







一、Bitmaps
一、简介
计算机存储数据时,都是以二进制位表示,Redis提供了Bitmaps这个“数据类型”可以实现对位的操作。
(1)Bitmaps本身不是一种数据类型, 实际上它就是字符串(key-value) , 但是它可以对字符串的位进行操作。
(2)Bitmaps单独提供了一套命令, 所以在Redis中使用Bitmaps和使用字符串的方法不太相同。 可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量(是从零开始算的)。
二、命令
1、setbit
setbit<key><offset><value>设置Bitmaps中某个偏移量的值(0或1)
2、getbit
getbit<key><offset>获取Bitmaps中某个偏移量的值

二、HyperLogLog
一、简介
HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
二、命令
(1)pfadd <key>< element> [element ...] 添加指定元素到 HyperLogLog 中
(2)pfcount<key> [key ...] 计算HLL的近似基数,可以计算多个HLL,比如用HLL存储每天的UV,计算一周的UV可以使用7天的UV合并计算即可

三、Geospatial
一、简介
Redis 3.2 中增加了对GEO类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
二、命令
(1)geoadd<key>< longitude><latitude><member> [longitude latitude member...] 添加地理位置(经度,纬度,名称)

(2)geopos <key><member> [member...] 获得指定地区的坐标值

(3)geodist<key><member1><member2> [m|km|ft|mi ] 获取两个位置之间的直线距离,后面跟着的是单位。
m:米 、km:千米 、ft:英尺 、mi:英里
(4)geohash key member 用于获取一个或多个位置元素的geohash值

(5)georadius 以给定的经纬度为中心,返回建包含位置元素当中,与中心的距离不超过给定最大距离的所有位置元素。输入的是经纬度


(6)georadiusbymember:找出制定范围内的元素,中心点是由给定的位置元素决定的,输入的是中文

四、Stream类型
一、是什么
一、redis5.0之前的痛点
redis消息队列的两种方案
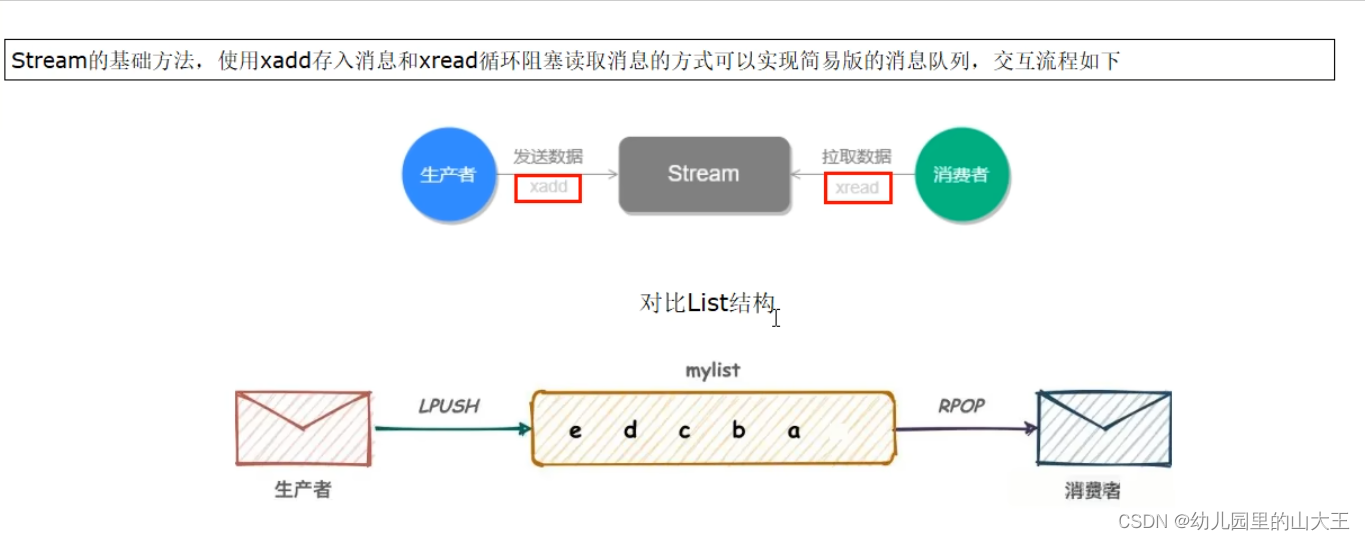
1、使用List实现消息队列
List实现方式其实就是点对点的模式。按照插入顺序排序,可以添加一个元素到列表的头部(左边)或者尾部(右边),所以常用来做异步队列来使用,将需要延后处理的任务结构体序列化成字符串塞进redis的列表,另一个线程从这个列表中轮训获取数据进行处理。

2、Pub/Sub
redis发布订阅有一个缺点就是消息无法持久化,如果出现网络断开、Redis宕机,消息就会全部丢失,而且也没有ack机制保证数据的可靠性,假设一个消费者都没有,那消息就直接被丢弃了。
二、 redis5.0之后新增了一个更强大的stream数据结构(redis版的消息中间件+阻塞队列)
二、能干嘛
实现消息队列,他支持消息的持久化、支持自动生成全局唯一id、支持ack确认消息的模式、支持消费者组模式等,让消息队列更加的稳定可靠
一、底层结构
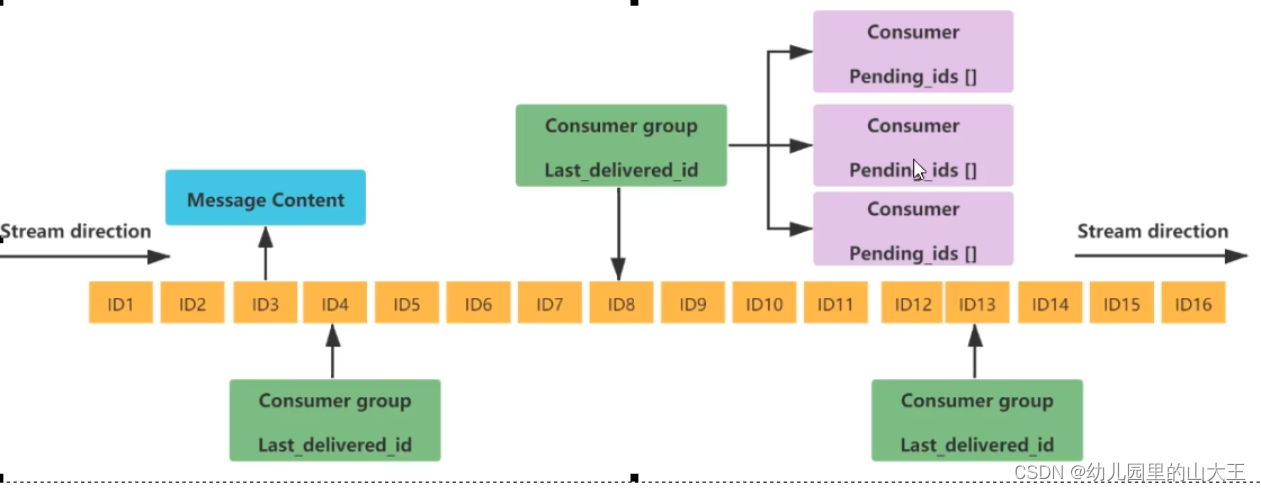

二、基础命令
1、队列相关命令

1、XADD:
前提:消息id必须必上一个id大,默认用星号表示自动生成规矩(*用于命令中让系统自动生成id,类似于mysql技术主键自动增长类型)

Stream的消息内容结构:类似于hash结构,是以key-value键值对的形式存在
2、XRANGE:用于获取消息列表(可以制定范围),忽略删除的消息
start:表示开始值;-:表示最小值(XRANGE stream名 start(-)end(+))
end:表示结束值;+:表示最大值
count:表示最多获取多少个值
3、XREVRANGE:反转
4、XDEL:删除消息内容,按照消息id进行删除;XDEL stream名 消息id
5、XLEN:用于获取Stream队列的长度
6、XTRIM:用于对Stream的长度进行截取。
MAXLEN:允许的最大长度,对流进行修剪限制长度
MINID:允许的最小id,从某个id开始比该id值小的将会被抛弃。
7、XREAD:
用于获取消息(阻塞/非阻塞),只返回大于指定ID的消息

非阻塞

阻塞

2、消费者相关命令
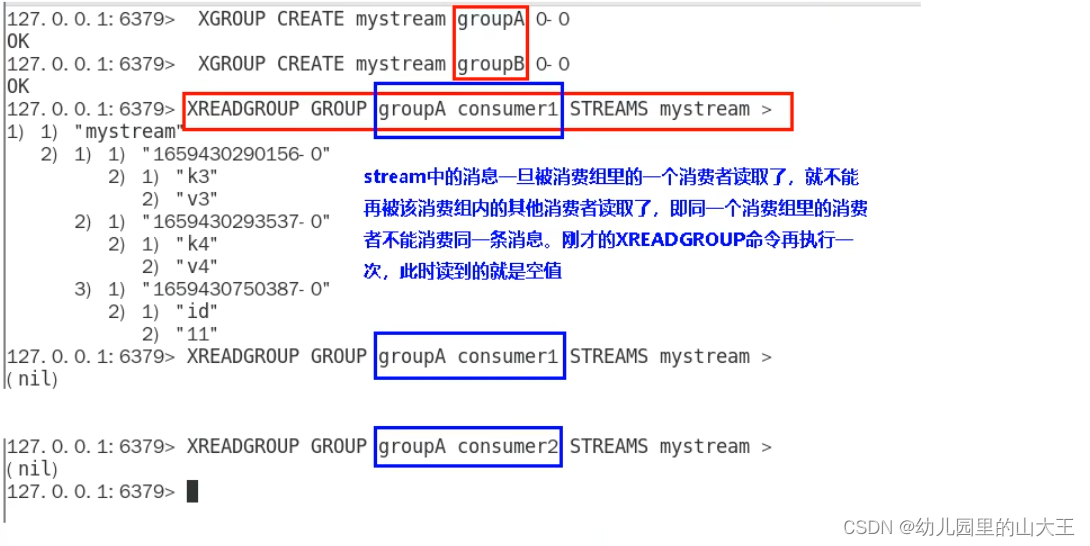
1、XGROUP CREATE :用于创建消费者组

2、XREADGROUP GROUP
1、“>”,表示从第一条尚未被消费的消息开始读取
2、消费者groupA内的消费者consumer1从mystream消息队列中读取所有消息
3、不同消费者组的消费者可以消费同一条消息
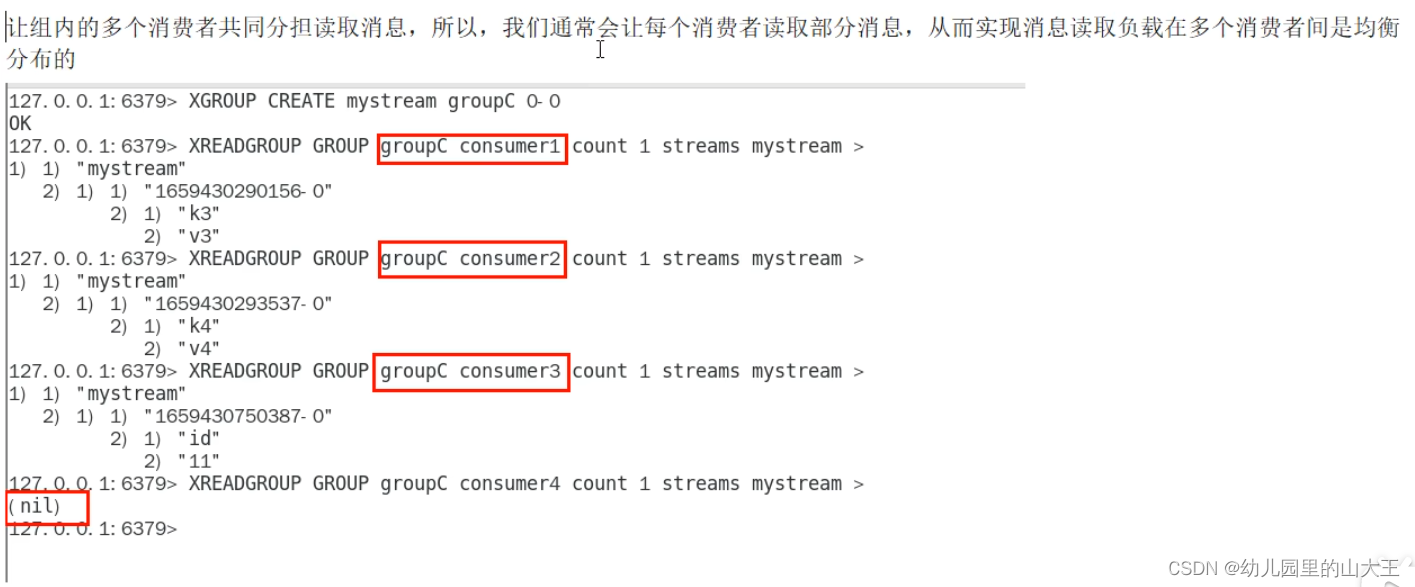
4、消费者组的目的
5、ack
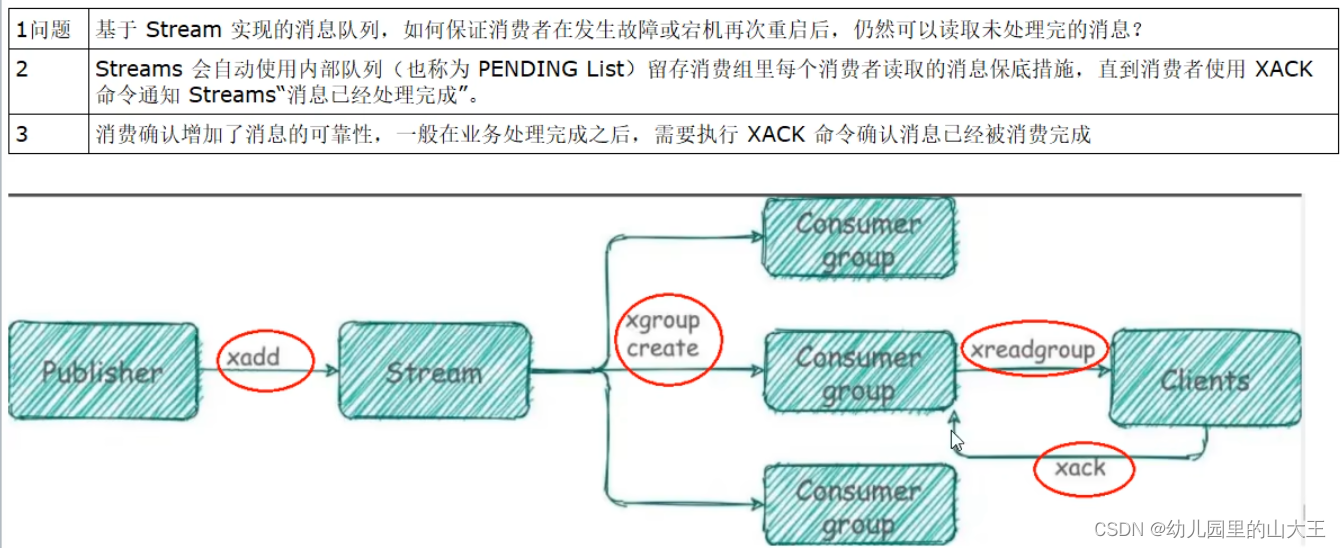
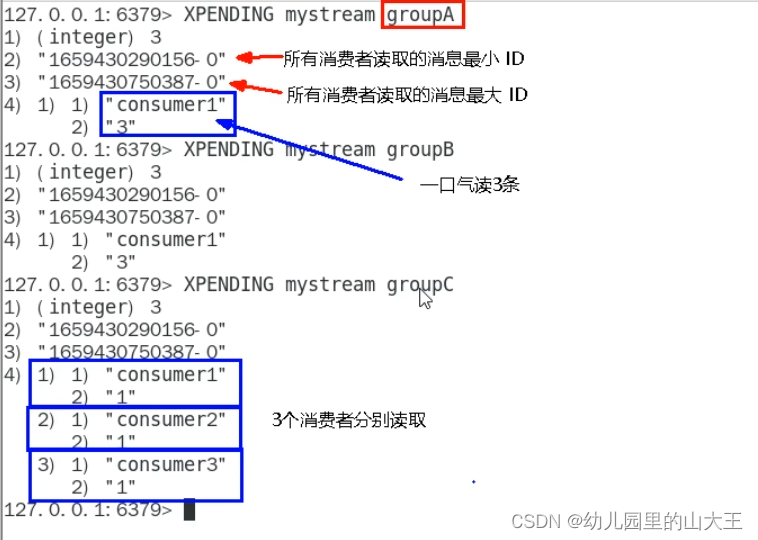
3、XPENDING
1、查询每个消费者组内所有消费者【已读,但尚未确认】的消息
2、查看某个消费者具体读了那些数据
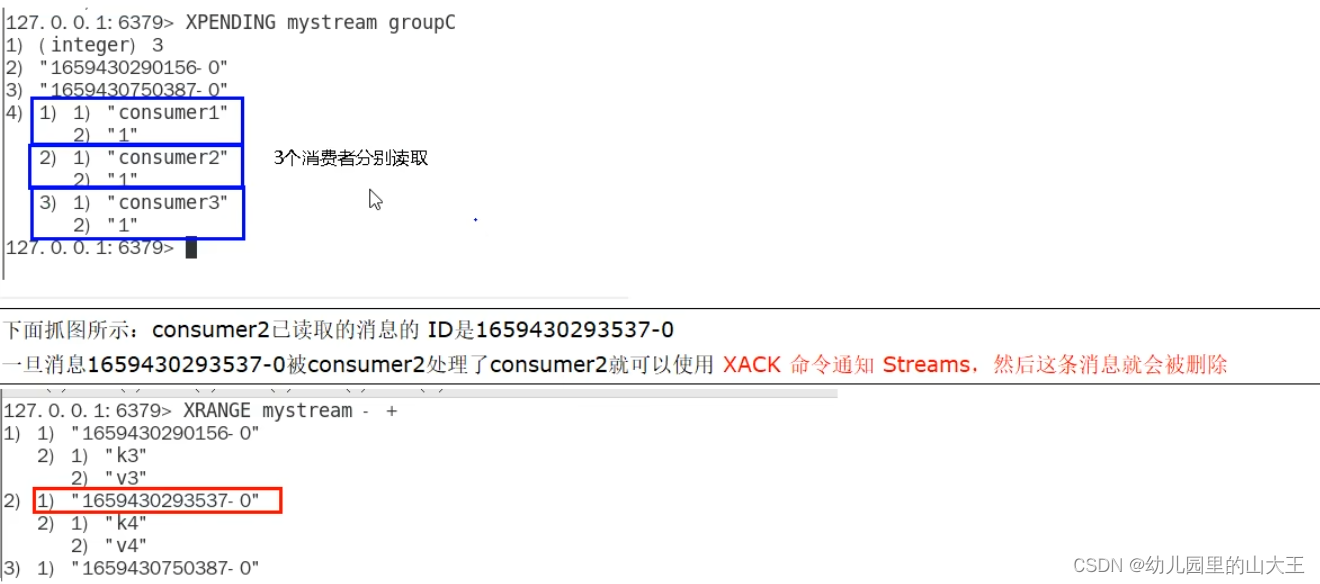
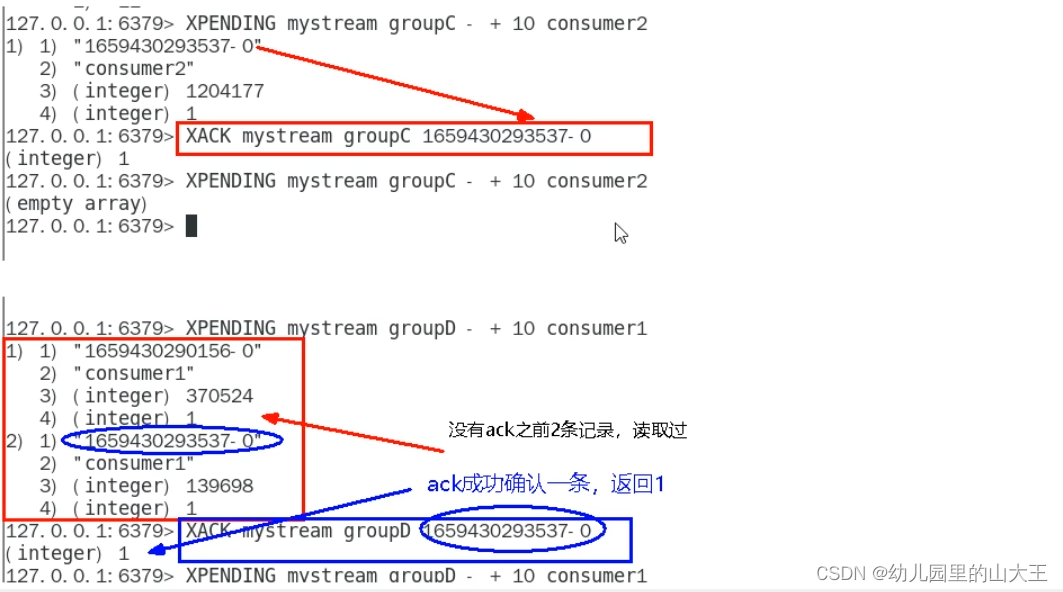
3、XACK:向消息队列确认消息处理已完成

4、XINFO:用于打印Stream\Consumer\Group
 3、四个特殊符号
3、四个特殊符号
1、-、+:最小、最大可能出现的id
2、$:表示只消费新的消息,当前流中最大的id,可用于将要到来的信息。
3、>:用于XREADGROUP命令,表示迄今为止还没有发送给组中使用者的,会更新消费者组的最后id
4、*:用于XADD命令,让系统自动生成消息id
五、bitField:位域
一、是什么

二、干什么
将一个redis字符串看做是一个有二进制位组成的数组,并能对变长位宽和任意没有字节对齐的指定整型位域进行寻址和修改。

栗子:
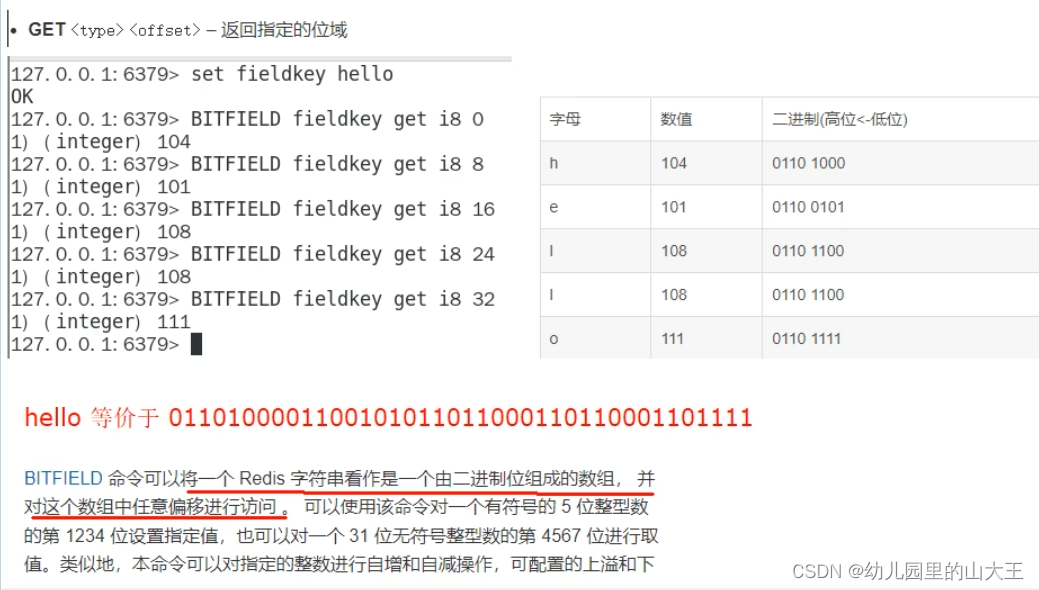
例如hello这个单词,会转化为ASCII码,拿到对应的二进制进行存储,如果需要改变其中的一个单词,只需要改变对应位上的数据即可(数据都是0或1),快捷直接且高效。
1、位域修改
也就是官网讲的,对数组中任意偏移进行访问
2、溢出控制

三、基础语法

一、 BITFIELD key [GET type offset]
二、 BITFIELD key [SET type offset value]

三、BITFIELD key [INCRBY type offset increment],默认情况下INCRBY使用参数为WRAP
 四、溢出控制OVERFLOW [WRAP|SAT|FAIL]
四、溢出控制OVERFLOW [WRAP|SAT|FAIL]
1、WRAP:使用回绕方法处理有符号整数和无符号整数溢出情况

2、SAT:使用饱和计算方法处理溢出,下溢计算的结果为最小的整数值,而上溢计算的结果为最大的整数值

3、FAIL:将拒绝执行那些会导致上溢或下溢情况出现的计算,并向用户返回空值,表示计算未执行。














 5052
5052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









