






 因工作需要分析好利来蛋糕品牌产品架构,作者编写爬虫脚本获取产品数据。思路是先确定官网数据展现形式,调用requests库请求,清理数据后保存到excel。操作包括查看官网页面、验证数据来源、查看ajax请求及参数等,最后展示运行效果和结果。
因工作需要分析好利来蛋糕品牌产品架构,作者编写爬虫脚本获取产品数据。思路是先确定官网数据展现形式,调用requests库请求,清理数据后保存到excel。操作包括查看官网页面、验证数据来源、查看ajax请求及参数等,最后展示运行效果和结果。
一、背景:
基于工作需要,需要了解好利来蛋糕品牌现有产品架构以作分析,所以写了个爬虫脚本获取他所有产品并汇总到excel做透视分析
二、思路:
1、找到好利来官网数据展现形式(相应的产品名称和价格等数据是随html来的还是通过ajax传过来的);
2、调用requests库请求;
3、做数据清理;
4、保存excel;
三、操作:
3-1、首先看下好利来官网的样子

他的所有产品在“全部产品”中,另外分成2类:蛋糕系列、零食糕点。由于我需要它产品层级分类,那么我需要分别爬取“蛋糕系列”和“零食糕点”系列。
3-2、看对应系列的数据构成,ctrl+i打开开发者工具,刷新界面
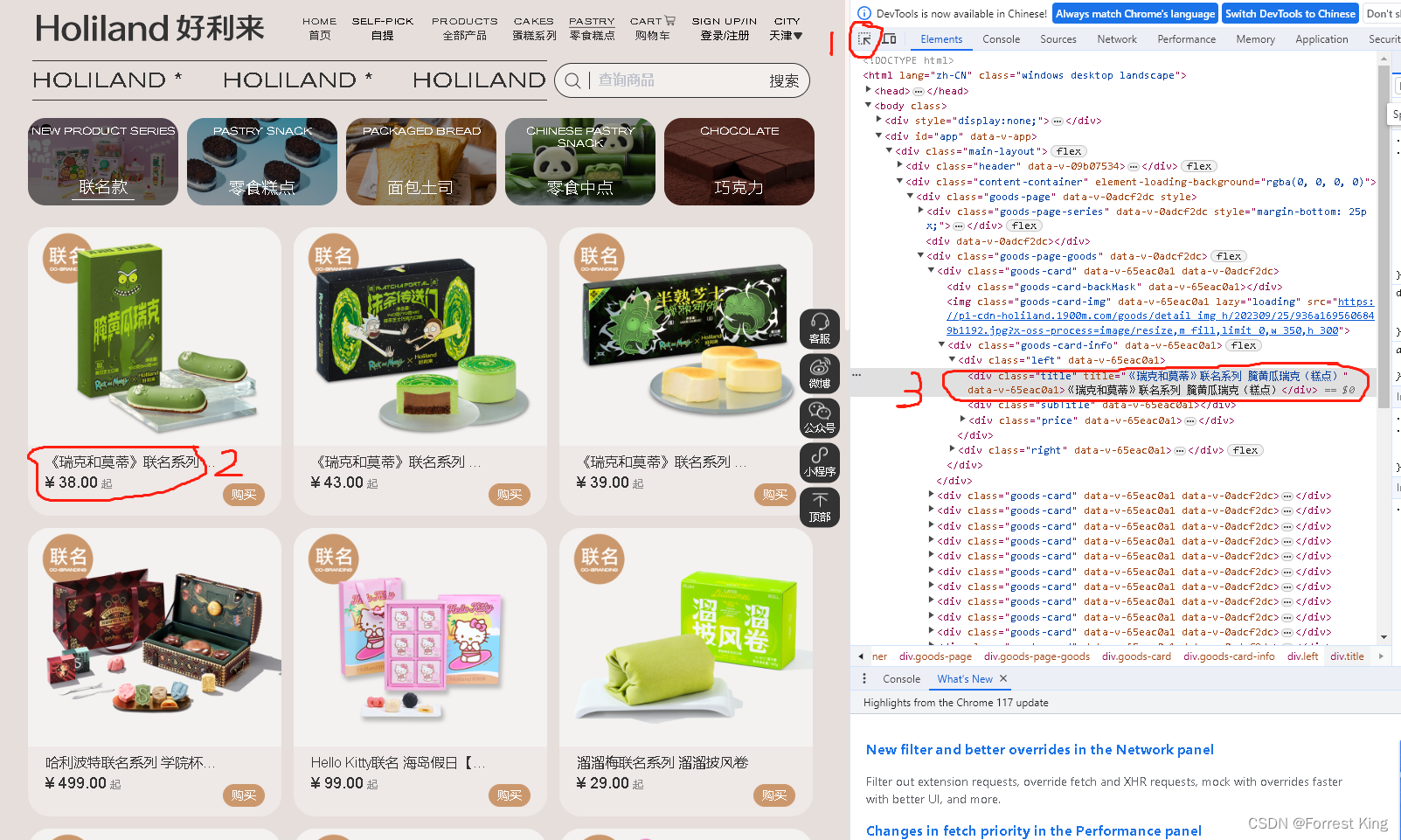
按照上图点击1、选择2,就会跳到3。
3-3、验证页面数据的来源:在页面上右键点击查看源码
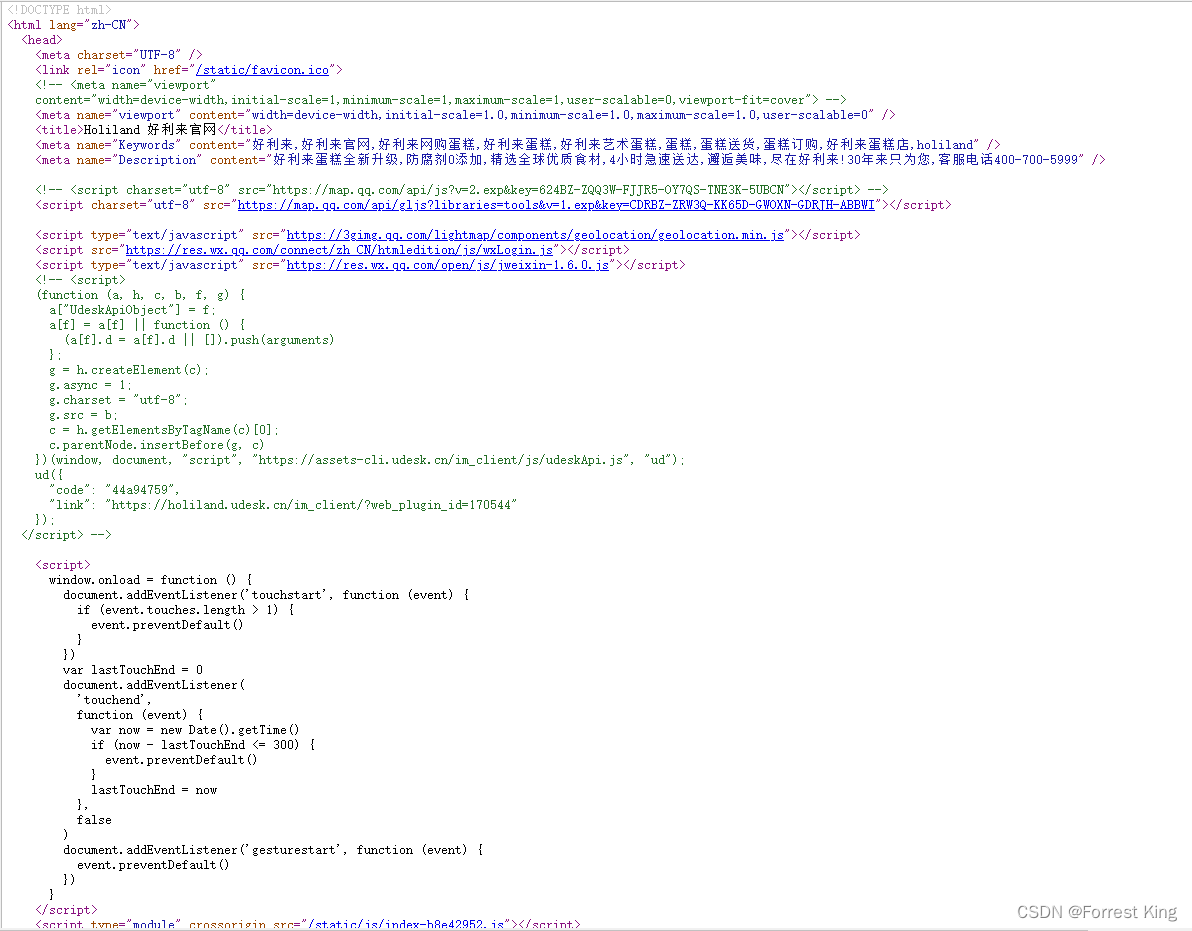
看得出来,页面的数据不同跟随html过来的,那有可能是ajax传递的json页面解析展现的。
3-4、查看后台交互的ajax请求:
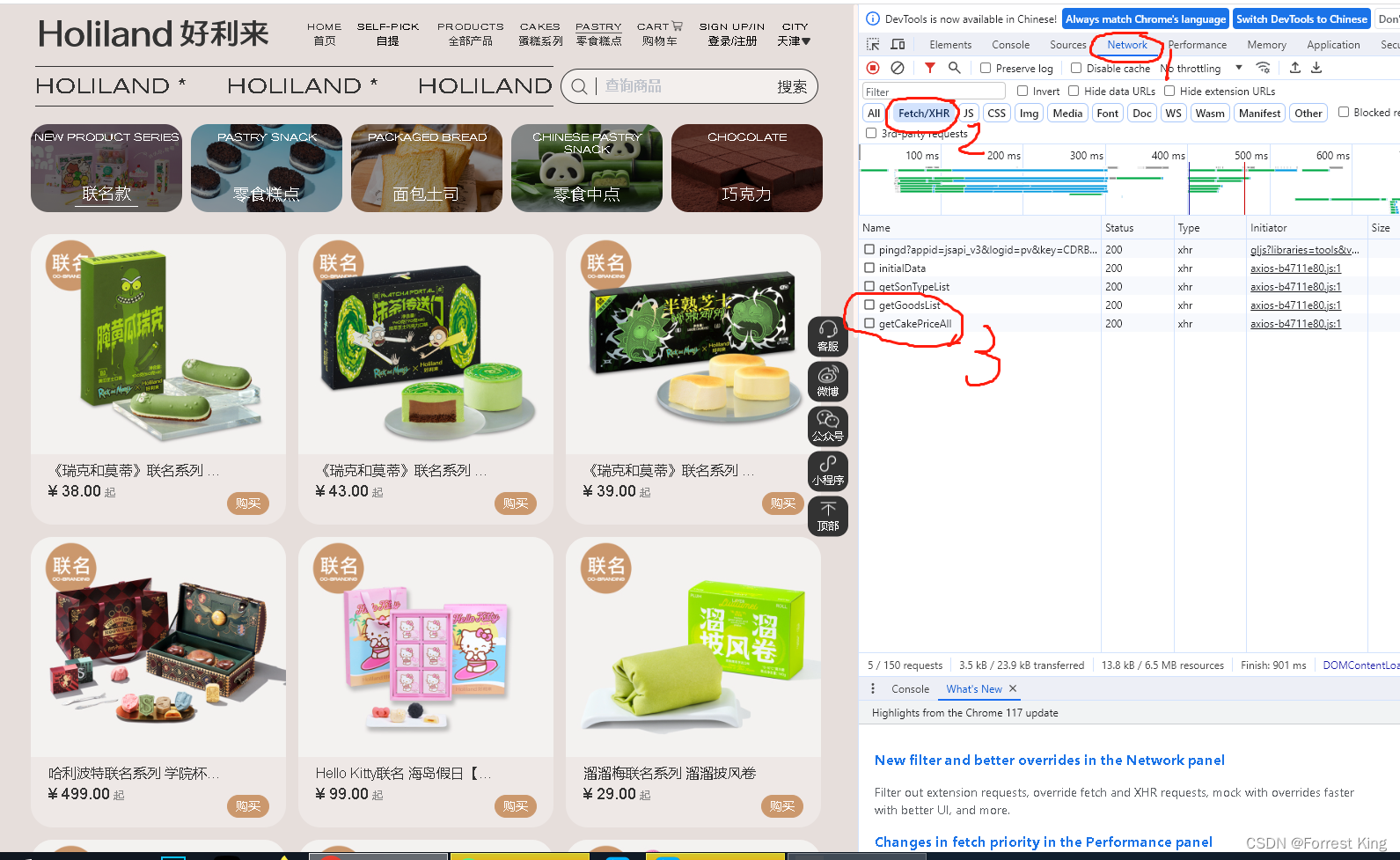
同样的点击1和2,就会出来3的结果,看下3的结果数据是啥?
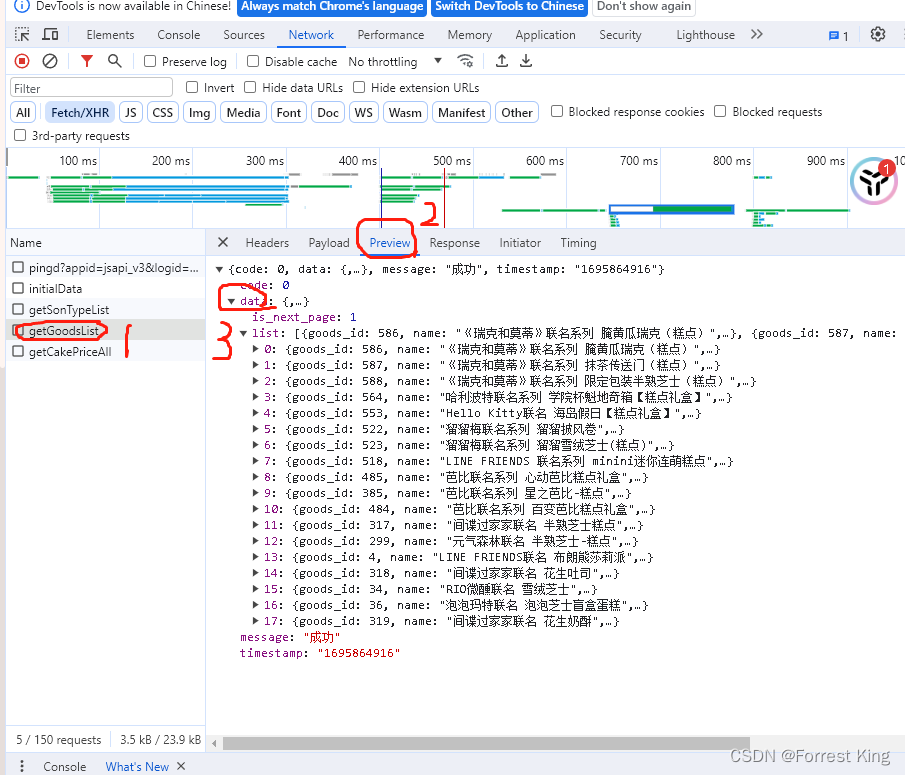
首先从名字上看,getGoodList小驼峰结构意思是获取产品,同时看数据就是我们要的。
3-5、ajax往往是post请求,那么需要关注传递的参数。
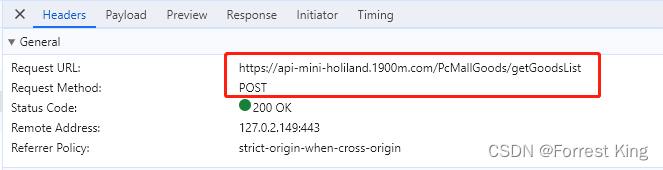
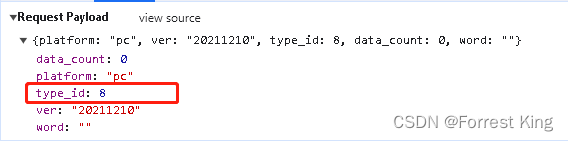
从headers中获取url,同时payload中获取post请求的数据,特别注意type_id:8,是不同细分类目的标志位。
四、上代码开撸
#该脚本用于爬取好利来官网产品信息并汇总到excel表
#author:Forrest King
#-导库
import requests
import json
from time import sleep
import openpyxl
#--创建一个表格的sheet对象用于装数据
wb=openpyxl.Workbook()
ws=wb['Sheet']
#--准备url和post请求的data数据
url='https://api-mini-holiland.1900m.com/PcMallGoods/getGoodsList'
#--经过尝试发现:唯一的变量是type_id,其中type_id为3-7是蛋糕系列,type_id为8-12是糕点系列。
#---需要构造对应的变量。
types=[{'id':3,'type':'联名款'},{'id':4,'type':'热销款'},{'id':5,'type':'经典系列'},{'id':6,'type':'儿童系列'},{'id':7,'type':'尊爱系列'},{'id':8,'type':'联名款'},{'id':9,'type':'零食糕点'},{'id':10,'type':'面包吐司'},{'id':11,'type':'零食中点'},{'id':12,'type':'巧克力'}]
#---循环取出变量并构造data
for typeId in types:
data={'platform': "pc", 'ver': "20211210", 'type_id': typeId['id'], 'data_count': 0, 'word': ""}
#----发出ajax请求并将返回的json转为dic以便清理
res_goods_json=requests.post(url=url,data=data).text
res_goods_dic=json.loads(res_goods_json)
#----遍历dic将需要的数据保存在excel中
for good in res_goods_dic['data']['list']:
data_list=[]
name=good['name']
price=good['price']
print('正在获取-%s-下的--%s--产品信息'%(typeId['type'],name))
data_list.append(typeId['type'])
data_list.append(name)
data_list.append(price)
ws.append(data_list)
wb.save('HLL_Allproducts.xlsx')
五、运行效果示意和结果展示
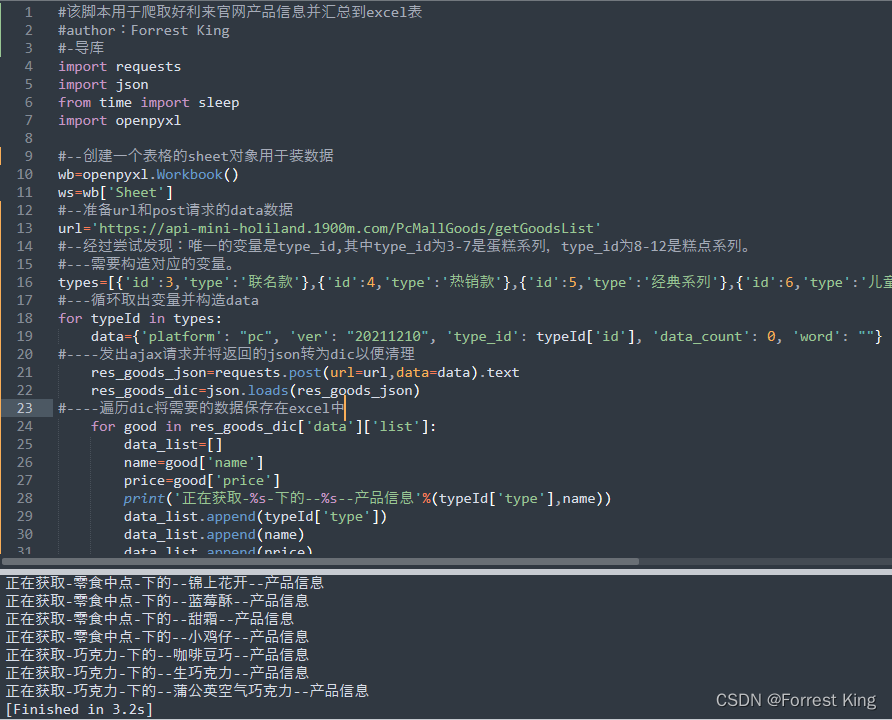
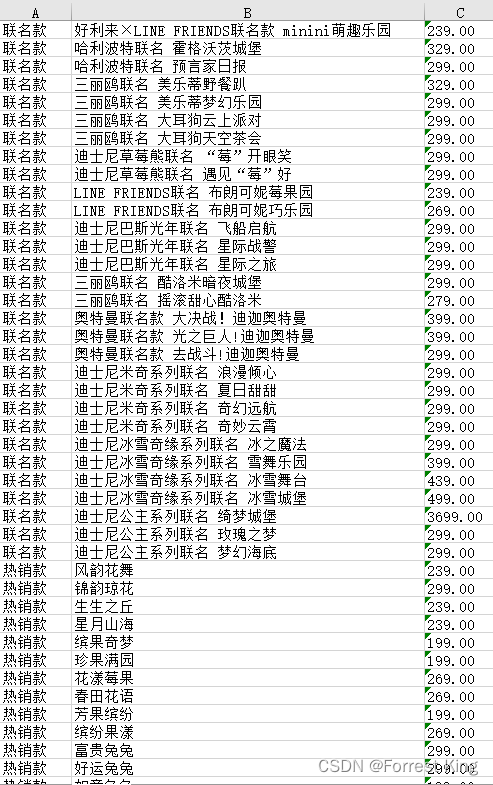


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









