







 本文探讨如何找到微信中保存的图片,首先揭示微信图片的存储位置和.dat格式,接着介绍解码过程,包括使用Notepad++和Hex Editor查看文件,并通过异或操作还原图片。然后,文章提供了解码dat文件的Python代码示例,最后讨论了两种寻找特定图片的方法:模板匹配和特征匹配。
本文探讨如何找到微信中保存的图片,首先揭示微信图片的存储位置和.dat格式,接着介绍解码过程,包括使用Notepad++和Hex Editor查看文件,并通过异或操作还原图片。然后,文章提供了解码dat文件的Python代码示例,最后讨论了两种寻找特定图片的方法:模板匹配和特征匹配。
前言
某一天,领导让找几张现场调研的图片,要求是是近2年来的,正面形象气质佳,指点江山气质的优先。想来愚钝,没怎么保存领导调研的图片,后来想从微信里面的各种群找,工作量一下就上来了,思前想后,不如搞个小程序弄下,于是就有了下面探索的内容。
一、微信图片保存在哪里?
电脑微信,设置,文件管理,即可看到文件管理的路径,各种文件均在此。
微信聊天记录,找一个非图片文件,右键,在文件夹中显示。
找到Image文件夹,里面基本都是图片,但是不是常规图片后缀名,均为.dat。
二、解码过程
1.dat是什么:一切皆数字
使用Notepad++软件打开任意一个dat文件:
结果是乱码
使用插件,插件,插件管理,下载Hex Editor
再次打开刚才的dat文件,view in hex 显示如下:

按网上各路大神所说,随机再打开其他的dat文件,94和4d这2个数字均一致。
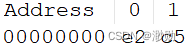
这里引用网上教程解释:jpeg格式的图片开头两个16进制的值通常为FFD8,将e2 c5这两个值异或一下,得到16进制的值,通常来说应该是一样的,修改加密的异或值,比如说我的异或值最后两位是1D,则xor_value = 0x1D,0x表示16进制,记下这个值。
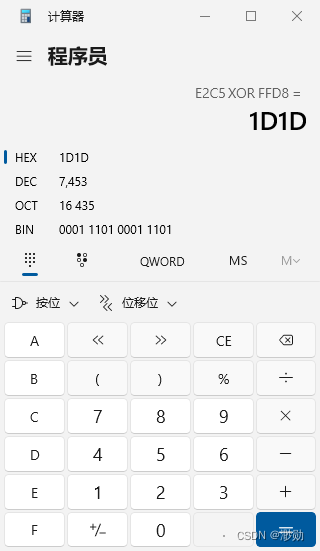
做好文件备份!验证下dat文件的开头是否如上面想的一样:
import os
path = r"E:\微信文件\WeChat Files\wxid_r3f11i50p8f022\FileStorage\MsgAttach" #wxid_r3f11i50p8f022 每个微信账号下的文件夹,且都不一致,注意换成自己的
result = {
}
files_list = os.listdir(path)
for i in files_list:
dat_paths = os.path.join(path, i,"Image")
try:
dat_dir = os.listdir(dat_paths)
except FileNotFoundError:
print(i)
continue
for j in dat_dir:
dat_file_dir = os.path.join(dat_paths,j)
dat_files = os.listdir(dat_file_dir)
for f in dat_files:
dat_file = os.path.join(dat_file_dir,f)
dats = open(dat_file,"rb")
txts = dats.read()
head_txt = hex(txts[0]) + hex(txts[1])
if head_txt in result.keys():
result[head_txt] = result[head_txt] + 1
else:
result[head_txt] = 1
print(result)
这可能会花费大量时间和计算机资源,取决于你的文件数量,完全是基于探索,所以,一定要做备份。
{‘0xe20xc5’: 11743, ‘0x940x4d’: 1921, ‘0xff0xd8’: 26, ‘0x770x78’: 44, ‘0x890x50’: 4}
我的文件开头e2c5的占大多数,所以就它了,后面转换验证的时候,其他的转换后图片无法显示也证明了这点。
2.转换输出图片
代码如下(示例):
def toimg(dat,img_save_path,img_name):
imgs = os.path.join(img_save_path,img_name) #转换后图片保存路径
txt = open(dat,"rb") #读取dat文件
img = open(imgs,"wb") #保存图片
xor_value = 0x1D #0x表示16进制
for lines in txt:
for nowByte in lines:
newByte = nowByte ^ xor_value
img.write(bytes([newByte]))
txt.close()
img.close()
核心就是nowByte ^ xor_value求值,再将新值写入新的文件,保存为图片文件格式,jpg或png。
3. 验证
上代码
import os
path = r"E:\微信文件\WeChat Files\wxid_r3f11i50p8f022\FileStorage\MsgAttach" #wxid_r3 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3003
3003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









