






背景
- 需求背景
依据公司广告运营和产品决策的需求,从数据、媒体、广告位、广告主四个维度对广告数据流进行分析,主要分别按小时、天、月统计广告数据流的pv,uv,点击数和分时趋势、日趋势以及月趋势。
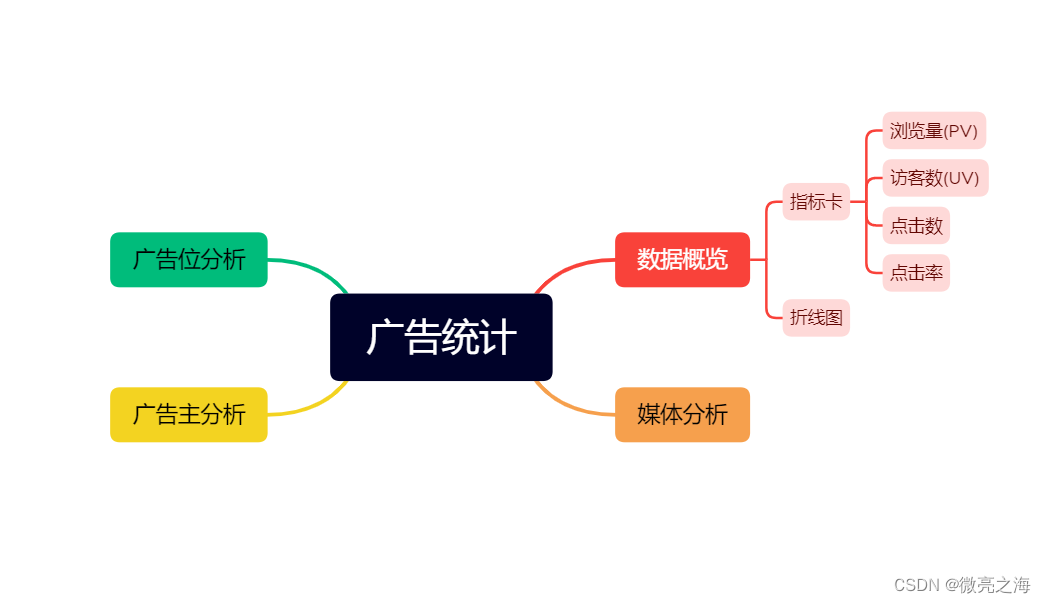
问题一
- 遇到的问题
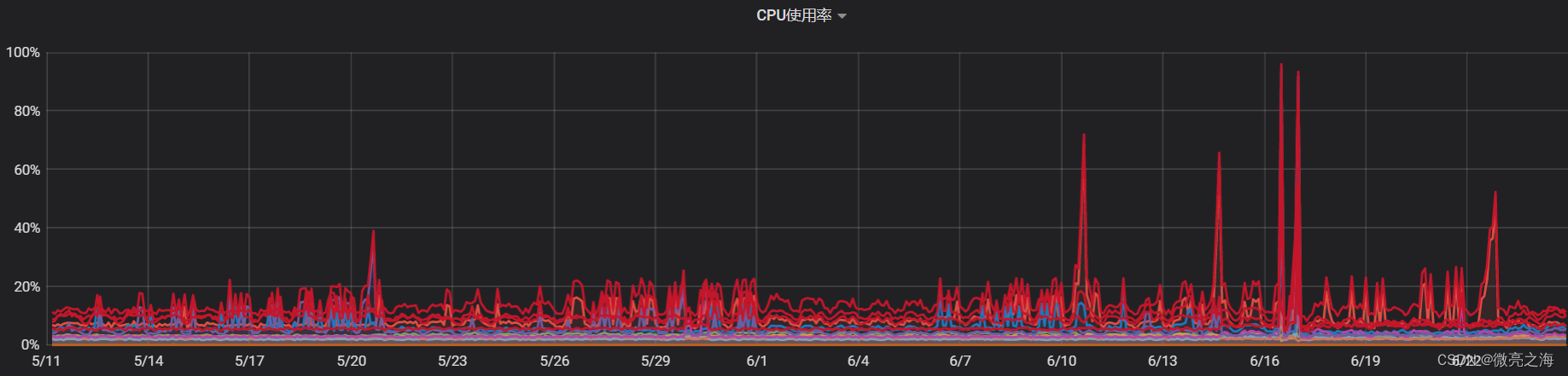
程序开发上线后,由于广告实时统计里面的UV指标,是按照IP去重的,在Flink流式计算中,去重需要把某个时间窗口的IP都缓存到内存中, 每次来一条浏览记录需要检查IP是否在缓存中存在来实现去重统计,按日的统计还好这个缓存不大,但是按月的统计就需要在缓存中 保存一个月的IP数据,导致数据量较大,然后Flink有个checkpoint检查点机制,每隔一段时间会把所有的状态数据包括缓存写到hdfs中, 当缓存的数据比较大的时候,这个写checkpoint检查点数据的时候,就会大量消耗内存和CPU,偶尔造成进程异常退出。
解决方案一
优化方法:为了解决该问题,我们调研了业内在Flink流式计算实现去重的方法,发现了一种大家在数据量较大的去重场景,都会使用到 的一种算法,叫做布隆过滤算法,可以实现大数据量的去重统计,并且占用内存小,但是也有缺点就是采用的是概率算法,会存在一定的误差。 目前在网上查到的别人的测试数据,在百万UV级别,误差为0,在千万级别,误差为0.07%,在过亿级别,误差为23%。目前我们的UV级别在2000万左右。 并且我们只打算在按月统计UV这一个指标上应用该算法。
布隆过滤器简介
布隆过滤器本质上是一个二进制向量(位数组)和一系列随机映射函数(哈希函数),用于判断数据一定不存在,或者可能存在。
使用布隆过滤器去重,首先准备长度为M的位数组和K个哈希函数,对于到来的数据进行K次哈希,并将位数组中hash值对应的位置修改为1。
-
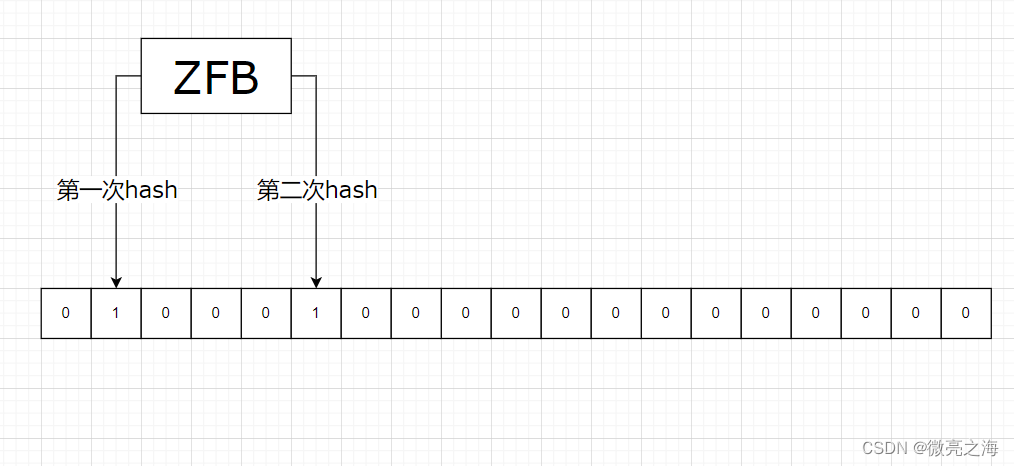
举例说明,现有4条所需处理数据(ZFB,WX,DY,ZFB),准备以下位数组以及2个哈希函数

位数组 -
第一条数据ZFB到来,经过两次哈希,分别将位数组哈希对应位置由0修改为1
-
第二条数据WX到来,经过两次哈希,分别将位数组哈希对应位置由0修改为1
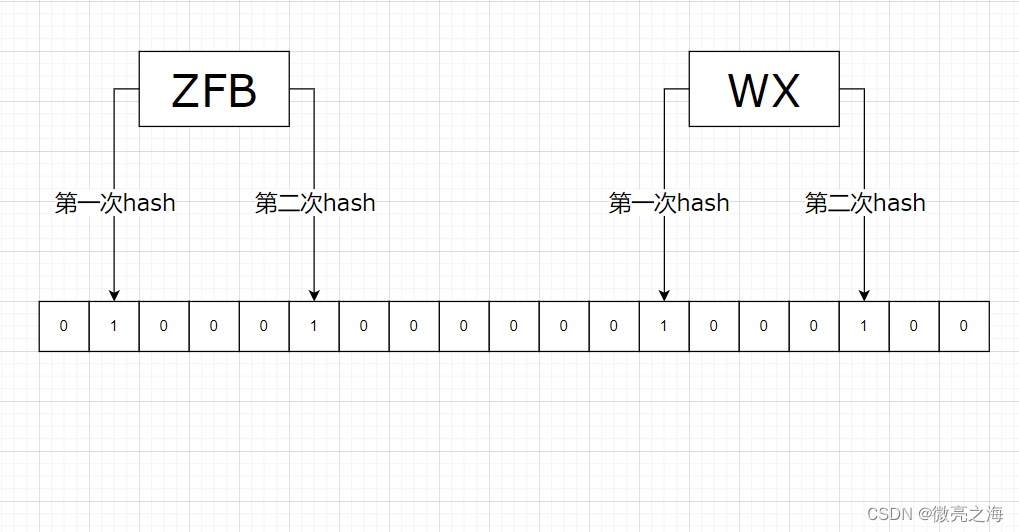
-
第三条数据DY到来,经过两次哈希,发现位数组哈希对应位置都为1,于是判断DY为重复数据。这里DY存在哈希冲突,本来不在里面,但是误判为在,错误去重。哈希冲突就是布隆过滤器会产生误差的原因,可以通过增大位数组长度以及增加Hash函数来减少哈希碰撞以减小错误率。
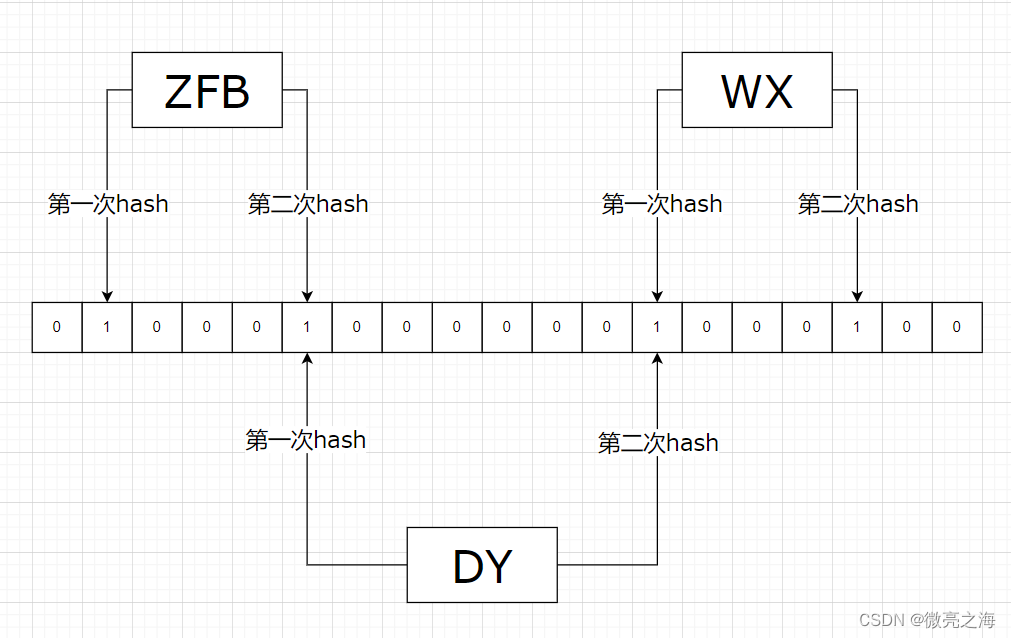
-
第四条数据ZFB到来,经过两次哈希,发现位数组对应位置都为1,判断ZFB为重复数据,正确去重。
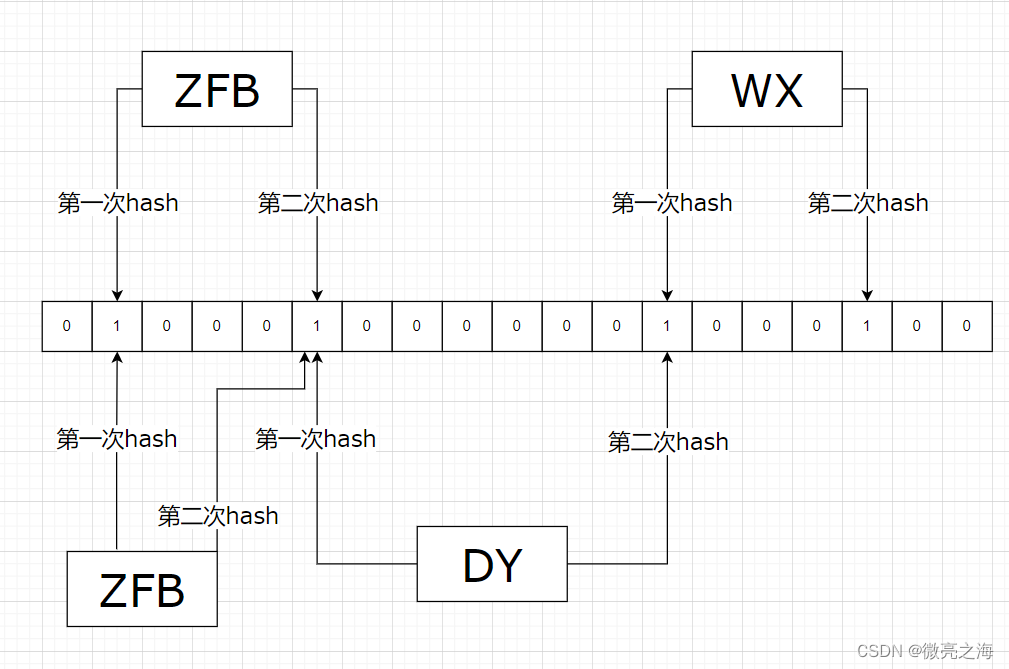
-
总结
使用布隆过滤器之前,去重需要缓存4条数据在内存中,使用布隆过滤器之后,去重只需要在内存中缓存一个固定长度的位数组,当然4条数据和一个位数组大小差不了多少,但是当面对4万条、400万条甚至4000万条数据的时候,缓存一个位数组和缓存4000万条数据对内存的占用就高下立判了。
布隆过滤是一种算法思想,我们可以基于算法原理自己实现,当然更方便的做法是引用Google官方在guava包实现的布隆过滤器。在guava包中的BloomFilter源码中,构造一个BloomFilter对象有三个参数:
- **Funnel funnel:**所需处理的数据类型,由Funnels类指定即可
- **int expectedInsertions:**预期插入的值的数量
- **double fpp:**错误率
程序根据提供的预期值和可容忍的错误率产生固定长度的位数组和选择一定数量的Hash函数,fpp越低,则位数组长度越长,Hash函数越多,CPU资源和内存资源消耗相应增加
问题二
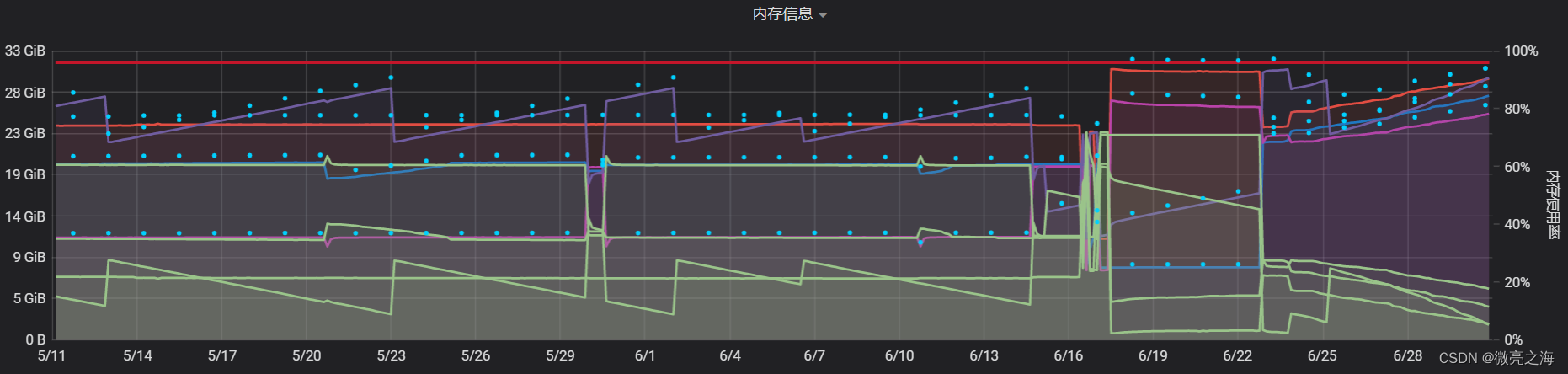
在按月统计的窗口中使用布隆过滤器上线之后,内存缓存由原来的缓存所有IP数据变为缓存一个固定长度的位数组,但是在Grafana内存监控中发现内存使用仍然是持续攀升。

这个现象十分的不正常,因为程序中一共有三种窗口,按小时窗口,按天窗口,按月窗口,按小时窗口和按天的窗口结束后,内存使用监控应该观察到明显到回落,但是实际情况确实持续攀升,这个现象更像是窗口结束但是窗口占用的内存却没有释放。
这个问题让我很疑惑,根据之前的经验,在窗口结束的时候会调用窗口的clear()方法来清理窗口中间状态以释放内存。在程序中的每个窗口中,明明全部重写了clear()方法,但是在窗口结束后状态没有得到清理,内存也没有释放,所以导致了内存占用持续攀升。
虽然布隆过滤器优化了内存占用,但是占用的少,程序不释放内存,还是会导致内存使用持续上升。
由于我之前没有遇到过这种问题,和组内同事们沟通之后,发现大家开的窗口一般都是秒级别和分钟级别的,都可以正常释放内存,组内小伙伴都没有遇到此类问题。于是在网上搜索相关问题,发现果然存在类似的问题:
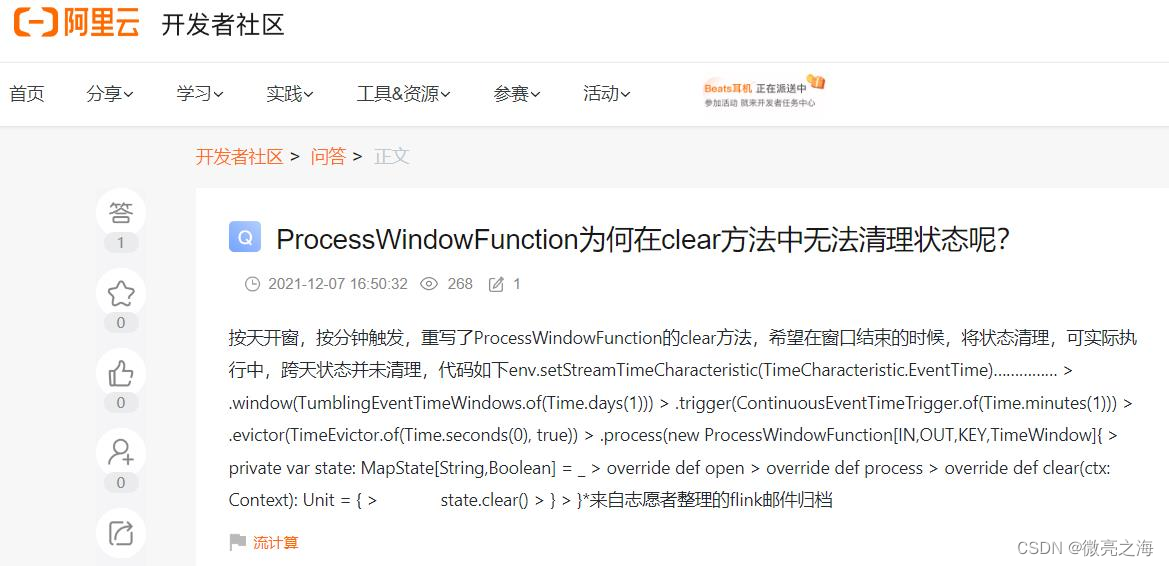
但是也仅是一个提问,并没有对应的解决方法。
于是我在各大数据社区以及Flink社区中提问,在博客园中给写过类似博客的牛人发邮件,和之前有幸添加过微信好友的Flink牛人咨询,以及翻看Flink官网doc,经过零零散散的信息拼凑,总结出此类问题的原因以及解决方法。
解决方案二
导致此问题的原因
全量窗口状态有两部分,一部分是窗口本身的状态比如窗口数据,这部分状态会随着窗口的过期而释放;一部分是程序中自定义的状态,这个需要在程序中自己清理或者使用 TTL清理。
解决方案之一:TTL
Flink官网文档中对于TTL是这样解释的:
TTL全称Time-to-Live,表示状态的生命周期。任何类型的 keyed state 都可以有 有效期 (TTL)。如果配置了 TTL 且状态值已过期,则会尽最大可能清除对应的值,这会在后面详述。所有状态类型都支持单元素的 TTL。 这意味着列表元素和映射元素将独立到期。
但是在官方文档的末尾标注了注意事项,其中之一居然是Flink暂时只支持基于 processing time 的 TTL。由于程序中使用的时间语义是EventTime,所以这条路走不通
解决方案之二:自定义触发器
我们知道Flink框架主要用来进行实时流式计算,但是在我们开的按小时,按天,按月的全量窗口中,如果不做额外处理,全量窗口就会将数据攒在窗口中,等到窗口结束时间的时候才开始计算,那这不就是批处理吗!就失去了Flink流处理的优势,而触发器就是解决这个问题的方法之一。
我们开的窗口实时接收数据,而触发器可以自定义间隔时间就窗口中目前拥有的数据触发一次计算并输出,这样在数据应用层观察到的结果就是实时变动的。
官方文档中这样描述触发器:
触发器接口有五种方法允许一个
Trigger对不同的事件做出反应:
onElement()为添加到窗口的每个元素调用该方法。onEventTime()当注册的事件时间计时器触发时调用该方法。- 当注册的处理时间计时器触发时,将调用该
onProcessingTime()方法。- 该
onMerge()方法与有状态触发器相关,并在两个触发器的相应窗口合并时合并两个触发器的状态,例如在使用会话窗口时。- 最后,该
clear()方法执行移除相应窗口时所需的任何操作。上述方法需要注意的两点是:
- 前三个决定如何通过返回一个来处理他们的调用事件
TriggerResult。该操作可以是以下之一:
CONTINUE: 没做什么,FIRE:触发计算,PURGE:清除窗口中的元素,并且FIRE_AND_PURGE:触发计算,然后清除窗口中的元素。
- 具体操作方案
默认情况下,预实现的触发器只是简单地
FIRE不清除窗口状态。所以我们需要自定义触发器,在触发器中判断窗口到期后返回FIRE_AND_PURGE,触发计算并销毁窗口,清理状态。
- 以下为自定义触发器代码
public class MyEventTrigger<W extends Window> extends Trigger<Object, W> {
private static final long serialVersionUID = 1L;
private final long interval;
private final ReducingStateDescriptor<Long> stateDesc =
new ReducingStateDescriptor<>("fire-time", new MyEventTrigger.Min(), LongSerializer.INSTANCE);
private MyEventTrigger(long interval) {
this.interval = interval;
}
@Override
public TriggerResult onElement(Object element, long timestamp, W window, TriggerContext ctx)
throws Exception {
if (window.maxTimestamp() <= ctx.getCurrentWatermark()) {
// if the watermark is already past the window fire immediately
return TriggerResult.FIRE;
} else {
ctx.registerEventTimeTimer(window.maxTimestamp());
}
ReducingState<Long> fireTimestamp = ctx.getPartitionedState(stateDesc);
if (fireTimestamp.get() == null) {
long start = timestamp - (timestamp % interval);
long nextFireTimestamp = start + interval;
ctx.registerEventTimeTimer(nextFireTimestamp);
fireTimestamp.add(nextFireTimestamp);
}
return TriggerResult.CONTINUE;
}
@Override
public TriggerResult onEventTime(long time, W window, TriggerContext ctx) throws Exception {
if (time >= window.maxTimestamp()) {
return TriggerResult.FIRE_AND_PURGE;
}
ReducingState<Long> fireTimestampState = ctx.getPartitionedState(stateDesc);
Long fireTimestamp = fireTimestampState.get();
if (fireTimestamp != null && fireTimestamp == time) {
fireTimestampState.clear();
fireTimestampState.add(time + interval);
ctx.registerEventTimeTimer(time + interval);
return TriggerResult.FIRE;
}
return TriggerResult.CONTINUE;
}
@Override
public TriggerResult onProcessingTime(long time, W window, TriggerContext ctx)
throws Exception {
return TriggerResult.CONTINUE;
}
@Override
public void clear(W window, TriggerContext ctx) throws Exception {
ReducingState<Long> purgingTimestamp = ctx.getPartitionedState(stateDesc);
Long timestamp = purgingTimestamp.get();
if (timestamp != null) {
ctx.deleteEventTimeTimer(timestamp);
purgingTimestamp.clear();
}
}
@Override
public boolean canMerge() {
return true;
}
@Override
public void onMerge(W window, OnMergeContext ctx) throws Exception {
ctx.mergePartitionedState(stateDesc);
Long nextFireTimestamp = ctx.getPartitionedState(stateDesc).get();
if (nextFireTimestamp != null) {
ctx.registerEventTimeTimer(nextFireTimestamp);
}
}
@Override
public String toString() {
return "MyEventTrigger(" + interval + ")";
}
@VisibleForTesting
public long getInterval() {
return interval;
}
public static <W extends Window> MyEventTrigger<W> of(Time interval) {
return new MyEventTrigger<>(interval.toMilliseconds());
}
private static class Min implements ReduceFunction<Long> {
private static final long serialVersionUID = 1L;
@Override
public Long reduce(Long value1, Long value2) throws Exception {
return Math.min(value1, value2);
}
}
}
问题三
代码通过自定义触发器优化后,发现不能从checkpoint启动。
Checkpoint 使 Flink 的状态具有良好的容错性,checkpoint 中保存程序的中间状态,通过 checkpoint 机制,Flink 可以对作业的状态和计算位置进行恢复。但是源码中涉及到状态的部分有修改,就不能通过checkpoint恢复了。必须等到程序所有的窗口都结束,计算结果写入结果表时停止老程序,然后指定kafka消费位置上线新程序。所以必须要等到月底按月的窗口结束后才可操作。
但是现在内存持续攀升,马上就要触顶,触顶后随时可能出现OOM(内存溢出),造成程序崩溃。需要采用其他方法维持程序稳定到月底。
解决方案三
在之前的解决问题过程中,我注意到程序的内存资源分配不合适,还有很大的优化空间。
Flink内存构成是JobManager进程内存+TaskManager进程内存,JobManager进程内存一般配置2~4G足够,因为只负责资源调度,真正干活的是TaskManager,下面谈谈TaskManager进程内存调优。
TaskManager内存模型
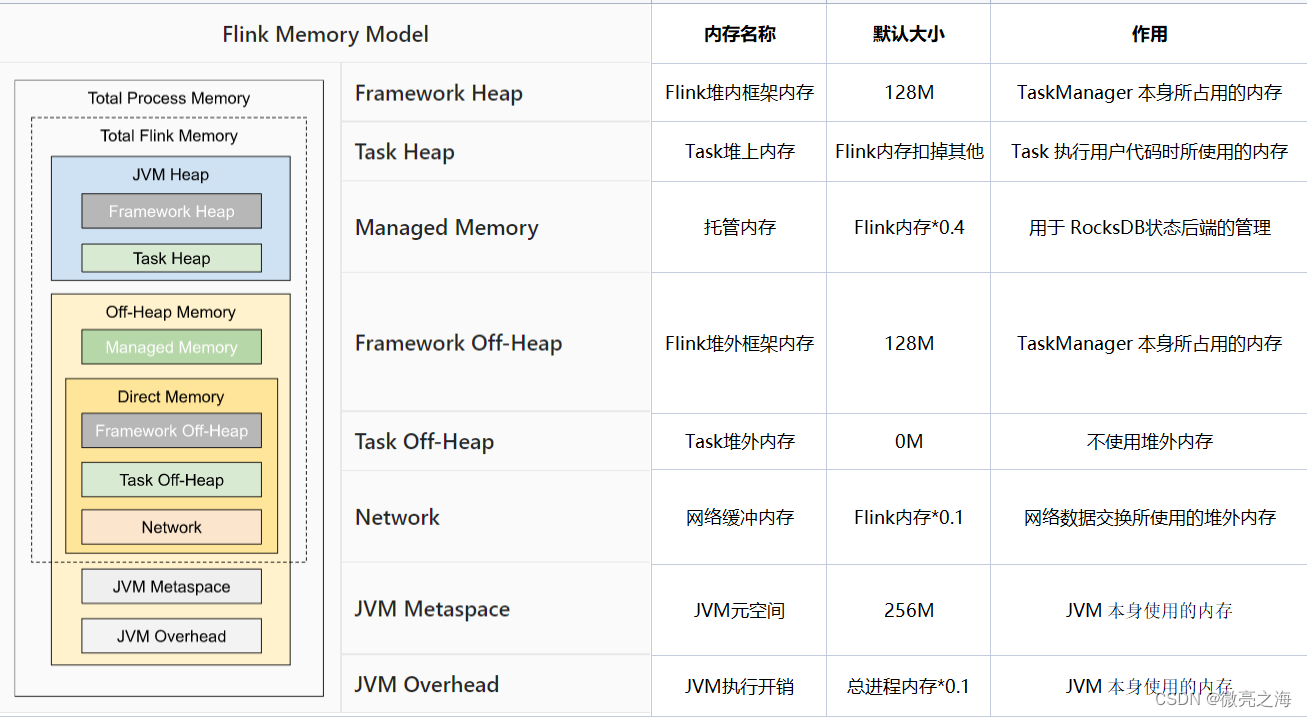
执行用户代码的内存是Task堆上内存,内存调优主要是增大这部分内存。但是这部分内存不可以直接调整,我们可以通过减少其他的内存来达到增大Task堆上内存的目的。
通过以上TaskManager内存模型我们可以发现,
Flink堆内框架内存、Flink堆外框架内存、Task堆外内存、JVM元空间
这四个内存是固定大小,内存占用也不大,无需调整。主要是调整按比例划分内存的
JVM执行开销、网络缓冲内存、托管内存
-
JVM over-head 执行开销:JVM 执行时自身所需要的内容,包括线程堆栈、IO、编译缓存等所使用的内存。
taskmanager.memory.jvm-overhead.fraction,默认 0.1
taskmanager.memory.jvm-overhead.min,默认 192mb
taskmanager.memory.jvm-overhead.max,默认 1gb
建议调整到192mb
-
网络内存:网络数据交换所使用的堆外内存大小,如网络数据交换缓冲区taskmanager.memory.network.fraction,默认 0.1
taskmanager.memory.network.min,默认 64mb
taskmanager.memory.network.max,默认 1gb
建议调整到64mb
-
托管内存:用于 RocksDB State Backend 的本地内存和批的排序、哈希表、缓存中间结果。taskmanager.memory.managed.fraction,默认 0.4
taskmanager.memory.managed.size,默认 none
如果状态后端不为RocksDB,请将托管内存调整为0
调优后启动参数:
./flink run
-t yarn-per-job
-d
-Dparallelism.default=4
-Dyarn.application.name=newadpro
-Djobmanager.memory.process.size=2048mb
-Dtaskmanager.memory.process.size=20480mb
-Dtaskmanager.memory.managed.size=0
-Dtaskmanager.memory.jvm-overhead.fraction=0.01
-Dtaskmanager.memory.network.fraction=0.01
-Dtaskmanager.numberOfTaskSlots=1
-c 启动类
-s checkpoint地址
jar包地址
问题四
经过内存调优后,Task可用内存从原本15G增加到20G,将可用内存利用到极致,内存压力得到了明显的缓解。
在组内讨论这项工作的时候,组长建议将状态后端调整为RocksDB,由基于内存的状态后端管理转变为基于磁盘的状态后端管理,可以一劳永逸的解决这件事情。
解决方案四
状态后端简介
状态编程一直是Flink的特点和优势,可以将计算的运行时状态保存下来并应用到上下文的计算中,让Flink可以更加灵活和快速的处理流式数据。而状态后端是Flink官方提供的开箱即用的状态管理插件。
自Flink1.13.0版本依赖,状态后端由之前的三种调整为两种。
- HashMapStateBackend
- EmbeddedRocksDBStateBackend
HashMapStateBackend
在 HashMapStateBackend 内部,数据以 Java 对象的形式存储在堆中。 Key/value 形式的状态和窗口算子会持有一个 hash table,其中存储着状态值、触发器。
HashMapStateBackend 的适用场景:
- 有较大 state,较长 window 和较大 key/value 状态的 Job。
- 所有的高可用场景。
建议同时将 managed memory 设为0,以保证将最大限度的内存分配给 JVM 上的用户代码。
EmbeddedRocksDBStateBackend
EmbeddedRocksDBStateBackend 将正在运行中的状态数据保存在 RocksDB 数据库中,RocksDB 数据库默认将数据存储在 TaskManager 的数据目录。 不同于 HashMapStateBackend 中的 java 对象,数据被以序列化字节数组的方式存储,这种方式由序列化器决定,因此 key 之间的比较是以字节序的形式进行而不是使用 Java 的 hashCode 或 equals() 方法。
EmbeddedRocksDBStateBackend 会使用异步的方式生成 snapshots。
EmbeddedRocksDBStateBackend 的适用场景:
- 状态非常大、窗口非常长、key/value 状态非常大的 Job。
- 所有高可用的场景。
注意,你可以保留的状态大小仅受磁盘空间的限制。与状态存储在内存中的 HashMapStateBackend 相比,EmbeddedRocksDBStateBackend 允许存储非常大的状态。
RocksDB大状态调优
RocksDB 是基于 LSM Tree 实现的(类似 HBase),写数据都是先缓存到内存中, 所以 RocksDB 的写请求效率比较高。RocksDB 使用内存结合磁盘的方式来存储数据,每次获取数据时,先从内存中 blockcache 中查找,如果内存中没有再去磁盘中查询。使用RocksDB 时,状态大小仅受可用磁盘空间量的限制,性能瓶颈主要在于 RocksDB 对磁盘的读请求,每次读写操作都必须对数据进行反序列化或者序列化。当处理性能不够时,仅需要横向扩展并行度即可提高整个 Job 的吞吐量。

从 Flink1.10 开始,Flink 默认将 RocksDB 的内存大小配置为每个 task slot 的托管内存。调试内存性能的问题主要是通过调整配置项 taskmanager.memory.managed.size 或者 taskmanager.memory.managed.fraction 以增加 Flink 的托管内存(即堆外的托管内存)。进一步可以调整一些参数进行高级性能调优,这些参数也可以在应用程序中通过RocksDBStateBackend.setRocksDBOptions(RocksDBOptionsFactory)指定。下面介绍提高资源利用率的几个重要配置:
1.开启State访问性能监控
State 访问的性能监控会产生一定的性能影响,所以,默认每 100 次做一次取样
(sample),对不同的 State Backend 性能损失影响不同:
对于 RocksDB State Backend,性能损失大概在 1% 左右对于 Heap State Backend,性能损失最多可达 10%
-Dstate.backend.latency-track.keyed-state-enabled=true
2.开启增量检查点和本地恢复
1) 开启增量检查点
RocksDB 是目前唯一可用于支持有状态流处理应用程序增量检查点的状态后端,可以修改参数开启增量检查点:
state.backend.incremental: true #默认 false,改为true。
或代码中指定 new EmbeddedRocksDBStateBackend(true)
2) 开启本地恢复
当 Flink 任务失败时,可以基于本地的状态信息进行恢复任务,可能不需要从 hdfs 拉取数据。本地恢复目前仅涵盖键控类型的状态后端(RocksDB),MemoryStateBackend 不支持本地恢复并忽略此选项。
state.backend.local-recovery: true
3) 设置多目录
如果有多块磁盘,也可以考虑指定本地多目录
state.backend.rocksdb.localdir:
/data1/flink/rocksdb,/data2/flink/rocksdb,/data3/flink/rocksdb
注意:不要配置单块磁盘的多个目录,务必将目录配置到多块不同的磁盘上,让多块磁盘来分担压力。
3.调整预定义选项
Flink 针对不同的设置为 RocksDB 提供了一些预定义的选项集合,其中包含了后续提到的一些参数,如果调整预定义选项后还达不到预期,再去调整后面的 block、writebuffer 等参数。
当 前 支 持 的 预 定 义 选 项 有
DEFAULT 、
SPINNING_DISK_OPTIMIZED 、
SPINNING_DISK_OPTIMIZED_HIGH_MEM 、
FLASH_SSD_OPTIMIZED
state.backend.rocksdb.predefined-options: SPINNING_DISK_OPTIMIZED_HIGH_MEM
#设置为机械硬盘+内存模式
4. 增大block缓存
整个 RocksDB 共享一个 block cache,读数据时内存的 cache 大小,该参数越大读数据时缓存命中率越高,默认大小为 8 MB,建议设置到 64 ~ 256 MB。
state.backend.rocksdb.block.cache-size: 64m
#默认 8m
5.增大writebuffer 和 level 阈值大小
RocksDB 中,每个 State 使用一个 Column Family,每个 Column Family 使用独占的 write buffer,默认 64MB,建议调大。
调整这个参数通常要适当增加 L1 层的大小阈值 max-size-level-base,默认 256m。该值太小会造成能存放的 SST 文件过少,层级变多造成查找困难,太大会造成文件过多, 合并困难。建议设为 target_file_size_base(默认 64MB) 的倍数,且不能太小,例如 5~10 倍,即 320~640MB。
state.backend.rocksdb.writebuffer.size: 128m
state.backend.rocksdb.compaction.level.max-size-level-base: 320m
6. 增大write buffer 数量
每个 Column Family 对应的 writebuffer 最大数量,这实际上是内存中“只读内存表“的最大数量,默认值是 2。对于机械磁盘来说,如果内存足够大,可以调大到 5 左右
state.backend.rocksdb.writebuffer.count: 5
7. 增大后台线程数和writebuffer合并数
1)增大线程数
用于后台 flush 和合并 sst 文件的线程数,默认为 1,建议调大,机械硬盘用户可以改为 4 等更大的值
state.backend.rocksdb.thread.num: 4
2)增大writebuffer 最小合并数
将数据从 writebuffer 中 flush 到磁盘时,需要合并的 writebuffer 最小数量,默认值为 1,可以调成 3。
state.backend.rocksdb.writebuffer.number-to-merge: 3
8.开启分区索引功能
Flink 1.13 中对 RocksDB 增加了分区索引功能,复用了 RocksDB 的 partitioned Index & filter 功能,简单来说就是对 RocksDB 的 partitioned Index 做了多级索引。
也就是将内存中的最上层常驻,下层根据需要再 load 回来,这样就大大降低了数据 Swap竞争。线上测试中,相对于内存比较小的场景中,性能提升 10 倍左右。如果在内存管控下 Rocksdb 性能不如预期的话,这也能成为一个性能优化点。
state.backend.rocksdb.memory.partitioned-index-filters:true
#默认false
具体实施案例
- 在代码中设置
env.setStateBackend(new EmbeddedRocksDBStateBackend());
- 启动参数配置案例
/home/hdfs/flink/bin/flink run \
-t yarn-per-job \
-p 4 \
-d \
-Drest.flamegraph.enabled=true \
-Dyarn.application.name=newadpro \
-Djobmanager.memory.process.size=2048mb \
-Dtaskmanager.memory.process.size=20480mb \
-Dtaskmanager.numberOfTaskSlots=1 \
-Dtaskmanager.memory.managed.fraction=0.7 \
-Dtaskmanager.memory.network.fraction=0.01 \
-Dtaskmanager.memory.jvm-overhead.fraction=0.01 \
-Dstate.backend.incremental=true \
-Dstate.backend.local-recovery=true \
-Dstate.backend.rocksdb.predefined-options=SPINNING_DISK_OPTIMIZED_HIGH_MEM \
-Dstate.backend.rocksdb.block.cache-size=256m \
-Dstate.backend.rocksdb.writebuffer.size=256m \
-Dstate.backend.rocksdb.compaction.level.max-size-level-base=640m \
-Dstate.backend.rocksdb.writebuffer.count=5 \
-Dstate.backend.rocksdb.thread.num=4 \
-Dstate.backend.rocksdb.writebuffer.number-to-merge=3 \
-Dstate.backend.rocksdb.memory.partitioned-index-filters=true \
-Dstate.backend.latency-track.keyed-state-enabled=true \
-c com.nuonuo.advertise.streamjob.Ad \
-s hdfs://hdptest/flinkinvoice/flink-checkpoints/8b8e18e2c157245732c3c71bce92c59f/chk-24/_metadata \
/home/hdfs/jar_flink/sml/advertising-statistics-1.0.jar















 1359
1359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









