






特征工程
EDA分析后,对特征进一步分析处理。
异常处理
通过箱线图分析删除异常值;
下边缘:Q1-1.5IQR
上边缘:Q3+1.5IQR
超出上下边缘的为异常值,这里将1.5改为3。
# 删除异常值
#代码封装
# 这里我包装了一个异常值处理的代码,可以随便调用。
def outliers_proc(data, col_name, scale=3):
"""
用于清洗异常值,默认用 box_plot(scale=3)进行清洗
:param data: 接收 pandas 数据格式
:param col_name: pandas 列名
:param scale: 尺度
:return:
"""
def box_plot_outliers(data_ser, box_scale):
"""
利用箱线图去除异常值
:param data_ser: 接收 pandas.Series 数据格式
:param box_scale: 箱线图尺度,
:return:
"""
iqr = box_scale * (data_ser.quantile(0.75) - data_ser.quantile(0.25))
val_low = data_ser.quantile(0.25) - iqr# 下边缘
val_up = data_ser.quantile(0.75) + iqr #上边缘
rule_low = (data_ser < val_low) # 超出下边缘的数据
rule_up = (data_ser > val_up) # 超出上边缘的数据
return (rule_low, rule_up), (val_low, val_up)
data_n = data.copy() # 如果要是深拷贝就是deep=true
data_series = data_n[col_name]
rule, value = box_plot_outliers(data_series, box_scale=scale)
index = np.arange(data_series.shape[0])[rule[0] | rule[1]] # 得到异常值的index
print("Delete number is: {}".format(len(index)))
data_n = data_n.drop(index)# 删除异常值后数据
data_n.reset_index(drop=True, inplace=True)
print("Now column number is: {}".format(data_n.shape[0]))
index_low = np.arange(data_series.shape[0])[rule[0]]#超出下边缘异常值的index
outliers = data_series.iloc[index_low]
print("Description of data less than the lower bound is:")
print(pd.Series(outliers).describe())
index_up = np.arange(data_series.shape[0])[rule[1]]#超出上边缘异常值的index
outliers = data_series.iloc[index_up]
print("Description of data larger than the upper bound is:")
print(pd.Series(outliers).describe())
# 删除异常值与未删除的箱型图对比。
fig, ax = plt.subplots(1, 2, figsize=(10, 7))
sns.boxplot(y=data[col_name], data=data, palette="Set1", ax=ax[0])
sns.boxplot(y=data_n[col_name], data=data_n, palette="Set1", ax=ax[1])
return data_n
3-sigma分析删除异常值:
数据符合正态分布:
至少有68%的数据,位于平均数1个标准差范围内(μ-σ,μ+σ)
至少有95%的数据,位于平均数2个标准差范围内(μ-2σ,μ+2σ)
至少有99.8%的数据,位于平均数3个标准差范围内(μ-3σ,μ+3σ)
二、初始值处理
不处理(针对类似 XGBoost 等树模型);
删除(缺失数据太多);
插值补全,包括均值/中位数/众数/建模预测/多重插补/压缩感知补全/矩阵补全等;
分箱,缺失值一个箱;
三、特征归一化/标准化
归一化:通过对原始数据进行变换把数据映射到(默认为[0,1])之间

通过公式可看出,最大值与最小值非常容易受异常点影响,鲁棒性较差,只适合传统精确小数据场景。
标准化:通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内

在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
幂律分布(长尾分布):少数点的数值特别高,大多数的点数值都很低,最大和最小的点之间,可能相差好几个数量级
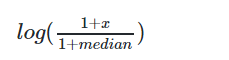
median为中位数
四、特征构造
构造统计量特征,报告计数、求和、比例、标准差等;

时间特征,包括相对时间和绝对时间,节假日,双休日等;

地理信息,包括分箱,分布编码等方法;

非线性变换,通过 log/ 平方/ 根号等方式转换;
五、数据分桶
# 数据分桶
# 种类:等频、等距、Best-KS、卡方分桶
# 以power为列
bin = [ i*10 for i in range(31)]
data['power_bin'] = pd.cut(data['power'],bin,labels=False)
data[['power_bin','power']].head()
六、特征筛选
过滤式:
1方差选择法:低方差特征过滤,删除低方差。
2相关系数: pearson:即针对线性数据,当0<|r|<1时,表示两变量存在一定程度的相关。且|r|越接近1,两变量间线性关系越密切;|r|越接近于0,表示两变量的线性相关越弱。
kendall:用于反映分类变量相关性的指标,即针对无序序列的相关系数,非正太分布的数据
spearman:非线性的,非正太分析的数据的相关系数
3.利用假设检验得到特征与输出值之间的相关性,方法有比如卡方检验、t检验、F检验等。
包裹式:
从初始特征集合中不断的选择特征子集,训练学习器,根据学习器的性能来对子集进行评价,直到选择出最佳的子集。但开销过大。
嵌入式:
算法自动选择特征(特征与目标值之间的关联)
逻辑回归、线性回归、决策树、L1和L2正则化等。
大部分情况下都是用嵌入式做特征筛选
七、特征降维:降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
PCA(主成分分析法):符合高斯分布的样本点比较有效,过某种线性投影,将高维的数据映射到低维的空间中表示,并期望在所投影的维度上数据的方差最大,以此使用较少的数据维度,同时保留住较多的原数据点的特性。
LDA(线性判别分析):一种有监督的(supervised)线性降维算法。与PCA保持数据信息不同,LDA是为了使得降维后的数据点尽可能地容易被区分!
ICA(独立成分分析法);对于高斯分布的样本点无效,对于其他分布的有效。
特征筛选也是一种降维
参考文章:https://tianchi.aliyun.com/notebook-ai/detail?postId=95501















 6062
6062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









