







第一步
在网页上登录新浪微博,获取登录cookie
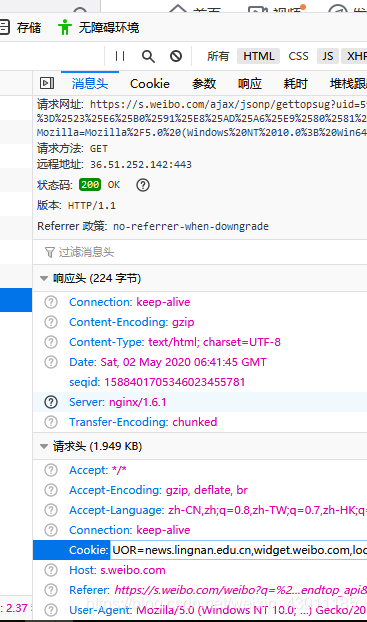
先把它复制好先,进行第二步
第二步
废话不多说,直接上代码,把刚刚复制好的值,赋给co变量
# -*- coding: utf-8 -*-
"""
Created on Fri May 1 14:54:19 2020
@author: Administrator
"""
import requests
import pandas as pd
import re
from bs4 import BeautifulSoup
#自定义header
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
co='刚刚复制的cookie值'
#自定义cookie,将cookie字符串,转为字典形式
def parse_cookieTodict(co):
#转为字典
codic={}
colist=co.replace(' ','').split(";")
#去空格
for i in colist:
a=i.split("=")
codic[a[0]]=a[1]
return codic
#通过网页的文本找到script脚本,因为微博的数据不是静态,他吧数据保存到js文件中的,因此,不能直接用beatifulsoup 查找,可以通过查找有‘hot_topic’类的script来获取到子元素的文本数据
def find_keyword(content):
a=BeautifulSoup(content,"html.parser")
print(type(a))
nameList = a.find_all("script")
nlen=len(nameList)
#查找目标所在的脚本位置
loc=[]
for a in range(nlen):
if(re.findall("hot_topic",nameList[a].text)):
loc.append(a)
for bb in loc:
if(re.findall("<ul class.*>*</ul>",nameList[bb].text)):
#找到了热门话题所在的位置
ul=re.findall("<ul class.*>*</ul>",nameList[20].text)[0]
# print(ul)
lis=ul.split("</p>")
hotpic=[]
for li in lis:
if(re.findall("<span class.*>(.*)</span>",li)):
hotdict={}
hotdict['num_read']=re.findall("<span class.*>(.*)</span>",li)[0]
# print("阅读量",re.findall("<span class.*>(.*)</span>",li)[0])
if(re.findall("<a target.*>(.*)</a>",li)):
hotdict['title']=re.findall(r'<a .* title=\"#(.*)\#"',li)[0]
hotdict['href']=re.findall('href=\"(.*)\" suda-uatrack',li)[0]
hotpic.append(hotdict)
# print("连接",re.findall('href=\"(.*)\" suda-uatrack',li)[0])
# print("标题",re.findall(r'<a .* title=\"#(.*)\#"',li)[0])
return hotpic
#发起请求
def get_text(url,co):
session=requests.session()
session.get(url,cookies=co).content.decode("utf-8")
return session.get(url,cookies=co).text.replace("\\","").replace(">n","").replace("rn","")
#执行代码
co=parse_cookieTodict(co)
#url为微博为网址,登录后自动跳转
content=get_text("https://weibo.com/u/5941486046/home?wvr=5",co)
# print(content)
aa=find_keyword(content)
gg=pd.DataFrame(aa)
#保存至磁盘,或者其他的地方,自己修改
gg.to_excel("D:\\数据分析数据与代码\\python-weibohot\\123.xlsx",index=False)
写在最后
交流:作为一名大学生,在求职的过程中,在选择企业的时候,你会考虑企业哪些方面呢?或者说,你希望从企业收获到什么、企业给你提供什么?欢迎在下方留言,一起探讨,么么哒

















 1472
1472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









