







一、基本简介
Requests 是一个简单的 HTTP 库,允许使用者发送 HTTP 请求。说白了我们能够通过 Requests 模块向指定的 URL 所在服务器发送请求,从而拿到服务器返回的响应结果,进而解析出我们需要的数据。
如何安装
本人喜欢使用原生 Python,不太喜欢 Anaconda,所以本人教程只选择 pip 命令进行安装。
Windows、Mac、Linux 都可以选择使用 pip3 install requests 命令进行安装,当然,Windows 可以简写为 pip install requests,安装位置的话就选择在 cmd 或者 终端内安装即可(PS:程序员一定知道 cmd 和终端的,不需要我教吧!)。
如何学习
Requests 官方提供的是有教程的,有能力的同学可以自学:Requests: HTTP for Humans™ — Requests 2.31.0 documentation
二、快速开始
让我们从一些简单的例子开始,比如使用 Requests 模块请求自己的官方文档链接:https://requests.readthedocs.io/en/latest/#
# 1. 导入 requests 这个模块
import requests
# 2. 给定需要爬取的网页的URL
URL = 'https://requests.readthedocs.io/en/latest/#'
# 3.先向 URL 所在服务器发送请求,得到响应结果,这里使用requests 的 get 方法,同 GET 请求方式
response = requests.get(url=URL)
为什么使用 requests 的 get 方法,前文有所叙述,不明白的请看这里👉🏻:可狱可囚的爬虫系列课程 02:爬虫必会概念中所编写的 GET 和 POST 部分!
上面代码已经拿到了服务器返回的响应结果,数据存储在 response 这个变量中,接下来我们继续处理。
# 4. 查看 HTTP 状态码,使用 response 对象的 status_code 属性
print(response.status_code)
为什么要查看 HTTP 状态码,前文有所叙述,不明白的请看这里👉🏻:可狱可囚的爬虫系列课程 02:爬虫必会概念中所编写的 HTTP 状态码部分!
此时状态码如果是 200,我们可以继续爬取,如果不是 200,我们便需要进行解决,Requests 的官方文档这个网站目前没有反爬,此时这里的状态码是 200。
# 5. 查看字符串类型的网页源代码,使用 response 对象的 text 属性
print(response.text)
结果如图所示: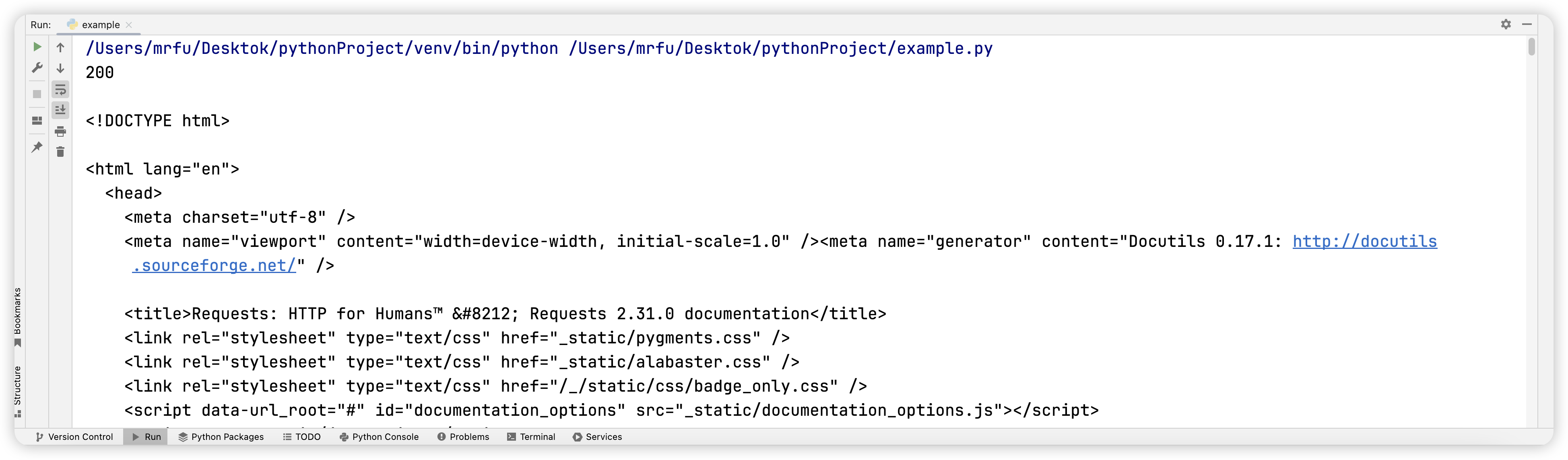
我们尝试看能不能从程序的结果中提取到一些信息,发现从程序的结果中我们找到了这个网站教程的目录信息,只不过源代码中还包含了很多的前端标签,CSS 样式等内容。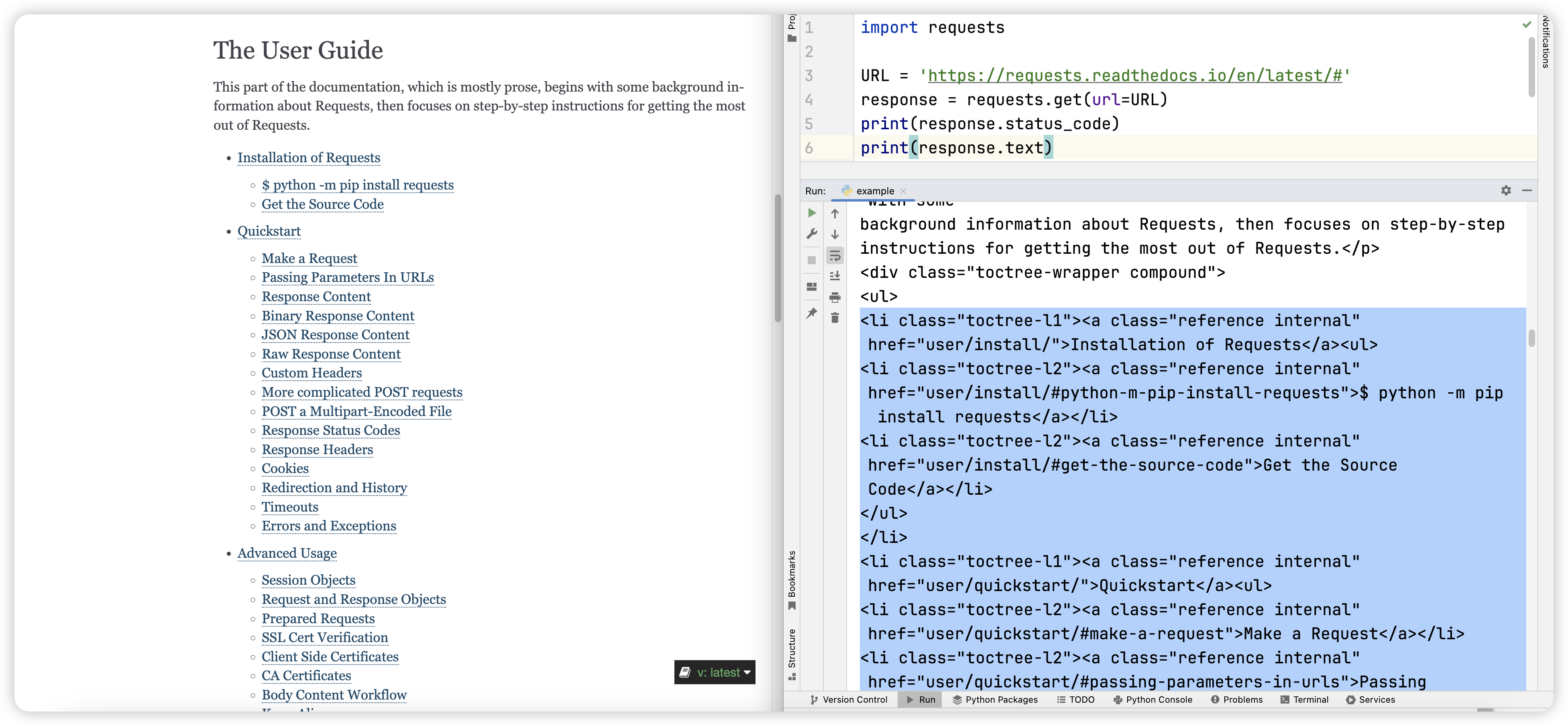
大家不妨多换几个网站,尝试使用 requests 模块进行请求,看一下能得到什么结果,不过呢我们目前讲解还比较浅显,大概率请求其他网站的时候会遇到各种问题,大家不要灰心。
我们爬虫的学习之路才刚开始,同样的 Requests 模块的学习还未结束,请大家继续下一章节的学习!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











