







内核初始化:生意做大了就得成立公司
- 软件平台:运行于VMware Workstation 12 Player下UbuntuLTS16.04_x64 系统
- 开发环境:Linux-4.19-rc3内核
目录
1、内核启动函数star_kernel() 初步分析
内核的启动从入口函数start_kernel()开始。在init/main.c文件中,start_kernel相当于内核的main函数。
1.1 0号进程(idle)初始化set_task_stack_end_magic(&init_task)
唯一一个没有通过fork或者kernel_thread产生的进程,是进程列表的第一个
asmlinkage __visible void __init start_kernel(void)
{
char *command_line;
char *after_dashes;
/* 1、初始化0号进程 */
set_task_stack_end_magic(&init_task);
smp_setup_processor_id();
debug_objects_early_init();
/* ...... */
1.2 页地址初始化、打印版本信息、设置架构…
boot_cpu_init();
page_address_init(); /* 页地址初始化 */
pr_notice("%s", linux_banner); /* 打印版本信息 */
setup_arch(&command_line); /* 设置硬件架构 */
/* ...... */
1.3 中断门初始化trap_init();
void __init trap_init(void)
{
register_break_hook(&bug_break_hook);
}
void register_break_hook(struct break_hook *hook)
{
spin_lock(&break_hook_lock);
list_add_rcu(&hook->node, &break_hook);
spin_unlock(&break_hook_lock);
}
1.4 内存管理初始化mm_init();
/*
* 设置内核内存管理制度
*/
static void __init mm_init(void)
{
/*
* page_ext requires contiguous pages,
* bigger than MAX_ORDER unless SPARSEMEM.
*/
page_ext_init_flatmem();
mem_init();
kmem_cache_init();
pgtable_init();
vmalloc_init();
ioremap_huge_init();
/* Should be run before the first non-init thread is created */
init_espfix_bsp();
/* Should be run after espfix64 is set up. */
pti_init();
}
1.5 调度管理初始化sched_init();
void __init sched_init(void)
{
int i, j;
unsigned long alloc_size = 0, ptr;
wait_bit_init();
#ifdef CONFIG_FAIR_GROUP_SCHED
alloc_size += 2 * nr_cpu_ids * sizeof(void **);
#endif
#ifdef CONFIG_RT_GROUP_SCHED
alloc_size += 2 * nr_cpu_ids * sizeof(void **);
#endif
if (alloc_size) {
ptr = (unsigned long)kzalloc(alloc_size, GFP_NOWAIT);
#ifdef CONFIG_FAIR_GROUP_SCHED
root_task_group.se = (struct sched_entity **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
root_task_group.cfs_rq = (struct cfs_rq **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
#endif /* CONFIG_FAIR_GROUP_SCHED */
#ifdef CONFIG_RT_GROUP_SCHED
root_task_group.rt_se = (struct sched_rt_entity **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
root_task_group.rt_rq = (struct rt_rq **)ptr;
ptr += nr_cpu_ids * sizeof(void **);
#endif /* CONFIG_RT_GROUP_SCHED */
}
#ifdef CONFIG_CPUMASK_OFFSTACK
for_each_possible_cpu(i) {
per_cpu(load_balance_mask, i) = (cpumask_var_t)kzalloc_node(
cpumask_size(), GFP_KERNEL, cpu_to_node(i));
per_cpu(select_idle_mask, i) = (cpumask_var_t)kzalloc_node(
cpumask_size(), GFP_KERNEL, cpu_to_node(i));
}
#endif /* CONFIG_CPUMASK_OFFSTACK */
init_rt_bandwidth(&def_rt_bandwidth, global_rt_period(), global_rt_runtime());
init_dl_bandwidth(&def_dl_bandwidth, global_rt_period(), global_rt_runtime());
#ifdef CONFIG_SMP
init_defrootdomain();
#endif
#ifdef CONFIG_RT_GROUP_SCHED
init_rt_bandwidth(&root_task_group.rt_bandwidth,
global_rt_period(), global_rt_runtime());
#endif /* CONFIG_RT_GROUP_SCHED */
#ifdef CONFIG_CGROUP_SCHED
task_group_cache = KMEM_CACHE(task_group, 0);
list_add(&root_task_group.list, &task_groups);
INIT_LIST_HEAD(&root_task_group.children);
INIT_LIST_HEAD(&root_task_group.siblings);
autogroup_init(&init_task);
#endif /* CONFIG_CGROUP_SCHED */
for_each_possible_cpu(i) {
struct rq *rq;
rq = cpu_rq(i);
raw_spin_lock_init(&rq->lock);
rq->nr_running = 0;
rq->calc_load_active = 0;
rq->calc_load_update = jiffies + LOAD_FREQ;
init_cfs_rq(&rq->cfs);
init_rt_rq(&rq->rt);
init_dl_rq(&rq->dl);
#ifdef CONFIG_FAIR_GROUP_SCHED
root_task_group.shares = ROOT_TASK_GROUP_LOAD;
INIT_LIST_HEAD(&rq->leaf_cfs_rq_list);
rq->tmp_alone_branch = &rq->leaf_cfs_rq_list;
/*
* How much CPU bandwidth does root_task_group get?
*
* In case of task-groups formed thr' the cgroup filesystem, it
* gets 100% of the CPU resources in the system. This overall
* system CPU resource is divided among the tasks of
* root_task_group and its child task-groups in a fair manner,
* based on each entity's (task or task-group's) weight
* (se->load.weight).
*
* In other words, if root_task_group has 10 tasks of weight
* 1024) and two child groups A0 and A1 (of weight 1024 each),
* then A0's share of the CPU resource is:
*
* A0's bandwidth = 1024 / (10*1024 + 1024 + 1024) = 8.33%
*
* We achieve this by letting root_task_group's tasks sit
* directly in rq->cfs (i.e root_task_group->se[] = NULL).
*/
init_cfs_bandwidth(&root_task_group.cfs_bandwidth);
init_tg_cfs_entry(&root_task_group, &rq->cfs, NULL, i, NULL);
#endif /* CONFIG_FAIR_GROUP_SCHED */
rq->rt.rt_runtime = def_rt_bandwidth.rt_runtime;
#ifdef CONFIG_RT_GROUP_SCHED
init_tg_rt_entry(&root_task_group, &rq->rt, NULL, i, NULL);
#endif
for (j = 0; j < CPU_LOAD_IDX_MAX; j++)
rq->cpu_load[j] = 0;
#ifdef CONFIG_SMP
rq->sd = NULL;
rq->rd = NULL;
rq->cpu_capacity = rq->cpu_capacity_orig = SCHED_CAPACITY_SCALE;
rq->balance_callback = NULL;
rq->active_balance = 0;
rq->next_balance = jiffies;
rq->push_cpu = 0;
rq->cpu = i;
rq->online = 0;
rq->idle_stamp = 0;
rq->avg_idle = 2*sysctl_sched_migration_cost;
rq->max_idle_balance_cost = sysctl_sched_migration_cost;
INIT_LIST_HEAD(&rq->cfs_tasks);
rq_attach_root(rq, &def_root_domain);
#ifdef CONFIG_NO_HZ_COMMON
rq->last_load_update_tick = jiffies;
rq->last_blocked_load_update_tick = jiffies;
atomic_set(&rq->nohz_flags, 0);
#endif
#endif /* CONFIG_SMP */
hrtick_rq_init(rq);
atomic_set(&rq->nr_iowait, 0);
}
set_load_weight(&init_task, false);
/*
* The boot idle thread does lazy MMU switching as well:
*/
mmgrab(&init_mm);
enter_lazy_tlb(&init_mm, current);
/*
* Make us the idle thread. Technically, schedule() should not be
* called from this thread, however somewhere below it might be,
* but because we are the idle thread, we just pick up running again
* when this runqueue becomes "idle".
*/
init_idle(current, smp_processor_id());
calc_load_update = jiffies + LOAD_FREQ;
#ifdef CONFIG_SMP
idle_thread_set_boot_cpu();
#endif
init_sched_fair_class();
init_schedstats();
scheduler_running = 1;
}
1.6 基于内存的文件系统rootfs初始化vfs_caches_init()
void __init vfs_caches_init(void)
{
names_cachep = kmem_cache_create_usercopy("names_cache", PATH_MAX, 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC, 0, PATH_MAX, NULL);
dcache_init();
inode_init();
files_init();
files_maxfiles_init();
mnt_init(); /* 基于内存的文件系统rootfs */
bdev_cache_init();
chrdev_init();
}
/*----------------------------------------------------------------------------------------*/
void __init mnt_init(void)
{
int err;
mnt_cache = kmem_cache_create("mnt_cache", sizeof(struct mount),
0, SLAB_HWCACHE_ALIGN | SLAB_PANIC, NULL);
mount_hashtable = alloc_large_system_hash("Mount-cache",
sizeof(struct hlist_head),
mhash_entries, 19,,
HASH_ZERO,
&m_hash_shift, &m_hash_mask, 0, 0);
mountpoint_hashtable = alloc_large_system_hash("Mountpoint-cache",
sizeof(struct hlist_head),
mphash_entries, 19,
HASH_ZERO,
&mp_hash_shift, &mp_hash_mask, 0, 0);
if (!mount_hashtable || !mountpoint_hashtable)
panic("Failed to allocate mount hash table\n");
kernfs_init();
err = sysfs_init(); /* 文件系统初始化 */
if (err)
printk(KERN_WARNING "%s: sysfs_init error: %d\n",
__func__, err);
fs_kobj = kobject_create_and_add("fs", NULL);
if (!fs_kobj)
printk(KERN_WARNING "%s: kobj create error\n", __func__);
/* rootfs初始化 */
init_rootfs();
init_mount_tree();
}
/*----------------------------------------------------------------------------------------*/
int __init sysfs_init(void)
{
int err;
sysfs_root = kernfs_create_root(NULL, KERNFS_ROOT_EXTRA_OPEN_PERM_CHECK,
NULL);
if (IS_ERR(sysfs_root))
return PTR_ERR(sysfs_root);
sysfs_root_kn = sysfs_root->kn;
/* 注册具体类型的文件系统 */
err = register_filesystem(&sysfs_fs_type);
if (err) {
kernfs_destroy_root(sysfs_root);
return err;
}
return 0;
}
1.7 其他资源初始化rest_init();
static noinline void __ref rest_init(void)
{
struct task_struct *tsk;
int pid;
rcu_scheduler_starting();
/*
* We need to spawn init first so that it obtains pid 1, however
* the init task will end up wanting to create kthreads, which, if
* we schedule it before we create kthreadd, will OOPS.
*/
/* 1号进程的产生:用户态 */
pid = kernel_thread(kernel_init, NULL, CLONE_FS);
/*
* Pin init on the boot CPU. Task migration is not properly working
* until sched_init_smp() has been run. It will set the allowed
* CPUs for init to the non isolated CPUs.
*/
rcu_read_lock();
tsk = find_task_by_pid_ns(pid, &init_pid_ns);
set_cpus_allowed_ptr(tsk, cpumask_of(smp_processor_id()));
rcu_read_unlock();
numa_default_policy();
/* 2号进程的产生:内核态 */
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
rcu_read_lock();
kthreadd_task = find_task_by_pid_ns(pid, &init_pid_ns);
rcu_read_unlock();
/*
* Enable might_sleep() and smp_processor_id() checks.
* They cannot be enabled earlier because with CONFIG_PREEMPT=y
* kernel_thread() would trigger might_sleep() splats. With
* CONFIG_PREEMPT_VOLUNTARY=y the init task might have scheduled
* already, but it's stuck on the kthreadd_done completion.
*/
system_state = SYSTEM_SCHEDULING;
complete(&kthreadd_done);
/*
* The boot idle thread must execute schedule()
* at least once to get things moving:
*/
schedule_preempt_disabled();
/* Call into cpu_idle with preempt disabled */
cpu_startup_entry(CPUHP_ONLINE);
}
1.8 小结


2、初始化1号(init)进程kernel_thread(kernel_init, NULL, CLONE_FS);
pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags)
{
return _do_fork(flags|CLONE_VM|CLONE_UNTRACED, (unsigned long)fn,
(unsigned long)arg, NULL, NULL, 0);
}
/*----------------------------------------------------------------------------------------*/
static int __ref kernel_init(void *unused)
{
int ret;
kernel_init_freeable();
/* 在释放内存之前需要完成所有的async __init代码 */
async_synchronize_full();
ftrace_free_init_mem();
jump_label_invalidate_initmem();
free_initmem();
mark_readonly();
/*
* 内核映射现在已经完成,更新用户空间(用户)敲定PTI页表。
*/
pti_finalize();
system_state = SYSTEM_RUNNING;
numa_default_policy();
rcu_end_inkernel_boot();
if (ramdisk_execute_command) {
ret = run_init_process(ramdisk_execute_command);
if (!ret)
return 0;
pr_err("Failed to execute %s (error %d)\n",
ramdisk_execute_command, ret);
}
/*
* 尝试运行ramdisk的“/init”,或者普通文件系统上的“/sbin/init”“/etc/init”“/bin/init”“/bin/sh”。
* 不同版本的Linux会选择不同的文件启动,但是只要有一个起来了就可以。
*/
if (execute_command) {
ret = run_init_process(execute_command);
if (!ret)
return 0;
panic("Requested init %s failed (error %d).",
execute_command, ret);
}
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
panic("No working init found. Try passing init= option to kernel. "
"See Linux Documentation/admin-guide/init.rst for guidance.");
}
-
init进程由idle通过kernel_thread创建,在内核空间完成初始化后, 加载init程序, 并最终用户空间
-
init进程由0进程创建,完成系统的初始化. 是系统中所有其它用户进程的祖先进程
-
Linux中的所有进程都是有init进程创建并运行的:首先Linux内核启动,然后在用户空间中启动init进程,再启动其他系统进程。在系统启动完成完成后,init将变为守护进程监视系统其他进程。
3、初始化2号进程kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags)
{
return _do_fork(flags|CLONE_VM|CLONE_UNTRACED, (unsigned long)fn,
(unsigned long)arg, NULL, NULL, 0);
}
/*-----------------------------------------------------------------*/
int kthreadd(void *unused)
{
struct task_struct *tsk = current;
/* 为子进程建立一个干净的环境来继承 */
set_task_comm(tsk, "kthreadd");
ignore_signals(tsk);
set_cpus_allowed_ptr(tsk, cpu_all_mask);
set_mems_allowed(node_states[N_MEMORY]);
current->flags |= PF_NOFREEZE;
cgroup_init_kthreadd();
for (;;) {
set_current_state(TASK_INTERRUPTIBLE);
if (list_empty(&kthread_create_list)) /* 如果队列为空,则睡眠 */
schedule();
__set_current_state(TASK_RUNNING);
spin_lock(&kthread_create_lock);
/* 如果队列不空,在循环创建线程 */
while (!list_empty(&kthread_create_list)) {
struct kthread_create_info *create;
/* 在队列中弹出申请者的结点 */
create = list_entry(kthread_create_list.next,
struct kthread_create_info, list);
/* 在队列中删除原结点 */
list_del_init(&create->list);
spin_unlock(&kthread_create_lock);
/* 根据申请者创建线程 */
create_kthread(create);
spin_lock(&kthread_create_lock);
}
spin_unlock(&kthread_create_lock);
}
return 0;
}
4、从内核态到用户态
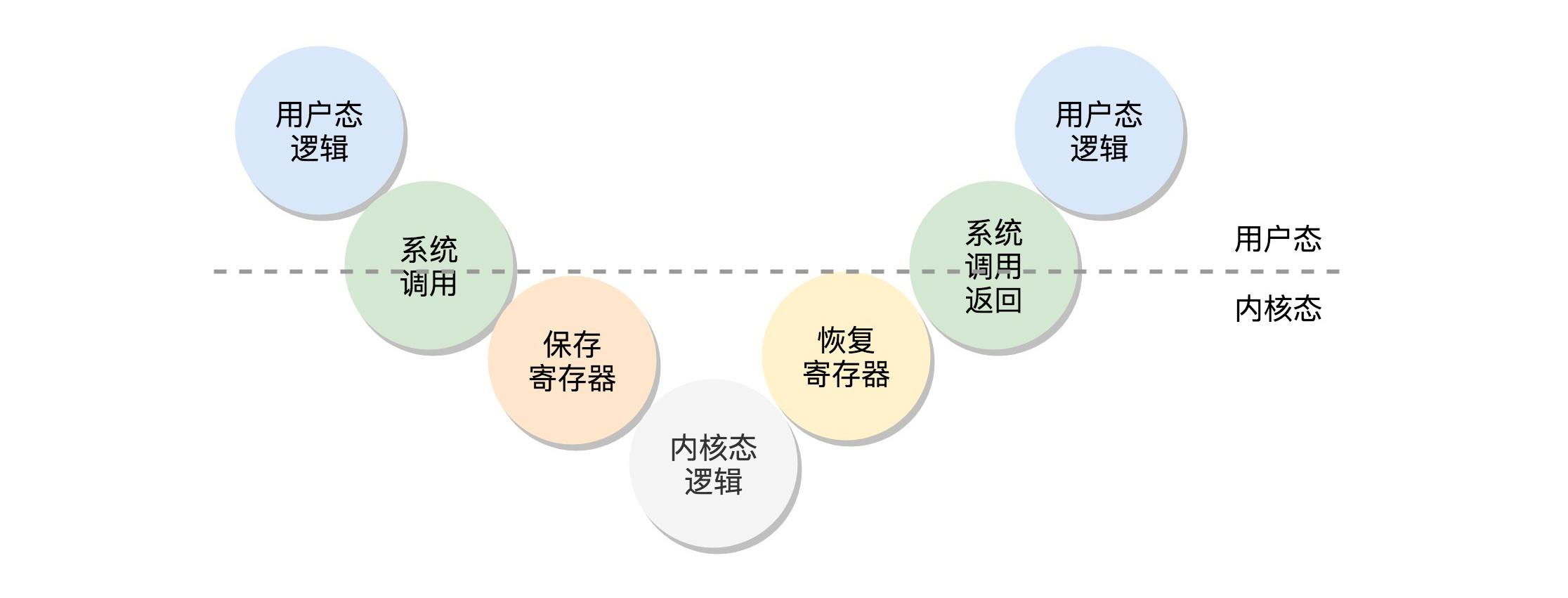
在发生系统调用的时候,调用顺序为:“用户态–>系统调用–>保存寄存器–>内核态执行系统调用–>恢复寄存器–>返回用户态”
现在来研究下如何从 内核态执行系统调用–>恢复寄存器–>返回用户态?
-
以创建1号进程为例子:
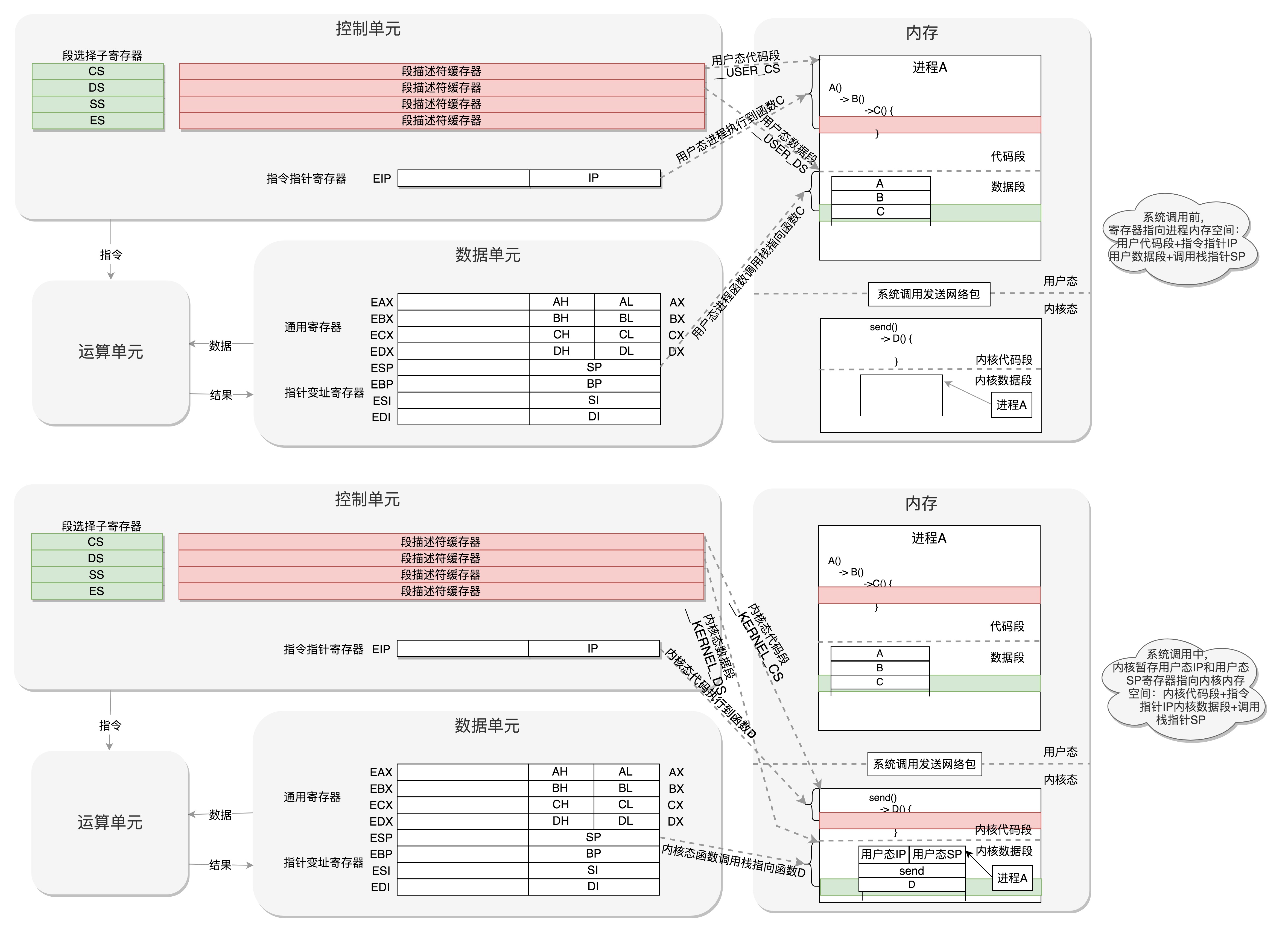
/* * 尝试运行ramdisk的“/init”,或者普通文件系统上的“/sbin/init”“/etc/init”“/bin/init”“/bin/sh”。 * 不同版本的Linux会选择不同的文件启动,但是只要有一个起来了就可以。 */ if (execute_command) { ret = run_init_process(execute_command); if (!ret) return 0; panic("Requested init %s failed (error %d).", execute_command, ret); } if (!try_to_run_init_process("/sbin/init") || !try_to_run_init_process("/etc/init") || !try_to_run_init_process("/bin/init") || !try_to_run_init_process("/bin/sh")) return 0; panic("No working init found. Try passing init= option to kernel. " "See Linux Documentation/admin-guide/init.rst for guidance."); -
在执行这段代码之前,处于在内核态,在执行到
run_init_process(execute_command)时static int run_init_process(const char *init_filename) { argv_init[0] = init_filename; pr_info("Run %s as init process\n", init_filename); return do_execve(getname_kernel(init_filename), (const char __user *const __user *)argv_init, (const char __user *const __user *)envp_init); }可以看到实际上调用的是
do_execve()这个系统调用函数,即完成内核态执行系统调用这个过程。 -
随后加载二进制配置文件,恢复寄存器
do_execve-->do_execveat_common-->__do_execve_file-->exec_binprm– >search_binary_handler-->search_binary_handler-->fmt->load_binary(bprm);int do_execve(struct filename *filename, const char __user *const __user *__argv, const char __user *const __user *__envp) { struct user_arg_ptr argv = { .ptr.native = __argv }; struct user_arg_ptr envp = { .ptr.native = __envp }; return do_execveat_common(AT_FDCWD, filename, argv, envp, 0); } /*------------------------------------------------------------------*/ static int do_execveat_common(int fd, struct filename *filename, struct user_arg_ptr argv, struct user_arg_ptr envp, int flags) { return __do_execve_file(fd, filename, argv, envp, flags, NULL); } /*------------------------------------------------------------------*/ /* * sys_execve() executes a new program. */ static int __do_execve_file(int fd, struct filename *filename, struct user_arg_ptr argv, struct user_arg_ptr envp, int flags, struct file *file) { char *pathbuf = NULL; struct linux_binprm *bprm; /* 为二进制文件分配内存空间 */ bprm = kzalloc(sizeof(*bprm), GFP_KERNEL); if (!bprm) goto out_files; /* 填充并设置这个二进制文件 */ retval = prepare_bprm_creds(bprm); if (retval) goto out_free; check_unsafe_exec(bprm); current->in_execve = 1; if (!file) file = do_open_execat(fd, filename, flags); retval = PTR_ERR(file); if (IS_ERR(file)) goto out_unmark; sched_exec(); bprm->file = file; /* ....... */ /* */ retval = exec_binprm(bprm); if (retval < 0) goto out; /* execve succeeded */ current->fs->in_exec = 0; current->in_execve = 0; membarrier_execve(current); rseq_execve(current); acct_update_integrals(current); task_numa_free(current); free_bprm(bprm); kfree(pathbuf); if (filename) putname(filename); if (displaced) put_files_struct(displaced); return retval; /* ...... */ return retval; } /*------------------------------------------------------------------*/ static int exec_binprm(struct linux_binprm *bprm) { pid_t old_pid, old_vpid; int ret; /* Need to fetch pid before load_binary changes it */ old_pid = current->pid; rcu_read_lock(); old_vpid = task_pid_nr_ns(current, task_active_pid_ns(current->parent)); rcu_read_unlock(); ret = search_binary_handler(bprm); if (ret >= 0) { audit_bprm(bprm); trace_sched_process_exec(current, old_pid, bprm); ptrace_event(PTRACE_EVENT_EXEC, old_vpid); proc_exec_connector(current); } return ret; } /*------------------------------------------------------------------*/ int search_binary_handler(struct linux_binprm *bprm) { bool need_retry = IS_ENABLED(CONFIG_MODULES); struct linux_binfmt *fmt; int retval; /* This allows 4 levels of binfmt rewrites before failing hard. */ if (bprm->recursion_depth > 5) return -ELOOP; retval = security_bprm_check(bprm); if (retval) return retval; retval = -ENOENT; retry: /* ...... */ retval = fmt->load_binary(bprm); /* ...... */ } -
随后执行init文件,返回用户态
/* * 尝试运行ramdisk的“/init”,或者普通文件系统上的“/sbin/init”“/etc/init”“/bin/init”“/bin/sh”。 * 不同版本的Linux会选择不同的文件启动,但是只要有一个起来了就可以。 */ if (!try_to_run_init_process("/sbin/init") || !try_to_run_init_process("/etc/init") || !try_to_run_init_process("/bin/init") || !try_to_run_init_process("/bin/sh")) return 0;init程序是在文件系统上的,文件系统一定是在一个存储设备上的。
Linux访问存储设备,要有驱动才能访问。如果存储系统数目很有限,那驱动可以直接放到内核里面,反正前面我们加载过内核到内存里了,现在可以直接对存储系统进行访问。
但是存储系统越来越多了,如果所有市面上的存储系统的驱动都默认放进内核,内核就太大了。这该怎么办呢?
我们只好先弄一个基于内存的文件系统。内存访问是不需要驱动的,这个就是ramdisk。这个时候,ramdisk是根文件系统。
然后,我们开始运行ramdisk上的/init。等它运行完了就已经在用户态了。
/init这个程序会先根据存储系统的类型加载驱动,有了驱动就可以设置真正的根文件系统了。有了真正的根文件系统,ramdisk上的/init会启动文件系统上的init。
接下来就是各种系统的初始化。启动系统的服务,启动控制台,用户就可以登录进来了。
5、总结
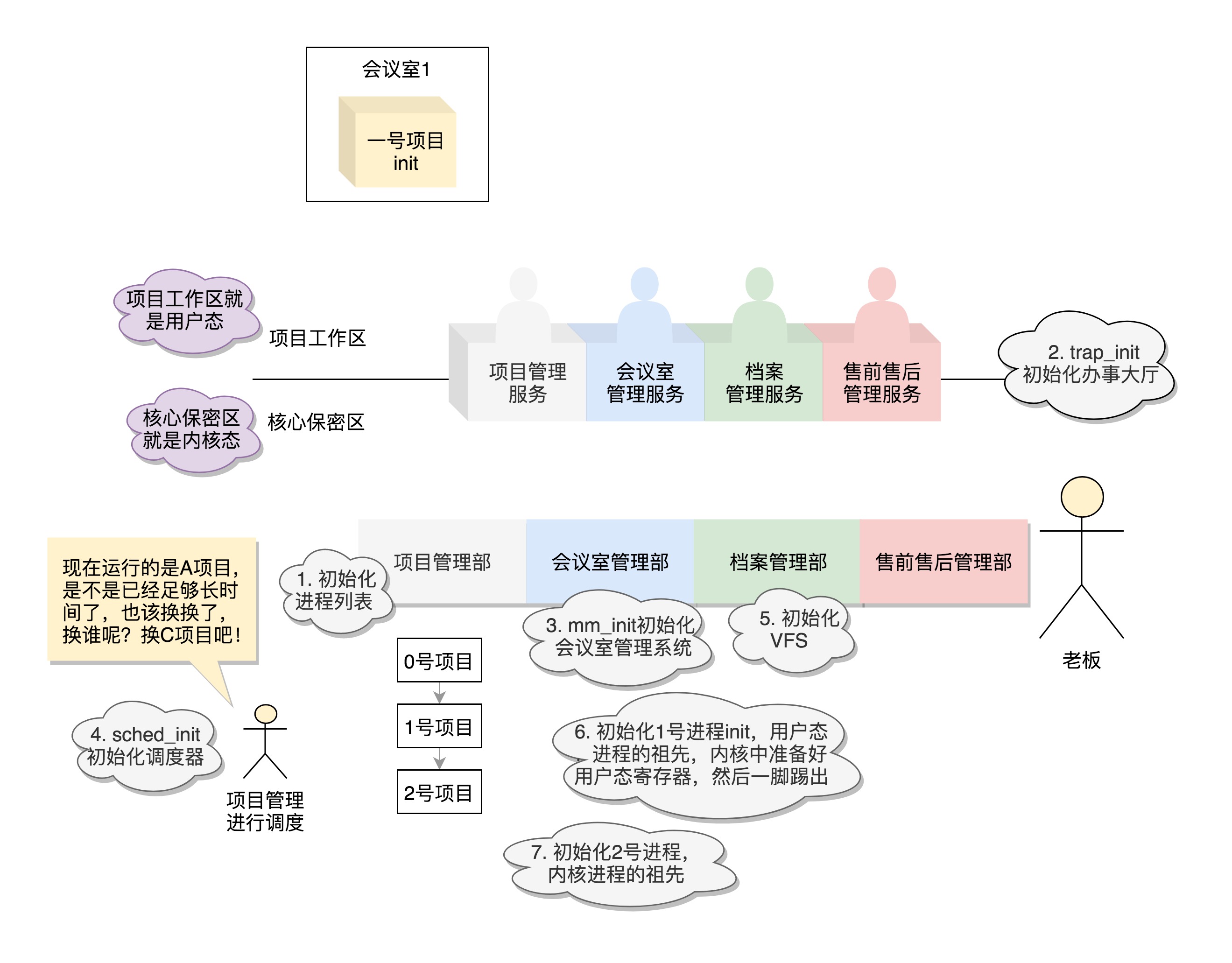
-
内核初始化, 运行
start_kernel()函数(位于 init/main.c), 初始化做三件事:-
创建样板进程, 及各个模块初始化
-
创建管理/创建用户态进程的进程
-
创建管理/创建内核态进程的进程
-
-
创建样板进程,及各个模块初始化
-
创建第一个进程, 0号进程.
set_task_stack_end_magic(&init_task)andstruct task_struct init_task = INIT_TASK(init_task) -
初始化中断,
trap_init(). 系统调用也是通过发送中断进行, 由set_system_intr_gate()完成. -
初始化内存管理模块,
mm_init() -
初始化进程调度模块,
sched_init() -
初始化基于内存的文件系统 rootfs,
vfs_caches_init() -
VFS(虚拟文件系统)将各种文件系统抽象成统一接口
-
调用
rest_init()完成其他初始化工作
-
-
创建管理/创建用户态进程的进程, 1号进程
rest_init()通过kernel_thread(kernel_init,...)创建 1号进程(工作在用户态).- 权限管理
- x86 提供 4个 Ring 分层权限
- 操作系统利用: Ring0-内核态(访问核心资源); Ring3-用户态(普通程序)
- 用户态调用系统调用: 用户态-系统调用-保存寄存器-内核态执行系统调用-恢复寄存器-返回用户态
- 新进程执行 kernel_init 函数, 先运行 ramdisk 的 /init 程序(位于内存中)
- 首先加载 ELF 文件
- 设置用于保存用户态寄存器的结构体
- 返回进入用户态
- /init 加载存储设备的驱动
- kernel_init 函数启动存储设备文件系统上的 init
-
创建管理/创建内核态进程的进程, 2号进程
rest_init()通过kernel_thread(kthreadd,...)创建 2号进程(工作在内核态).kthreadd负责所有内核态线程的调度和管理















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









