







【x264】分析模块(analyse)的简单分析
参考:
雷霄骅博士, x264源代码简单分析:宏块分析(Analysis)部分-帧内宏块(Intra)
参数分析:
【x264】x264编码器参数配置
流程分析:
【x264】x264编码主流程简单分析
【x264】编码核心函数(x264_encoder_encode)的简单分析
1. 分析模块(analyse)概述
在x264当中,编码器首先会将一帧图像分成若干个小的图像块(macro block, mb),每一个块当中包含若干个像素点,这些块又可以被称之为像素块。这种操作称之为块划分操作,这里的分析模块就是针对于每一个小的图像块进行处理的。
分析模块主要执行的任务是对宏块进行预测,预测的主要思想是以当前块的参考块作为依据,使用不同的预测模式,进行预测操作,获得一个预测块,随后将获得的预测块和当前块进行对比,获得一个差值,将这个差值进行变换、量化和编码,最后评估当前的预测模式是否是最合适的。在解码端,基于这个块的残差值和参考块的重建值,能够获取解码之后块的值,此外,由于帧的类型有所不同,预测的模式也有差异,例如I帧(Intra帧),P帧(Inter-Prediciton)还有B帧(Inter-Bi-Prediction),I帧当中的块只进行帧内预测,P帧中的块主要进行前向预测,B帧中的块主要进行前后向双向预测。但是,mb的预测方式和帧的类型并不是完全一致,有些P帧中的mb块也会进行帧内预测,但数量很少。
这里应该思考的问题有:
1.1 预测的意义
使用这个工具会考虑到一个问题,为什么要进行分析预测,随后计算编码残差以及进行变换量化呢?通过预测,能够获取一个预测块,如果预测的策略比较合适,那么预测块和原始块差异比较小,如果计算两者的残差值,并且将二者的残差值进行变换、量化和熵编码,这样码流文件就比较小。如果存储的是原始块,码流文件就会很大,这样不符合编码器想要高效压缩视频流的初衷。
值得注意的是,如果编码的帧是Intra帧,这一帧由于是后面很多帧的参考帧,使用了很多高性能的编码策略,所以这一帧的码流是比较大的。
1.2 预测的重要组成变量
在进行预测时,最重要的组成变量包括:图像块的原始像素、预测像素、残差像素和重建像素。那么在编解码前后,它们之间的关系是怎样的?
下面举例说明这几个变量在编解码前后的关系,假设现在使用帧内预测,已经编码了2个mb,分别记录为a和b,现在要编码的块为c,且3个块都位于当前帧的最上方的一行,如下所示。在这种情况下,b的参考块为a,c的参考块为b(参考块只能位于当前块的左侧或者上方),而a没有参考块。
// a b c
// …
// …
// …
…
在编码流程当中,如果a已经进行了编码,后续的b如果要参考a,会进行a的重建,获得一个重建的a_rec,b在进行预测时,参考的是重建的a_rec。在码流当中,存储b的信息时,存储的是残差信息而不是原始信息,解码b时必须依赖b的残差和a的重建。对于这样一个过程,有如下的梳理
org = original(原始像素)
res = residual(残差像素)
pre = predict(预测像素)
rec = reconstruction(重建像素)
(1)b的编解码
编码时:b_res = b_org - b_pre (b的残差 = b的原始 - b的预测)
解码时:b_rec = b_res + a_rec (b的重建 = b的残差 + a的重建)
可以看到,在解码时,b的重建是依赖于a的重建的;同理,有如下的情况:
(2)c的编解码
编码时:c_res = c_org - c_pre(c的残差 = c的原始 - c的预测)
解码时:c_rec = c_res + b_rec(c的重建 = c的残差 + b的重建)
结合上面的(1)和(2),进行移项,有:
b_org = b_res + b_pre
b_rec = b_res + a_rec
c_org = c_res + c_pre
c_rec = c_res + b_rec
由于编解码器的重要目标之一是保证编解码前后的像素之差较小,即b和c的org尽可能接近rec,结合上式有:
b_pre = a_rec
c_pre = b_rec
即b的预测值应该由a的重建值描述,c的预测值由b的重建值描述。换一种说法是,b的预测过程的参考块应该是a的重建块,而c的预测过程中的参考块应该是b的重建块。
如果用一段话来描述这一过程,我想可以这么来描述:
残差信息在经过处理之后会存储在码流当中,为了展示传输过来的图像,需要将当前图像的残差信息和前面图像的重建信息结合,获得当前的图像。同时,第一幅图像的原始编码是高质量编码的,且后面图像参考第一幅图像时进行了高质量的预测,所以能够获得很好的图像展示效果
1.3 预测的模式
预测的模式取决于帧的类型和实际编码的情况,一般而言,Intra帧当中的像素块只进行帧内预测,P帧进行前向参考,B帧进行前后向同时参考,其中P帧和B帧当中的像素块还有可能进行帧内预测。此外,在特殊情况下还会使用PCM模式,即直接存储像素而不进行变换量化。
由于同一个区域内的像素值比较接近,帧内预测可以使用一些特定的预测模式作为模板。其中,16x16的亮度块和8x8的色度块会使用的水平(horizontal)、垂直(vertical)、直流(DC)和平面(plane)模式,4x4的亮度块除了上述4种之外,还会增加水平向下、垂直向右等角度模式。相对比而言,帧间预测由于前后帧运动的方向不确定,不好给出一个预测的模板,使用了一种灵活的描述方式叫做运动向量,先在前后帧当中寻找一个比较接近的像素块,再用运动向量来描述参考块和当前块之间的差异,这个运动向量就是帧间预测的模式
2. 预测主函数(x264_macroblock_analyse)
进行预测的主函数入口位于x264_macroblock_analyse,其定义位于encoder/analyse.c当中。其主要的工作流程为:
- 码控获取qp
- 宏块分析的初始化
- 帧内预测
帧内预测通过一系列的预测模式,确定一个Intra mb的最佳模式。主要流程如下
(1) 从16×16的SAD,4个8×8的SAD和,16个4×4的SAD中选出最优方式(mb_analyse_intra)
(2)先考虑16x16块的损失,再与8x8和4x4的损失进行比较,选择一个最佳的 - P帧的帧间预测
帧间预测分为P帧和B帧,P帧的预测只考虑前向,B帧的预测考虑前向和后向。P帧的预测主要流程如下
(1)检测是否使用P-Skip模式,如果是则将mv设置为0,同时结束预测过程
(2)检查16x16的损失(mb_analyse_inter_p16x16)
(3)检查8x8的损失(mb_analyse_inter_p8x8)
(4)如果8x8的损失小于16x16,则执行8x8的分块处理;处理的数据源自于l0
(5)8x8块的子块的分析(mb_analyse_inter_p4x4)
(6)如果4x4小于8x8,则进行8x4以及4x8尺寸的检查(mb_analyse_inter_p4x8、mb_analyse_inter_p8x4)
(7)如果8x8的代价值小于16x16+16x8,则进行16x8和8x16尺寸的检查(mb_analyse_inter_p16x8、mb_analyse_inter_p8x16)
(8)亚像素精度估计(x264_me_refine_qpel),根据不同的划分方式,输入的cost也不同
(9)对色度分量检查是否进行帧间预测(mb_analyse_intra_chroma),否则就进行帧内预测(mb_analyse_intra)
(9)运动估计的亚像素rd优化(x264_me_refine_qpel_rd) - B帧的帧间预测(与P帧类似,但是预测的方向为前后两个方向)
- 从分析中更新MB(analyse_update_cache)
void x264_macroblock_analyse( x264_t *h )
{
x264_mb_analysis_t analysis;
int i_cost = COST_MAX;
// ----- 1.码控获取qp ----- //
h->mb.i_qp = x264_ratecontrol_mb_qp( h );
/* If the QP of this MB is within 1 of the previous MB, code the same QP as the previous MB,
* to lower the bit cost of the qp_delta. Don't do this if QPRD is enabled. */
if( h->param.rc.i_aq_mode && h->param.analyse.i_subpel_refine < 10 )
h->mb.i_qp = abs(h->mb.i_qp - h->mb.i_last_qp) == 1 ? h->mb.i_last_qp : h->mb.i_qp;
if( h->param.analyse.b_mb_info )
h->fdec->effective_qp[h->mb.i_mb_xy] = h->mb.i_qp; /* Store the real analysis QP. */
// ----- 2.宏块分析的初始化 ----- //
mb_analyse_init( h, &analysis, h->mb.i_qp );
/*--------------------------- Do the analysis ---------------------------*/
// ----- 3.帧内预测 ----- //
// 通过一系列的帧内预测模式,计算出代价最小的最优模式
if( h->sh.i_type == SLICE_TYPE_I )
{
intra_analysis:
// i_mbrd表示宏块的运动搜索过程中所使用的模式的数量
if( analysis.i_mbrd )
mb_init_fenc_cache( h, analysis.i_mbrd >= 2 );
// 进行帧内预测,从16×16的SAD,4个8×8的SAD和,16个4×4SAD中选出最优方式
mb_analyse_intra( h, &analysis, COST_MAX );
if( analysis.i_mbrd )
intra_rd( h, &analysis, COST_MAX ); // 计算使用的比特数量
i_cost = analysis.i_satd_i16x16;
h->mb.i_type = I_16x16;
// 检查4x4和8x8的开销是否更小
COPY2_IF_LT( i_cost, analysis.i_satd_i4x4, h->mb.i_type, I_4x4 );
COPY2_IF_LT( i_cost, analysis.i_satd_i8x8, h->mb.i_type, I_8x8 );
if( analysis.i_satd_pcm < i_cost )
h->mb.i_type = I_PCM;
else if( analysis.i_mbrd >= 2 ) // 如果模式数量大于等于2,则再进行一次refine
intra_rd_refine( h, &analysis );
}
else if( h->sh.i_type == SLICE_TYPE_P )
{ // ----- 4.P帧的预测 ----- //
int b_skip = 0;
// 预取一个参考帧的下几个宏块
h->mc.prefetch_ref( h->mb.pic.p_fref[0][0][h->mb.i_mb_x&3], h->mb.pic.i_stride[0], 0 );
analysis.b_try_skip = 0;
if( analysis.b_force_intra ) // 如果强制进行帧内预测
{
if( !h->param.analyse.b_psy )
{
mb_analyse_init_qp( h, &analysis, X264_MAX( h->mb.i_qp - h->mb.ip_offset, h->param.rc.i_qp_min ) );
goto intra_analysis;
}
}
else
{
/* Special fast-skip logic using information from mb_info. */
if( h->fdec->mb_info && (h->fdec->mb_info[h->mb.i_mb_xy]&X264_MBINFO_CONSTANT) )
{
if( !SLICE_MBAFF && (h->fdec->i_frame - h->fref[0][0]->i_frame) == 1 && !h->sh.b_weighted_pred &&
h->fref[0][0]->effective_qp[h->mb.i_mb_xy] <= h->mb.i_qp )
{
h->mb.i_partition = D_16x16;
/* Use the P-SKIP MV if we can... */
if( !M32(h->mb.cache.pskip_mv) )
{
b_skip = 1;
h->mb.i_type = P_SKIP;
}
/* Otherwise, just force a 16x16 block. */
else
{
h->mb.i_type = P_L0;
analysis.l0.me16x16.i_ref = 0;
M32( analysis.l0.me16x16.mv ) = 0;
}
goto skip_analysis;
}
/* Reset the information accordingly */
else if( h->param.analyse.b_mb_info_update )
h->fdec->mb_info[h->mb.i_mb_xy] &= ~X264_MBINFO_CONSTANT;
}
int skip_invalid = h->i_thread_frames > 1 && h->mb.cache.pskip_mv[1] > h->mb.mv_max_spel[1];
/* If the current macroblock is off the frame, just skip it. */
if( HAVE_INTERLACED && !MB_INTERLACED && h->mb.i_mb_y * 16 >= h->param.i_height && !skip_invalid )
b_skip = 1;
/* Fast P_SKIP detection */
// 快速P-Skip检测
else if( h->param.analyse.b_fast_pskip )
{
if( skip_invalid )
// FIXME don't need to check this if the reference frame is done
{}
else if( h->param.analyse.i_subpel_refine >= 3 )
analysis.b_try_skip = 1;
else if( h->mb.i_mb_type_left[0] == P_SKIP ||
h->mb.i_mb_type_top == P_SKIP ||
h->mb.i_mb_type_topleft == P_SKIP ||
h->mb.i_mb_type_topright == P_SKIP )
b_skip = x264_macroblock_probe_pskip( h );
}
}
h->mc.prefetch_ref( h->mb.pic.p_fref[0][0][h->mb.i_mb_x&3], h->mb.pic.i_stride[0], 1 );
// 检查是否是skip模式,如果不是则按顺序进行16x16、8x8、8x4(4x8)、4x4尺寸的检查
if( b_skip ) // 使用skip模式
{
h->mb.i_type = P_SKIP;
h->mb.i_partition = D_16x16;
assert( h->mb.cache.pskip_mv[1] <= h->mb.mv_max_spel[1] || h->i_thread_frames == 1 );
skip_analysis:
/* Set up MVs for future predictors */
for( int i = 0; i < h->mb.pic.i_fref[0]; i++ )
M32( h->mb.mvr[0][i][h->mb.i_mb_xy] ) = 0;
}
else
{
const unsigned int flags = h->param.analyse.inter;
int i_type;
int i_partition;
int i_satd_inter, i_satd_intra;
// 为所有可能的MVS初始化一个lambda*nbits数组
mb_analyse_load_costs( h, &analysis );
// 检查16x16的损失
mb_analyse_inter_p16x16( h, &analysis );
if( h->mb.i_type == P_SKIP )
{
for( int i = 1; i < h->mb.pic.i_fref[0]; i++ )
M32( h->mb.mvr[0][i][h->mb.i_mb_xy] ) = 0;
return;
}
if( flags & X264_ANALYSE_PSUB16x16 )
{
if( h->param.analyse.b_mixed_references )
mb_analyse_inter_p8x8_mixed_ref( h, &analysis );
else
mb_analyse_inter_p8x8( h, &analysis ); // 检查8x8的损失
}
// 选择一个最好的帧间模式
/* Select best inter mode */
i_type = P_L0;
i_partition = D_16x16;
i_cost = analysis.l0.me16x16.cost;
// 如果8x8的损失小于16x16,则执行8x8的分块处理;处理的数据源自于l0
if( ( flags & X264_ANALYSE_PSUB16x16 ) && (!analysis.b_early_terminate ||
analysis.l0.i_cost8x8 < analysis.l0.me16x16.cost) )
{
i_type = P_8x8;
i_partition = D_8x8;
i_cost = analysis.l0.i_cost8x8;
/* Do sub 8x8 */
if( flags & X264_ANALYSE_PSUB8x8 )
{
for( int i = 0; i < 4; i++ )
{
//8x8块的子块的分析
/*
* 4x4
* +----+----+
* | | |
* +----+----+
* | | |
* +----+----+
*
*/
mb_analyse_inter_p4x4( h, &analysis, i );
int i_thresh8x4 = analysis.l0.me4x4[i][1].cost_mv + analysis.l0.me4x4[i][2].cost_mv;
// 如果4x4小于8x8,则进行8x4以及4x8尺寸的检查
if( !analysis.b_early_terminate || analysis.l0.i_cost4x4[i] < analysis.l0.me8x8[i].cost + i_thresh8x4 )
{
int i_cost8x8 = analysis.l0.i_cost4x4[i];
h->mb.i_sub_partition[i] = D_L0_4x4;
mb_analyse_inter_p8x4( h, &analysis, i );
COPY2_IF_LT( i_cost8x8, analysis.l0.i_cost8x4[i],
h->mb.i_sub_partition[i], D_L0_8x4 );
mb_analyse_inter_p4x8( h, &analysis, i );
COPY2_IF_LT( i_cost8x8, analysis.l0.i_cost4x8[i],
h->mb.i_sub_partition[i], D_L0_4x8 );
i_cost += i_cost8x8 - analysis.l0.me8x8[i].cost;
}
mb_cache_mv_p8x8( h, &analysis, i );
}
analysis.l0.i_cost8x8 = i_cost;
}
}
/* Now do 16x8/8x16 */
int i_thresh16x8 = analysis.l0.me8x8[1].cost_mv + analysis.l0.me8x8[2].cost_mv;
// 如果8x8的代价值小于16x16+16x8,则进行16x8和8x16尺寸的检查
if( ( flags & X264_ANALYSE_PSUB16x16 ) && (!analysis.b_early_terminate ||
analysis.l0.i_cost8x8 < analysis.l0.me16x16.cost + i_thresh16x8) )
{
int i_avg_mv_ref_cost = (analysis.l0.me8x8[2].cost_mv + analysis.l0.me8x8[2].i_ref_cost
+ analysis.l0.me8x8[3].cost_mv + analysis.l0.me8x8[3].i_ref_cost + 1) >> 1;
analysis.i_cost_est16x8[1] = analysis.i_satd8x8[0][2] + analysis.i_satd8x8[0][3] + i_avg_mv_ref_cost;
// 16x8宏块划分
mb_analyse_inter_p16x8( h, &analysis, i_cost );
COPY3_IF_LT( i_cost, analysis.l0.i_cost16x8, i_type, P_L0, i_partition, D_16x8 );
i_avg_mv_ref_cost = (analysis.l0.me8x8[1].cost_mv + analysis.l0.me8x8[1].i_ref_cost
+ analysis.l0.me8x8[3].cost_mv + analysis.l0.me8x8[3].i_ref_cost + 1) >> 1;
analysis.i_cost_est8x16[1] = analysis.i_satd8x8[0][1] + analysis.i_satd8x8[0][3] + i_avg_mv_ref_cost;
// 8x16宏块划分
mb_analyse_inter_p8x16( h, &analysis, i_cost );
COPY3_IF_LT( i_cost, analysis.l0.i_cost8x16, i_type, P_L0, i_partition, D_8x16 );
}
h->mb.i_partition = i_partition;
// 亚像素精度估计
/* refine qpel */
//FIXME mb_type costs?
if( analysis.i_mbrd || !h->mb.i_subpel_refine )
{
/* refine later */
}
else if( i_partition == D_16x16 )
{
x264_me_refine_qpel( h, &analysis.l0.me16x16 );
i_cost = analysis.l0.me16x16.cost;
}
else if( i_partition == D_16x8 )
{
x264_me_refine_qpel( h, &analysis.l0.me16x8[0] );
x264_me_refine_qpel( h, &analysis.l0.me16x8[1] );
i_cost = analysis.l0.me16x8[0].cost + analysis.l0.me16x8[1].cost;
}
else if( i_partition == D_8x16 )
{
x264_me_refine_qpel( h, &analysis.l0.me8x16[0] );
x264_me_refine_qpel( h, &analysis.l0.me8x16[1] );
i_cost = analysis.l0.me8x16[0].cost + analysis.l0.me8x16[1].cost;
}
else if( i_partition == D_8x8 )
{
i_cost = 0;
for( int i8x8 = 0; i8x8 < 4; i8x8++ )
{
switch( h->mb.i_sub_partition[i8x8] )
{
case D_L0_8x8:
x264_me_refine_qpel( h, &analysis.l0.me8x8[i8x8] );
i_cost += analysis.l0.me8x8[i8x8].cost;
break;
case D_L0_8x4:
x264_me_refine_qpel( h, &analysis.l0.me8x4[i8x8][0] );
x264_me_refine_qpel( h, &analysis.l0.me8x4[i8x8][1] );
i_cost += analysis.l0.me8x4[i8x8][0].cost +
analysis.l0.me8x4[i8x8][1].cost;
break;
case D_L0_4x8:
x264_me_refine_qpel( h, &analysis.l0.me4x8[i8x8][0] );
x264_me_refine_qpel( h, &analysis.l0.me4x8[i8x8][1] );
i_cost += analysis.l0.me4x8[i8x8][0].cost +
analysis.l0.me4x8[i8x8][1].cost;
break;
case D_L0_4x4:
x264_me_refine_qpel( h, &analysis.l0.me4x4[i8x8][0] );
x264_me_refine_qpel( h, &analysis.l0.me4x4[i8x8][1] );
x264_me_refine_qpel( h, &analysis.l0.me4x4[i8x8][2] );
x264_me_refine_qpel( h, &analysis.l0.me4x4[i8x8][3] );
i_cost += analysis.l0.me4x4[i8x8][0].cost +
analysis.l0.me4x4[i8x8][1].cost +
analysis.l0.me4x4[i8x8][2].cost +
analysis.l0.me4x4[i8x8][3].cost;
break;
default:
x264_log( h, X264_LOG_ERROR, "internal error (!8x8 && !4x4)\n" );
break;
}
}
}
// 是否进行色度分量的运动估计
if( h->mb.b_chroma_me )
{
if( CHROMA444 )
{
mb_analyse_intra( h, &analysis, i_cost );
mb_analyse_intra_chroma( h, &analysis );
}
else
{
mb_analyse_intra_chroma( h, &analysis );
mb_analyse_intra( h, &analysis, i_cost - analysis.i_satd_chroma );
}
analysis.i_satd_i16x16 += analysis.i_satd_chroma;
analysis.i_satd_i8x8 += analysis.i_satd_chroma;
analysis.i_satd_i4x4 += analysis.i_satd_chroma;
}
else
mb_analyse_intra( h, &analysis, i_cost ); // P Slice中也允许有Intra宏块,也要进行分析
i_satd_inter = i_cost;
i_satd_intra = X264_MIN3( analysis.i_satd_i16x16,
analysis.i_satd_i8x8,
analysis.i_satd_i4x4 );
if( analysis.i_mbrd )
{
// 速率失真最优QP选择
mb_analyse_p_rd( h, &analysis, X264_MIN(i_satd_inter, i_satd_intra) );
i_type = P_L0;
i_partition = D_16x16;
i_cost = analysis.l0.i_rd16x16;
COPY2_IF_LT( i_cost, analysis.l0.i_cost16x8, i_partition, D_16x8 );
COPY2_IF_LT( i_cost, analysis.l0.i_cost8x16, i_partition, D_8x16 );
COPY3_IF_LT( i_cost, analysis.l0.i_cost8x8, i_partition, D_8x8, i_type, P_8x8 );
h->mb.i_type = i_type;
h->mb.i_partition = i_partition;
if( i_cost < COST_MAX )
mb_analyse_transform_rd( h, &analysis, &i_satd_inter, &i_cost );
intra_rd( h, &analysis, i_satd_inter * 5/4 + 1 );
}
// 获取最小的损失
COPY2_IF_LT( i_cost, analysis.i_satd_i16x16, i_type, I_16x16 );
COPY2_IF_LT( i_cost, analysis.i_satd_i8x8, i_type, I_8x8 );
COPY2_IF_LT( i_cost, analysis.i_satd_i4x4, i_type, I_4x4 );
COPY2_IF_LT( i_cost, analysis.i_satd_pcm, i_type, I_PCM );
h->mb.i_type = i_type;
if( analysis.b_force_intra && !IS_INTRA(i_type) )
{
/* Intra masking: copy fdec to fenc and re-encode the block as intra in order to make it appear as if
* it was an inter block. */
analyse_update_cache( h, &analysis );
x264_macroblock_encode( h );
for( int p = 0; p < (CHROMA444 ? 3 : 1); p++ )
h->mc.copy[PIXEL_16x16]( h->mb.pic.p_fenc[p], FENC_STRIDE, h->mb.pic.p_fdec[p], FDEC_STRIDE, 16 );
if( !CHROMA444 )
{
int height = 16 >> CHROMA_V_SHIFT;
h->mc.copy[PIXEL_8x8] ( h->mb.pic.p_fenc[1], FENC_STRIDE, h->mb.pic.p_fdec[1], FDEC_STRIDE, height );
h->mc.copy[PIXEL_8x8] ( h->mb.pic.p_fenc[2], FENC_STRIDE, h->mb.pic.p_fdec[2], FDEC_STRIDE, height );
}
mb_analyse_init_qp( h, &analysis, X264_MAX( h->mb.i_qp - h->mb.ip_offset, h->param.rc.i_qp_min ) );
goto intra_analysis;
}
if( analysis.i_mbrd >= 2 && h->mb.i_type != I_PCM )
{
if( IS_INTRA( h->mb.i_type ) )
{
intra_rd_refine( h, &analysis );
}
else if( i_partition == D_16x16 )
{
x264_macroblock_cache_ref( h, 0, 0, 4, 4, 0, analysis.l0.me16x16.i_ref );
analysis.l0.me16x16.cost = i_cost;
x264_me_refine_qpel_rd( h, &analysis.l0.me16x16, analysis.i_lambda2, 0, 0 );
}
else if( i_partition == D_16x8 )
{
M32( h->mb.i_sub_partition ) = D_L0_8x8 * 0x01010101;
x264_macroblock_cache_ref( h, 0, 0, 4, 2, 0, analysis.l0.me16x8[0].i_ref );
x264_macroblock_cache_ref( h, 0, 2, 4, 2, 0, analysis.l0.me16x8[1].i_ref );
x264_me_refine_qpel_rd( h, &analysis.l0.me16x8[0], analysis.i_lambda2, 0, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me16x8[1], analysis.i_lambda2, 8, 0 );
}
else if( i_partition == D_8x16 )
{
M32( h->mb.i_sub_partition ) = D_L0_8x8 * 0x01010101;
x264_macroblock_cache_ref( h, 0, 0, 2, 4, 0, analysis.l0.me8x16[0].i_ref );
x264_macroblock_cache_ref( h, 2, 0, 2, 4, 0, analysis.l0.me8x16[1].i_ref );
x264_me_refine_qpel_rd( h, &analysis.l0.me8x16[0], analysis.i_lambda2, 0, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me8x16[1], analysis.i_lambda2, 4, 0 );
}
else if( i_partition == D_8x8 )
{
analyse_update_cache( h, &analysis );
for( int i8x8 = 0; i8x8 < 4; i8x8++ )
{
if( h->mb.i_sub_partition[i8x8] == D_L0_8x8 )
{
x264_me_refine_qpel_rd( h, &analysis.l0.me8x8[i8x8], analysis.i_lambda2, i8x8*4, 0 );
}
else if( h->mb.i_sub_partition[i8x8] == D_L0_8x4 )
{
x264_me_refine_qpel_rd( h, &analysis.l0.me8x4[i8x8][0], analysis.i_lambda2, i8x8*4+0, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me8x4[i8x8][1], analysis.i_lambda2, i8x8*4+2, 0 );
}
else if( h->mb.i_sub_partition[i8x8] == D_L0_4x8 )
{
x264_me_refine_qpel_rd( h, &analysis.l0.me4x8[i8x8][0], analysis.i_lambda2, i8x8*4+0, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me4x8[i8x8][1], analysis.i_lambda2, i8x8*4+1, 0 );
}
else if( h->mb.i_sub_partition[i8x8] == D_L0_4x4 )
{
x264_me_refine_qpel_rd( h, &analysis.l0.me4x4[i8x8][0], analysis.i_lambda2, i8x8*4+0, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me4x4[i8x8][1], analysis.i_lambda2, i8x8*4+1, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me4x4[i8x8][2], analysis.i_lambda2, i8x8*4+2, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me4x4[i8x8][3], analysis.i_lambda2, i8x8*4+3, 0 );
}
}
}
}
}
}
else if( h->sh.i_type == SLICE_TYPE_B ) // B帧的预测
{ // ----- 5.B帧的帧间预测 ----- //
int i_bskip_cost = COST_MAX;
int b_skip = 0;
if( analysis.i_mbrd )
mb_init_fenc_cache( h, analysis.i_mbrd >= 2 );
h->mb.i_type = B_SKIP;
if( h->mb.b_direct_auto_write )
{
/* direct=auto heuristic: prefer whichever mode allows more Skip macroblocks */
for( int i = 0; i < 2; i++ )
{
int b_changed = 1;
h->sh.b_direct_spatial_mv_pred ^= 1;
analysis.b_direct_available = x264_mb_predict_mv_direct16x16( h, i && analysis.b_direct_available ? &b_changed : NULL );
if( analysis.b_direct_available )
{
if( b_changed )
{
x264_mb_mc( h );
b_skip = x264_macroblock_probe_bskip( h );
}
h->stat.frame.i_direct_score[ h->sh.b_direct_spatial_mv_pred ] += b_skip;
}
else
b_skip = 0;
}
}
else
analysis.b_direct_available = x264_mb_predict_mv_direct16x16( h, NULL );
analysis.b_try_skip = 0;
if( analysis.b_direct_available )
{
if( !h->mb.b_direct_auto_write )
x264_mb_mc( h );
/* If the current macroblock is off the frame, just skip it. */
if( HAVE_INTERLACED && !MB_INTERLACED && h->mb.i_mb_y * 16 >= h->param.i_height )
b_skip = 1;
else if( analysis.i_mbrd )
{
i_bskip_cost = ssd_mb( h );
/* 6 = minimum cavlc cost of a non-skipped MB */
b_skip = h->mb.b_skip_mc = i_bskip_cost <= ((6 * analysis.i_lambda2 + 128) >> 8);
}
else if( !h->mb.b_direct_auto_write )
{
/* Conditioning the probe on neighboring block types
* doesn't seem to help speed or quality. */
analysis.b_try_skip = x264_macroblock_probe_bskip( h );
if( h->param.analyse.i_subpel_refine < 3 )
b_skip = analysis.b_try_skip;
}
/* Set up MVs for future predictors */
if( b_skip )
{
for( int i = 0; i < h->mb.pic.i_fref[0]; i++ )
M32( h->mb.mvr[0][i][h->mb.i_mb_xy] ) = 0;
for( int i = 0; i < h->mb.pic.i_fref[1]; i++ )
M32( h->mb.mvr[1][i][h->mb.i_mb_xy] ) = 0;
}
}
if( !b_skip )
{
const unsigned int flags = h->param.analyse.inter;
int i_type;
int i_partition;
int i_satd_inter;
h->mb.b_skip_mc = 0;
h->mb.i_type = B_DIRECT;
mb_analyse_load_costs( h, &analysis );
/* select best inter mode */
/* direct must be first */
if( analysis.b_direct_available )
mb_analyse_inter_direct( h, &analysis );
// 进行16x16的预测
mb_analyse_inter_b16x16( h, &analysis );
if( h->mb.i_type == B_SKIP )
{
for( int i = 1; i < h->mb.pic.i_fref[0]; i++ )
M32( h->mb.mvr[0][i][h->mb.i_mb_xy] ) = 0;
for( int i = 1; i < h->mb.pic.i_fref[1]; i++ )
M32( h->mb.mvr[1][i][h->mb.i_mb_xy] ) = 0;
return;
}
i_type = B_L0_L0;
i_partition = D_16x16;
i_cost = analysis.l0.me16x16.cost;
COPY2_IF_LT( i_cost, analysis.l1.me16x16.cost, i_type, B_L1_L1 );
COPY2_IF_LT( i_cost, analysis.i_cost16x16bi, i_type, B_BI_BI );
COPY2_IF_LT( i_cost, analysis.i_cost16x16direct, i_type, B_DIRECT );
if( analysis.i_mbrd && analysis.b_early_terminate && analysis.i_cost16x16direct <= i_cost * 33/32 )
{
mb_analyse_b_rd( h, &analysis, i_cost );
if( i_bskip_cost < analysis.i_rd16x16direct &&
i_bskip_cost < analysis.i_rd16x16bi &&
i_bskip_cost < analysis.l0.i_rd16x16 &&
i_bskip_cost < analysis.l1.i_rd16x16 )
{
h->mb.i_type = B_SKIP;
analyse_update_cache( h, &analysis );
return;
}
}
if( flags & X264_ANALYSE_BSUB16x16 )
{
// 进行8x8的预测
if( h->param.analyse.b_mixed_references )
mb_analyse_inter_b8x8_mixed_ref( h, &analysis );
else
mb_analyse_inter_b8x8( h, &analysis );
COPY3_IF_LT( i_cost, analysis.i_cost8x8bi, i_type, B_8x8, i_partition, D_8x8 );
/* Try to estimate the cost of b16x8/b8x16 based on the satd scores of the b8x8 modes */
int i_cost_est16x8bi_total = 0, i_cost_est8x16bi_total = 0;
int i_mb_type, i_partition16x8[2], i_partition8x16[2];
for( int i = 0; i < 2; i++ )
{
int avg_l0_mv_ref_cost, avg_l1_mv_ref_cost;
int i_l0_satd, i_l1_satd, i_bi_satd, i_best_cost;
// 16x8
i_best_cost = COST_MAX;
i_l0_satd = analysis.i_satd8x8[0][i*2] + analysis.i_satd8x8[0][i*2+1];
i_l1_satd = analysis.i_satd8x8[1][i*2] + analysis.i_satd8x8[1][i*2+1];
i_bi_satd = analysis.i_satd8x8[2][i*2] + analysis.i_satd8x8[2][i*2+1];
avg_l0_mv_ref_cost = ( analysis.l0.me8x8[i*2].cost_mv + analysis.l0.me8x8[i*2].i_ref_cost
+ analysis.l0.me8x8[i*2+1].cost_mv + analysis.l0.me8x8[i*2+1].i_ref_cost + 1 ) >> 1;
avg_l1_mv_ref_cost = ( analysis.l1.me8x8[i*2].cost_mv + analysis.l1.me8x8[i*2].i_ref_cost
+ analysis.l1.me8x8[i*2+1].cost_mv + analysis.l1.me8x8[i*2+1].i_ref_cost + 1 ) >> 1;
COPY2_IF_LT( i_best_cost, i_l0_satd + avg_l0_mv_ref_cost, i_partition16x8[i], D_L0_8x8 );
COPY2_IF_LT( i_best_cost, i_l1_satd + avg_l1_mv_ref_cost, i_partition16x8[i], D_L1_8x8 );
COPY2_IF_LT( i_best_cost, i_bi_satd + avg_l0_mv_ref_cost + avg_l1_mv_ref_cost, i_partition16x8[i], D_BI_8x8 );
analysis.i_cost_est16x8[i] = i_best_cost;
// 8x16
i_best_cost = COST_MAX;
i_l0_satd = analysis.i_satd8x8[0][i] + analysis.i_satd8x8[0][i+2];
i_l1_satd = analysis.i_satd8x8[1][i] + analysis.i_satd8x8[1][i+2];
i_bi_satd = analysis.i_satd8x8[2][i] + analysis.i_satd8x8[2][i+2];
avg_l0_mv_ref_cost = ( analysis.l0.me8x8[i].cost_mv + analysis.l0.me8x8[i].i_ref_cost
+ analysis.l0.me8x8[i+2].cost_mv + analysis.l0.me8x8[i+2].i_ref_cost + 1 ) >> 1;
avg_l1_mv_ref_cost = ( analysis.l1.me8x8[i].cost_mv + analysis.l1.me8x8[i].i_ref_cost
+ analysis.l1.me8x8[i+2].cost_mv + analysis.l1.me8x8[i+2].i_ref_cost + 1 ) >> 1;
COPY2_IF_LT( i_best_cost, i_l0_satd + avg_l0_mv_ref_cost, i_partition8x16[i], D_L0_8x8 );
COPY2_IF_LT( i_best_cost, i_l1_satd + avg_l1_mv_ref_cost, i_partition8x16[i], D_L1_8x8 );
COPY2_IF_LT( i_best_cost, i_bi_satd + avg_l0_mv_ref_cost + avg_l1_mv_ref_cost, i_partition8x16[i], D_BI_8x8 );
analysis.i_cost_est8x16[i] = i_best_cost;
}
i_mb_type = B_L0_L0 + (i_partition16x8[0]>>2) * 3 + (i_partition16x8[1]>>2);
analysis.i_cost_est16x8[1] += analysis.i_lambda * i_mb_b16x8_cost_table[i_mb_type];
i_cost_est16x8bi_total = analysis.i_cost_est16x8[0] + analysis.i_cost_est16x8[1];
i_mb_type = B_L0_L0 + (i_partition8x16[0]>>2) * 3 + (i_partition8x16[1]>>2);
analysis.i_cost_est8x16[1] += analysis.i_lambda * i_mb_b16x8_cost_table[i_mb_type];
i_cost_est8x16bi_total = analysis.i_cost_est8x16[0] + analysis.i_cost_est8x16[1];
/* We can gain a little speed by checking the mode with the lowest estimated cost first */
int try_16x8_first = i_cost_est16x8bi_total < i_cost_est8x16bi_total;
if( try_16x8_first && (!analysis.b_early_terminate || i_cost_est16x8bi_total < i_cost) )
{
mb_analyse_inter_b16x8( h, &analysis, i_cost );
COPY3_IF_LT( i_cost, analysis.i_cost16x8bi, i_type, analysis.i_mb_type16x8, i_partition, D_16x8 );
}
if( !analysis.b_early_terminate || i_cost_est8x16bi_total < i_cost )
{
mb_analyse_inter_b8x16( h, &analysis, i_cost );
COPY3_IF_LT( i_cost, analysis.i_cost8x16bi, i_type, analysis.i_mb_type8x16, i_partition, D_8x16 );
}
if( !try_16x8_first && (!analysis.b_early_terminate || i_cost_est16x8bi_total < i_cost) )
{
mb_analyse_inter_b16x8( h, &analysis, i_cost );
COPY3_IF_LT( i_cost, analysis.i_cost16x8bi, i_type, analysis.i_mb_type16x8, i_partition, D_16x8 );
}
}
if( analysis.i_mbrd || !h->mb.i_subpel_refine )
{
/* refine later */
}
/* refine qpel */
else if( i_partition == D_16x16 )
{
analysis.l0.me16x16.cost -= analysis.i_lambda * i_mb_b_cost_table[B_L0_L0];
analysis.l1.me16x16.cost -= analysis.i_lambda * i_mb_b_cost_table[B_L1_L1];
if( i_type == B_L0_L0 )
{
x264_me_refine_qpel( h, &analysis.l0.me16x16 );
i_cost = analysis.l0.me16x16.cost
+ analysis.i_lambda * i_mb_b_cost_table[B_L0_L0];
}
else if( i_type == B_L1_L1 )
{
x264_me_refine_qpel( h, &analysis.l1.me16x16 );
i_cost = analysis.l1.me16x16.cost
+ analysis.i_lambda * i_mb_b_cost_table[B_L1_L1];
}
else if( i_type == B_BI_BI )
{
x264_me_refine_qpel( h, &analysis.l0.bi16x16 );
x264_me_refine_qpel( h, &analysis.l1.bi16x16 );
}
}
else if( i_partition == D_16x8 )
{
for( int i = 0; i < 2; i++ )
{
if( analysis.i_mb_partition16x8[i] != D_L1_8x8 )
x264_me_refine_qpel( h, &analysis.l0.me16x8[i] );
if( analysis.i_mb_partition16x8[i] != D_L0_8x8 )
x264_me_refine_qpel( h, &analysis.l1.me16x8[i] );
}
}
else if( i_partition == D_8x16 )
{
for( int i = 0; i < 2; i++ )
{
if( analysis.i_mb_partition8x16[i] != D_L1_8x8 )
x264_me_refine_qpel( h, &analysis.l0.me8x16[i] );
if( analysis.i_mb_partition8x16[i] != D_L0_8x8 )
x264_me_refine_qpel( h, &analysis.l1.me8x16[i] );
}
}
else if( i_partition == D_8x8 )
{
for( int i = 0; i < 4; i++ )
{
x264_me_t *m;
int i_part_cost_old;
int i_type_cost;
int i_part_type = h->mb.i_sub_partition[i];
int b_bidir = (i_part_type == D_BI_8x8);
if( i_part_type == D_DIRECT_8x8 )
continue;
if( x264_mb_partition_listX_table[0][i_part_type] )
{
m = &analysis.l0.me8x8[i];
i_part_cost_old = m->cost;
i_type_cost = analysis.i_lambda * i_sub_mb_b_cost_table[D_L0_8x8];
m->cost -= i_type_cost;
x264_me_refine_qpel( h, m );
if( !b_bidir )
analysis.i_cost8x8bi += m->cost + i_type_cost - i_part_cost_old;
}
if( x264_mb_partition_listX_table[1][i_part_type] )
{
m = &analysis.l1.me8x8[i];
i_part_cost_old = m->cost;
i_type_cost = analysis.i_lambda * i_sub_mb_b_cost_table[D_L1_8x8];
m->cost -= i_type_cost;
x264_me_refine_qpel( h, m );
if( !b_bidir )
analysis.i_cost8x8bi += m->cost + i_type_cost - i_part_cost_old;
}
/* TODO: update mvp? */
}
}
i_satd_inter = i_cost;
if( analysis.i_mbrd )
{
mb_analyse_b_rd( h, &analysis, i_satd_inter );
i_type = B_SKIP;
i_cost = i_bskip_cost;
i_partition = D_16x16;
COPY2_IF_LT( i_cost, analysis.l0.i_rd16x16, i_type, B_L0_L0 );
COPY2_IF_LT( i_cost, analysis.l1.i_rd16x16, i_type, B_L1_L1 );
COPY2_IF_LT( i_cost, analysis.i_rd16x16bi, i_type, B_BI_BI );
COPY2_IF_LT( i_cost, analysis.i_rd16x16direct, i_type, B_DIRECT );
COPY3_IF_LT( i_cost, analysis.i_rd16x8bi, i_type, analysis.i_mb_type16x8, i_partition, D_16x8 );
COPY3_IF_LT( i_cost, analysis.i_rd8x16bi, i_type, analysis.i_mb_type8x16, i_partition, D_8x16 );
COPY3_IF_LT( i_cost, analysis.i_rd8x8bi, i_type, B_8x8, i_partition, D_8x8 );
h->mb.i_type = i_type;
h->mb.i_partition = i_partition;
}
if( h->mb.b_chroma_me )
{
if( CHROMA444 )
{
mb_analyse_intra( h, &analysis, i_satd_inter );
mb_analyse_intra_chroma( h, &analysis );
}
else
{
mb_analyse_intra_chroma( h, &analysis );
mb_analyse_intra( h, &analysis, i_satd_inter - analysis.i_satd_chroma );
}
analysis.i_satd_i16x16 += analysis.i_satd_chroma;
analysis.i_satd_i8x8 += analysis.i_satd_chroma;
analysis.i_satd_i4x4 += analysis.i_satd_chroma;
}
else
mb_analyse_intra( h, &analysis, i_satd_inter );
if( analysis.i_mbrd )
{
mb_analyse_transform_rd( h, &analysis, &i_satd_inter, &i_cost );
intra_rd( h, &analysis, i_satd_inter * 17/16 + 1 );
}
COPY2_IF_LT( i_cost, analysis.i_satd_i16x16, i_type, I_16x16 );
COPY2_IF_LT( i_cost, analysis.i_satd_i8x8, i_type, I_8x8 );
COPY2_IF_LT( i_cost, analysis.i_satd_i4x4, i_type, I_4x4 );
COPY2_IF_LT( i_cost, analysis.i_satd_pcm, i_type, I_PCM );
h->mb.i_type = i_type;
h->mb.i_partition = i_partition;
if( analysis.i_mbrd >= 2 && IS_INTRA( i_type ) && i_type != I_PCM )
intra_rd_refine( h, &analysis );
if( h->mb.i_subpel_refine >= 5 )
refine_bidir( h, &analysis );
if( analysis.i_mbrd >= 2 && i_type > B_DIRECT && i_type < B_SKIP )
{
int i_biweight;
analyse_update_cache( h, &analysis );
if( i_partition == D_16x16 )
{
if( i_type == B_L0_L0 )
{
analysis.l0.me16x16.cost = i_cost;
x264_me_refine_qpel_rd( h, &analysis.l0.me16x16, analysis.i_lambda2, 0, 0 );
}
else if( i_type == B_L1_L1 )
{
analysis.l1.me16x16.cost = i_cost;
x264_me_refine_qpel_rd( h, &analysis.l1.me16x16, analysis.i_lambda2, 0, 1 );
}
else if( i_type == B_BI_BI )
{
i_biweight = h->mb.bipred_weight[analysis.l0.bi16x16.i_ref][analysis.l1.bi16x16.i_ref];
x264_me_refine_bidir_rd( h, &analysis.l0.bi16x16, &analysis.l1.bi16x16, i_biweight, 0, analysis.i_lambda2 );
}
}
else if( i_partition == D_16x8 )
{
for( int i = 0; i < 2; i++ )
{
h->mb.i_sub_partition[i*2] = h->mb.i_sub_partition[i*2+1] = analysis.i_mb_partition16x8[i];
if( analysis.i_mb_partition16x8[i] == D_L0_8x8 )
x264_me_refine_qpel_rd( h, &analysis.l0.me16x8[i], analysis.i_lambda2, i*8, 0 );
else if( analysis.i_mb_partition16x8[i] == D_L1_8x8 )
x264_me_refine_qpel_rd( h, &analysis.l1.me16x8[i], analysis.i_lambda2, i*8, 1 );
else if( analysis.i_mb_partition16x8[i] == D_BI_8x8 )
{
i_biweight = h->mb.bipred_weight[analysis.l0.me16x8[i].i_ref][analysis.l1.me16x8[i].i_ref];
x264_me_refine_bidir_rd( h, &analysis.l0.me16x8[i], &analysis.l1.me16x8[i], i_biweight, i*2, analysis.i_lambda2 );
}
}
}
else if( i_partition == D_8x16 )
{
for( int i = 0; i < 2; i++ )
{
h->mb.i_sub_partition[i] = h->mb.i_sub_partition[i+2] = analysis.i_mb_partition8x16[i];
if( analysis.i_mb_partition8x16[i] == D_L0_8x8 )
x264_me_refine_qpel_rd( h, &analysis.l0.me8x16[i], analysis.i_lambda2, i*4, 0 );
else if( analysis.i_mb_partition8x16[i] == D_L1_8x8 )
x264_me_refine_qpel_rd( h, &analysis.l1.me8x16[i], analysis.i_lambda2, i*4, 1 );
else if( analysis.i_mb_partition8x16[i] == D_BI_8x8 )
{
i_biweight = h->mb.bipred_weight[analysis.l0.me8x16[i].i_ref][analysis.l1.me8x16[i].i_ref];
x264_me_refine_bidir_rd( h, &analysis.l0.me8x16[i], &analysis.l1.me8x16[i], i_biweight, i, analysis.i_lambda2 );
}
}
}
else if( i_partition == D_8x8 )
{
for( int i = 0; i < 4; i++ )
{
if( h->mb.i_sub_partition[i] == D_L0_8x8 )
x264_me_refine_qpel_rd( h, &analysis.l0.me8x8[i], analysis.i_lambda2, i*4, 0 );
else if( h->mb.i_sub_partition[i] == D_L1_8x8 )
x264_me_refine_qpel_rd( h, &analysis.l1.me8x8[i], analysis.i_lambda2, i*4, 1 );
else if( h->mb.i_sub_partition[i] == D_BI_8x8 )
{
i_biweight = h->mb.bipred_weight[analysis.l0.me8x8[i].i_ref][analysis.l1.me8x8[i].i_ref];
x264_me_refine_bidir_rd( h, &analysis.l0.me8x8[i], &analysis.l1.me8x8[i], i_biweight, i, analysis.i_lambda2 );
}
}
}
}
}
}
// ----- 6.从分析中更新MB ----- //
analyse_update_cache( h, &analysis );
/* In rare cases we can end up qpel-RDing our way back to a larger partition size
* without realizing it. Check for this and account for it if necessary. */
if( analysis.i_mbrd >= 2 )
{
/* Don't bother with bipred or 8x8-and-below, the odds are incredibly low. */
static const uint8_t check_mv_lists[X264_MBTYPE_MAX] = {[P_L0]=1, [B_L0_L0]=1, [B_L1_L1]=2};
int list = check_mv_lists[h->mb.i_type] - 1;
if( list >= 0 && h->mb.i_partition != D_16x16 &&
M32( &h->mb.cache.mv[list][x264_scan8[0]] ) == M32( &h->mb.cache.mv[list][x264_scan8[12]] ) &&
h->mb.cache.ref[list][x264_scan8[0]] == h->mb.cache.ref[list][x264_scan8[12]] )
h->mb.i_partition = D_16x16;
}
if( !analysis.i_mbrd )
mb_analyse_transform( h );
if( analysis.i_mbrd == 3 && !IS_SKIP(h->mb.i_type) )
mb_analyse_qp_rd( h, &analysis );
h->mb.b_trellis = h->param.analyse.i_trellis;
h->mb.b_noise_reduction = h->mb.b_noise_reduction || (!!h->param.analyse.i_noise_reduction && !IS_INTRA( h->mb.i_type ));
if( !IS_SKIP(h->mb.i_type) && h->mb.i_psy_trellis && h->param.analyse.i_trellis == 1 )
psy_trellis_init( h, 0 );
if( h->mb.b_trellis == 1 || h->mb.b_noise_reduction )
h->mb.i_skip_intra = 0;
}
3. 帧内预测(intra prediction)
帧内预测的主要思想是利用当前帧内部的信息作为参考,进行信息的预测,选择一个最佳的预测模式。具体来说,当前编码块利用左侧和上方的参考块边界像素作为依据,按照不同的预测模式对当前块进行预测。帧内预测主要关注的内容包括:
- 预测模式
(1)16x16亮度块(4种预测模式)
(2)4x4亮度块(9种预测模式)
(3)8x8色度块(4种预测模式) - 评价方式
(1)绝对误差(SAD, Sum of Absolute Difference)
(2)变换后的绝对误差(SATD, Sum of Absolute Transformed Difference)
(3)平方误差和(SSD, Sum of Square Difference) - 实现函数
(1)帧内预测主干函数(x264_mb_analyse_intra)
(2)16x16块的预测函数(x264_predict_16x16_dc_c)
(3)4x4块的satd函数(x264_pixel_satd_4x4)
3.1 预测模式
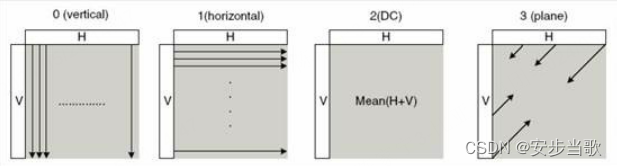
对于16x16的亮度块,预测的模式有4种,操作方式如下:
(0)垂直(vertical):利用左侧参考像素进行预测
(1)水平(horizontal):利用上方参考像素进行预测
(2)直流(DC):利用左侧和上方参考像素的平均值进行预测
(3)平面(plane):利用左侧和上方参考像素进行预测
如下图所示:
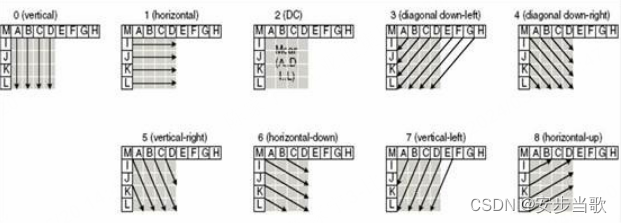
对于4x4的亮度块,预测的模式有9种,操作方式如下:
(0)垂直(vertical):利用上方像素进行参考
(1)水平(horizontal):利用左侧像素进行参考
(2)直流(DC):利用左侧和上方参考像素的平均值进行预测
(3)对角线左下方(diagonal down-left): 向左下45°的方向
(4)对角线右下方(diagonal down-right): 向右下45°的方向
(5)垂直右侧(vertical-right):以垂直方向为轴,向右偏移
(6)水平下方(horizontal-down):以水平方向为轴,向下偏移
(7)垂直左侧(vertical-left):以垂直方向为轴,向左偏移
(8)水平上方(horizontal-up):以水平方向为轴,向上偏移
如下图所示
对于8x8的色度块,每个帧内编码宏块的8x8色度成分由已编码左上方色度像素预测而得,两种色度分量(Cb和Cr)常用同一种预测模式。4种预测模式类似于帧内16x16预测的4种预测模式,但是模式编号不同。其中,直流(DC)为模式0,水平(horizontal)为模式1,垂直(vertical)为模式2,平面(plane)为模式3
3.2 评价方式
在H264标准中,采用率失真优化(Rate-Distortion Optimization)策略选择最优的编码模式,先去遍历所有可能的编码模式,后选择率失真代价最小的模式作为最佳帧内编码模式。具体的率失真代价计算公式为:
J
=
S
S
D
+
λ
m
R
J = SSD+\lambda_{m}R
J=SSD+λmR
其中,J是率失真代价,SSD是原始亮度块与重建块之间的差值平方和,R是当前模式进行编码时所需要的比特数。可以看出,编码器中评估当前模式的优劣,既考虑了质量也考虑了比特数,这样权重系数λ是一个非常重要的评估因子,它根据量化参数QP获得,其计算方式为:
λ
=
0.85
∗
2
Q
−
12
3
\lambda = 0.85 * 2^{\frac{Q-12}{3}}
λ=0.85∗23Q−12
在实际应用之中,由于SSD计算复杂度比较高,常使用SAD和SATD替代。相比较于SAD,SATD更能够描述图像的差异,因为SAD只能反映时域差异,而SATD能够反映频域差异,计算复杂度比DCT要低。此外,SAD能够影响PSNR值,但不能反应码流大小,但是SATD由于可以反映频域信息,可以一定程度上反映码流大小
3.2.1 绝对误差(SAD, Sum of Absolute Difference)
SAD的计算方法就是求出两个像素块对应像素点的差值,将这些差值分别求绝对值之后再进行累加。计算公式为
S
A
D
=
1
m
n
∑
j
=
0
m
−
1
∑
i
=
0
n
−
1
∣
f
(
x
,
y
)
−
g
(
x
,
y
)
∣
SAD = \frac{1}{mn}\sum_{j = 0}^{m-1} \sum_{i = 0}^{n-1}|f(x,y) - g(x,y)|
SAD=mn1j=0∑m−1i=0∑n−1∣f(x,y)−g(x,y)∣
3.2.2 变换后的绝对误差(SATD, Sum of Absolute Transformed Difference)
SATD应用于变换域。将残差信号先进行哈达玛变换到频域,设其矩阵为H,计算公式为
S
A
T
D
=
∑
K
∑
K
H
X
H
SATD = \sum_{K} \sum_{K}HXH
SATD=K∑K∑HXH
其中,残差信号为X,归一化的变化矩阵为H(维度为K * K)
3.2.3 平方误差和(SSD, Sum of Square Difference)
SSD与SAD的区别在于,SSD将像素的差异求平方再求和
S
S
D
=
1
m
n
∑
j
=
0
m
−
1
∑
i
=
0
n
−
1
∣
f
(
x
,
y
)
−
g
(
x
,
y
)
∣
2
SSD = \frac{1}{mn}\sum_{j = 0}^{m-1} \sum_{i = 0}^{n-1}|f(x,y) - g(x,y)|^2
SSD=mn1j=0∑m−1i=0∑n−1∣f(x,y)−g(x,y)∣2
3.3 帧内预测主干函数(x264_mb_analyse_intra)
对于Intra帧和P帧中的部分使用intra模式的mb而言,会使用帧内预测函数进行预测,从16x16的SAD,4个8x8的SAD和16个4x4SAD中选出最优方式。主要的工作流程如下:
-
帧内16x16的预测
(1)根据当前mb的相邻块(左侧和上方)确定可用的参考模式(predict_16x16_mode_available)
(2)遍历所有的可用的Intra16x16帧内预测模式(最多4种)
(3)进行帧内预测(h->predict_16x16)
(4)使用汇编函数计算loss,计算的内容是sad或satd,使用的代码是汇编代码(.asm)而不是c代码(h->pixf.mbcmp[PIXEL_16x16])
(5)存储16x16帧内预测最小的损失值 -
帧内8x8的预测(猜测应该是chroma分量)
(1)根据当前mb的相邻块(左侧和上方)确定可用的参考模式(predict_8x8_mode_available)
(2)遍历所有的可用的Intra8x8帧内预测模式
(3)进行帧内预测(h->predict_8x8)
(4)计算sad(sa8d),并累加每个子块
(5)存储8x8帧内预测最小的损失值 -
帧内4x4的预测
(1)获取4x4块可用的模式list(predict_4x4_mode_available)
(2)遍历所有的可用的Intra4x4帧内预测模式(至多9种)
(3)进行帧内预测(h->predict_4x4)
(4)计算sad或satd(h->pixf.mbcmp),并累加每个子块
(5)存储4x4帧内预测最小的损失值
/* FIXME: should we do any sort of merged chroma analysis with 4:4:4? */
static void mb_analyse_intra( x264_t *h, x264_mb_analysis_t *a, int i_satd_inter )
{
const unsigned int flags = h->sh.i_type == SLICE_TYPE_I ? h->param.analyse.intra : h->param.analyse.inter;
pixel *p_src = h->mb.pic.p_fenc[0]; // p_fenc: point_frame_encode 编码帧
pixel *p_dst = h->mb.pic.p_fdec[0]; // p_fdec: point_frame_decode 重建帧
static const int8_t intra_analysis_shortcut[2][2][2][5] =
{
{{{I_PRED_4x4_HU, -1, -1, -1, -1},
{I_PRED_4x4_DDL, I_PRED_4x4_VL, -1, -1, -1}},
{{I_PRED_4x4_DDR, I_PRED_4x4_HD, I_PRED_4x4_HU, -1, -1},
{I_PRED_4x4_DDL, I_PRED_4x4_DDR, I_PRED_4x4_VR, I_PRED_4x4_VL, -1}}},
{{{I_PRED_4x4_HU, -1, -1, -1, -1},
{-1, -1, -1, -1, -1}},
{{I_PRED_4x4_DDR, I_PRED_4x4_HD, I_PRED_4x4_HU, -1, -1},
{I_PRED_4x4_DDR, I_PRED_4x4_VR, -1, -1, -1}}},
};
int idx;
int lambda = a->i_lambda;
/*---------------- Try all mode and calculate their score ---------------*/
// ----- 1.帧内16x16 ----- //
/* Disabled i16x16 for AVC-Intra compat */
if( !h->param.i_avcintra_class )
{
// 根据当前mb的相邻块(左侧和上方)确定可用的参考模式
const int8_t *predict_mode = predict_16x16_mode_available( h->mb.i_neighbour_intra );
// 进行轻微的阈值调整
/* Not heavily tuned */
static const uint8_t i16x16_thresh_lut[11] = { 2, 2, 2, 3, 3, 4, 4, 4, 4, 4, 4 };
int i16x16_thresh = a->b_fast_intra ? (i16x16_thresh_lut[h->mb.i_subpel_refine]*i_satd_inter)>>1 : COST_MAX;
if( !h->mb.b_lossless && predict_mode[3] >= 0 )
{ // 使用了lossless模式,并且相邻的左侧和上方的块都可以参考,进行高质量的预测编码
h->pixf.intra_mbcmp_x3_16x16( p_src, p_dst, a->i_satd_i16x16_dir );
a->i_satd_i16x16_dir[0] += lambda * bs_size_ue(0);
a->i_satd_i16x16_dir[1] += lambda * bs_size_ue(1);
a->i_satd_i16x16_dir[2] += lambda * bs_size_ue(2);
COPY2_IF_LT( a->i_satd_i16x16, a->i_satd_i16x16_dir[0], a->i_predict16x16, 0 );
COPY2_IF_LT( a->i_satd_i16x16, a->i_satd_i16x16_dir[1], a->i_predict16x16, 1 );
COPY2_IF_LT( a->i_satd_i16x16, a->i_satd_i16x16_dir[2], a->i_predict16x16, 2 );
/* Plane is expensive, so don't check it unless one of the previous modes was useful. */
if( a->i_satd_i16x16 <= i16x16_thresh )
{
h->predict_16x16[I_PRED_16x16_P]( p_dst );
a->i_satd_i16x16_dir[I_PRED_16x16_P] = h->pixf.mbcmp[PIXEL_16x16]( p_src, FENC_STRIDE, p_dst, FDEC_STRIDE );
a->i_satd_i16x16_dir[I_PRED_16x16_P] += lambda * bs_size_ue(3);
COPY2_IF_LT( a->i_satd_i16x16, a->i_satd_i16x16_dir[I_PRED_16x16_P], a->i_predict16x16, 3 );
}
}
else
{ // 遍历所有的可用的Intra16x16帧内预测模式(最多4种)
// 帧内预测汇编函数:根据左边和上边的像素计算出预测值
/*
* 帧内预测举例
* Vertical预测方式
* |X1 X2 ... X16
* --+---------------
* |X1 X2 ... X16
* |X1 X2 ... X16
* |.. .. ... X16
* |X1 X2 ... X16
*
* Horizontal预测方式
* |
* --+---------------
* X1| X1 X1 ... X1
* X2| X2 X2 ... X2
* ..| .. .. ... ..
* X16|X16 X16 ... X16
*
* DC预测方式
* |X1 X2 ... X16
* --+---------------
* X17|
* X18| Y
* ..|
* X32|
*
* Y=(X1+X2+X3+X4+...+X31+X32)/32
*
*/
for( ; *predict_mode >= 0; predict_mode++ )
{
int i_satd;
int i_mode = *predict_mode;
if( h->mb.b_lossless )
x264_predict_lossless_16x16( h, 0, i_mode );
else
h->predict_16x16[i_mode]( p_dst );
// 亚像素的细化和模式决策(使用sad和satd)
// sad : Sum of Absolute Difference
// satd : Sum of Absolute Transformed Difference
i_satd = h->pixf.mbcmp[PIXEL_16x16]( p_src, FENC_STRIDE, p_dst, FDEC_STRIDE ) +
lambda * bs_size_ue( x264_mb_pred_mode16x16_fix[i_mode] );
COPY2_IF_LT( a->i_satd_i16x16, i_satd, a->i_predict16x16, i_mode );
a->i_satd_i16x16_dir[i_mode] = i_satd; // 存储每一种模式的损失
}
}
if( h->sh.i_type == SLICE_TYPE_B )
/* cavlc mb type prefix */
a->i_satd_i16x16 += lambda * i_mb_b_cost_table[I_16x16];
if( a->i_satd_i16x16 > i16x16_thresh )
return;
}
uint16_t *cost_i4x4_mode = h->cost_table->i4x4_mode[a->i_qp] + 8;
// ----- 2.帧内8x8预测 ----- //
/* 8x8 prediction selection */
if( flags & X264_ANALYSE_I8x8 )
{
ALIGNED_ARRAY_32( pixel, edge,[36] );
x264_pixel_cmp_t sa8d = (h->pixf.mbcmp[0] == h->pixf.satd[0]) ? h->pixf.sa8d[PIXEL_8x8] : h->pixf.mbcmp[PIXEL_8x8];
int i_satd_thresh = a->i_mbrd ? COST_MAX : X264_MIN( i_satd_inter, a->i_satd_i16x16 );
// FIXME some bias like in i4x4?
int i_cost = lambda * 4; /* base predmode costs */
h->mb.i_cbp_luma = 0;
if( h->sh.i_type == SLICE_TYPE_B )
i_cost += lambda * i_mb_b_cost_table[I_8x8];
for( idx = 0;; idx++ ) // 遍历各个子块
{
int x = idx&1;
int y = idx>>1;
pixel *p_src_by = p_src + 8*x + 8*y*FENC_STRIDE;
pixel *p_dst_by = p_dst + 8*x + 8*y*FDEC_STRIDE;
int i_best = COST_MAX;
int i_pred_mode = x264_mb_predict_intra4x4_mode( h, 4*idx );
// 检查可用的预测模式
const int8_t *predict_mode = predict_8x8_mode_available( a->b_avoid_topright, h->mb.i_neighbour8[idx], idx );
// 进行8x8块的滤波
h->predict_8x8_filter( p_dst_by, edge, h->mb.i_neighbour8[idx], ALL_NEIGHBORS );
if( h->pixf.intra_mbcmp_x9_8x8 && predict_mode[8] >= 0 )
{
// 使用SSSE3进行帧内预测函数的实现,这是一种并行处理技术,比c代码实现速度快很多
/* No shortcuts here. The SSSE3 implementation of intra_mbcmp_x9 is fast enough. */
i_best = h->pixf.intra_mbcmp_x9_8x8( p_src_by, p_dst_by, edge, cost_i4x4_mode-i_pred_mode, a->i_satd_i8x8_dir[idx] );
i_cost += i_best & 0xffff;
i_best >>= 16;
a->i_predict8x8[idx] = i_best;
if( idx == 3 || i_cost > i_satd_thresh )
break;
x264_macroblock_cache_intra8x8_pred( h, 2*x, 2*y, i_best );
}
else
{
if( !h->mb.b_lossless && predict_mode[5] >= 0 )
{
ALIGNED_ARRAY_16( int32_t, satd,[4] );
h->pixf.intra_mbcmp_x3_8x8( p_src_by, edge, satd );
int favor_vertical = satd[I_PRED_4x4_H] > satd[I_PRED_4x4_V];
if( i_pred_mode < 3 )
satd[i_pred_mode] -= 3 * lambda;
for( int i = 2; i >= 0; i-- )
{
int cost = satd[i];
a->i_satd_i8x8_dir[idx][i] = cost + 4 * lambda;
COPY2_IF_LT( i_best, cost, a->i_predict8x8[idx], i );
}
/* Take analysis shortcuts: don't analyse modes that are too
* far away direction-wise from the favored mode. */
if( a->i_mbrd < 1 + a->b_fast_intra )
predict_mode = intra_analysis_shortcut[a->b_avoid_topright][predict_mode[8] >= 0][favor_vertical];
else
predict_mode += 3;
}
for( ; *predict_mode >= 0 && (i_best >= 0 || a->i_mbrd >= 2); predict_mode++ )
{
int i_satd;
int i_mode = *predict_mode;
if( h->mb.b_lossless ) // lossless情况
x264_predict_lossless_8x8( h, p_dst_by, 0, idx, i_mode, edge );
else
h->predict_8x8[i_mode]( p_dst_by, edge );
i_satd = sa8d( p_dst_by, FDEC_STRIDE, p_src_by, FENC_STRIDE );
if( i_pred_mode == x264_mb_pred_mode4x4_fix(i_mode) )
i_satd -= 3 * lambda;
COPY2_IF_LT( i_best, i_satd, a->i_predict8x8[idx], i_mode );
a->i_satd_i8x8_dir[idx][i_mode] = i_satd + 4 * lambda;
}
i_cost += i_best + 3*lambda;
if( idx == 3 || i_cost > i_satd_thresh )
break;
if( h->mb.b_lossless )
x264_predict_lossless_8x8( h, p_dst_by, 0, idx, a->i_predict8x8[idx], edge );
else
h->predict_8x8[a->i_predict8x8[idx]]( p_dst_by, edge );
x264_macroblock_cache_intra8x8_pred( h, 2*x, 2*y, a->i_predict8x8[idx] );
}
/* we need to encode this block now (for next ones) */
x264_mb_encode_i8x8( h, 0, idx, a->i_qp, a->i_predict8x8[idx], edge, 0 );
}
if( idx == 3 ) // 如果处理到了最后一个8x8的子块
{
a->i_satd_i8x8 = i_cost;
if( h->mb.i_skip_intra )
{
h->mc.copy[PIXEL_16x16]( h->mb.pic.i8x8_fdec_buf, 16, p_dst, FDEC_STRIDE, 16 );
h->mb.pic.i8x8_nnz_buf[0] = M32( &h->mb.cache.non_zero_count[x264_scan8[ 0]] );
h->mb.pic.i8x8_nnz_buf[1] = M32( &h->mb.cache.non_zero_count[x264_scan8[ 2]] );
h->mb.pic.i8x8_nnz_buf[2] = M32( &h->mb.cache.non_zero_count[x264_scan8[ 8]] );
h->mb.pic.i8x8_nnz_buf[3] = M32( &h->mb.cache.non_zero_count[x264_scan8[10]] );
h->mb.pic.i8x8_cbp = h->mb.i_cbp_luma;
if( h->mb.i_skip_intra == 2 )
h->mc.memcpy_aligned( h->mb.pic.i8x8_dct_buf, h->dct.luma8x8, sizeof(h->mb.pic.i8x8_dct_buf) );
}
}
else
{
static const uint16_t cost_div_fix8[3] = {1024,512,341};
a->i_satd_i8x8 = COST_MAX;
i_cost = (i_cost * cost_div_fix8[idx]) >> 8;
}
/* Not heavily tuned */
static const uint8_t i8x8_thresh[11] = { 4, 4, 4, 5, 5, 5, 6, 6, 6, 6, 6 };
if( a->b_early_terminate && X264_MIN(i_cost, a->i_satd_i16x16) > (i_satd_inter*i8x8_thresh[h->mb.i_subpel_refine])>>2 )
return;
}
// ---- 3.进行4x4的帧内预测 ---- //
/* 4x4 prediction selection */
if( flags & X264_ANALYSE_I4x4 )
{
/*
* 16x16 宏块被划分为16个4x4子块
*
* +----+----+----+----+
* | | | | |
* +----+----+----+----+
* | | | | |
* +----+----+----+----+
* | | | | |
* +----+----+----+----+
* | | | | |
* +----+----+----+----+
*
*/
int i_cost = lambda * (24+16); /* 24from JVT (SATD0), 16 from base predmode costs */
int i_satd_thresh = a->b_early_terminate ? X264_MIN3( i_satd_inter, a->i_satd_i16x16, a->i_satd_i8x8 ) : COST_MAX;
h->mb.i_cbp_luma = 0;
if( a->b_early_terminate && a->i_mbrd )
i_satd_thresh = i_satd_thresh * (10-a->b_fast_intra)/8;
if( h->sh.i_type == SLICE_TYPE_B )
i_cost += lambda * i_mb_b_cost_table[I_4x4];
// 循环所有的4x4块
for( idx = 0;; idx++ )
{
pixel *p_src_by = p_src + block_idx_xy_fenc[idx]; // block_idx_xy_fenc[]记录了4x4小块在p_fenc中的偏移地址
pixel *p_dst_by = p_dst + block_idx_xy_fdec[idx]; // // block_idx_xy_fdec[]记录了4x4小块在p_fdec中的偏移地址
int i_best = COST_MAX;
int i_pred_mode = x264_mb_predict_intra4x4_mode( h, idx );
// 获取4x4块可用的模式list
const int8_t *predict_mode = predict_4x4_mode_available( a->b_avoid_topright, h->mb.i_neighbour4[idx], idx );
if( (h->mb.i_neighbour4[idx] & (MB_TOPRIGHT|MB_TOP)) == MB_TOP )
/* emulate missing topright samples */
MPIXEL_X4( &p_dst_by[4 - FDEC_STRIDE] ) = PIXEL_SPLAT_X4( p_dst_by[3 - FDEC_STRIDE] );
if( h->pixf.intra_mbcmp_x9_4x4 && predict_mode[8] >= 0 )
{
/* No shortcuts here. The SSSE3 implementation of intra_mbcmp_x9 is fast enough. */
i_best = h->pixf.intra_mbcmp_x9_4x4( p_src_by, p_dst_by, cost_i4x4_mode-i_pred_mode );
i_cost += i_best & 0xffff;
i_best >>= 16;
a->i_predict4x4[idx] = i_best;
if( i_cost > i_satd_thresh || idx == 15 )
break;
h->mb.cache.intra4x4_pred_mode[x264_scan8[idx]] = i_best;
}
else
{
if( !h->mb.b_lossless && predict_mode[5] >= 0 )
{
ALIGNED_ARRAY_16( int32_t, satd,[4] );
h->pixf.intra_mbcmp_x3_4x4( p_src_by, p_dst_by, satd );
int favor_vertical = satd[I_PRED_4x4_H] > satd[I_PRED_4x4_V];
if( i_pred_mode < 3 )
satd[i_pred_mode] -= 3 * lambda;
i_best = satd[I_PRED_4x4_DC]; a->i_predict4x4[idx] = I_PRED_4x4_DC;
COPY2_IF_LT( i_best, satd[I_PRED_4x4_H], a->i_predict4x4[idx], I_PRED_4x4_H );
COPY2_IF_LT( i_best, satd[I_PRED_4x4_V], a->i_predict4x4[idx], I_PRED_4x4_V );
/* Take analysis shortcuts: don't analyse modes that are too
* far away direction-wise from the favored mode. */
if( a->i_mbrd < 1 + a->b_fast_intra )
predict_mode = intra_analysis_shortcut[a->b_avoid_topright][predict_mode[8] >= 0][favor_vertical];
else
predict_mode += 3;
}
if( i_best > 0 )
{
// 遍历所有Intra4x4帧内模式(最多9种)
for( ; *predict_mode >= 0; predict_mode++ )
{
int i_satd;
int i_mode = *predict_mode;
/*
* 4x4帧内预测举例
*
* Vertical预测方式
* |X1 X2 X3 X4
* --+-----------
* |X1 X2 X3 X4
* |X1 X2 X3 X4
* |X1 X2 X3 X4
* |X1 X2 X3 X4
*
* Horizontal预测方式
* |
* --+-----------
* X5|X5 X5 X5 X5
* X6|X6 X6 X6 X6
* X7|X7 X7 X7 X7
* X8|X8 X8 X8 X8
*
* DC预测方式
* |X1 X2 X3 X4
* --+-----------
* X5|
* X6| Y
* X7|
* X8|
*
* Y=(X1+X2+X3+X4+X5+X6+X7+X8)/8
*
*/
if( h->mb.b_lossless )
x264_predict_lossless_4x4( h, p_dst_by, 0, idx, i_mode );
else
h->predict_4x4[i_mode]( p_dst_by ); // 帧内预测汇编函数
// 计算sad或satd
i_satd = h->pixf.mbcmp[PIXEL_4x4]( p_src_by, FENC_STRIDE, p_dst_by, FDEC_STRIDE );
if( i_pred_mode == x264_mb_pred_mode4x4_fix(i_mode) )
{
i_satd -= lambda * 3;
if( i_satd <= 0 )
{
i_best = i_satd;
a->i_predict4x4[idx] = i_mode;
break;
}
}
// 看看代价是否更小
// i_best中存储了最小的代价值
// i_predict4x4[idx]中存储了代价最小的预测模式(idx为4x4小块的序号)
COPY2_IF_LT( i_best, i_satd, a->i_predict4x4[idx], i_mode );
}
}
// 累加每个4x4子块的损失函数
i_cost += i_best + 3 * lambda;
if( i_cost > i_satd_thresh || idx == 15 )
break;
if( h->mb.b_lossless )
x264_predict_lossless_4x4( h, p_dst_by, 0, idx, a->i_predict4x4[idx] );
else
h->predict_4x4[a->i_predict4x4[idx]]( p_dst_by );
/*
* 将mode填充至intra4x4_pred_mode_cache
*
* 用简单图形表示intra4x4_pred_mode_cache如下。数字代表填充顺序(一共填充16次)
* |
* --+-------------------
* | 0 0 0 0 0 0 0 0
* | 0 0 0 0 1 2 5 6
* | 0 0 0 0 3 4 7 8
* | 0 0 0 0 9 10 13 14
* | 0 0 0 0 11 12 15 16
*
*/
h->mb.cache.intra4x4_pred_mode[x264_scan8[idx]] = a->i_predict4x4[idx];
}
/* we need to encode this block now (for next ones) */
x264_mb_encode_i4x4( h, 0, idx, a->i_qp, a->i_predict4x4[idx], 0 );
}
if( idx == 15 ) // 如果处理到了最后一个小块
{
a->i_satd_i4x4 = i_cost;
if( h->mb.i_skip_intra )
{
h->mc.copy[PIXEL_16x16]( h->mb.pic.i4x4_fdec_buf, 16, p_dst, FDEC_STRIDE, 16 );
h->mb.pic.i4x4_nnz_buf[0] = M32( &h->mb.cache.non_zero_count[x264_scan8[ 0]] );
h->mb.pic.i4x4_nnz_buf[1] = M32( &h->mb.cache.non_zero_count[x264_scan8[ 2]] );
h->mb.pic.i4x4_nnz_buf[2] = M32( &h->mb.cache.non_zero_count[x264_scan8[ 8]] );
h->mb.pic.i4x4_nnz_buf[3] = M32( &h->mb.cache.non_zero_count[x264_scan8[10]] );
h->mb.pic.i4x4_cbp = h->mb.i_cbp_luma;
if( h->mb.i_skip_intra == 2 )
h->mc.memcpy_aligned( h->mb.pic.i4x4_dct_buf, h->dct.luma4x4, sizeof(h->mb.pic.i4x4_dct_buf) );
}
}
else
a->i_satd_i4x4 = COST_MAX;
}
}
由于使用的预测函数和损失函数种类很多,下面各做一例进行讨论,且都是c语言版本,汇编优化版本在其他文章中记录
3.3.1 16x16块的预测函数(x264_predict_16x16_dc_c)
x264_predict_16x16_dc_c执行16x16的dc模式的预测过程,函数定义在common\predict.c中
#define PREDICT_16x16_DC(v)\ // 把最后一个像素(最后8位)拷贝给前面3个像素(前24位)
for( int i = 0; i < 16; i++ )\
{\
MPIXEL_X4( src+ 0 ) = v;\
MPIXEL_X4( src+ 4 ) = v;\
MPIXEL_X4( src+ 8 ) = v;\
MPIXEL_X4( src+12 ) = v;\
src += FDEC_STRIDE;\
}
void x264_predict_16x16_dc_c( pixel *src )
{
/*
* DC预测方式
* |X1 X2 X3 X4
* --+-----------
* X5|
* X6| Y
* X7|
* X8|
*
* Y=(X1+X2+X3+X4+X5+X6+X7+X8)/8
*/
int dc = 0;
// //把16x16块中所有像素的值加起来,存储在dc中
for( int i = 0; i < 16; i++ )
{
dc += src[-1 + i * FDEC_STRIDE]; // 左侧像素
dc += src[i - FDEC_STRIDE]; // 上方像素
}
// 将前面的值加起来除以32,+16是为了四舍五入
pixel4 dcsplat = PIXEL_SPLAT_X4( ( dc + 16 ) >> 5 );
//赋值到16x16块中的每个像素
/*
* 宏展开之后结果
* for( int i = 0; i < 16; i++ )
* {
* (((x264_union32_t*)(src+ 0))->i) = dcsplat;
* (((x264_union32_t*)(src+ 4))->i) = dcsplat;
* (((x264_union32_t*)(src+ 8))->i) = dcsplat;
* (((x264_union32_t*)(src+12))->i) = dcsplat;
* src += 32;
* }
*/
PREDICT_16x16_DC( dcsplat );
}
3.3.2 4x4块的satd函数(x264_pixel_satd_4x4)
用于计算4x4块的satd值,函数的定义位于common\pixel.c中
/****************************************************************************
* pixel_satd_WxH: sum of 4x4 Hadamard transformed differences
****************************************************************************/
static NOINLINE int x264_pixel_satd_4x4( pixel *pix1, intptr_t i_pix1, pixel *pix2, intptr_t i_pix2 )
{
sum2_t tmp[4][2];
sum2_t a0, a1, a2, a3, b0, b1;
sum2_t sum = 0;
for( int i = 0; i < 4; i++, pix1 += i_pix1, pix2 += i_pix2 )
{
a0 = (sum2_t)(pix1[0] - pix2[0]);
a1 = (sum2_t)(pix1[1] - pix2[1]);
b0 = (a0+a1) + ((a0-a1)<<BITS_PER_SUM);
a2 = (sum2_t)(pix1[2] - pix2[2]);
a3 = (sum2_t)(pix1[3] - pix2[3]);
b1 = (a2+a3) + ((a2-a3)<<BITS_PER_SUM);
tmp[i][0] = b0 + b1;
tmp[i][1] = b0 - b1;
}
for( int i = 0; i < 2; i++ )
{
HADAMARD4( a0, a1, a2, a3, tmp[0][i], tmp[1][i], tmp[2][i], tmp[3][i] ); // 进行哈达玛变换
a0 = abs2(a0) + abs2(a1) + abs2(a2) + abs2(a3);
sum += ((sum_t)a0) + (a0>>BITS_PER_SUM);
}
return sum >> 1;
}
4.小结
帧内预测属于分析模块(或者说预测模块)之中比较简单的部分,有固定的预测模式列表可以使用,只需要一一去遍历查询,寻找一个开销最小的模式即可。在视频编码之中,进行帧内预测的块比进行帧间预测的块的量少得多,尤其是一些实时场景,为了保证实时性,大多数的编码帧都是P帧,这样大多数的编码块都会进行帧间预测。
这里还有一个小细节,假设当前帧为P帧,但是当前的编码块使用帧内预测,且参考块使用帧间预测。由于参考块进行的运动补偿会有误差,而当前块对其进行了参考,这样会导致误差扩散。因此,在这种情况下,使用帧内预测的块的参考块通常选取使用帧内编码的相邻块。
CSDN : https://blog.csdn.net/weixin_42877471
Github : https://github.com/DoFulangChen















 996
996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









