。最小生成树是一个包含图中所有节点的树,且树中边的权重之和最小。Prim算法的主要思想是从一个初始节点开始,选择当前节点连接的最短边,并将新节点加入到生成树中。然后,从生成树的节点中选择下一个最短的边连接到一个未加入生成树的节点,依此类推,直到生成树包含了图中的所有节点。
算法步骤:
1.初始化: 选择一个起始节点,并将其标记为已访问。
2.重复以下步骤直到生成树包含了图中的所有节点:
1).从已访问节点集合中选择一个节点,然后选择与该节点连接的最短边,且该边连接的节点未被访问。
2).将新节点加入已访问节点集合,并将该边加入生成树。
Prim算法与Dijkstra算法实现几乎一样,都是要找距离最小顶点,只不过区别就在于进行边的更新的操作,Dijkstra算法是要拿当前顶点的距离+边的权重与邻居顶点的距离比较是否要更新,而Prim算法只需要比较边的权重与邻居顶点的距离即可(唯一的实现区别),为此在找最小距离顶点的时候我只用了遍历的方式,使用优先级队列大家可根据上述Dijkstra的实现过程自行进行修改。
算法实现:
package com.zsh.图.algorithm;
import com.zsh.图.domain.Edge;
import com.zsh.图.domain.Vertex;
import java.util.ArrayList;
import java.util.List;
/**
* @version v1.0
* @ClassName: Prim
* @Description:
* @Author: zsh
*/
public class Prim {
public static void main(String[] args) {
Vertex v1 = new Vertex("v1");
Vertex v2 = new Vertex("v2");
Vertex v3 = new Vertex("v3");
Vertex v4 = new Vertex("v4");
Vertex v5 = new Vertex("v5");
Vertex v6 = new Vertex("v6");
Vertex v7 = new Vertex("v7");
v1.edges = List.of(new Edge(v2, 2), new Edge(v3, 4), new Edge(v4, 1));
v2.edges = List.of(new Edge(v1, 2), new Edge(v4, 3), new Edge(v5, 10));
v3.edges = List.of(new Edge(v1, 4), new Edge(v4, 2), new Edge(v6, 5));
v4.edges = List.of(new Edge(v1, 1), new Edge(v2, 3), new Edge(v3, 2),
new Edge(v5, 7), new Edge(v6, 8), new Edge(v7, 4));
v5.edges = List.of(new Edge(v2, 10), new Edge(v4, 7), new Edge(v7, 6));
v6.edges = List.of(new Edge(v3, 5), new Edge(v4, 8), new Edge(v7, 1));
v7.edges = List.of(new Edge(v4, 4), new Edge(v5, 6), new Edge(v6, 1));
List<Vertex> graph = List.of(v1, v2, v3, v4, v5, v6, v7);
prim(graph, v1);
}
private static void prim(List<Vertex> graph, Vertex source) {
ArrayList<Vertex> list = new ArrayList<>(graph);
source.dist = 0;
while (!list.isEmpty()) {
// 1. 选取最小临时距离的未访问顶点,作为新的当前结点
Vertex cur = chooseMinDistVertex(list);
// 2. 更新当前顶点邻居距离
updateNeighboursDist(cur);
// 3.移除当前结点
list.remove(cur);
cur.visited = true;
if (cur.pre != null) {
System.out.println("(" + cur.pre.name + "," + cur.name + ")"+"距离:"+cur.dist);
}
}
System.out.println("----------------------");
}
private static void updateNeighboursDist(Vertex cur) {
//遍历邻居
for (Edge edge : cur.edges) {
Vertex linked = edge.linked;
if (!linked.visited) {
if (edge.weight < linked.dist) {
linked.dist = edge.weight; //区别所在
linked.pre = cur;
}
}
}
}
private static Vertex chooseMinDistVertex(ArrayList<Vertex> list) {
Vertex min = list.get(0);
for (int i = 1; i < list.size(); i++) {
if (list.get(i).dist < min.dist) {
min = list.get(i);
}
}
return min;
}
}
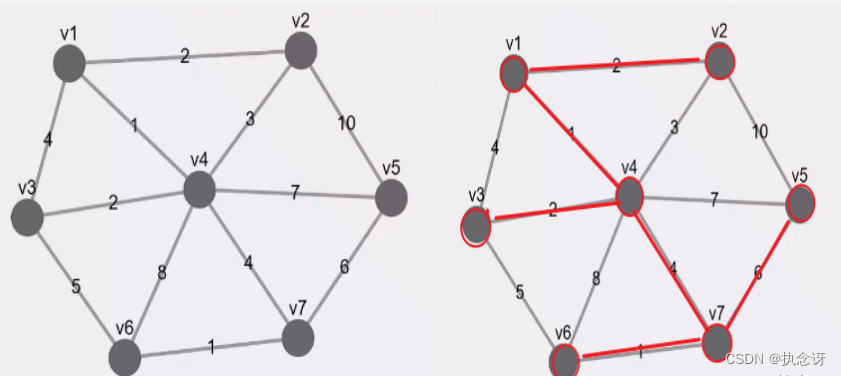
对上面左边的图生成最小生成树,最小生成树应是右图所示。代码运行结果如下:

5. Kruskal算法(克鲁斯卡尔算法)
算法思想:
Kruskal算法是一种用于构建最小生成树的贪心算法。最小生成树是一个包含图中所有节点的树,且树中边的权重之和最小。Kruskal算法的主要思想是通过不断选择图中权重最小的边,并确保所选择的边不形成环,逐步构建最小生成树。
算法步骤:
1.将每个节点看作是一个独立的树(单节点树),将所有边按权重从小到大排序,创建一个优先级队列即可。
2.从排序后的边集中选择权重最小的边 (u, v)。
3.如果边 (u, v) 不形成环,即节点 u 和节点 v 不在同一棵树中,将该边加入最小生成树。
4.合并节点 u 和节点 v 所在的两棵树。
其中在合并u,v到同一个树的过程中,使用了并查集来实现。
算法代码:
package com.zsh.图.algorithm;
import com.zsh.图.domain.Vertex;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.PriorityQueue;
/**
* @version v1.0
* @ClassName: Kruskal
* @Description:
* @Author: zsh
*/
public class Kruskal {
static class Edge implements Comparable<Edge> {
List<Vertex> vertices;
int start; //边的起始顶点索引
int end; //结尾顶点索引
int weight; //权重
public Edge(List<Vertex> vertices, int start, int end, int weight) {
this.vertices = vertices;
this.start = start;
this.end = end;
this.weight = weight;
}
public Edge(int start, int end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
@Override
public int compareTo(Edge o) {
return Integer.compare(this.weight, o.weight);
}
@Override
public String toString() {
return vertices.get(start).name + "<->" + vertices.get(end).name + "(" + weight + ")";
}
}
/**
* 并查集
*/
static class UnionFindSet {
int[] s;
int[] size; //记录每一个连通分量的个数
public UnionFindSet(int size) {
this.s = new int[size];
this.size = new int[size];
for (int i = 0; i < size; i++) {
this.s[i] = i;
this.size[i] = 1;
}
}
/***
* 找老大
* @param x
* @return
*/
public int find(int x) {
if (x == s[x]) {
return x;
}
return s[x] = find(s[x]);
}
/**
* 选出x,y的新的老大
*
* @param x 变成新的老大
* @param y
*/
public void union(int x, int y) {
if (size[x] < size[y]) {
// y作为老大,x作为小弟
s[x] = y;
size[y] += size[x]; //更新新的老大个数
} else {
// x作为老大,y作为小弟
s[y] = x;
size[x] += size[y];
}
}
@Override
public String toString() {
return Arrays.toString(s);
}
}
public static void main(String[] args) {
Vertex v1 = new Vertex("v1");
Vertex v2 = new Vertex("v2");
Vertex v3 = new Vertex("v3");
Vertex v4 = new Vertex("v4");
Vertex v5 = new Vertex("v5");
Vertex v6 = new Vertex("v6");
Vertex v7 = new Vertex("v7");
List<Vertex> vertices = List.of(v1, v2, v3, v4, v5, v6, v7);
//将所有边放到优先级队列中(小根堆)
PriorityQueue<Edge> queue = new PriorityQueue<>(List.of(
new Edge(vertices, 0, 1, 2),
new Edge(vertices, 0, 2, 4),
new Edge(vertices, 0, 3, 1),
new Edge(vertices, 1, 3, 3),
new Edge(vertices, 1, 4, 10),
new Edge(vertices, 2, 3, 2),
new Edge(vertices, 2, 5, 5),
new Edge(vertices, 3, 4, 7),
new Edge(vertices, 3, 5, 8),
new Edge(vertices, 3, 6, 4),
new Edge(vertices, 4, 6, 6),
new Edge(vertices, 5, 6, 1)
));
kruskal(vertices.size(),queue);
}
/**
* 克鲁斯卡尔算法实现
* @param size
* @param queue
*/
private static void kruskal(int size, PriorityQueue<Edge> queue) {
List<Edge> res = new ArrayList<>();
UnionFindSet set = new UnionFindSet(size);
while (res.size() < size - 1) {
Edge poll = queue.poll();
int s = set.find(poll.start);
int e = set.find(poll.end);
if (s != e) {
res.add(poll);
set.union(s,e);
}
}
for (Edge edge : res) {
System.out.println(edge);
}
}
}
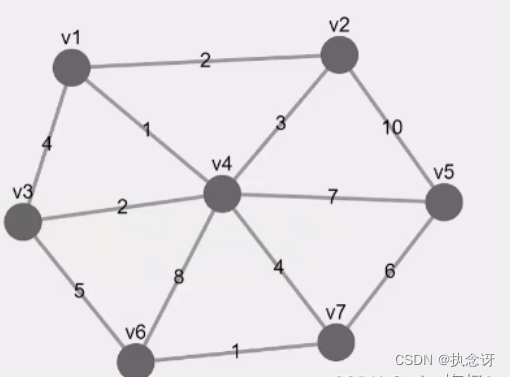
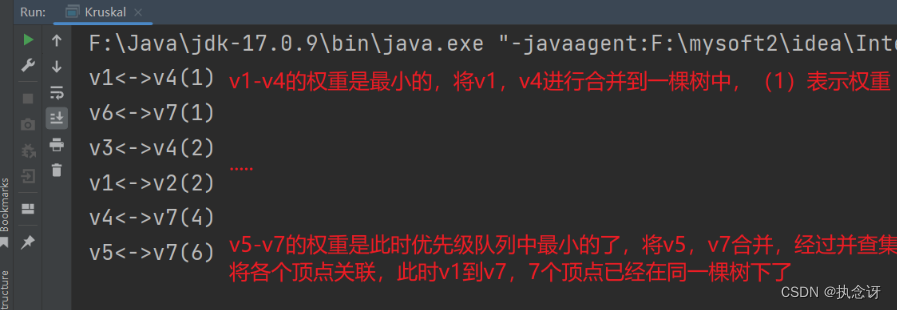
创建上图的最小生成树,运行结果如下:
6.Huffman算法(构建哈夫曼树)
算法思想:
Huffman算法是一种用于构建哈夫曼树(Huffman Tree)的贪心算法,通常用于数据压缩。哈夫曼树是一种带权的二叉树,通过使用变长编码来表示不同的字符,使得出现频率高的字符具有较短的编码,而出现频率低的字符具有较长的编码,从而实现数据的高效压缩。
算法步骤:
1.构建初始森林: 将每个字符看作是一个单独的树,其中树的权重为字符的出现频率。这样就构成了一个初始的树的集合(也可以称为森林)。
2.从初始森林中选择两棵权重最小的树,合并成一棵新树。新树的权重为两棵树的权重之和。
3.将新树放回初始森林。
重复以上2、3步骤,直到只剩下一个树为止。
4.构建的哈夫曼树中,从根节点到每个叶子节点的路径上的左分支表示0,右分支表示1。每个字符对应于一个叶子节点,其编码即为从根节点到该叶子节点的路径上的分支组成的0和1序列。
Huffman算法通过不断合并出现频率最低的节点,构建了一颗带权的二叉树,使得权重越高的节点距离根节点越近,从而实现了对字符的变长编码。由于出现频率高的字符编码较短,而出现频率低的字符编码较长,所以Huffman编码是一种有效的数据压缩方法。
代码实现:
package com.zsh.图.algorithm;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Map;
import java.util.PriorityQueue;
/**
* @version v1.0
* @ClassName: Huffman
* @Description:哈夫曼算法 Huffman编码过程
* 1. 将统计了出现频率的字符,放入到优先级队列
* 2. 每次出队两个频次最差的元素,给他俩创建个爹
* 3. 把爹重新放入队列,重复2-3
* 4. 当队列只剩下一个元素时,Huffman树构建完成
* @Author: zsh
*/
public class Huffman {
/**
* 结点结构
*/
static class Node {
private Character ch; //字符
private int freq; //字符出现频率
private Node left; // 左孩子
private Node right; //右孩子
private String code; //编码
public Node(Character ch) {
this.ch = ch;
}
public Node(int freq, Node left, Node right) {
this.freq = freq;
this.left = left;
this.right = right;
}
public int getFreq() {
return this.freq;
}
/**
* 判断是否是叶子结点
*
* @return
*/
public boolean isLeaf() {
return this.left == null;
}
@Override
public String toString() {
return "Node{" +
"ch=" + ch +
", freq=" + freq +
'}';
}
}
Node root;
String str;
// 存储字符的频率
Map<Character, Node> map = new HashMap<>();
public Huffman(String str) {
this.str = str;
// 1. 统计频率
char[] chars = str.toCharArray();
for (char ch : chars) {
Node node = map.computeIfAbsent(ch, Node::new);
node.freq++;
}
// 2.构造二叉树
PriorityQueue<Node> queue = new PriorityQueue<>(Comparator.comparingInt(Node::getFreq));
queue.addAll(map.values()); //将所有字符对应的结点添加到队列中
while (queue.size() >= 2) {
Node l = queue.poll();
Node r = queue.poll();
int freq = l.freq + r.freq;
queue.offer(new Node(freq, l, r));
}
root = queue.poll(); //队列中剩的最后一个即为根节点
// 3.计算每个字符的编码,并统计一个需要的bit位
int sum = dfs(root, new StringBuilder());
for (Node node : map.values()) {
System.out.println(node + " " + node.code);
}
System.out.println("一共需要的bits:" + sum);
}
// 编码
public String encode() {
char[] chars = str.toCharArray();
StringBuilder sb = new StringBuilder();
for (char ch : chars) {
sb.append(map.get(ch).code);
}
return sb.toString();
}
/**
* 解码
* 从根节点寻找数字对应的字符
* 数字是0往左走
* 数字是1往右走
* 如果没走到头,每走一步数字的索引++
* 走到头就可以找到解码字符,在将node重新置为根节点
*
* @return
*/
public String decode(String str) { //0001011111111
char[] chars = str.toCharArray();
int i = 0;
StringBuilder sb = new StringBuilder();
Node node = root;
while (i < chars.length) {
//如果是非叶子节点
if (!node.isLeaf()) {
if (chars[i] == '0') { //0向左走
node = node.left;
} else if (chars[i] == '1') {
node = node.right; //1向右走
}
i++;
}
if (node.isLeaf()) { //如果是叶子结点
sb.append(node.ch); //将叶子结点字符追加到sb中
node = root; //node重新置为根节点
}
}
return sb.toString();
}
private int dfs(Node node, StringBuilder code) {
int sum = 0;
//是叶子结点
if (node.isLeaf()) {
node.code = code.toString();
sum = node.freq * code.length();
} else {
// 非叶子结点的和应该是叶子结点的和累加的结果
sum += dfs(node.left, code.append("0")); //向左走追加一个0
sum += dfs(node.right, code.append("1")); //向右走追加1
}
// 向回走的时候,删除最后一个编码
if (code.length() > 0) {
code.deleteCharAt(code.length() - 1);
}
return sum;
}
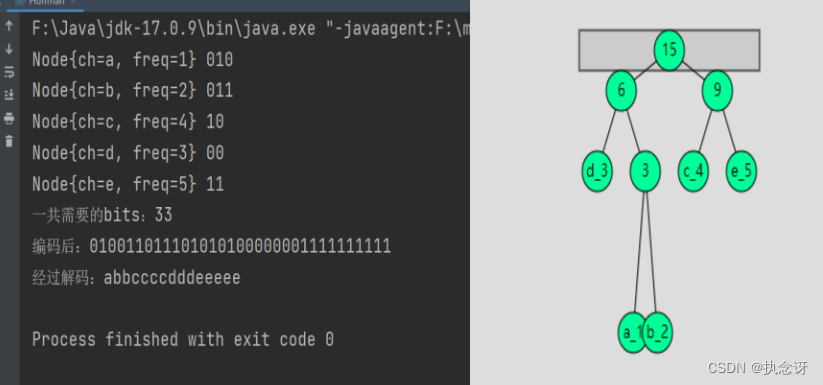
public static void main(String[] args) {
Huffman huffman = new Huffman("abbccccdddeeeee");
String encode = huffman.encode();
String decode = huffman.decode(encode);
System.out.println("编码后:"+encode);
System.out.println("经过解码:"+decode);
}
}
运行结果
欧拉回路与路径算法
7. Fleury算法(寻找无向图中欧拉回路)
算法思想:
Fleury算法是一种寻找无向图欧拉回路的算法。欧拉回路是指一条经过图中每条边且经过一次且仅一次的回路。Fleury算法的思想是通过一系列的规则来遍历图中的边,确保每次选择的边不是桥(不会断开图的连接),从而找到欧拉回路。
算法步骤:
1.从任意顶点开始,选择一条未访问过的边,并将其从图中删除。
2.如果删除该边之后,原图中没有断开的部分(即图仍然是连通的),则选择该边;否则,选择其他的未访问过的边。
3.重复上述步骤,直到所有的边都被访问过。
算法代码:
package com.zsh.图.algorithm;
import java.util.*;
/**
* @version v1.0
* @ClassName: FleuryAlgorithm
* @Description:
* @Author: zsh
*/
public class FleuryAlgorithm {
static final int MAXN = 256;
/**
* 模拟栈结构
*/
static class Stack {
int top; //表示栈顶的位置。初始化为0
int[] node = new int[MAXN]; //用数组作为栈的存储结构,数组中存储栈中的各个元素
}
static int[][] Edge = new int[MAXN][MAXN]; //图的邻接矩阵表示
static int n;
static void DFS(int x, Stack s) {
s.top++;
s.node[s.top] = x; //x作为栈顶
for (int i = 0; i < n; ++i) {
// 如果存在边,
if (Edge[x][i] > 0) {
Edge[x][i] = Edge[i][x] = 0; //将其在邻接矩阵中置为0表示已经访问该边了
DFS(i, s);
break;
}
}
}
static void Fleury(int start) {
Stack s = new Stack();
s.top = 0;
s.node[s.top] = start;
// 只要栈中还有元素就继续
while (s.top >= 0) {
int b = 0; //用于标记是否存在未访问的边 1-表示未访问
for (int i = 0; i < n; i++) { //遍历与栈顶顶点相邻的顶点。
if (Edge[s.node[s.top]][i] > 0) { //如果存在未访问的边
b = 1;
break;
}
}
//如果不存在未访问的边输出当前结点的值
if (b == 0) {
System.out.print(s.node[s.top] + 1 + "->");
s.top--;
} else {
s.top--;
DFS(s.node[s.top + 1], s);
}
}
System.out.println();
}
private static void printEdge(int n,int m){
System.out.println("-----------------------");
for(int i = 0; i < n;i++){
System.out.print("[");
for(int j = 0; j < m;j++){
System.out.print(String.format("%2s",Edge[i][j]));
}
System.out.println("]");
}
System.out.println("-----------------------");
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int m, s, t;
int degree, num, start;
n = scanner.nextInt();
m = scanner.nextInt();
for (int i = 0; i < m; ++i) {
s = scanner.nextInt();
t = scanner.nextInt();
Edge[s - 1][t - 1] = Edge[t - 1][s - 1] = 1;
}
printEdge(n,m);
num = start = 0;
// 统计顶点的度,因为满足是欧拉回路的前提是必须所有顶点的度都为偶数,或者只有两个为奇数的度
for (int i = 0; i < n; ++i) {
degree = 0;
for (int j = 0; j < n; ++j)
degree += Edge[i][j];
if (degree % 2 == 1) {
num++;
start = i;
}
}
if (num == 0 || num == 2)
Fleury(start);
else
System.out.println("没有欧拉回路");
}
}
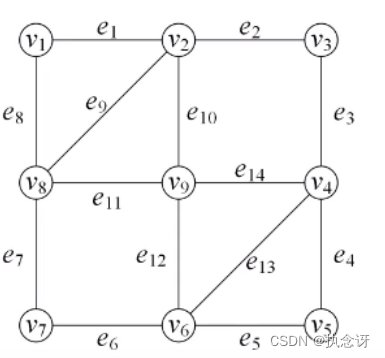
对以上欧拉图进行测试,结果如下:
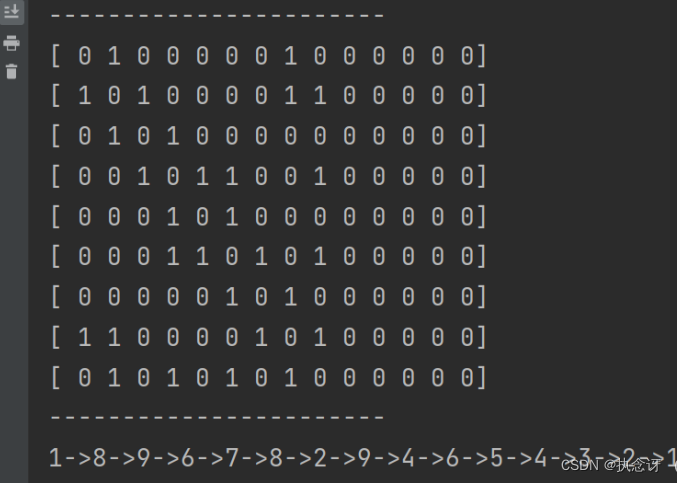
即V1->V8->V9->V6->V7->V8->V2->V9->V4->V6->V5->V4->V3->V2->V1构成一条欧拉回路















 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









