






一. 完全基于pipline实现完整的代码部署流水线
流程:开发 提交代码 到gitlab -> clone代码 - > sonarqube执行代码扫描 -> 代码打包(制品)-> 制作镜像(run执行编译,add/copy宿主机上文件,expose端口,cmd启动服务)-> 镜像上传到harbor -> 拉取镜像部署到生产环境 -> send email。

pipline脚本说明,注意设置全局变量时,需要放在env模块里面,才可以被下面不同的模块来引用。每个模块的代码放在相应的stage里面,在sh里面执行shell命令。
pipeline{
agent any //全局必须带有agent,表明此pipeline执行节点
//agent { label 'jenkins-node1' }
options {
buildDiscarder(logRotator(numToKeepStr: '5')) //保留最近5个构建历史
disableConcurrentBuilds() //禁用并发构建
}
//声明环境变量
environment {
//定义镜像仓库地址
def GIT_URL = 'git@192.168.159.130:primaryedu/app1.git'
//镜像仓库变量
def HARBOR_URL = 'harbor.yongedu.net'
//镜像项目变量
def IMAGE_PROJECT = 'myserver'
//镜像名称变量
IMAGE_NAME = 'nginx'
def DATE = sh(script:"date +%F_%H-%M-%S", returnStdout: true).trim() //基于shell命令获取当前时间
def GIT_COMMIT_TAG = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim() //获取clone完成的分支tagId,用于做镜像做tag
}
//参数定义
parameters {
string(name: 'BRANCH', defaultValue: 'develop', description: 'branch select') //字符串参数,会配置在jenkins的参数化构建过程中
choice(name: 'DEPLOY_ENV', choices: ['develop', 'production'], description: 'deploy env') //选项参数,会配置在jenkins的参数化构建过程中
}
stages{
stage("code clone"){
//#agent { label 'master' } //具体执行的步骤节点,非必须
steps {
deleteDir() //删除workDir当前目录
script {
if ( env.BRANCH == 'main' ) {
git branch: 'main', credentialsId: '93711e1d-e4d3-49e5-8652-183d9654c492', url: 'git@192.168.159.130:primaryedu/app1.git'
} else if ( env.BRANCH == 'develop' ) {
git branch: 'develop', credentialsId: '93711e1d-e4d3-49e5-8652-183d9654c492', url: 'git@192.168.159.130:primaryedu/app1.git'
} else {
echo '您传递的分支参数BRANCH ERROR,请检查分支参数是否正确'
}
}
}
}
stage("sonarqube-scanner"){
//#agent { label 'master' } //具体执行的步骤节点,非必须
steps{
dir('/var/lib/jenkins/workspace/pipline-full-test') {
// some block
sh '/apps/sonar-scanner/bin/sonar-scanner -Dsonar.projectKey=magedu -Dsonar.projectName=magedu-app1 -Dsonar.projectVersion=1.0 -Dsonar.sources=./ -Dsonar.language=py -Dsonar.sourceEncoding=UTF-8'
}
}
}
stage("code build"){
//#agent { label 'master' }
steps{
dir('/var/lib/jenkins/workspace/pipline-full-test') {
// some block
sh 'tar czvf frontend.tar.gz ./index.html ./images'
}
}
}
stage("file sync"){ //SSH Pipeline Steps
//#agent { label 'master' }
steps{
dir('/var/lib/jenkins/workspace/pipline-full-test') {
script {
stage('file copy') {
sh 'scp frontend.tar.gz root@192.168.159.132:/opt/ubuntu-dockerfile/'
}
}
}
}
}
stage("image build"){ //SSH Pipeline Steps
//#agent { label 'master' }
steps{
dir('/var/lib/jenkins/workspace/pipline-full-test') {
script {
stage('image put') {
sh 'ssh root@192.168.159.132 "cd /opt/ubuntu-dockerfile && bash build-command.sh ${GIT_COMMIT_TAG}-${DATE}"'
}
}
}
}
}
stage('docker-compose image update') {
steps {
sh """
ssh root@192.168.159.135 "echo ${DATE} && cd /data/magedu-app1 && sed -i 's#image: harbor.yongedu.net/myserver/nginx:.*#image: harbor.yongedu.net/myserver/nginx:${GIT_COMMIT_TAG}-${DATE}#' docker-compose.yml"
"""
}
}
stage('docker-compose app update') {
steps {
sh """
ssh root@192.168.159.135 "echo ${DATE} && cd /data/magedu-app1 && docker-compose pull && docker-compose up -d"
"""
}
}
stage('send email') {
steps {
sh 'echo send email'
}
post {
always {
script {
mail to: '603938723@qq.com',
subject: "Pipeline Name: ${currentBuild.fullDisplayName}",
body: " ${env.JOB_NAME} -Build Number-${env.BUILD_NUMBER} \n Build URL-'${env.BUILD_URL}' "
}
}
}
}
}
}
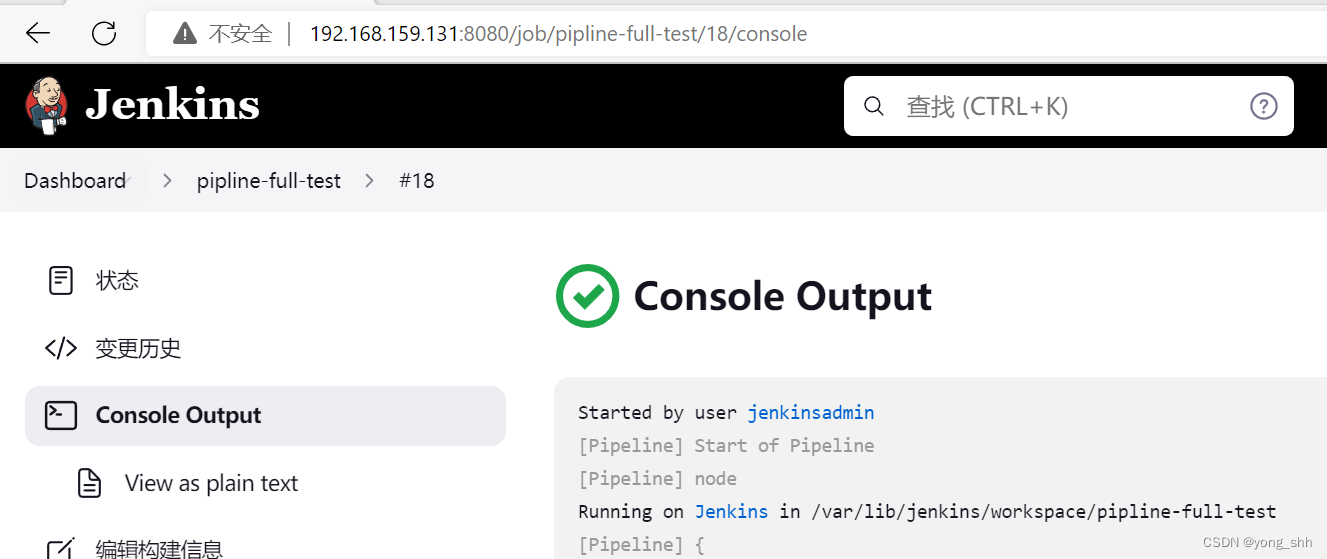
pipline脚本执行成功。
二. 熟悉ELK各组件的功能、elasticsearch的节点角色类型
ELK简介:
elasticsearch: 负责数据存储及检索
logstash:负责日志收集、日志处理并发送至elasticsearch
kibana: 负责从ES读取数据进行可视化展示及数据管理
Elasticsearch主要节点类型:
data node:数据节点,负责数据的存储,如分片的创建及删除、
数据的读写、数据的更新、数据的删除等操作。
master node:主节点,负责index的创建、删除,分片的分配,
node节点的添加、删除,node节点宕机时进行将状态通告至其它
可用node节点,一个ES集群只有一个活跃的master node节点,
其它非活跃的master备用节点将等待master宕机以后进行新的
master的竞选。
client node/coordinating-node:客户端节点或协调节点,负责
将数据读写请求转发data node、将集群管理相关的操作转发到
master node,客户端节点只作为集群的访问入口、其不存储任何
数据,也不参与master角色的选举。
Ingest节点:预处理节点,在检索数据之前可以先对数据做预处理
操作(Ingest pipelines,数据提取管道),可以在管道对数据实现对
数据的字段删除、文本提取等操作。
所有节点其实默认都是支持 Ingest 操作的,也可以专门将某个
节点配置为 Ingest 节点。
Elasticsearch节点类型配置:
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/modules-node.html#node-roles #旧版本定义方式
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/modules-node.html#node-roles #新版本定义方式
master node:主节点
node.master: true #可以参与选举并成为为master,备用的master将等待选举,默认值即为true。
node.data: false #可以作为数据节点,如果为true,则表示该节点同时也可以作为数据节点使用,默认值即为true。
node.roles: [ master ] #ES 7.9开始定义主节点的当前方式
data node:数据节点
node.master: false #不可以成为master节点也不能参数选举,只能作为数据节点使用
node.data: true #角色为数据节点
node.roles: [ data ] #ES 7.9开始定义数据节点的当前方式
client node:客户端节点/协调节点
node.master: false #不是master角色
node.data: false #不是数据节点角色
node.roles: [ ] #ES 7.9开始定义协调节点的当前方式
Ingest节点:预处理节点
所有节点其实默认都是支持 Ingest 操作的,也可以专门将某个节点配置为 Ingest 节点。
node.ingest: true
node.roles: [ ingest ] #ES 7.9开始定义预处理节点的当前方式
Logstash简介:
Logstash是一个具有实时传输能力的数据收集与处理组件,其可以通过插件实现各场景的日志收集、日志过滤、日志处理及
日志输出,支持普通log、json格式等格式的日志解析,处理完成后把日志发送给elasticsearch cluster进行存储。
kibana:
Kibana为elasticsearch提供一个查看数据的web界面,其主要是通过elasticsearch的API接口进行数据查找,并进行前端数据可
视化的展现,另外还可以针对特定格式的数据生成相应的表格、柱状图、饼图等。
三. 熟悉索引、doc、分片与副本的概念
Elasticsearch组成:
Node: 存储业务数据的主机,node节点有多种不同的类型。
Cluster: 多个主机组成的高可用Elasticsearch集群环境。
Document:文档、简称doc,存储在Elasticsearch的数据。
Index:一类相同类型的数据(doc),在逻辑上通过同一个index进行查询、修改与删除等操作。
Shard:分片,是对Index的逻辑拆分存储,分片可以是一个也可以是多个,多个分片合并起来就是Index的所有数据。
Replica:一个分片的跨主机完整备份,分为主分片和副本分片,数据写入主分片时立即同步到副本分片,以实现数据高可用及主分片宕机的故障转
移,副本分片可以读,多副本分片可以提高ES集群的读性能,只有在主分片宕机以后才会给提升为主分片继续写入数据,并为其添加新的副本分片。
四. 掌握不同环境的ELK部署规划,基于deb或二进制部署elasticsearch集群
elasticsearch 8.5.1集群部署:
内核参数优化:
vm.max_map_count=262144
各节点配置主机名解析
资源limit优化:
# cat /etc/security/limits.conf
# End of file
root soft core unlimited
root hard core unlimited
root soft nproc 1000000
root hard nproc 1000000
root soft nofile 1000000
root hard nofile 1000000
root soft memlock 32000
root hard memlock 32000
root soft msgqueue 8192000
root hard msgqueue 8192000
* soft core unlimited
* hard core unlimited
* soft nproc 1000000
* hard nproc 1000000
* soft nofile 1000000
* hard nofile 1000000
* soft memlock 32000
* hard memlock 32000
* soft msgqueue 8192000
* hard msgqueue 8192000
创建普通⽤户运⾏环境:
root# groupadd -g 2888 elasticsearch && useradd -u 2888 -g 2888 -r -m -s /bin/bash
elasticsearch
root# password elasticsearch
部署elasticsearch集群:
root# tar xvf elasticsearch-8.5.1-linux-x86_64.tar.gz
root# ln -sv /apps/elasticsearch-8.5.1 /apps/elasticsearch
root# reboot
各node节点配置service⽂件:
root# cat /lib/systemd/system/elasticsearch.service
[Unit]
Description=Elasticsearch
Documentation=http://www.elastic.co
Wants=network-online.target
After=network-online.target
[Service]
RuntimeDirectory=elasticsearch
Environment=ES_HOME=/apps/elasticsearch
Environment=ES_PATH_CONF=/apps/elasticsearch/config
Environment=PID_DIR=/apps/elasticsearch
WorkingDirectory=/apps/elasticsearch
User=elasticsearch
Group=elasticsearch
ExecStart=/apps/elasticsearch/bin/elasticsearch --quiet
…
批量设置密码:
elasticsearch@es1:/apps/elasticsearch$ bin/elasticsearch-setup-passwords interactive
创建超级管理员账户
elasticsearch@es1:/apps/elasticsearch$ ./bin/elasticsearch-users useradd magedu -p
123456 -r superuser
elasticsearch@es1:/apps/elasticsearch$ curl -u magedu:123456 http://172.31.2.101:9200
{
“name” : “node1”,
“cluster_name” : “magedu-es-cluster”,
“cluster_uuid” : “bo8ls2WsSPKf4aWs-Yef_Q”,
“version” : {
“number” : “8.5.1”,
“build_flavor” : “default”,
“build_type” : “tar”,
“build_hash” : “c1310c45fc534583afe2c1c03046491efba2bba2”,
“build_date” : “2022-11-09T21:02:20.169855900Z”,
“build_snapshot” : false,
“lucene_version” : “9.4.1”,
“minimum_wire_compatibility_version” : “7.17.0”,
“minimum_index_compatibility_version” : “7.0.0”
},
“tagline” : “You Know, for Search”
}
*
五. 了解elasticsearch API的简单使用,安装head插件管理ES的数据
验证集群状态:
root@es1:~# curl -u magedu:123456 http://172.31.2.102:9200
{
"name" : "node2",
"cluster_name" : "magedu-es-cluster",
"cluster_uuid" : "bo8ls2WsSPKf4aWs-Yef_Q",
"version" : {
"number" : "8.5.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "c1310c45fc534583afe2c1c03046491efba2bba2",
"build_date" : "2022-11-09T21:02:20.169855900Z",
"build_snapshot" : false,
"lucene_version" : "9.4.1",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
root@es1:~# curl -u magedu:123456 -X GET http://172.31.2.102:9200 #获取集群状态
root@es1:~# curl -u magedu:123456 -X GET http://172.31.2.102:9200/_cat #集群支持的操作
root@es1:~# curl -u magedu:123456 -X GET http://172.31.2.102:9200/_cat/master?v #获取master信息
root@es1:~# curl -u magedu:123456 -X GET http://172.31.2.102:9200/_cat/nodes?v #获取node节点信息
root@es1:~# curl -u magedu:123456 -X GET http://172.31.2.102:9200/_cat/health?v #获取集群心跳信息
root@es1:~# curl -u magedu:123456 -X PUT http://172.31.2.102:9200/test_index?pretty #创建索引test_index,pretty 为格式序列化
root@es1:~# curl -u magedu:123456 -X GET http://172.31.2.102:9200/test_index?pretty #查看索引
root@es1:~# curl -u magedu:123456 -X POST "http://172.31.2.102:9200/test_index/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{"name": "Jack","age": 19}' #上传数据
root@es1:~# curl -u magedu:123456 -X GET "http://172.31.2.102:9200/test_index/_doc/1?pretty" #查看文档
root@es1:~# curl -u magedu:123456 -X PUT http://172.31.2.102:9200/test_index/_settings -H 'content-Type:application/json' -d
'{"number_of_replicas": 2}' #修改副本数,副本数可动态调整
root@es1:~# curl -u magedu:123456 -X GET http://172.31.2.102:9200/test_index/_settings?pretty #查看索引设置
root@es1:~# curl -u magedu:123456 -X DELETE "http://172.31.2.102:9200/test_index?pretty" #删除索引
root@es1:~# curl -u magedu:123456 -X POST "http://172.31.2.102:9200/test_index/_close" #关闭索引
root@es1:~# curl -u magedu:123456 -X POST "http://172.31.2.102:9200/test_index/_open?pretty" #打开索引
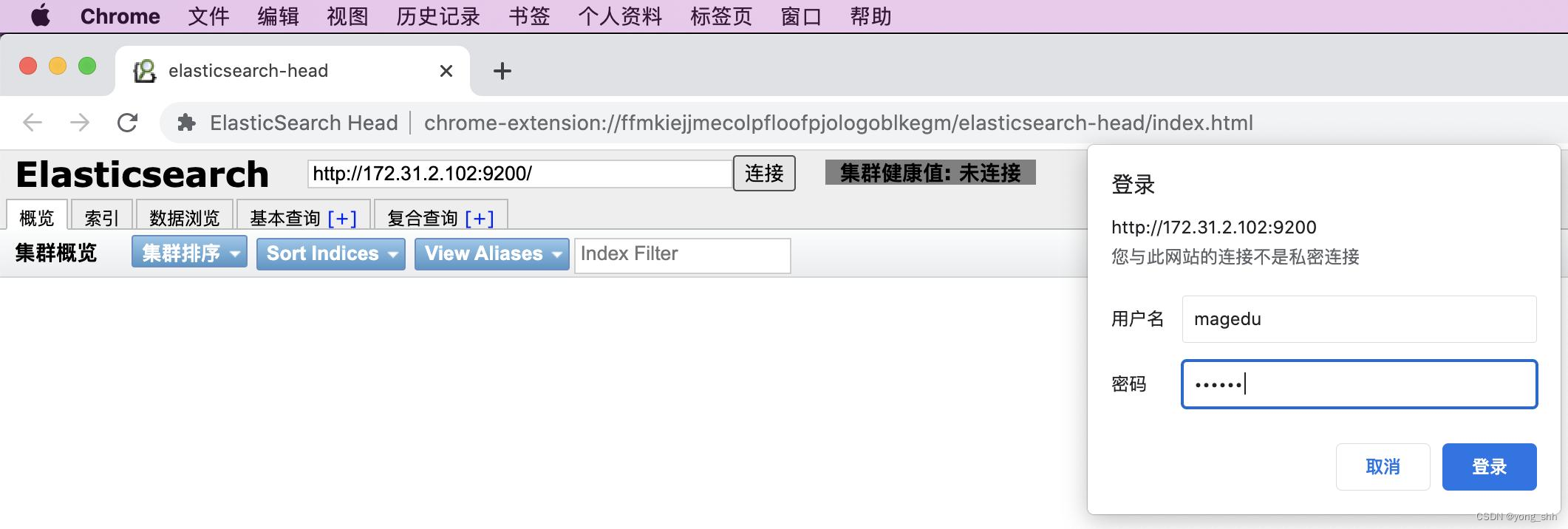
head插件访问elasticsearch 集群
六. 安装logstash收集不同类型的系统日志并写入到ES 的不同index
logstash安装及环境测试:
# dpkg -i logstash-8.5.1-amd64.deb # service文件的启动用户配置
测试标准输出:
# /usr/share/logstash/bin/logstash -e ‘input { stdin{} } output { stdout{ codec => rubydebug }}’ #直接启动logsatsh测试标准输入和输出
hello world
{
“event” => {
“original” => “hello world” #源内容
},
“message” => “hello world”, #经过logstash输出后的消息内容
“@timestamp” => 2022-11-18T03:15:10.778250378Z, #当前事件发生的具体时间
“host” => {
“hostname” => “logstash1.example.com” #事件发生的具体主机(会获取当前主机名)
},
“@version” => “1” #事件版本号,一个事件就是一个ruby对象
}
测试输出到文件:
# /usr/share/logstash/bin/logstash -e ‘input { stdin{} } output { file { path => “/tmp/logstash-test-%{+YYYY.MM.dd}.txt”}}’ #输出到文件
基于logstash收集单个文件并输出到elasticsearch:
# cat /etc/logstash/conf.d/syslog-to-es.conf
input {
file {
path => “/var/log/syslog”
type => “systemlog”
start_position => “beginning”
stat_interval => “1”
}
}
output {
if [type] == “systemlog” {
elasticsearch {
hosts => [“172.31.2.101:9200”]
index => “magedu-systemlog-%{+YYYY.MM.dd}”
password => “123456”
user => “magedu”
}}
}
# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/syslog-to-es.conf -t
Configuration OK
~# systemctl start logstash && systemctl enable logstash

七. 安装kibana、查看ES集群的数据
kibana安装:
root@es1:/usr/local/src# dpkg -i kibana-8.5.1-amd64.deb
server.port: 5601
elasticsearch.hosts: ["http://172.31.2.102:9200"]
elasticsearch.username: "kibana_system"
elasticsearch.password: "magedu123"
i18n.locale: "zh-CN"
root@es1:/usr/local/src# systemctl restart kibana.service
root@es1:/usr/local/src# systemctl enable kibana.service
root@es1:/usr/local/src# lsof -i:5601
root@es1:/usr/local/src# tail -f /var/log/kibana/kibana.log
基于logstash收集多个文件并输出到elasticsearch:
# cat /etc/logstash/conf.d/syslog-to-es.conf
input {
file {
path => "/var/log/syslog"
type => "systemlog"
start_position => "beginning"
stat_interval => "1"
}
file {
path => "/var/log/auth.log"
type => "authlog"
start_position => "beginning"
stat_interval => "1"
}
}
output {
if [type] == "systemlog" {
elasticsearch {
hosts => ["172.31.2.101:9200"]
index => "magedu-systemlog-%{+YYYY.MM.dd}"
password => "123456"
user => "magedu"
}}
if [type] == "authlog" {
elasticsearch {
hosts => ["172.31.2.101:9200"]
index => "magedu-authlog-%{+YYYY.MM.dd}"
password => "123456"
user => "magedu"
}}
}
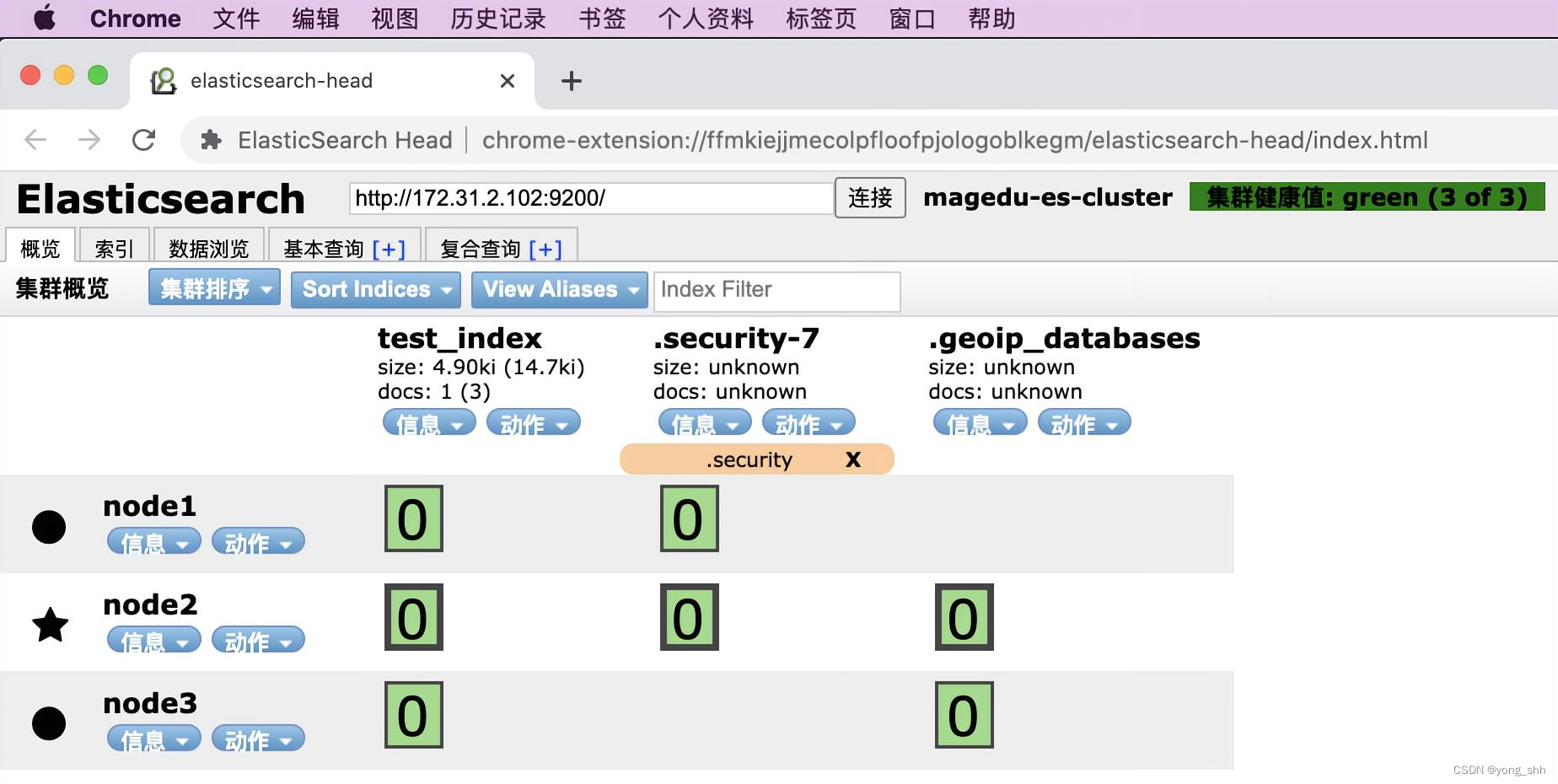
elasticsearch验证数据:

kibana添加索引并验证数据:















 2413
2413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









