







 本文深入探讨Dubbo微服务框架的核心概念,包括分布式RPC、服务注册与发现、负载均衡策略、序列化与通信协议。解析Dubbo如何通过Zookeeper实现服务治理,以及Dubbo在服务调用、监控和管理方面的优势。
本文深入探讨Dubbo微服务框架的核心概念,包括分布式RPC、服务注册与发现、负载均衡策略、序列化与通信协议。解析Dubbo如何通过Zookeeper实现服务治理,以及Dubbo在服务调用、监控和管理方面的优势。
分布式 + RPC 介绍:
https://blog.csdn.net/weixin_42915286/article/details/90479469
https://www.bilibili.com/video/av30612478/
序列化框架:Hessian(默) / Dubbo
通信框架:netty(默) / mina
通信协议:Dubbo / rmi / WebService / memcache
——————————————
面试
提问:序列化?
把数据结构或者对象转换为:二进制串;
反序列化就是反过来;
提问:dubbo是什么?
http://dubbo.apache.org/zh-cn/
dubbo是一个微服务框架,RPC分布式框架,其核心部分包含:
集群容错:提供基于接口方法的透明RPC,包括多协议支持,以及软负载均衡,失败容错,地址路由,动态配置等集群支持。
远程通讯:提供对多种基于长连接的NIO框架抽象封装,包括多种线程模型,序列化,以及“请求-响应”模式的信息交换方式。
自动发现:基于注册中心目录服务,使Consumer能动态的查找Provider,使地址透明,使Provider可以平滑增加或减少机器。
提问:dubbo能做什么?
透明化的远程方法调用,就像调用本地方法一样调用远程方法,只需简单配置,没有任何API侵入。
软负载均衡及容错机制,可在内网替代F5等硬件负载均衡器,降低成本,减少单点。
服务自动注册与发现,不再需要写死服务提供方地址;注册中心基于接口名查询服务提供者的IP地址,并且能够平滑添加或删除服务提供者。
提问:什么是 Dubbo 服务治理?
服务与服务之间会有很多个 URL、依赖关系、负载均衡、容错、自动注册服务。
提问:Dubbo 有几种配置方式?
XML 配置
注解配置
属性配置
Java API 配置
提问:Dubbo 调用是同步的吗?
默认情况下,调用是同步的方式。
提问:Dubbo 可以对调用结果进行缓存吗?
Dubbo 通过 CacheFilter 过滤器,提供结果缓存的功能,且既可以适用于 Consumer 也可以适用于 Provider 。
通过结果缓存,用于加速热门数据的访问速度,Dubbo 提供声明式缓存, 以减少用户加缓存的工作量。
提问:Dubbo 目前提供三种实现:
IRU :基于最近最少使用原则删除多余缓存,保持最热的数据被缓存。
ThreadLocal :当前线程缓存,比如一个页面渲染,用到很多 portal,每个 portal 都要去查用户信息,通过线程缓存,可以减少这种多余访问。
JCache :与 JSR107 集成,可以桥接各种缓存实现。
1、默认使用的是什么通信框架,还有别的选择吗?
答:默认也推荐使用 netty 框架,还有 mina。
2、服务调用是阻塞的吗?
答:默认是阻塞的,可以异步调用,没有返回值的可以这么做。
3、一般使用什么注册中心?还有别的选择吗?
答:推荐使用 zookeeper 注册中心,还有 Multicast注册中心, Redis注册中心, Simple注册中心.
ZooKeeper的节点是通过像树一样的结构来进行维护的,并且每一个节点通过路径来标示以及访问。除此之外,每一个节点还拥有自身的一些信息,包括:数据、数据长度、创建时间、修改时间等等。
4、默认使用什么序列化框架,你知道的还有哪些?
答:默认使用 Hessian 序列化,还有 Duddo、FastJson、Java 自带序列化。 hessian是一个采用二进制格式传输的服务框架,相对传统soap web service,更轻量,更快速。
Hessian原理与协议简析:
http的协议约定了数据传输的方式,hessian也无法改变太多:
- hessian中client与server的交互,基于http-post方式。
- hessian将辅助信息,封装在http header中,比如“授权token”等,我们可以基于http-header来封装关于“安全校验”“meta数据”等。hessian提供了简单的”校验”机制。
- 对于hessian的交互核心数据,比如“调用的方法”和参数列表信息,将通过post请求的body体直接发送,格式为字节流。
- 对于hessian的server端响应数据,将在response中通过字节流的方式直接输出。
hessian的协议本身并不复杂,在此不再赘言;所谓协议(protocol)就是约束数据的格式,client按照协议将请求信息序列化成字节序列发送给server端,server端根据协议,将数据反序列化成“对象”,然后执行指定的方法,并将方法的返回值再次按照协议序列化成字节流,响应给client,client按照协议将字节流反序列话成”对象”。
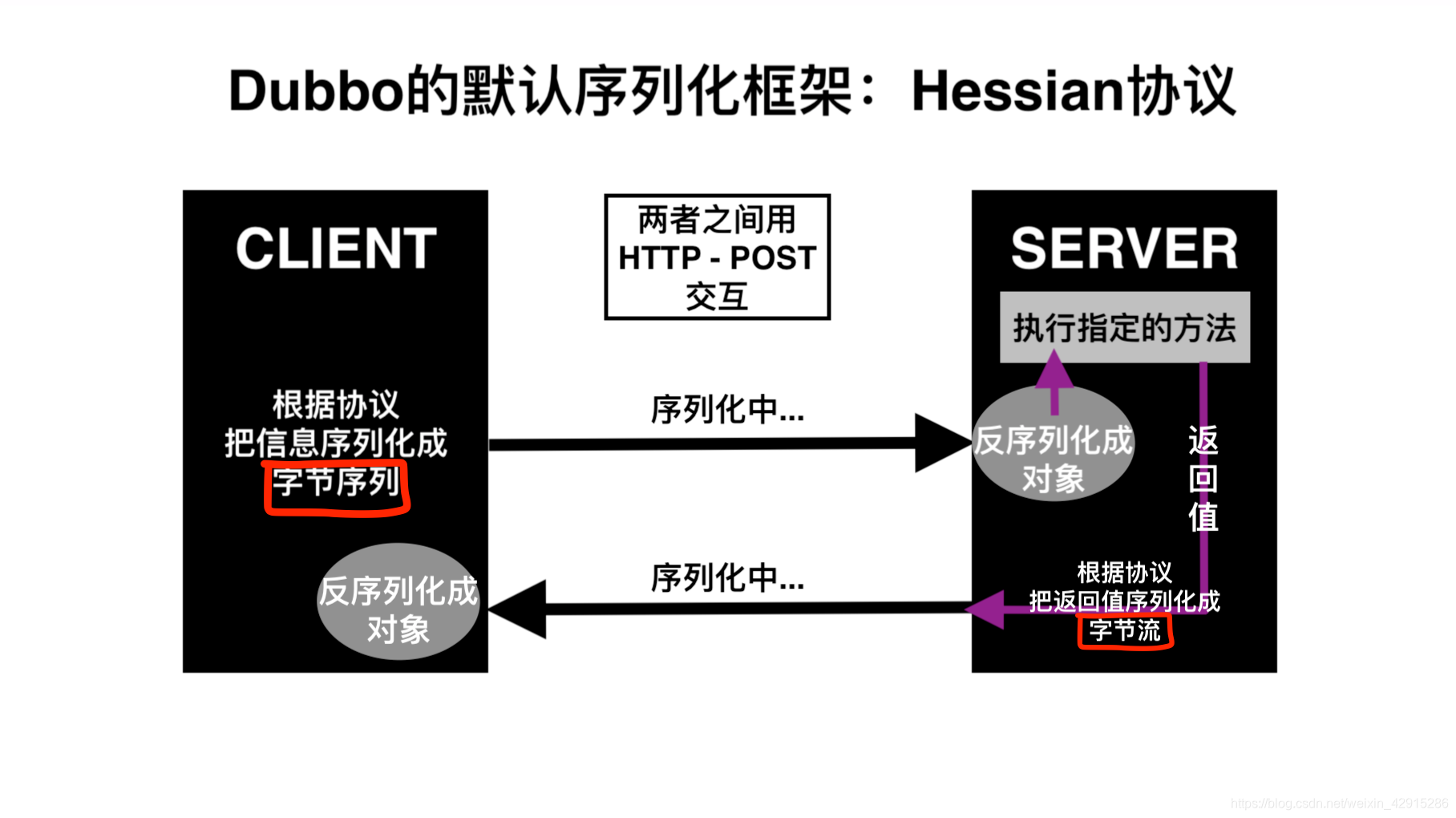
5、Provider能实现失效被踢出是什么原理?
答:服务失效踢出基于 zookeeper 的临时节点原理。
6、服务上线怎么不影响旧版本?
答:采用多版本开发,不影响旧版本。在配置中添加version来作为版本区分
7、如何解决服务调用链过长的问题?
答:可以结合zipkin 实现分布式服务追踪。
8、说说核心的配置有哪些?
核心配置有:
dubbo:service/dubbo:reference/dubbo:protocol/dubbo:registry/dubbo:application/dubbo:provider/dubbo:consumer/dubbo:method/
9.你还了解别的分布式框架吗?
答:别的还有 spring 的 spring cloud,facebook 的 thrift,twitter 的 finagle 等。
10.在使用过程中都遇到了些什么问题? 如何解决的?
-
同时配置了 XML 和 properties 文件,则 properties 中的配置无效
只有 XML 没有配置时,properties 才生效。 -
dubbo 缺省会在启动时检查依赖是否可用,不可用就抛出异常,阻止 spring 初始化完成,check 属性默认为 true。
测试时有些服务不关心或者出现了循环依赖,将 check 设置为 false -
为了方便开发测试,线下有一个所有服务可用的注册中心,这时如果有一个正在开发中的Provider注册,可能影响Consumer不能正常运行。
解决:让Provider只订阅服务,而不注册正在开发的服务,通过直连测试正在开发的服务。设置dubbo:registry标签的register属性为false。 -
spring 2.x 初始化死锁问题。
在 spring 解析到dubbo:service时,就已经向外暴露了服务,而 spring 还在接着初始化其他 bean;
如果这时有请求进来,并且服务的实现类里有调用applicationContext.getBean()的用法,getBean线程和 spring 初始化线程的锁的顺序不一样,导致了线程死锁,不能提供服务,启动不了。
解决:不要在服务的实现类中使用applicationContext.getBean();
如果不想依赖配置顺序,可以将dubbo:provider的delay属性设置为- 1,使 dubbo 在容器初始化完成后再暴露服务。 -
服务注册不上
检查 dubbo 的 jar 包有没有在 classpath 中,以及有没有重复的 jar 包;
检查暴露服务的 spring 配置有没有加载
在provider机器上测试与注册中心的网络是否通 -
出现
RpcException: No provider available for remote service异常;表示没有可用的Provider;
a. 检查连接的注册中心是否正确
b. 到注册中心查看相应的Provider是否存在
c. 检查Provider是否正常运行 -
出现” 消息发送失败” 异常
通常是接口方法的传入传出参数未实现Serializable接口。
11.Dubbo 集群的负载均衡有哪些策略
Dubbo 提供了常见的集群策略实现,并预扩展点予以自行实现。
Random LoadBalance: 随机选取提供者策略,有利于动态调整提供者权重。截面碰撞率高,调用次数越多,分布越均匀;
RoundRobin LoadBalance: 轮循选取提供者策略,平均分布,但是存在请求累积的问题;
LeastActive LoadBalance: 最少活跃调用策略,解决慢提供者接收更少的请求; ConstantHash LoadBalance: 一致性 Hash 策略,使相同参数请求总是发到同一提供者,一台机器宕机,可以基于虚拟节点,分摊至其他提供者,避免引起提供者的剧烈变动;
12.Dubbo 支持哪些通信协议?每种协议的应用场景,优缺点?
https://www.jianshu.com/p/0cbac7c13311
dubbo: 单一长连接和 NIO 异步通讯,适合大并发小数据量的服务调用,以及Consumer远大于Provider。
传输协议 TCP,异步,Hessian序列化;
默认就是走 dubbo 协议,单一长连接,进行的是 NIO 异步通信,基于 hessian 作为序列化协议。
使用的场景是:大并发小数据量(传输数据量小(每次请求在 100kb 以内),但是并发量很高)
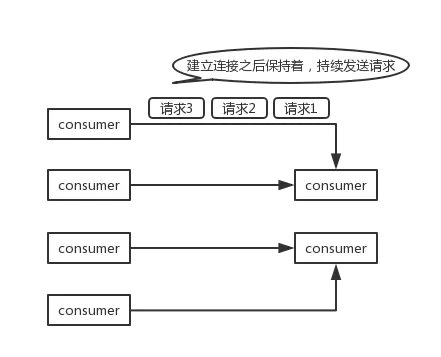
为了要支持高并发场景,一般是Provider就几台机器,但是Consumer有上百台,可能每天调用量达到上亿次!
此时用长连接是最合适的,就是跟每个Consumer维持一个长连接就可以,可能总共就 100 个连接。
然后后面直接基于长连接 NIO 异步通信,可以支撑高并发请求。
长连接,通俗点说,就是建立连接过后可以持续发送请求,无须再建立连接。
而短连接,每次要发送请求之前,需要先重新建立一次连接。
rmi: (少用)采用 JDK 标准的 rmi 协议实现,传输参数和返回参数对象需要实现 Serializable 接口,使用 java 标准序列化机制,使用阻塞式短连接,传输数据包大小混合,消费者和提供者个数差不多,可传文件,传输协议 TCP。 多个短连接,TCP 协议传输,同步传输,适用常规的远程服务调用和 rmi 互操作。在依赖低版本的 Common-Collections 包,java 序列化存在安全漏洞;
webservice:(少用)基于 WebService 的远程调用协议,集成 CXF 实现,提供和原生 WebService 的互操作。多个短连接,基于 HTTP 传输,同步传输,适用系统集成和跨语言调用;http: 基于 Http 表单提交的远程调用协议,使用 Spring 的 HttpInvoke 实现。多个短连接,传输协议 HTTP,传入参数大小混合,提供者个数多于消费者,需要给应用程序和浏览器 JS 调用; hessian: 集成 Hessian 服务,基于 HTTP 通讯,采用 Servlet 暴露服务,Dubbo 内嵌 Jetty 作为服务器时默认实现,提供与 Hession 服务互操作。多个短连接,同步 HTTP 传输,Hessian 序列化,传入参数较大,提供者大于消费者,提供者压力较大,可传文件;
memcache: 基于 memcached 实现的 RPC 协议 redis: 基于 redis 实现的 RPC 协议
附录:为什么 PB 的效率是最高的?
可能有一些同学比较习惯于 JSON or XML 数据存储格式,对于 Protocal Buffer 还比较陌生。
Protocal Buffer 其实是 Google 出品的一种轻量并且高效的结构化数据存储格式,性能比 JSON、XML 要高很多。
其实 PB 之所以性能如此好,主要得益于两个:
第一,它使用 proto 编译器,自动进行序列化和反序列化,速度非常快,应该比 XML 和 JSON 快上了 20~100 倍;
第二,它的数据压缩效果好,就是说它序列化后的数据量体积小。因为体积小,传输起来带宽和速度上会有优化。
提问:注册中心挂了还可以通信吗?
可以。
- 对于正在运行的 Consumer 调用 Provider 是不需要经过注册中心, 所以不受影响;
- 并且,Consumer 进程中,内存已经缓存了 Provider 列表;
- 那么,此时 Provider 如果下线呢?如果 Provider 是正常关闭,它会主动且 直接对和其处于连接中的 Consumer 们,发送一条“我要关闭”了的消息。那么, Consumer 们就不会调用该 Provider ,而调用其它的 Provider 。
- 另外,因为 Consumer 也会持久化 Provider 列表到本地文件。所以,此处 如果 Consumer 重启,依然能够通过本地缓存的文件,获得到 Provider 列表。
- 再另外,一般情况下,注册中心是一个集群,如果一个节点挂了,Dubbo Consumer 和 Provider 将自动切换到集群的另外一个节点上。
提问:Dubbo Provider 异步关闭时,如何从注册中心下线?
- 1 Zookeeper 注册中心的情况下
服务提供者,注册到 Zookeeper 上时,创建的是EPHEMERAL(adj.n. 只生存一天的事物 / 短暂的) 临时节点。 所以在服务提供者异常关闭时,等待 Zookeeper 会话超时,那么该临时节点就 会自动删除。(Provider能实现失效被踢出是什么原理?ephemeral) - 2 Redis 注册中心的情况下
使用 Redis 作为注册中心,是有点小众的选择,我们就不在本文详细说了。 感兴趣的胖友,可以看看 《精尽 Dubbo 源码分析 —— 注册中心(三)之 Redis》 一文。总的来说,实现上,还是蛮有趣的。因为,需要通知到消费者, 服务列表发生变化,所以就无法使用 Redis Key 自动过期。所以… 还是看文章 吧。哈哈哈哈。
提问:Dubbo Consumer 只能调用从注册中心获取的 Provider 么?
不是,Consumer 可以强制直连 Provider 。
在开发及测试环境下,经常需要绕过注册中心,只测试指定服务提供者,这时可能需要点对点直连,点对点直连将以服务接口为单位,忽略注册中心的提供者列表,A接口配置点对点,不影响 B 接口从注册中心获取列表。
提问:Dubbo 支持哪些通信协议?
https://www.cnblogs.com/yangzhilong/p/6121551.html
对应【protocol 远程调用层】。
Dubbo 目前支持如下 9 种通信协议:
- 1.
dubbo://【重要】,默认协议。参见 《Dubbo 用户指南 —— dubbo://》 。
Dubbo缺省协议采用单一长连接和NIO异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。 - 2.
rest://【重要】,贡献自 Dubbox ,目前最合适的 HTTP Restful API 协议。参见 《Dubbo 用户指南 —— rest://》 。 - 3.
rmi://,参见 《Dubbo 用户指南 —— rmi://》 。 - 4.
webservice://,参见 《Dubbo 用户指南 —— webservice://》 。 - 5.
hessian://,参见 《Dubbo 用户指南 —— hessian://》 。 - 6.
thrift://,参见 《Dubbo 用户指南 —— thrift://》 。 - 7.
memcached://,参见 《Dubbo 用户指南 —— memcached://》 。 - 8.
redis://,参见 《Dubbo 用户指南 —— redis://》 。 - 9.
http://,参见 《Dubbo 用户指南 —— http://》 。注意,这个和我们理解的HTTP 协议有差异,这里采用Spring的HttpInvoker实现。
提问:Dubbo 使用什么通信框架?
对应【transport 网络传输层】。
在通信框架的选择上,强大的技术社区有非常多的选择,如下列表:
Netty3Netty4MinaGrizzly
提问:Dubbo 支持哪些序列化方式?
对应【serialize 数据序列化层】。
Dubbo 目前支付如下 7 种序列化方式:
- 1.
Hessian2【重要】:基于 Hessian 实现的序列化拓展。dubbo://协议的默认序列化方案。 - 2.
Hessian【默认协议】除了提供 Web 服务,也提供了其序列化实现,因此 Dubbo 基于它实现了序列化拓展。
另外,Dubbo 维护了自己的 hessian-lite ,对 Hessian 2 的序列化部分的精简、改进、BugFix 。 - 3.
Dubbo:Dubbo 自己实现的序列化拓展。
具体可参见 《精尽 Dubbo 源码分析 —— 序列化(二)之 Dubbo 实现》;Kryo :基于Kryo实现的序列化拓展;
具体可参见 《Dubbo 用户指南 —— Kryo 序列化》 - 4.
FST:基于FST实现的序列化拓展。
具体可参见 《Dubbo 用户指南 —— FST 序列化》 - 5.
JSON:基于FastJson实现的序列化拓展。 - 6.
NativeJava:基于 Java 原生的序列化拓展。 - 7.
CompactedJava:在 NativeJava 的基础上,实现了对 ClassDescriptor 的处理。
提问:Dubbo 服务如何监控和管理?
一旦使用 Dubbo 做了服务化后,必须必须必须要做服务治理;
也就是说, 要做服务的 管理与监控。
当然,还有服务的 降级和限流 。这块,放在下面的面试题详细解析。
Dubbo 管理平台 + 监控平台:
dubbo-monitor监控平台
基于 Dubbo 的【monitor 监控层】,实现相应的"监控数据的收集"到监控平台。dubbo-admin管理平台
基于注册中心,可以获取到服务相关的信息。
提问:Dubbo 服务如何做降级?
比如说服务 A 调用服务 B,结果服务 B 挂掉了。服务 A 再重试几次调用服务B,还是不行,那么直接降级,走一个备用的逻辑,给用户返回响应。
在 Dubbo 中,实现服务降级的功能,一共有两大种方式。
- 1.Dubbo 自带的服务降级功能
当然,这个功能,并不能实现 “ 现代微服务 的 熔断器 功能 ” ;
所以一般情况下,不推荐这种方式,而是采用第二种方式; - 2.引入支持服务降级的组件
目前开源社区常用的有两种组件支持服务降级的功能,分别是:
Alibaba Sentinel(推荐使用)
Netflix Hystrix
因为目前 Hystrix 已经停止维护,并且和 Dubbo 的集成度不是特别高,需要做二次开发;
所以推荐使用Sentinel。
提问:Dubbo 支持哪些注册中心?
ZooKeeper
Redis 参见 《用户指南 —— Redis 注册中心》 。
Multicast 注册中心,参见 《用户指南 —— Multicast 注册中心》 。
Simple 注册中心,参见 《用户指南 —— Simple 注册中心》 。
提问:Dubbo 需要 Web 容器吗?
这个问题,仔细回答,需要思考 Web 容器的定义。
然而实际上,真正想问的是,Dubbo 服务启动是否需要启动类似 Tomcat、Jetty 等服务器。
这个答案可以是,也可不是;
因为根据协议的不同,Provider 会启动不同的服务器:
在使用 dubbo://协议时,不用其他容器,因为 Provider 启动 Netty、Mina 等 NIO Server。
在使用rest://协议时,答案是是,Provider 启动 Tomcat、Jetty 等 HTTP 服 务器,或者也可以使用Netty 封装的 HTTP 服务器。
在使用hessian://协议时,答案是是,Provider 启动 Jetty、Tomcat 等 HTTP 服务器。
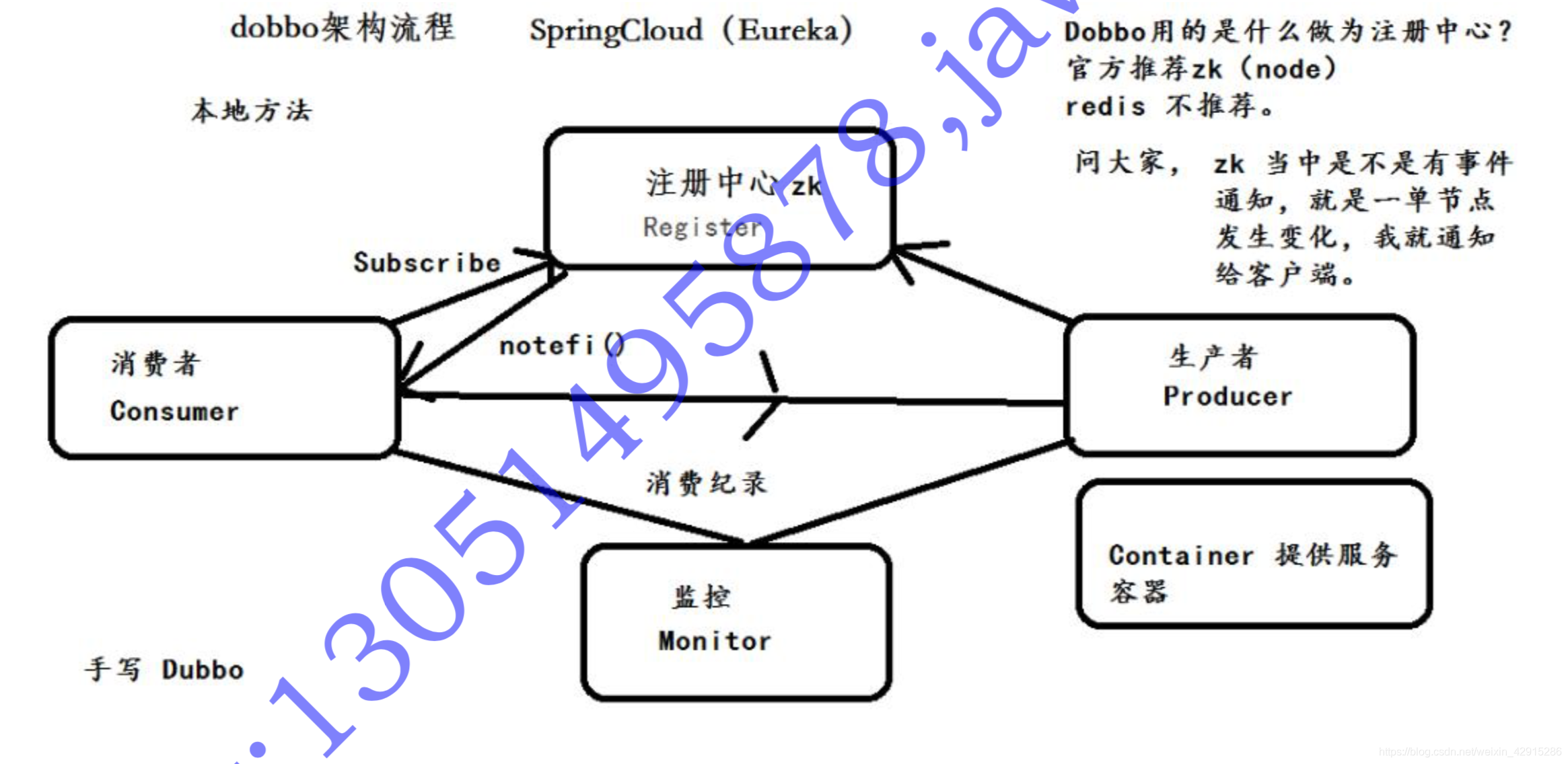
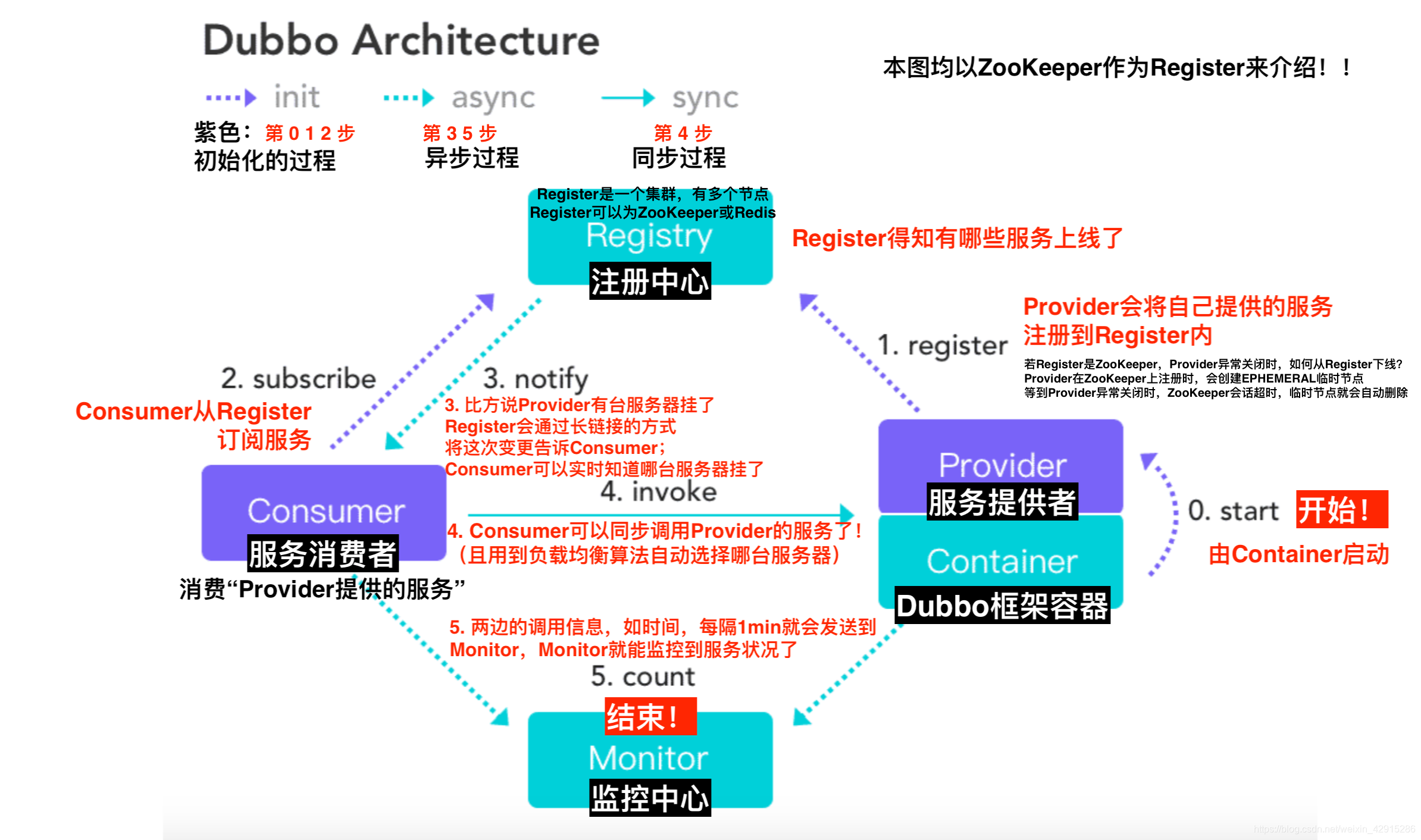
提问:Dubbo 整个架构流程
分为四大模块:
Provider / Consumer / Register / Monitor
生产者:提供服务
消费者: 调用服务
注册中心:注册信息(redis、zookeeper)
监控中心:调用次数、关系依赖等。 首先生产者将服务注册到注册中心(zookeeper),使用 zookeeper 持久节点进行存储,消
费订阅 zookeeper 节点,一旦有节点变更,zookeeper 通过事件通知传递给消费者,消费者可以调用生产者服务。
服务与服务之间进行调用,都会在监控中心中,存储一个记录。
提问:Dubbox 与 Dubbo 区别?
Dubox 使用 http 协议+rest风格传入 json 或者 xml 格式进行远程调用。
Dubbo 使用 Dubbo 协议。
提问:SpringCloud 与 Dubbo 区别? 相同点?
dubbo 与 springcloud 都可以实现 RPC 远程调用。
dubbo 与 springcloud 都可以使用分布式、微服务场景下。
区别:
dubbo 有比较强的背景,在国内有一定影响力。
dubbo 使用 zk 或 redis 作为作为注册中心 ;springcloud 使用 eureka 作为注册中心
dubbo 支持多种协议,默认使用 dubbo 协议。 Springcloud 只能支持 http 协议。
Springcloud 是一套完整的微服务解决方案。
Dubbo 曾经停止过更新,目前更新地断断续续;SpringCloud 更新速度快。
生产者和消费者是怎么交互的?
dubbo首先向zookeerper暴露端口,消费者向它们这边订阅服务通过zookeerper,消费者发送请求,zookeerper用来调度,调度的方式有三种,轮循,随机,把这些请求都拿给生产者,如果其中一个生产者挂掉,如果有新的生产者,会把请求分发给新的生产者。
你看过dubbo底层吗?
生产者跟消费者之间相当于长连接长请求,传统的request请求,response响应,请求一次,响应一次,开关一次,dubbo是基于 tcp/ip协议的,其他的源码闲的时候,基本上通过maven来看过没有刻意的去了解,因为平时这个业务开发状况很繁琐。
项目安全性怎么解决?
是指 攻击安全 还是 访问量过大安全 还是 数据安全 ?
如果是攻击性的话,input框都采用了js验证,用Java代替重复效验,避免输入不必要的空格或者sql注入。
如果是访问的安全的话,页面做了大量的页面静态化,缓存,通常访问量不会增加服务器造成负担。
如果是数据安全这一块的话,系统用的是linux,数据库的账号密码都做了加密处理。
如果是数据遗失或是自然灾害,数据库做了读写分离,而且一个主库,两个从库,其中一个从库做了备份,而且是定时备份。
在登录过程中,为了防止程序直接登录,也做了一些验证码,包括支付的资金账户安全,我们的系统没有钱,主要是通过超链接将钱存储到网络支付宝qq账号,最主要还是支付宝的安全和网民的安全,而且这个账号只能出不能进。
——————————————————————————
提问:ZooKeeper是什么?
是一个分布式、开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。
他是一个为分布式应用提供一执行服务的软件,【功能】有:
配置维护;
域名服务;
分布式同步;
组服务,等;
ZooKeeper的目标就是封装好复杂易出错的关键服务,把简单易用的接口性能搞笑、功能稳定的系统提供给用户;
提问:ZooKeeper的作用?
dubbo是把项目实现分离,分为消费端跟服务端,在消费者这边的配置文件中添上zookeeper地址,让它连上zookeeper,每个服务端都暴露一个端口给zookeeper,这样就实现服务端在zookeeper中注册,消费者发送请求给zookeeper,zookeeper接收请求,zookeeper再分发给这些服务端。
提问:ZooKeeper的部署模式?
单机部署:一台集群上运行;
集群部署:多台集群运行;
伪集群部署:一台集群启动多个ZooKeeper实例运行;
提问:ZooKeeper怎么保证主从节点状态同步?
它的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做zab协议,有两种模式:
恢复模式(选主);
广播模式(同步);
当服务启动或者在领导者崩溃后,zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和Leader的状态同步后,恢复模式就结束了。状态同步保证了Leader和Server具有相同的系统状态;
提问:集群中为什么有主节点?
分布式环境中,有些业务逻辑只需要集群中某一台机器进行执行,其他机器可以共享这个结果,这样可以大大减少重复计算,提高性能,所以需要主节点;
提问:集群中有3台服务器,其中一个节点宕机,此时ZooKeeper还可以使用吗?
可以;单数服务器主要没超过一半的服务器宕机就可以继续使用;
提问:ZooKeeper通知机制?
客户端会对某个znode建立一个watcher事件,当该znode发生变化时,这些客户端会收到ZooKeeper的通知,然后客户端可以根据znode变化来做出业务上的改变;
Dubbo
dubbo.apache.org/
前身:阿里巴巴的内部框架,2011年开始使用;2014年停止更新,但仍有大量企业使用;
2017年SpringCloud流行起来后,阿里巴巴重新开始更新Dubbo;
2018年阿里巴巴将其开源贡献给了Apache;
现在多为中小企业使用;
——————————————
Dubbo的特性? (了解即可)
- 1.面向接口的高性能RPC调用;
意思是若A调用B的方法,A只要把B方法的接口写进代码,Dubbo会自动寻找B的方法;
程序员无需关注远程调用底层细节;
又比如,远程调用MyBatis时,只需写入Mapper接口即可操作MyBatis,这是很舒服的方式; - 2.智能负载均衡;
之前学习Redis时,Redis有个功能就是负载均衡; - 3.服务自动注册与发现;(支持多种注册中心,服务实例上下线实时感知)
解释:分布式时,一个功能由多个服务器运行;
比如【用户业务】由1、2、3号服务器运行;【支付业务】由4、11、13号服务器运行;
这时,前端程序【订单web功能】想要调去支付业务,那他如何得知支付业务都在哪些服务器上?
同时,若支付业务的4、11、13好服务器有个突发故障,框架如何得知这件事?
(两个服务器之间是互相不知道地址的,他们如何联络到彼此?通过“注册发现”来找到彼此,比如B发送消息到Registry,说谁需要我?A到Register说:我需要B,于是A和B就可以避开Registry直接沟通了)
这时可以引入【注册中心】机制:
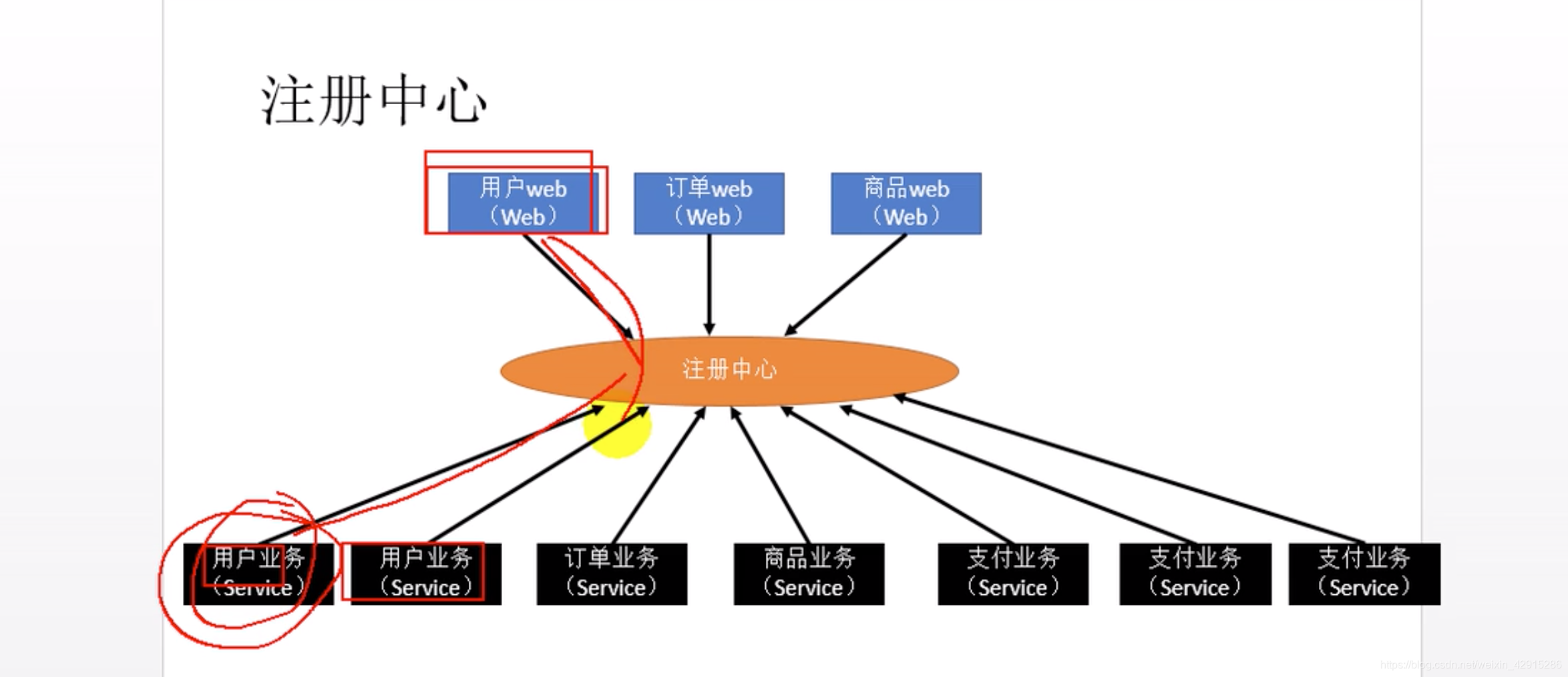
【注册中心】中:【支付业务】等所有业务可以登记入内,前端业务也都可以登记入内;
【注册中心】就像一个清单:
用户业务:服务器1、2、3;支付业务:服务器4、11、13;
若哪台服务器有了问题,注册中心就会把它删掉;
若此时,前端程序如【订单web功能】想要调用支付业务,他会先问【注册中心】,哪些服务器上有此功能;前端程序就会根据负载均衡机制选择合适的服务器,建起通讯,传递数据,进行远程调用;
(【注册中心】就像一个交友app,可以搜索个人信息,通过他可以要到对方的联系方式,建立联系)
注册中心 Registry 拓展!!
A通过Registry调用B服务器:不是说B随便给Registry发消息,或者A随便给Registry发消息,Registry就懂他们的想法的,这些消息需要有一个协议来遵循;那么Dubbo就是这个协议框架,有各种规范在内;
Dubbo会封装大部分代码,只开放一小部分给开发者填写,比如Dubbo需要知道开发的对象是谁?类型?名字等等,然后提供一个接口后,剩下的事情开发者就不用管了,dubbo为开发者包办大部分事情;
- 4.高度可扩展能力
- 5.运行时流量调度
轻松实现灰度发布;
https://blog.csdn.net/weixin_42915286/article/details/90459760 - 6.可视化的服务治理和运维
可视化界面让我们可以清楚了解到其中信息和调整参数;
【服务治理】的意思:比如当用到RPC架构,且未用到Dubbo时,A调用B服务,A又调C等等,最后开发者根本搞不清谁调用了谁,那么服务治理就能让开发者清晰明朗的看到谁调用了谁。
——————————————
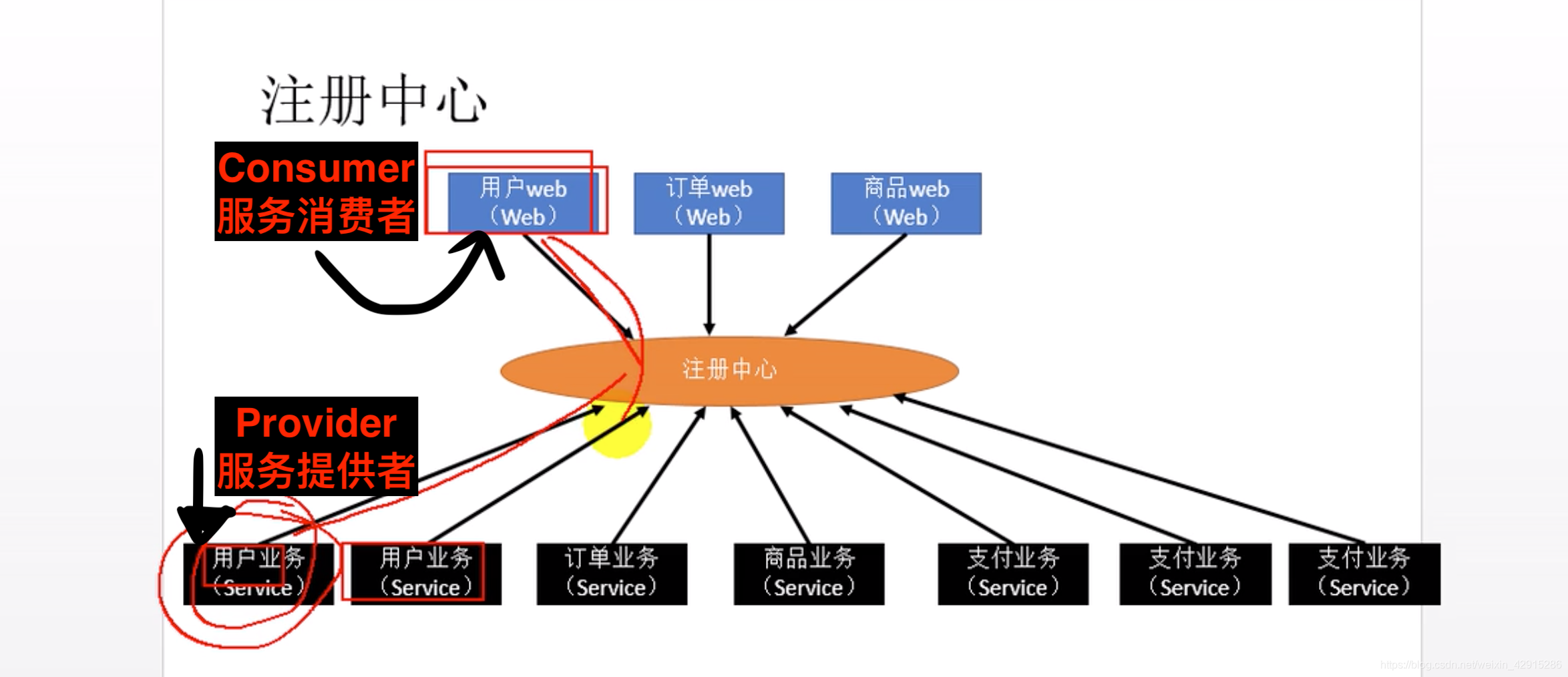
Dubbo的设计架构?
Provider相当于:用户业务
Consumer相当于:用户web(前端程序)
注意!!!
这张图中的Provider和Consumer之间的实际调用是不通过Register的!!!
意思是如果Register挂了,Provider和Consumer还是可以正常通信。
——————————————
服务最佳化实践
官方文档中建议将服务接口、服务模型、服务异常均放在API包中;
意思是:
比如Provider为user模块,Consumer为service模块;
Consumerservice想调用Providerruser中的方法时,就需要把Provideruser的接口和Entity都复制到Consumerservice模块中;
但是! 如果Consumer不止service一家,还有五六个模块呢?难道把user的接口和Entity都复制一遍吗?
Dubbo建议将服务接口、服务模型、服务异常均放在API包中;
那么我们就可以在总项目中新建一个项目名 - interface
内分:Entity文件夹、接口文件夹;
——————————————
——————————————
ZooKeeper (注册中心)
登录
ZooKeeper默认端口:2181
cd /usr/local/zookeeper-3.4.8/bin
./zkServer.sh start
返回:
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.8/bin/…/conf/zoo.cfg
Starting zookeeper … STARTED
./zkCli.sh -server 127.0.0.1:2181
前缀变成:[zk: 127.0.0.1:2181(CONNECTED) 0]
——————————————
4种注册中心的注册:
1.Multicast注册中心
2.ZooKeeper 注册中心
3.Redis注册中心
4.Simple注册中心
Dubbo介绍:
Zookeeper 是 Apacahe Hadoop 的子项目,是一个 树型的目录服务 ,支持变更推送,适合作为 Dubbo 服务的注册中心,工业强度较高,可用于生产环境,并推荐使用。
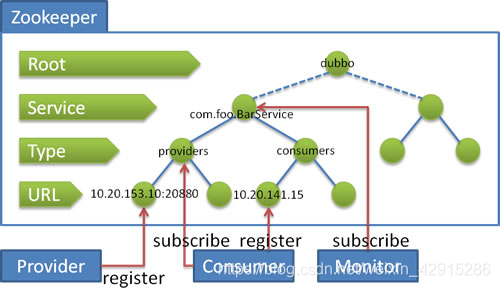
树型的目录服务 :如图
ZooKeeper跟节点下,我们可以根据目录的层级关系(由上到下)创建多个节点;
其中可以保存一些数据
Dubbo + ZooKeeper 项目演示
官方文档中的快速启动项目介绍:
http://dubbo.apache.org/zh-cn/docs/user/quick-start.html
————————————————————————
操作Register:ZooKeeper
-
1.启动ZooKeeper;
-
2.启动客户端
zkCli.sh查看一下:
cd /usr/local/zookeeper-3.4.8/bin
./zkCli.sh -timeout 5000 -server 127.0.0.1:2181
注解:
ZooKeeper默认端口:2181
-timeout:表示客户端向zk服务器发送心跳的时间间隔,单位为毫秒。
因为zk客户端与服务器的连接状态是通过心跳检测来维护的,如果在指定的时间间隔内,zk客户端没有向服务器发送心跳包,服务器则会断开与该客户端的连接。参数5000,表示zk客户端向服务器发送心跳的间隔为5秒。
-r:表示客户端以只读模式连接
-server:指定zk服务器的IP与端口,zk默认的客户端端口为2181 -
3.在ZK客户端
zkCli中新建临时节点:
因为ZK是树状结构,所以我们可以在他根节点下,按照目录层级关系创造出很多节点,节点内还可以保存数据;
zkCli.sh登录成功后返回:
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: 127.0.0.1:2181(CONNECTED) 0]
(1).查看根节点下的值:
[zk: 127.0.0.1:2181(CONNECTED) 0] get /
返回:
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
(2).继续查看根节点列表:
[zk: 127.0.0.1:2181(CONNECTED) 1]ls /
返回:
[zookeeper]
说明有一个节点,叫[zookeeper]
(3).创建一个临时节点,叫atguigu,值为123456
[zk: 127.0.0.1:2181(CONNECTED) 1]create -e /atguigu 123456
返回:
Created /atguigu
再查看下根节点 ls /
返回:两个根节点
[zookeeper, atguigu]
查看 临时节点atguigu
[zk: 127.0.0.1:2181(CONNECTED) 1]
返回:
123456
cZxid = 0x4
ctime = Mon Jun 03 17:10:20 CST 2019
mZxid = 0x4
mtime = Mon Jun 03 17:10:20 CST 2019
pZxid = 0x4
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x16ae37a3a100001
dataLength = 6
numChildren = 0
临时节点搭建成功;
————————————————————————
搭建和操作Monitor
其实Monitor安装与否不影响项目运行,它只是帮用户可视化管理任务;
————————————————————————
需求举例:
某个电商系统,订单需要调用用户服务获取某个用户的所有地址;
现在创建两个服务模块进行测试:
1.模块:订单的web - 功能:创建订单等;
2.模块:用户的service - 功能:查询用户地址等;
创建订单时要去用户的service查询用户地址;
且订单模块和用户模块都在不同服务器上进行RPC通信;
所以这样的话,
Provider:用户服务;Consumer:订单服务;(因为订单要用到用户的服务)
————————————
新建项目:
使用IntelliJ IDEA搭建Dubbo:创建一个maven空项目,作为项目的父工程;
使用模版:Maven archetype quick-start,项目叫做:dubbozkp
Dubbo on IDEA需要把Provider和Consumer作为在整个项目下的Module:
Module选择Maven(不需要archetype),如图:
两个Module:user-service-provider order-service-consumer
(新建Module时注意填写GroupId 和 ArtifactId,因为Module在POM中被当作依赖引入的时候要填写)
(新建Module时留意他们都必须包含POM!!!)

————————————
调用接口:
User是Provider,Order是Consumer;
那么在OrderServiceImpl中实现查询用户的收货地址功能,就需要用到User的方法;
Order如何调用User的方法?
不能直接把User的JAR包复制到Order!!
因为他们假设在不同的服务器中,若直接复制的话就不是分布式了,违背了RPC!!
user-service-provider order-service-consumer
我们可以把user-service-provider中接口UserService复制到order-service-consumer内;
(包括user-service-provider中的Entity也复制到order-service-consumer内)
可是,若Provider的Consumer不止一个,有多个,难道每个Consumer的模块中都复制一遍吗?不合理;
应该采用Dubbo官方建议的 服务最佳化实践 思想(页面搜索);
(1).在总项目中新建一个模块(与每个Provider或Consumer平级的模块),专门存放需要RPC的接口和实体类,他是公共享用的,比如取名叫:项目名 - interface
(2).然后其他的Provider和Consumer需要在各自的POM中添加项目名 - interface依赖
<dependencies>
<dependency>
<groupId>com.xxxx</groupId>
<artifactId>项目名-interface</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
————————————
1.把Provider提供到Register: ZooKeeper;(暴露服务)(此部分仅在Provider中配置)
2.Consumer去Register: ZooKeeper订阅Provider的服务地址;(此部分仅在Consumer中配置)
(Consumer到Register找Provider所在的机器是哪台,让C和P能远程沟通):
————————————
1.把Provider提供到Register: ZooKeeper;(暴露服务)(此部分仅在Provider中配置)
(暴露:指Provider需要暴露哪个方法给Consumer)
(1).POM中引入dubbo和ZooKeeper客户端:
【注意!】
Dubbo 2.6 及以后 对应的ZooKeeper客户端是:org.apache.curator curator-framework
Dubbo 2.6 以下 对应的ZooKeeper客户端是:org.101tec zkclient
当然此POM中还包括公共接口的依赖!!!
<!--Dubbo-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>dubbo</artifactId>
<version>2.6.2</version>
</dependency>
<!--ZooKeeper Client-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.12.0</version>
</dependency>
当然此POM中还包括公共接口的依赖!!!
(2).配置Provider.xml
在Provider的Resources下创建Provider.xml
其内容在官方文档的快速建立中有写:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<!-- 1.给当前Provider命名(不要和其他服务同名)dubbo:application name -->
<dubbo:application name="user-service-provider" />
<!-- 2.指定Registry的地址 dubbo:registry address 这样Provider一启动就能注册到Register-->
<!--http://dubbo.apache.org/zh-cn/docs/user/references/registry/zookeeper.html-->
<!--可参考官方文档 - ZooKeeper注册中心 单机配置默认2181端口 -->
<dubbo:registry address="zookeeper://127.0.0.1:2181" />
<!-- 3.Consumer用哪个端口和Provider通信?指定通信协议和端口【重要】(用dubbo协议在20880端口暴露服务) -->
<dubbo:protocol name="dubbo" port="20880" />
<!-- 4.声明需要暴露的服务接口 dubbo:service 即Provider要提供哪个方法给Consumer使用 -->
<!-- interface:要从公共接口中拿 和 ref:即impl 要从最初的模块中拿(不是从公共接口中拿)-->
<dubbo:service interface="com.chiu.Service.UserService" ref="userserviceimpl" />
<!--把ref拆成一个Bean变量-->
<bean id="userserviceimpl" class="Service.Impl.UserServiceImpl"></bean>
(3).Provider模块中新建启动类:
Provider.java:
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Provider {
public static void main(String[] args) throws Exception {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext(new String[] {"http://10.20.160.198/wiki/display/dubbo/provider.xml"});
context.start();
System.in.read(); // 按任意键退出
}
}
(4).运行启动类
Console中出现几行代码后就停止了,此时需要配合Dubbo Monitor查看;
刷新其首页,可见服务数1,应用数1,提供者1 等等;
至此,说明Provider配置完毕,他也被注册在了Register(因为Monitor可以查看到);
————————————
2.Consumer去Register: ZooKeeper订阅Provider的服务地址;(此部分仅在Consumer中配置)
Consumer的配置和Provider基本差不多;
(1).POM中引入dubbo和ZooKeeper客户端;(当然此POM中还包括公共接口的依赖)
(2).配置Consumer.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<!-- 1.本Consumer的名字(不要和Provider一样) -->
<dubbo:application name="order-service-consumer" />
<!-- 2.Consumer想使用的Register地址(当然要和Provider写的保持一致) -->
<dubbo:registry address="zookeeper://127.0.0.1:2181" />
<!-- 3.生成远程服务代理,生命需要调用的远程服务【接口】 -->
<!-- 之前Provider中暴露了接口UserService,那么Consumer就要调用此接口;且给他取名-->
<dubbo:reference id="userService" interface="com.chiu.Service.UserService" />
</beans>
此时的Consumer:OrderServiceImpl就可以使用userService了:
@Autowired即可;
记得还要在OrderServiceImpl上添加@Service;
————————————
————————————
————————————
————————————
————————————
————————————
————————————————————————
ZooKeeper安装和启动
ZooKeeper默认端口:2181
我的安装地址:/usr/local/zookeeper-3.4.8
启动zookeeper
到zookeeper bin 目录下 cd /usr/local/zookeeper-3.4.8/bin
执行./zkServer.sh start进行启动;
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.8/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED 或者 already running as process xxxxx
如此就等于启动成功;
————————————————————
Dubbo官方推荐使用ZooKeeper;
zookeeper.apache.org
下载:Older releases are available in the archive.
选一个稳定版本,如:zookeeper-3.4.8
https://archive.apache.org/dist/zookeeper/zookeeper-3.4.8/
下载zookeeper-3.4.8.tar.gz 到Mac目录
解压tar -zxvf (可以重命名命令:mv zookeeper-3.4.8 zookeeper)
$ tar -zxvf zookeeper-3.4.8.tar.gz (此行没有重命名)
把他移动到/usr/local 文件目录下,命令:
sudo mv zookeeper /usr/local (此行已经重命名为zookeeper)
配置环境变量
open ~/.bash_profile
添加:
ZOOKEEPER_HOME=/usr/local/zookeeper
PATH=$ZOOKEEPER_HOME/bin
export ZOOKEEPER_HOME
export PATH
记得重启环境变量:source ~/.bash_profile
复制配置文件,当作副本,改名为zoo.cfg:cp zoo_sample.cfg zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# dataDir=/tmp/zookeeper
dataDir=/usr/local/zookeeper-3.4.8/dataDir
dataLogDir=/usr/local/zookeeper-3.4.8/dataLogDir
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
因为刚刚的配置里添加了两个不存在的文件夹
所以在文件夹zookeeper中创建目录 dataDir和dataLogDir
mkdir dataDir
mkdir dataLogDir
若第一次安装出现报错,参考如下:
https://www.bilibili.com/video/av51438101/?p=6
Monitor 控制台 搭建和启动
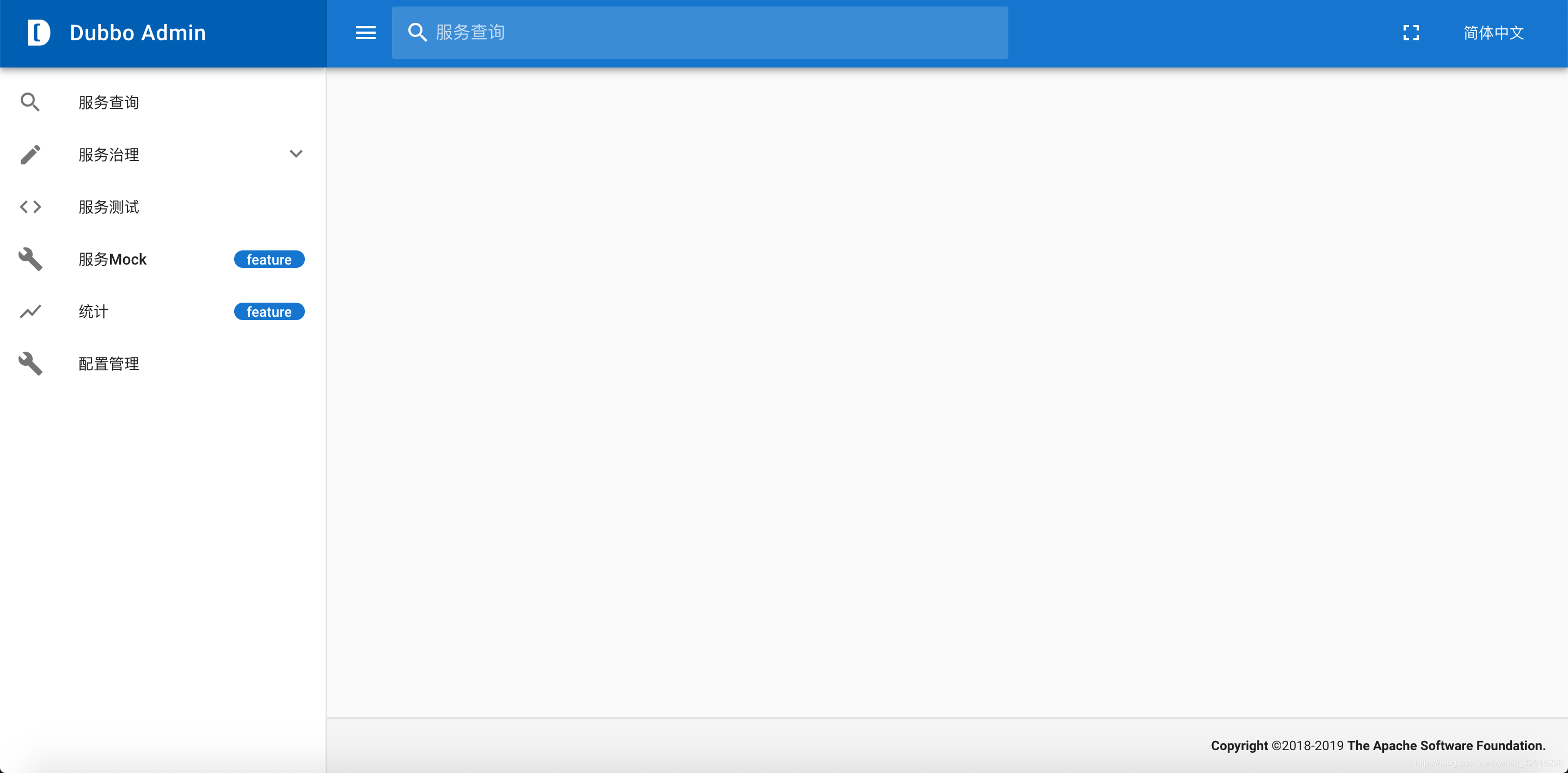
其实Monitor安装与否不影响项目运行,它只是帮用户可视化管理任务;
https://github.com/apache/dubbo-admin
下载项目
(1).首先确保此过程中,ZooKeeper要一直开启!!!否则控制台无法搭建好!!!
(2).保证application.properties(随便dubbo-admin-distribution或dubbo-admin-server文件夹)中地址是这样:
admin.registry.address=zookeeper://127.0.0.1:2181 (指向本地地址)
(3).把dubbo-admin-develop打包
dubbo-admin-develop xxxx$mvn clean package
直至返回:
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 04:07 min
[INFO] Finished at: 2019-06-04T01:34:03+08:00
[INFO] ------------------------------------------------------------------------
打好的包会保存在项目的target中:
(打开dubbo-admin-server文件夹中target文件夹,确保有dubbo-admin-server-0.1.jar)
(4).启动Spring Boot:
cd /Library/ZooKeeper\ Monitor/dubbo-admin-develop
dubbo-admin-develop xxxx$ mvn --projects dubbo-admin-server spring-boot:run
直至返回:
Tomcat started on port(s): 8080
说明控制台的地址为:localhost:8080
此时仍然要确保ZooKeeper一直是开启的!!!
(5).浏览器访问该地址,即见到截图那样的界面,表示搭建本地控制台成功;

















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









