






参考:https://blog.csdn.net/qq_44907926/article/details/119531324
创建项目步骤:
1.目标网站:www.itcast.cn
2.安装虚拟环境
pip install virtualenv
3.创建虚拟环境
virtualenv --always-copy --system-site-packages venv
4.激活虚拟环境
venv\scripts\activate
5.安装twisted(Twisted是基于事件驱动的网络引擎框架)
pip install twisted
6.安装scrapy 爬虫框架
pip install scrapy
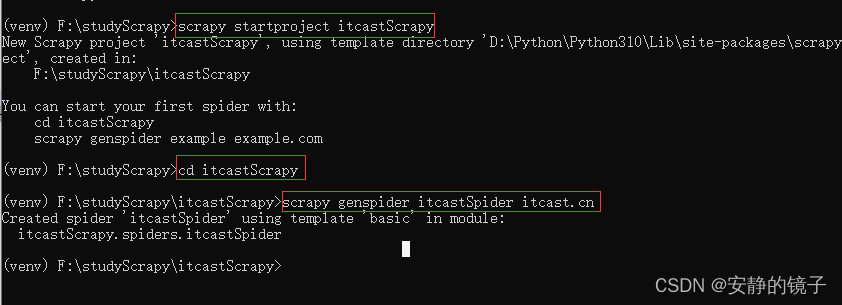
7.创建项目
scrapy startproject itcastScrapy
cd itcastScrapy
#itcastSpider 爬虫名字 itcast.cn 爬虫网站
scrapy genspider itcastSpider itcast.cn
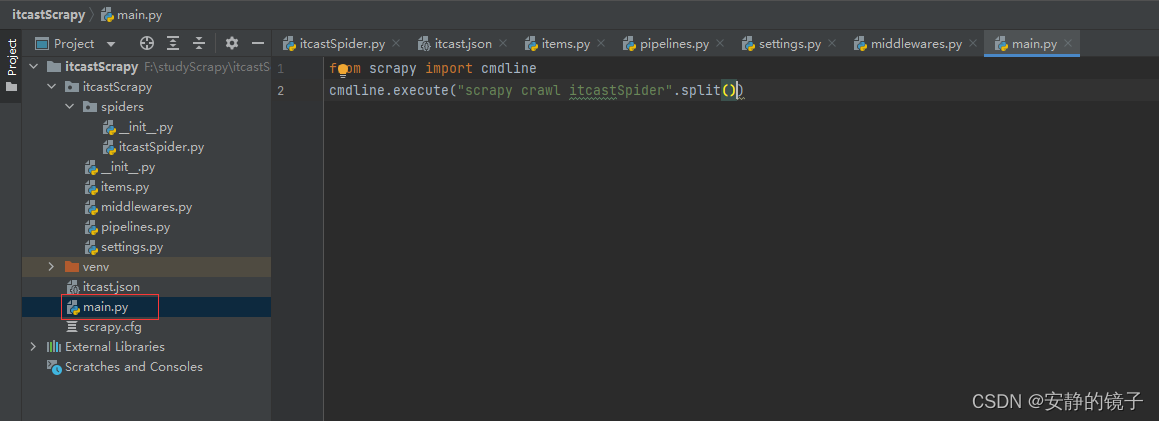
8.创建 main.py 执行scrapy
from scrapy import cmdline
cmdline.execute("scrapy crawl itcastSpider".split())
9.各文件代码
9.1 items.py 需要爬取的内容
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
# 需要爬取的内容 建模
class ItcastscrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class ItcastItem(scrapy.Item):
# 爬取老师信息
name = scrapy.Field()
# 爬取老师职位
title = scrapy.Field()
# 爬取 老师信息
info = scrapy.Field()
9.2 pipelines.py 管道,保存数据
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import json
# 管道,保存数据
class ItcastscrapyPipeline:
def process_item(self, item, spider):
return item
class UbuntuPipeline(object):
def __init__(self):
self.file = open('itcast.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
# 将item对象强制转为字典,该操作只能在scrapy中使用
item = dict(item)
# 爬虫文件中提取数据的方法每yield一次,就会运行一次
# 该方法为固定名称函数
# 默认使用完管道,需要将数据返回给引擎
# 1.将字典数据序列化
'''ensure_ascii=False 将unicode类型转化为str类型,默认为True'''
json_data = json.dumps(item, ensure_ascii=False, indent=2) + ',\n'
# 2.将数据写入文件
self.file.write(json_data)
return item
def __del__(self):
self.file.close()
9.3 middlewares.py 自定义中间件文件
9.4 settings.py 设置文件
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 设置浏览器UA
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36',
}
# 300 优先级,越小执行越早
ITEM_PIPELINES = {
# "itcastScrapy.pipelines.ItcastscrapyPipeline": 300,
"itcastScrapy.pipelines.UbuntuPipeline": 300,
}
9.5 ItcastspiderSpider.py
import scrapy
from ..items import ItcastItem
from bs4 import BeautifulSoup
class ItcastspiderSpider(scrapy.Spider):
name = "itcastSpider"
allowed_domains = ["itcast.cn"]
start_urls = ["https://itcast.cn"]
def parse(self, response):
# 获取网页源代码
# print(response.body.decode())
soup = BeautifulSoup(response.body.decode(), 'lxml')
li_list = soup.select('div.head_nav>ul>li')
for li in li_list:
if li.text.strip() == '教研团队':
for a in li.select('a'):
href = a['href']
yield scrapy.Request(url=href, callback=self.parse_teacher)
break
def parse_teacher(self, response):
# 获取网页源代码
# print(response.body.decode())
items = []
document = BeautifulSoup(response.body.decode(), 'lxml')
li_list = document.select('div.tea_con div.tea_txt_cur ul li')
# 遍历教师节点列表
for li in li_list:
item = ItcastItem()
name = li.select(' div.li_txt h3')[0].text
title = li.select(' div.li_txt h4')[0].text
info = li.select(' div.li_txt p')[0].text
item['name'] = name
item['title'] = title
item['info'] = info
items.append(item)
# 提交所有收集的items
for item in items:
yield item
执行结果
















 57万+
57万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









