







目录
6、示例_通过FlinkSQL读取kafka在写入hive表
6.3、insert into 写入到 hdfs_sink_table
1、文件系统 SQL 连接器
文件系统连接器允许从本地或分布式文件系统进行读写数据
官网链接:文件系统 SQL 连接器

2、如何指定文件系统类型
创建表时通过 'path' = '协议名称:///path' 来指定 文件系统类型
参考官网:文件系统类型
CREATE TABLE filesystem_table (
id INT,
name STRING,
ds STRING
) partitioned by (ds) WITH (
'connector' = 'filesystem',
-- 本地文件系统
'path' = 'file:///URI',
-- HDFS文件系统
'path' = 'hdfs://URI',
-- 阿里云对象存储
'path' = 'oss://URI',
'format' = 'json'
);3、如何指定文件格式
FlinkSQL 文件系统连接器支持多种format,来读取和写入文件
比如当读取的source格式为 csv、json、Parquet... 可以在建表是指定相应的格式类型
来对数据进行解析后映射到表中的字段中

CREATE TABLE filesystem_table_file_format (
id INT,
name STRING,
ds STRING
) partitioned by (ds) WITH (
'connector' = 'filesystem',
-- 指定文件格式类型
'format' = 'json|csv|orc|raw'
);4、读取文件系统
FlinkSQL可以将单个文件或整个目录的数据读取到单个表中
注意:
1、当读取目录时,对目录中的文件进行 无序的读取
2、默认情况下,读取文件时为批处理模式,只会扫描配置路径一遍后就会停止
当开启目录监控(source.monitor-interval)时,才是流处理模式
4.1 开启 目录监控
通过设置 source.monitor-interval 属性来开启目录监控,以便在新文件出现时继续扫描
注意:
只会对指定目录内新增文件进行读取,不会读取更新后的旧文件
-- 目录监控
drop table filesystem_source_table;
CREATE TABLE filesystem_source_table (
id INT,
name STRING,
`file.name` STRING NOT NULL METADATA
) WITH (
'connector' = 'filesystem',
'path' = 'file:///usr/local/lib/mavne01/FlinkAPI1.17/data/output/1016',
'format' = 'json',
'source.monitor-interval' = '3' -- 开启目录监控,设置监控时间间隔
);
-- 持续读取
select * from filesystem_source_table;
4.2 可用的 Metadata
使用FLinkSQL读取文件系统中的数据时,支持对 metadata 进行读取
注意: 所有 metadata 都是只读的
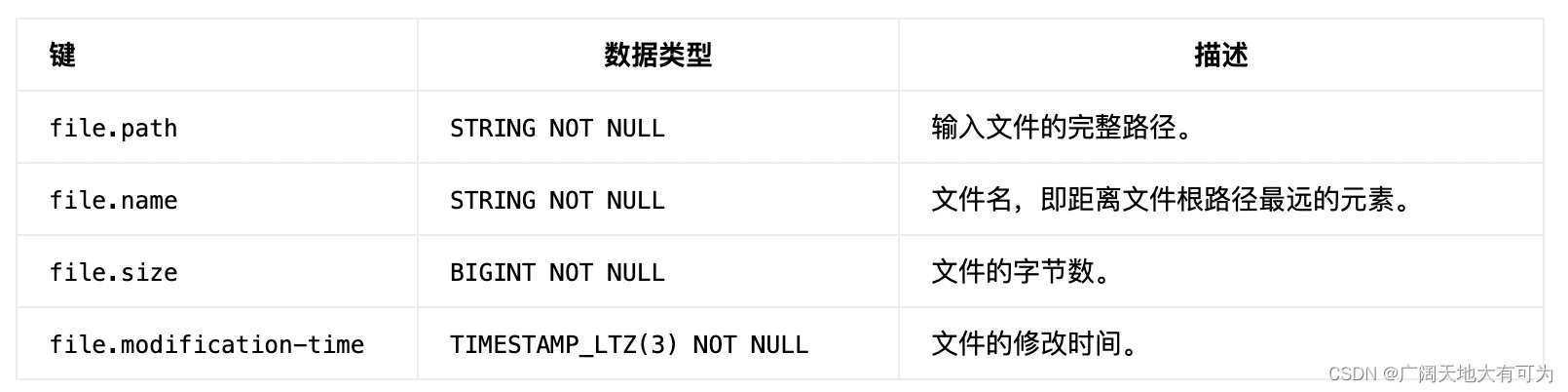
-- 可用的Metadata
drop table filesystem_source_table_read_metadata;
CREATE TABLE filesystem_source_table_read_metadata (
id INT,
name STRING,
`file.path` STRING NOT NULL METADATA,
`file.name` STRING NOT NULL METADATA,
`file.size` BIGINT NOT NULL METADATA,
`file.modification-time` TIMESTAMP_LTZ(3) NOT NULL METADATA
) WITH (
'connector' = 'filesystem',
'path' = 'file:///usr/local/lib/mavne01/FlinkAPI1.17/data/output/1012',
'format' = 'json'
);
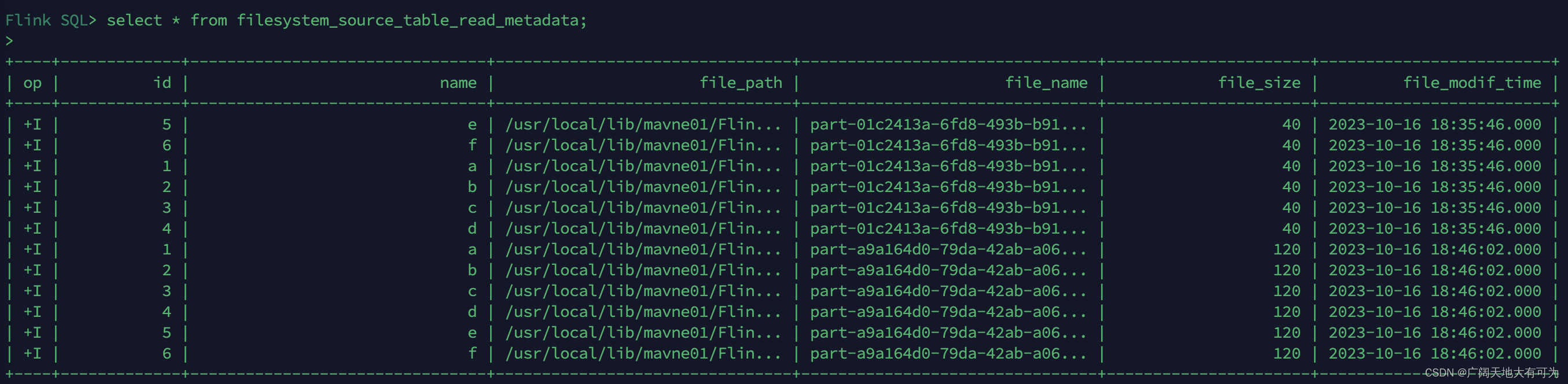
select * from filesystem_source_table_read_metadata;运行结果:
5、写出文件系统
5.1 创建分区表
FlinkSQL支持创建分区表,并且通过 insert into(追加) 和 insert overwrite(覆盖) 写入数据
-- 创建分区表
drop table filesystem_source_table_partition;
CREATE TABLE filesystem_source_table_partition (
id INT,
name STRING,
ds STRING
) partitioned by (ds) WITH (
'connector' = 'filesystem',
'path' = 'file:///usr/local/lib/mavne01/FlinkAPI1.17/data/output/1012',
'partition.default-name' = 'default_partition',
'format' = 'json'
);
-- 动态分区写入
insert into filesystem_source_table_partition
SELECT * FROM (VALUES
(1,'a','20231010')
, (2,'b','20231010')
, (3,'c','20231011')
, (4,'d','20231011')
, (5,'e','20231012')
, (6,'f','20231012')
) AS user1 (id,name,ds);
-- 静态分区写入
insert into filesystem_source_table_partition partition(ds = '20231010')
SELECT * FROM (VALUES
(1,'a')
, (2,'b')
, (3,'c')
, (4,'d')
, (5,'e')
, (6,'f')
) AS user1 (id,name);
-- 查询分区表数据
select * from filesystem_source_table_partition where ds = '20231010';5.2 滚动策略、文件合并、分区提交
可以看之前的博客:flink写入文件时分桶策略
官网链接:官网分桶策略
5.3 指定 Sink Parallelism
当使用FlinkSQL写出到文件系统时,可以通过 sink.parallelism 设置sink算子的并行度
注意:当且仅当上游的 changelog 模式为 INSERT-ONLY 时,才支持配置 sink parallelism。否则,程序将会抛出异常
CREATE TABLE hdfs_sink_table (
`log` STRING,
`dt` STRING, -- 分区字段,天
`hour` STRING -- 分区字段,小时
) partitioned by (dt,`hour`) WITH (
'connector' = 'filesystem',
'path' = 'file:///usr/local/lib/mavne01/FlinkAPI1.17/data/output/kafka',
'sink.parallelism' = '2', -- 指定sink算子并行度
'format' = 'raw'
);6、示例_通过FlinkSQL读取kafka在写入hive表
需求:
使用FlinkSQL将kafka数据写入到hdfs指定目录中
根据kafka的timestamp进行分区(按小时分区)
6.1、创建 kafka source表用于读取kafka
-- TODO 创建读取kafka表时,同时读取kafka元数据字段
drop table kafka_source_table;
CREATE TABLE kafka_source_table(
`log` STRING,
`timestamp` TIMESTAMP(3) METADATA FROM 'timestamp' -- 消息的时间戳
) WITH (
'connector' = 'kafka',
'topic' = '20231017',
'properties.bootstrap.servers' = 'worker01:9092',
'properties.group.id' = 'FlinkConsumer',
'scan.startup.mode' = 'earliest-offset',
'format' = 'raw'
);6.2、创建 hdfs sink表用于写出到hdfs
drop table hdfs_sink_table;
CREATE TABLE hdfs_sink_table (
`log` STRING,
`dt` STRING, -- 分区字段,天
`hour` STRING -- 分区字段,小时
) partitioned by (dt,`hour`) WITH (
'connector' = 'filesystem',
'path' = 'hdfs://usr/local/lib/mavne01/FlinkAPI1.17/data/output/kafka',
'sink.parallelism' = '2', -- 指定sink算子并行度
'format' = 'raw'
);6.3、insert into 写入到 hdfs_sink_table
-- 流式 sql,插入文件系统表
insert into hdfs_sink_table
select
log
,DATE_FORMAT(`timestamp`,'yyyyMMdd') as dt
,DATE_FORMAT(`timestamp`,'HH') as `hour`
from kafka_source_table;6.4、查询 hdfs_sink_table
-- 批式 sql,使用分区修剪进行选择
select * from hdfs_sink_table;6.5、创建hive表,指定local
create table `kafka_to_hive` (
`log` string comment '日志数据')
comment '埋点日志数据' PARTITIONED BY (dt string,`hour` string)
row format delimited fields terminated by '\t' lines terminated by '\n' stored as orc
LOCATION 'hdfs://usr/local/lib/mavne01/FlinkAPI1.17/data/output/kafka';















 1218
1218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









