







行转列explode
数据explode_lateral_view.txt:
a:shandong,b:beijing,c:hebei|1,2,3,4,5,6,7,8,9|[{“source”:“7fresh”,“monthSales”:4900,“userCount”:1900,“score”:“9.9”},{“source”:“jd”,“monthSales”:2090,“userCount”:78981,“score”:“9.8”},{“source”:“jdmart”,“monthSales”:6987,“userCount”:1600,“score”:“9.0”}]
建表将数据导入表中:
drop table explode_lateral_view;
create table explode_lateral_view(
`area` string,
`goods_id` string,
`sale_info` string)
row format delimited fields terminated by '|' stored as textfile;
--本地导入数据
hive> load data local inpath '/home/01/temp/hive_json.txt' overwrite into explode_lateral_view;
--查看导入后的数据
hive> select * from explode_lateral_view;
OK
a:shandong,b:beijing,c:hebei 1,2,3,4,5,6,7,8,9 [{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]
1.explode使用案例,将一行数据转为列或多列数据:
拆解Array字段,将 good_id行数据转成多列展示
hive> select explode(split(goods_id,',')) as goods_id from explode_lateral_view;
OK
1
2
3
4
5
6
7
8
9
拆解Map字段,将area列拆解成多行多列
hive> with t1 as(select explode(split(area,',')) as area from explode_lateral_view)
> select split(area,':')[0],split(area,':')[1] from t1;
OK
a shandong
b beijing
c hebei
插解json字段
这个时候要配合使用一下regexp_replace和get_json_object
我们想获取所有的monthSales,第一步我们先把这个字段拆成list,并且拆成行展示:
hive> select explode(split(regexp_replace(regexp_replace(sale_info,'\\[\\{',''),'}]',''),'},\\{')) as sale_info from explode_lateral_view;
OK
"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"
"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"
"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"
Time taken: 5.206 seconds, Fetched: 3 row(s)
然后我们想用get_json_object来获取key为monthSales的数据:
select get_json_object(explode(split(regexp_replace(regexp_replace(sale_info,’\[\{’,’’),’}]’,’’),’},\{’)),’$.monthSales’) as sale_info from explode_lateral_view;
然后挂了FAILED: SemanticException [Error 10081]: UDTF’s are not supported outside the SELECT clause, nor nested in expressions
UDTF explode不能写在别的函数内
如果你这么写,想查两个字段,select explode(split(area,’,’)) as area,good_id from explode_lateral_view;
会报错FAILED: SemanticException 1:40 Only a single expression in the SELECT clause is supported with UDTF’s. Error encountered near token ‘good_id’
使用UDTF的时候,只支持一个字段,这时候就需要LATERAL VIEW出场了
LATERAL VIEW的使用:
侧视图的意义是配合explode(或者其他的UDTF),一个语句生成把单行数据拆解成多行后的数据结果集。
hive> select goods_id2,sale_info from explode_lateral_view LATERAL VIEW explode(split(goods_id,','))goods as goods_id2;
OK
1 [{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]
2 [{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]
3 [{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]
4 [{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]
5 [{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]
6 [{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]
7 [{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]
8 [{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]
9 [{"source":"7fresh","monthSales":4900,"userCount":1900,"score":"9.9"},{"source":"jd","monthSales":2090,"userCount":78981,"score":"9.8"},{"source":"jdmart","monthSales":6987,"userCount":1600,"score":"9.0"}]
Time taken: 0.746 seconds, Fetched: 9 row(s)
其中LATERAL VIEW explode(split(goods_id,’,’))goods相当于一个虚拟表,与原表explode_lateral_view笛卡尔积关联。
select goods_id2,sale_info,area2
from explode_lateral_view
LATERAL VIEW explode(split(goods_id,','))goods as goods_id2
LATERAL VIEW explode(split(area,','))area as area2;
也是三个表笛卡尔积的结果

现在我们解决一下上面的问题,从sale_info字段中找出所有的monthSales并且行展示
hive> select get_json_object(concat('{',sale_info_r,'}'),'$.monthSales') as monthSales from explode_lateral_view
> LATERAL VIEW explode(split(regexp_replace(regexp_replace(sale_info,'\\[\\{',''),'}]',''),'},\\{'))sale_info as sale_info_r;
OK
4900
2090
6987
Time taken: 0.719 seconds, Fetched: 3 row(s)
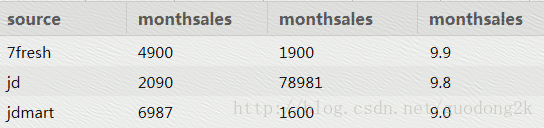
最终,我们可以通过下面的句子,把这个json格式的一行数据,完全转换成二维表的方式展现
select get_json_object(concat('{',sale_info_1,'}'),'$.source') as source,
get_json_object(concat('{',sale_info_1,'}'),'$.monthSales') as monthSales,
get_json_object(concat('{',sale_info_1,'}'),'$.userCount') as monthSales,
get_json_object(concat('{',sale_info_1,'}'),'$.score') as monthSales
from explode_lateral_view
LATERAL VIEW explode(split(regexp_replace(regexp_replace(sale_info,'\\[\\{',''),'}]',''),'},\\{'))sale_info as sale_info_1;
查询结果:
列传行 concat
1.concat()函数
CONCAT()函数用于将多个字符串连接成一个字符串。
语法:concat(sol1,col2,…,colN)
返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。可以有一个或多个参数。
hive> select id,name from employee limit 2;
OK
1000 刘能
1001 张三
--将2列合并为1列,以逗号分开
hive> select concat(id,',',name) as emp from employee limit 2;
OK
1000,刘能
1001,张三
hive> select concat(id,null,name) as emp from employee limit 2;
OK
NULL
NULL
2.concat_ws函数
语法:CONCAT_WS(separator,str1,str2,…)
CONCAT_WS() 代表 CONCAT With Separator ,是CONCAT()的特殊形式。第一个参数是其它参数的分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。如果分隔符为 NULL,则结果为 NULL。函数会忽略任何分隔符参数后的 NULL 值。但是CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。
hive> select concat_ws('_',id,name) as con_ws from employee limit 2;
FAILED: SemanticException [Error 10016]: Line 1:21 Argument type mismatch 'id': Argument 2 of function CONCAT_WS must be "string or array<string>", but "int" was found.
咦?我代码写错了?为什么不行看下报错,这里说concat_ws函数的参数类型必须是string、array<string>类型,而我们的id字段类型是int,原来使用此函数还有前提要求
下面换两个string类型的字段合并成一行试试:
hive> select concat_ws('_',name,leader) as con_ws from employee limit 2;
OK
刘能_刘能
张三_刘能
--concat_ws会忽略null值
hive> select concat_ws(',',name,null,leader) as concat_ws from employee limit 2;
OK
刘能,刘能
张三,刘能















 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









