







文章目录
一、计算机系统
1. 计算机系统的整体框架
一个经典的计算机系统,通常由五部分组成:运算器,存储器,控制器,输入设备,输出设备。如下图为更详尽的计算机的系统框架:

① 总线:总线用于各个部件间的信息的传递,总线被设计成传送定长的字节块(字,word)。字中的字节数(字长)是基本的系统参数。在32位计算机中,字长为4个字节,在64位计算机中,字长为8个字节。
② I/O设备:I/O设备是基本的输入输出,通过I/O总线与其他部件传递信息。
③ 主存储器:主存是计算机中数据的临时存储设备,由DRAM组成。从逻辑上来说,存储器是一个线性的字节数组,每一个字节都有其唯一的地址(索引)。
④ CPU: CPU的核心是一个大小为一个字的寄存器 — 程序计数器(PC),在任意时刻,PC都指向主存中的某条机器语言指令(其地址)。
下图是一个hello的程序,从磁盘读入内存,再到,程序运行,输出结果的数据流程:

2. 存储器
在存储器中, 不同层次的存储器其指令执行的效率有着很大的差别。存储器层次结构的中心思想是:对于每个k,位于k层的更快更小的存储设备作为位于k+1层更大更慢存储设备的缓存。存储器的层次结构如下图所示:

2.1 存储缓存 cache
缓存是上一级存储设备中经常被访问的数据的临时存储。
3. 程序编译原理
编译程序计算机系统的基本组成,编译程序的功能如下图所示,其目标是将一个高级语言程序转换为低级语言程序。
一个高级语言的程序不能被计算机直接运行,因为计算机只能对二进制数据进行计算,因此需要将高级语言程序通过编译器驱动程序转换为可执行目标程序。如一个hello.c的程序转换过程如下图所示:
① 预处理阶段:预处理器根据源文件.cpp,读取系统头文件中(#include<stdio.h>)的内容,并插入到程序文本中,得到一个.i为后缀的文件。{ .cpp -> .i }
② 编译阶段:编译器将预处理后的.i文件翻译成汇编语言程序。{ .i -> .s }
③ 汇编阶段:汇编器将汇编语言程序翻译成可重定位目标程序。{ .s -> .o }
④ 链接阶段:链接器将多个可重定位目标程序进行合并,生成最终的可执行文件。
3.1 程序预处理过程 (预处理器)
程序的预处理主要包括条件编译,源文件(.h)包含,宏替换,行控制,抛错,杂注和空指令。
① 条件编译:
条件编译的功能是根据条件有选择性的保留或放弃源文件中的内容 ,常见的条件编译包括#if,#ifdef,#ifndef开始,#endif结束。
#if defined(CREDIT)
credit();
#elif defined(DEBIT)
debit();
#else
printerror();
#endif
② 源文件包含
源文件包含是搜索指定的文件,并将它的内容包含到程序中,放在当前所在的位置。源文件包含两种:系统文件,用户自定义文件。
#include<stdio.h> //系统文件
#include"test.h" //用户自定义文件
③ 宏替换
宏的本质是替换,将文本中的标识符用对应的预处理记号进行替换。宏定义分为两种方式:无参数宏(对象宏定义)和有参数宏(函数式宏定义)
#define Max 1024
#define max(a,b,c) (a>b?(a>c?a:c):(b>c?b:c))
④ 行控制
行控制与“#”和“LINE”引导,后面是行号和可选的字面串,用于改变预定义宏__LINE__的值,如果后面的字面串存在,则改变__FILE__的值。
#include<stdio.h>
int main(){
printf("%d,%s",__LINE__,__FILE__);
#line 1 "Test"
printf("%d,%s",__LINE__,__FILE__); //此时行号和文件名被改变
}
⑤ 抛错
宏定义抛错指令以“#”和“error”引导的,抛错指令用于在预处理期间发出一个诊断信息,抛错是人为定义的动作。
#include<stdio.h>
#define max 100
int main(){
#ifndef max
#error "Nomax"
#endif
#ifdef max
#error "max"
#endif
}
3.2 程序编译过程 (编译器)
一个程序的编译是划分为不同的阶段进行的,各个阶段的操作在逻辑上市连接的一起的。编译过程分为6个阶段:词法分析,语法分析,语义分析,中间代码生成,代码优化和目标代码发生成。除此之外,编译程序还包括表格管理和出错处理两个工作。

💗 3.2.1 程序编译的6个阶段
① 词法分析
词法分析就是将编辑好的程序,从左到右一个字符一个字符的读入源程序中,对过程源程序的字符流进行扫描和分解,从而识别出程序中的一个个单词(这里的单词是指逻辑上紧密相连的一组字符)
② 语法分析
语法分析是在词法分析的基础上将单词序列分解成各类语法短语,如程序,语句,表达式等。语法分析描述了程序结构的规则,通过语法分析确定整个输入串是否构成一个语法上正确的程序。如下为int a=b+10的语法树。

③ 语义分析
审查源程序有无语义错误,为代码生成阶段收集类型信息。如判断一个数组下标是否为正整数,int类型与string类型相加等。
④ 中间代码生成与代码优化
在语义分析后,编译程序将源程序变成一种内部表示形式,称为中间代码。中间代码是一种结构简单,含义明确的记号系统,记号系统的两个基本原则是:容易生成,容易将它翻译成目标代码。常见的中间代码为四元式 (运算符,运算对象1,运算对象2,结果)。 代码优化是将产生的中间代码进行变换和改造,使生成的目标代码更为高效。
⑤ 目标代码生成
将优化后的中间代码变换成特定机器上的绝对指令代码或可重定位的指令代码或汇编指令代码。目标代码生成是编译的最后阶段,它的工作与硬件系统结构和指令含义有关。
💗 3.2.2编译器的其他功能
编译器在对源程序进行编译的同时,会针对程序的内容执行不同的操作,如下图所示:

Q1. 关于“编译时分配内存”的说法 ?
在编译时,程序中能够明确空间大小的变量,会“进行内存分配”,如下图所示:

但是,编译其实只是一个扫描过程,进行词法语法检查,代码优化而已,编译程序越好,程序运行的时候越高效。编译时是不分配内存的,此时只是根据声明时的类型进行占位(在可执行目标文件ELF中,描述着编译时的占位情况),到以后程序执行时分配才会内存。只有当程序运行时,操作系统会创建进程,同时将可执行程序从硬盘中加载到内存中,此时才会真正的分配内存空间。
Q2. 编译器对默认成员函数的生成 ?
在编译器对类进行编译时,如果类是一个空类,则编译器会自动生成默认构造函数,析构函数,默认拷贝构造函数(浅拷贝),取址运算符,const取址运算符,赋值运算符。
3.3 程序链接 (链接器)
在预处理,编译,汇编阶段,程序与源程序以文件为单位一个个的转换为目标文件,再由链接器将目标文件组合成一个可执行文件或库。因此,链接的过程就是解决目标文件之间各种符号(变量,函数)相互引用(对其在内存中的具体地址的引用)的问题,链接的本质是符号的重定位。
在每个可重定位目标文件中都有一个符号表,包含了目标文件中定义和引用的符号,存在三种链接器符号:
在程序链接阶段通常分为两种链接方式:静态链接和动态链接。
静态链接与动态链接最大的区别就是链接的时机不同,静态链接是在形成可执行程序之前,而动态链接是在程序执行时进行的。
💗 3.3.1 链接的本质 - 符号重定位
链接的本质是对符号(函数,变量)的重定位。
● 静态链接的符号重定位如下图所示:在编译时将不明确的符号加入到 重定向表中,在链接时确定具体的符号地址。

● 在linux中,动态链接的符号重定位有两种方式:加载时符号重定位和地址无关代码。
① 加载时符号重定位与静态时符号重定位原理相同,唯一的区别是将链接时机放到了程序运行时(动态库被加载到内存中)。
加载时符号重定位存在两个问题:
Ⅰ.不能使动态库的指令代码被共享
Ⅱ.动态库加载到内存时,对动态库中的符号引用进行重定位需要花费较多的时间。
② 地址无关代码(PIC)
针对加载时符号重定位的问题,ELF引入地址无关代码方法。
=>1. 对于模块内符号的访问(static变量和函数):
static函数在动态库编译完成时,模块内的相对地址就已经确定了,且函数调用只用到相对地址,因此不需要进行重定位。对于访问数据,因为访问数据需要绝对地址,当动态库编译好之后,库中的数据段,代码段的相对位置就已经固定了,此时对任意一条指令来说,该指令的地址与数据段的距离都是固定的,那么,只要程序在运行时获取到当前指令的地址,就可以直接加上该固定的位移,从而得到所想要访问的数据的绝对地址。
=>2. 对于外部模块的符号的访问:
因为动态库运行时被加载到哪里是未知的,为了能使得代码段里对数据及函数的引用与具体地址无关,ELF 在动态库的数据段中加一个GOT(global offset table)表项, GOT表格中放的是数据全局符号的地址,该表项在动态库被加载后由动态加载器进行初始化,动态库内所有对数据全局符号的访问都到该表中来取出相应的地址。
💗 3.3.2 静态链接
Q1. 为什么要使用静态链接 ?
在程序中,每个源文件并不是相互独立的,而是存在相互依赖关系。但在编译过程中每个源文件(*.c)都是独立编译,生成一个*.o文件。这就需要静态链接,将产生目标文件进行链接,形成可执行的程序。

Q2. 静态链接的优缺点 ?
● 缺点:由于每个可执行程序对所有需要的目标文件建立副本,从而浪费空间。其次,静态链接的更新困难,当某个库函数更新后,就需要重新进行编译链接。
● 优点:在可执行程序中具备了执行程序的所有东西,执行速度快。
💗 3.2.2 动态链接
为了解决静态链接中的问题,提出了动态链接。动态链接将程序按模块拆分为独立的部分,在程序的运行时才链接在一起。
Q1. 动态链接的优缺点 ?
● 优点:动态链接的每个程序都依赖同一个库,不会建立副本。其次,动态链接的更新方便,更新时只需替换原来的目标文件,不需要将所有程序重新编译链接一遍。
● 缺点:由于动态链接是程序运行时链接,因此性能上低于静态链接。
3.4 ELF文件
ELF文件是一种对象文件格式,可以定义不同的对象文件中都放了什么东西。对象文件通常分为三种,不同的对象文件对应着不同ELF文件:
① 可重定位的对象文件(可重定位目标文件)
② 可执行的对象文件(可执行文件)
③ 可共享的对象文件
ELF文件提供两种不同的观察视角,从链接的角度来看,从执行的角度来看。如下图所示:

💗 3.4.1 可重定位ELF文件
可重定向ELF文件是经过编译器编译后,并通过汇编得到的ELF文件。其结构如下图所示:

💗 3.4.2 符号表
在源程序经过编译器后,会将程序中的标识符编译成符号,并保存到符号表中。
符号表是每个ELF文件中的一个重要部分,是编译器和解释器中的数据结构,它保存了程序实现或使用的所有变量和函数,并将程序源代码中的每个标识符和它声明或使用的信息绑定在一起。如果程序引用了一个自身代码未定义的符号,则称之为未定义的符号。符号表的基本属性如下图所示:

3.5 提高编译的效率
C++是基于“头文件-源文件”的编译方式的,每个源文件作为一个编译单元,每个编译单元都会产生一个可重定位目标文件(obj)。下面从三个角度来介绍如何提高编译效率:
① 代码角度:
● 在头文件中使用前置声明,而不是直接包含头文件。
第一个原则: 如果可以不包含头文件,那就不要包含,这时候前置声明可以解决问题,如果使用的仅仅是一个类的指针,没有使用这个类的具体对象(非指针),也没有访问到类的具体成员,那么前置声明就可以了,因为指针这一数据类型的大小是特定的,编译器可以获知.。
第二个原则: 尽量在CPP文件中包含头文件,而非在头文件中。
● 使用Pimpl模式:Pimpl模式可以将类的接口与实现得以完全分离,当对类进行修改时,只需要编译包含该类的cpp文件即可,无需全部编译。
● 删除冗余的头文件
② 编译资源角度:
● 并行编译
● 分布式编译
4. 程序局部性
良好的程序具有良好的局部性,倾向于引用邻近于其他最近引用过的数据项的数据项,或最近引用过的数据项本身,这种倾向性称为程序的局部性。
局部性包括时间局部性和空间局部性。
① 时间局部性:被引用过一次的内存位置在不远的将来再次被多次引用。
② 空间局部性:被引用过一次的内存位置,在不远将来会引用附件的一个内存位置。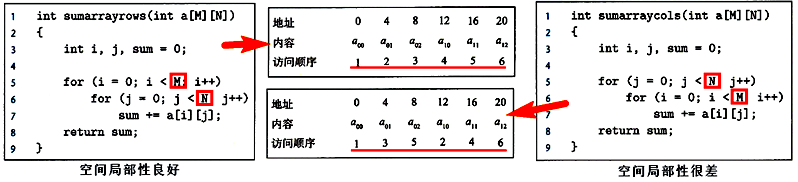
如何判断一个程序的局部性:
① 重复引用相同变量的程序有良好的时间局部性。
② 对具有步长为k的引用模式程序,步长越小,空间局部性越好。在内存中大步长跳来跳去的程序空间局部性很差。
③ 对于取指令,循环有良好的时间和空间局部性,循环体越小,循环迭代次数越多,局部性越好。
5. 程序的运行
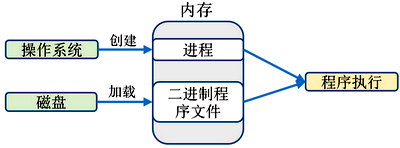
程序编译后会生成二进制可执行程序文件。当程序运行时首先要将可执行程序文件装入内存中,然后操作系统创建进程,读入程序,随后程序才会被执行。















 1791
1791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









