







js的数据类型分为基本数据类型和引用数据类型,众所周知,基本数据类型是存在栈中的,引用数据类型是存在堆中的。
JS在浏览器中的运行内存
运行js代码需要内存的空间,是由浏览器自动向计算机申请分配的。
浏览器:计算机内存老兄,你给我块内存呗,我要运行我的js代码
计算机内存:好的,老弟,给你这块栈内存,它也叫ECStack执行环境栈
同时,为了区分是哪个区域(全局或函数)下的代码执行,会产生一个“执行上下文”,全局下执行的上下文叫做全局执行上下文即EC => EC(G) Execution Context(global)全局执行上下文。函数中形成是的私有上下文
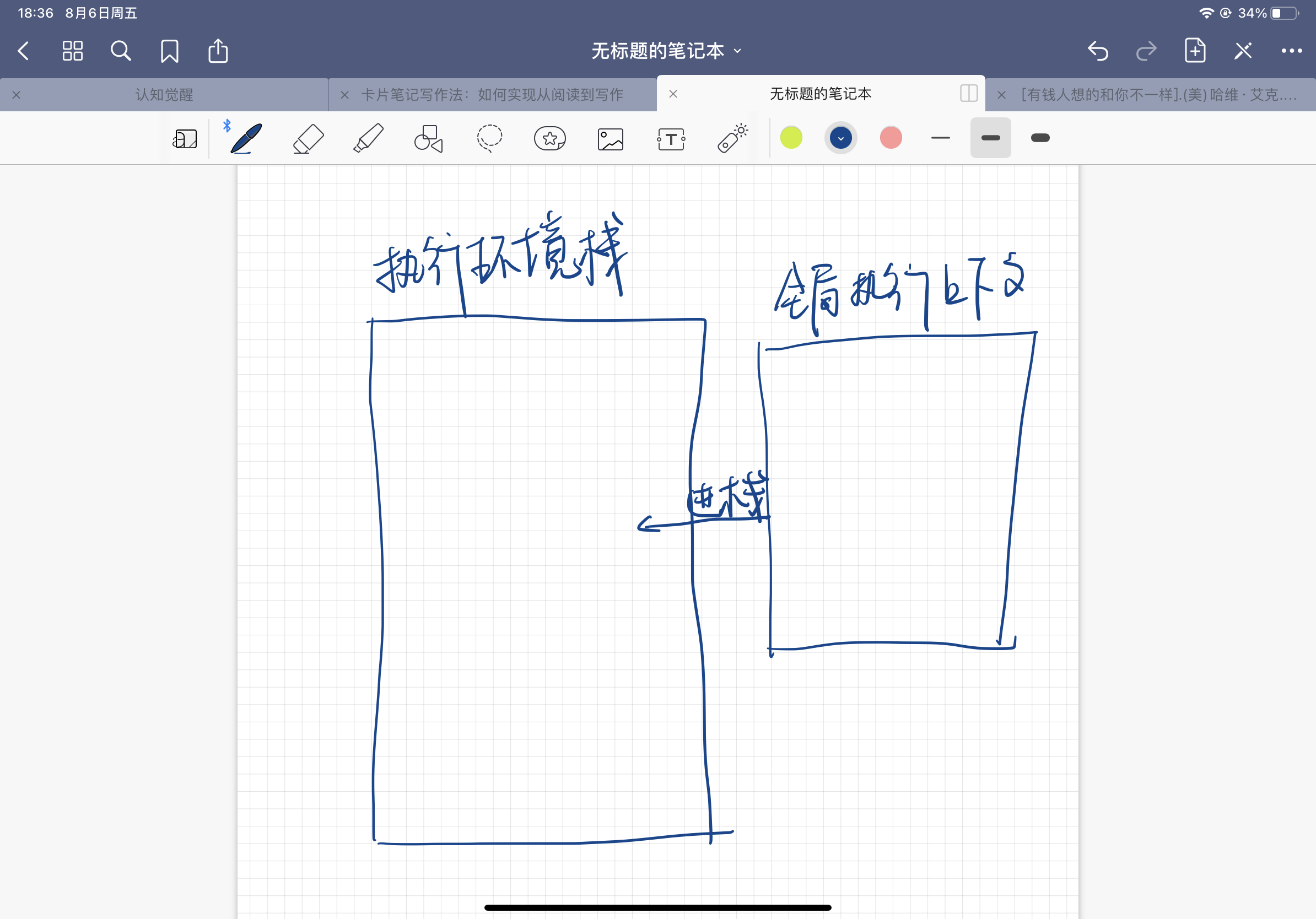
js的执行过程
- 创建存储当前上下文声明变量的全局变量对象
- 进栈
- 开始执行代码
- 第一步创建值
- 基本类型,直接存储再栈内存中
- 引用类型,开辟一个单独的内存空间,存储信息
- 声明变量,存放到当前上下文的变量对象中
- 让变量和值关联到一起,即赋值操作,叫做定义(defined)
- 第一步创建值
比如说var a =12,这个赋值过程是这样的
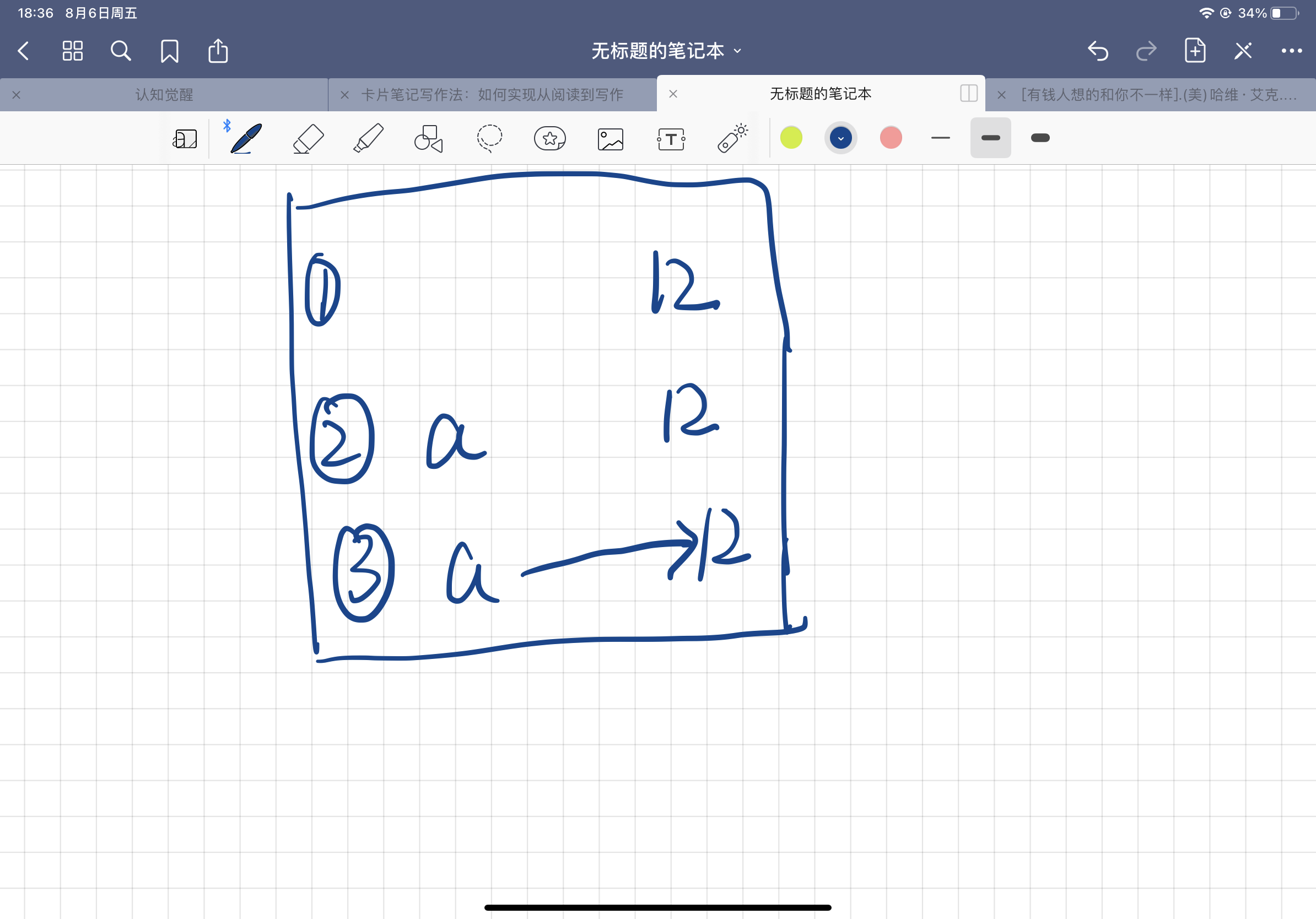
示例一:
创建引用类型时
- 在计算机内存中会分配一个单独的内存进行处理,即堆内存
- 这个堆内存是一个十六进制的地址
- 把对象中的键值对分别存储到堆内存中
- 把堆内存的地址放置到栈中,供变量使用
var a = {
n:12
}
var b = a
b['n'] = 13
console.log(a.n) // 13
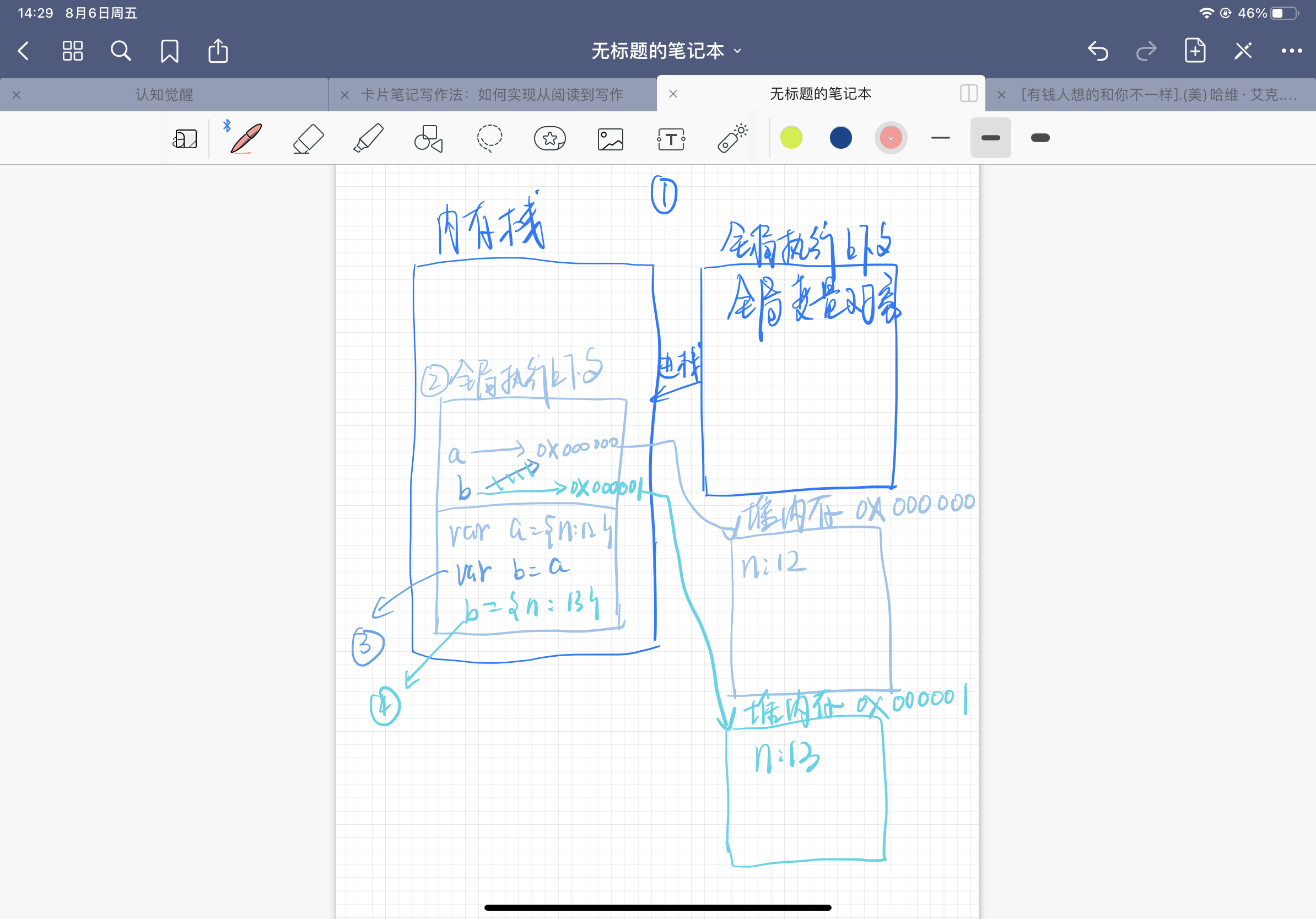
那么,这段代码的执行过程
- 在计算机中分配一个内存栈,并创建一个全局执行上下文,将这个执行上下文放入栈中
- 创建变量
var a = {n:12},分配一个堆内存存储0x000000存储n:12,并将变量a指向这个堆内存地址 a-> 0x000000 - 创建变量
var b= a; 所以变量b也指向0x000000这个堆内存的地址;b -> 0x000000 - 操作
b['n'] = 13, 成员访问 即改变堆内存0x000000地址中n的值,由12改成13
所以 console.log(a.n) // 13

示例二:
var a= {
n:12
}
var b = a;
b = {
n:13
}
console.log(a.n) // 12
此段代码的执行过程:
- 在计算机中分配一个内存栈,并创建一个全局执行上下文,将这个执行上下文放入栈中
- 执行代码
var a = {n:12}分配一个堆内存存储n:12,地址为:0x000000,a -> 0x000000 - 执行
var b = a; 将b和地址0x000000 关联在一起,b -> 0x000000 - 执行
b = {n:13};这是创建值,不是成员访问,开辟一个新的堆内存,地址为0x000001,存储n:13; 将变量b与地址0x000001 产生关联,b -> 0x000001 - 所以最后的值是 a = {n:12}; b ={n:13};执行代码:
console.log(a.n)输出12 - 流程图如下:
示例三:
var a = {n:1}
var b = a;
a.x = a = {n:2};
console.log(a.x)
console.log(b)
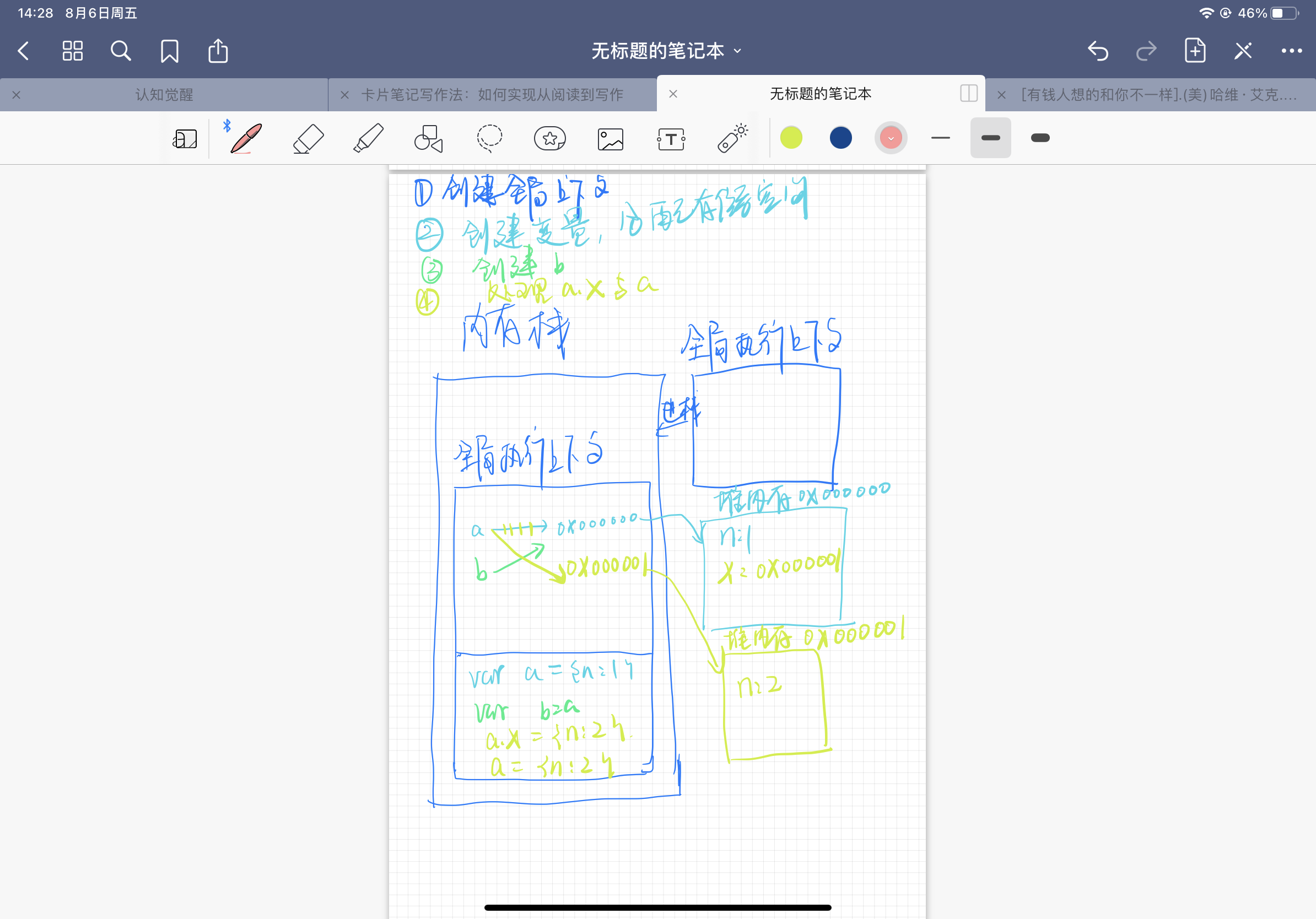
此段代码执行过程:
- 在计算机中分配一份内存栈,创建一个全局上下文,并将全局上下文放入栈中
- 执行代码:
var a = {n:1},创建堆内存地址为0x000000,内容为n:1,并且将变量a与地址0x000000关联到一起 a -> 0x00000 - 执行
var b = a;将变量b也关联到地址0x000000; b - > 0x000000 - 执行
a.x = a = {n:2};;因为a.x 的优先级高于a的优先级,所以先执行a.x={n:2};开辟新的堆内存,地址为0x000001,内容为n:2,将a.x于地址0x000001 关联到一起,a.x -> 0x000001;执行a = {n:2};变量a赋值成为n:2,所以将a与地址0x000000关联取消,重新指向地址0x000001 a - > 0x000001 - 所以最后 结果为:
a={n:2};
b= {n:1,
x:{n:2}
}
所以
var a = {n:1}
var b = a;
a.x = a = {n:2};
console.log(a.x) // undefined
console.log(b)
// {n:1,
// x:{n:2}
//}
函数的执行是如何处理的呢?
函数的执行步骤
- 形成一个私有的上下文,用于存储当前上下文中声明的变量,然后进栈
- 在代码执行之前,先做一些准备工作
- 初始化作用域链scopne-chain
- 初始化this
- 初始化arguments
- 形参赋值,在当前上下文中声明一个形参变量,并且吧传递的实参赋值给它
- 代码执行
- 出栈释放
在私有上下文中,如果遇到一个变量,首先看看是否是自己的私有变量,如果是私有变量,则操作自己的,与外界没有必然关系,如果不是自己的,则基于作用域链向其上下文中查找,如果也不是其上级上下文,则继续向上查找,直到找到EC全局上下文为止,我们把这个过程称之为作用域链查找机制
示例:
var x = [12,23]
function fn(y) {
y[0] = 100;
y = [100]
y[1] = 200
console.log(y)
}
fn(x)
console.log(x)
函数的执行过程
首先, 在计算机中开辟一个内存栈,并创建一个全局执行上下文,将全局上下文放入栈中
第一步:执行全局代码
- 执行
var x= [12,23];因为是个数组,所以同样是创建一个堆内存0x000000,将变量x和地址0x000000关联到一起,x -> 0x000000 - 创建函数fn,同样是开辟一个堆内存,地址为0x000001,内容为代码字符串y[0] = 100; y = [100];y[1] = 200;console.log(y),将fn与地址0x000001 关联到一起, fn -> 0x000001
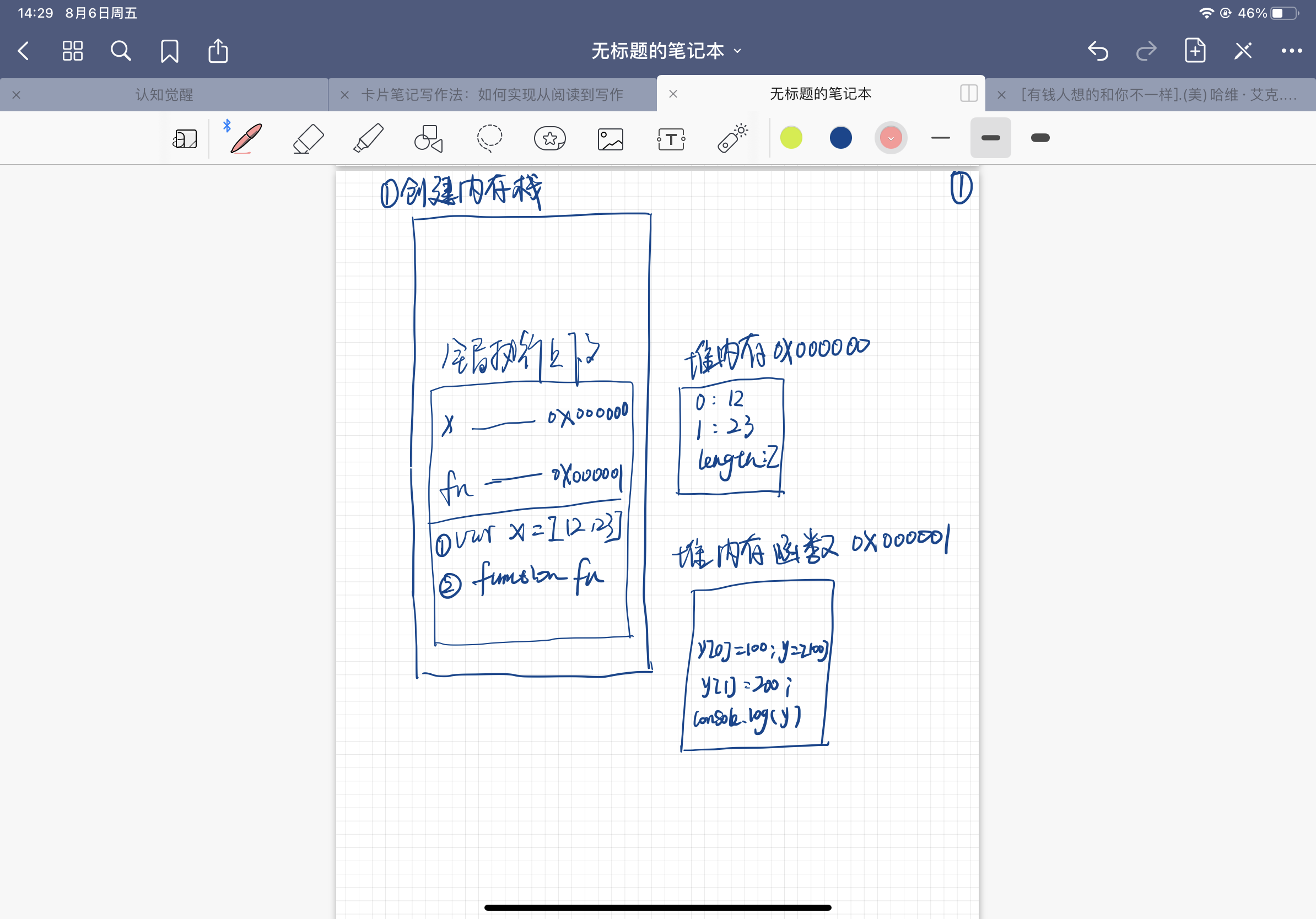
第二步:将fn私有上下文放入栈中
- 执行代码fn(x);会形成一个私有的上下文,
- 将函数fn的私有上下文放入执行环境栈中
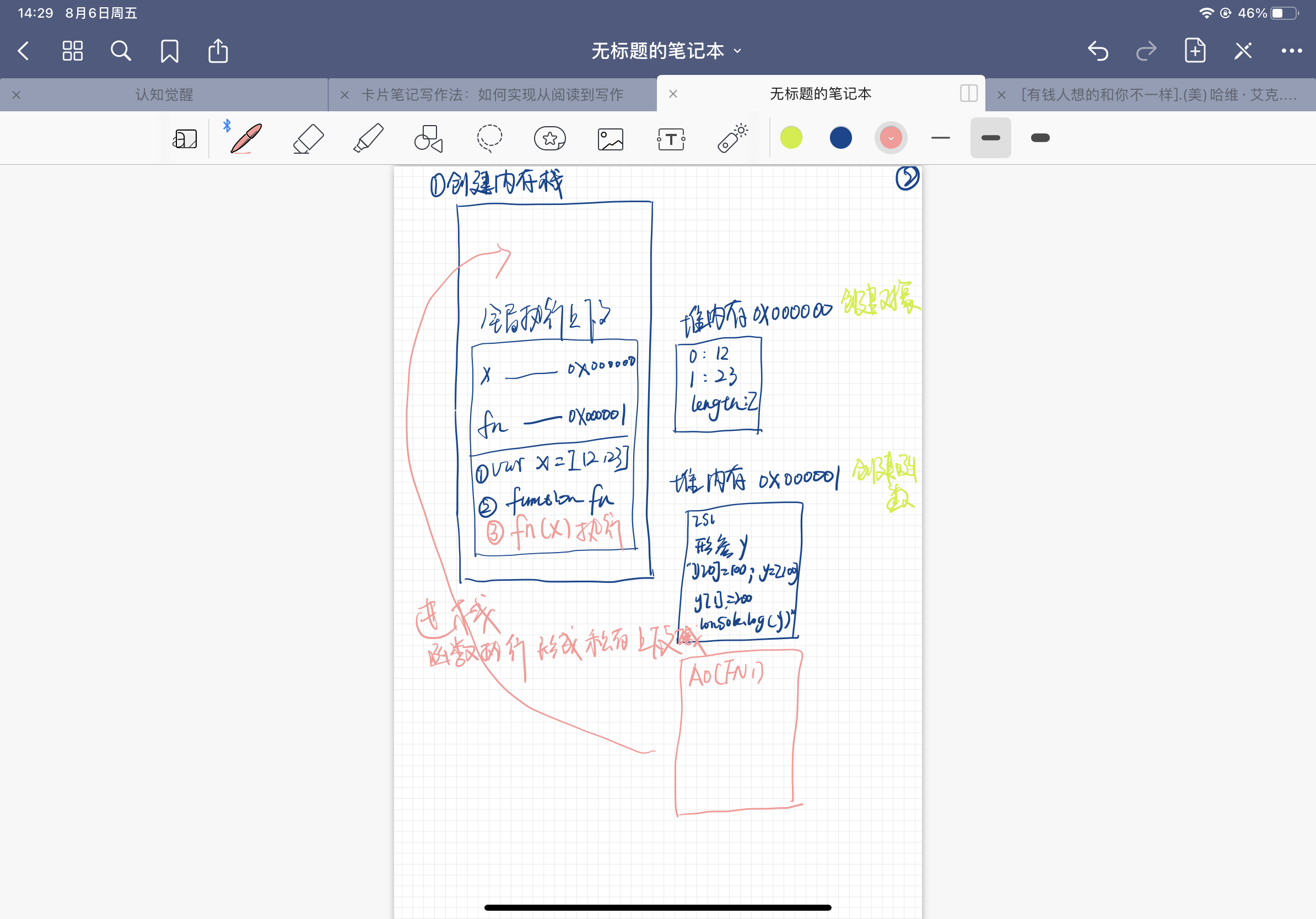
第三步:执行fn中的代码
- 变量x作为实参传入函数fn中,y与x产生关联,变量y指向x的地址0x000000; 内容为:
0:12,y:23,length:2y -> 0x000000 - 执行y[0] = 100; y -> 0x000000 内容为
0:12,y:23,length:2;所以将12改为100 内容变成0:100,y:23,length:2 - 执行
y=[100]; 注意,这里是创建值,所以开辟一个新的堆内存,地址为0x000001,内容为0:100,length:1,将y和0x000001产生关联,y -> 0x00001 - 执行
y[1] = 200; 这是成员访问,没有y[1];创建y[1],因为此时y -> 0x000001, 内容为0:100,length:1; 创建后的内容为0:100,1:200,length:2 - 执行代码
console.log(y)输出y=[100,200] - 执行代码
console.log(x)输出 x= [100,23]
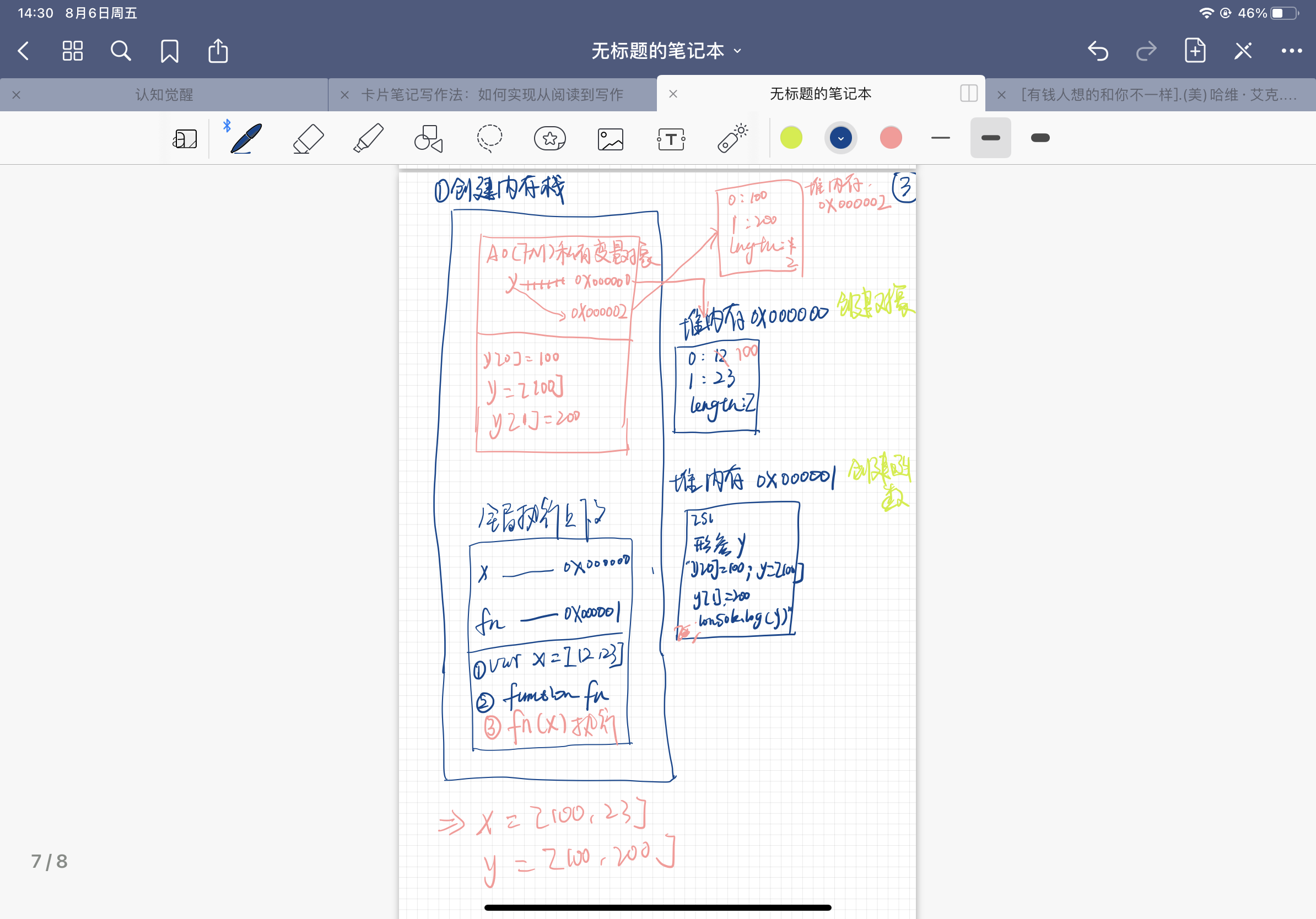
这个内存原理在日常使用上有三个最常用到的点
- 引用类型实际是指向内存空间,修改之后所有指向这个值的变量都会变化,新手容易搞混。
- 尾调优化。
- 引用变量的内存回收机制,防止内存泄漏。
总结
那今天都学习了哪些内容呢?
- js变量的赋值过程
- js代码的运行过程
今天,你学废了吗?















 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









