







弱小和无知不是生存的障碍,傲慢才是
文章目录
第一章:Java基础
1.1 JDBC的流程
-
加载JDBC驱动类
-
创建数据库的连接Connection
-
获得预处理语句PreparedStatement (多条记录时PreparedStatement语句编译一次,执行多次,而Statement编译多次,执行多次)
-
执行SQL语句
-
返回结果集
-
关闭资源
1.2 实例化对象的方法除了new还有哪些
工厂模式、反射、克隆、反序列化(Java序列化就是指把Java对象转换为字节序列的过程)
1.3 HashTable与HashMap的区别
-
HashTable线程安全,HashMap线程不安全
-
父类不同,HashTable继承自Dictory类,HashMap继承自AbstractMap类
-
HashTable不允许为null,HashMap允许存在nullkey和null值,但因为key不能重复,所以只能有一个key为null
1.4 Java8新特性
-
lambda表达式,函数式接口
-
foreach循环
-
接口中新增了静态方法和默认方法,都有方法体
-
stream流:filter,map,limit,distinct,sorted,foreach
-
时间日期API:
java.time.LocalDate 表示日期
LocalTime 表示时间
LocalDateTime 表示日期+时间
1.5 StringBuilder和StringBuffer
-
StringBuilder线程不安全,性能高
-
StringBuffer线程安全,性能不高
1.6 HashMap
链接:数据域 指针域,指针域有两个分别存储前驱节点和后继节点的地址就是双向链表
元素放入hashmap中,放入node节点中,nodel节点有四个字段key value next hash,当两个元素的key通过hash算法得到的hash值相同时就会存入单向链表中。hashmap初始值是16,负载因子是0.75,得到阈值是12,当元素超过12就会扩容,当数组长度超过64并且单向链表长度超过8就会将单向链表转为红黑树,当红黑树数据量小于6就会再转为单向链表
第二章:JavaWeb
2.1 session和cookie的区别
-
cookie数据存放于浏览器上,session存在服务器上
-
存放存放在本地所以不是很安全,别人可能分析你本地的cookie,进行欺诈,session更安全一些
-
session较多会影响系统性能
-
单个cookie保存的数据不能超过4k,很多浏览器限制一个站点最多保存20个cookie
-
session默认建立在cookie的基础之上,如果客户端不支持cookie,通过url重写实现
2.2 post和get的区别
-
post将请求参数放在请求的正文部分,get是放在请求行,url后面,以问号隔开,用&分割参数
-
post方式参数长度没限制,get方式有限制
-
post方式参数地址栏不可见,相对安全,get方式可见
2.3 rest风格
Representational State Transfer: 表现层状态转移->URL定位资源,用HTTP动词(GET,POST,DELETE,DETC)描述操作,REST本身不实用,
实用的是如何设计 RESTful API(REST风格的网络接口):
-
增:@PostMapping
-
删:@DeleteMapping
-
改:@PutMapping
-
查:@GetMapping
2.4 同源策略
两个页面的协议、域名和端口都一样,则是同源,可以隔离潜在恶意文件
第三章:多线程
3.1 sleep和wait的区别
-
sleep属于Thread类,wait属于Object
-
sleep可以在任何位置使用,而wait,notify等需要在同步方法或同步代码块中使用
-
sleep没有释放锁,它只释放了时间片,wait释放了锁
-
sleep需要捕获异常,wait不需要
3.2 AQS相关问题
AQS是一个抽象类AbstractQueuedSynchronizer,抽象同步队列,可以解决数据安全问题;
造成数据安全问题的原因:
- 可见性
JMM(Java Memory Model)java内存模型,使用volatile、synchronized、Lock、CountDownLatch可以 解决CountDownLatch是通过一个计数器来实现的,计数器的初始化值为线程的数量。每当一个线程完成了自己的任务后,计数器的值就相应得减1。当计数器到 达0时,表示所有的线程都已完成任务,然后在闭锁上等待的线程就可以恢复执行任务。
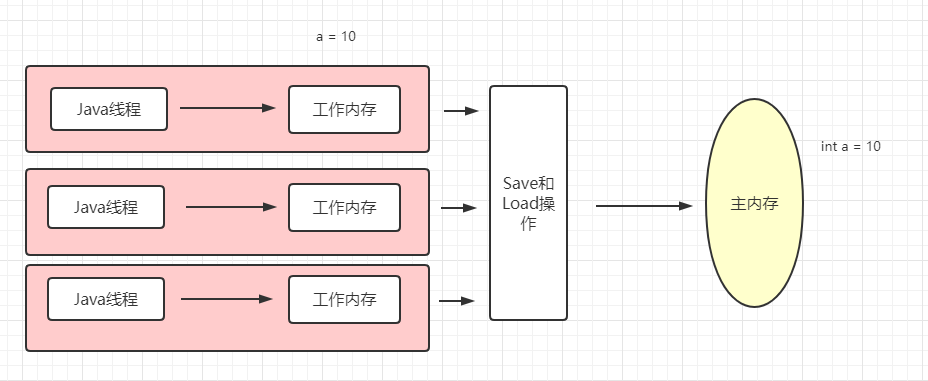
每个线程都有自己的工作内存,彼此隔离,当线程需要操作主内存中的数据时,就从主内存中将数据加载到本线程的工作内存中,对数据操作完成后,再把结果 保存到主内存中,这样就做到了各线程间的数据隔离,当多个线程同一时间把主内存中的同一数据进行加载到各自工作内存进行操作的时候就会引起数据安全问 题。
- 有序性
程序在jvm中运行时可能会发生指令优化导致重排序,volatile、synchronized、Lock都可以阻止重排序。
// 比如
int a;
a = 1;
a = 2;
本来a最终值为2,
若是发生重排序3、4行重排序,则会导致a最终值为1,
- 原子性
保证一段代码要么都执行要么都不执行,使用AtomicInteger、synchronized、Lock
第四章:数据库
4.1 事务的隔离级别
-
未提交读:导致脏读,即事务A读取了事务B的数据,此时B回滚,A读取的数据就是脏数据
-
已提交读(oracle默认级别):导致不可重复读,即事务A多次读取事务B的数据,但读取过程中更新了,导致A读取的数据前后不一致
-
可重复读(mysql默认级别):导致幻读,系统管理员A将表中的分数改为abcd等级,在改的过程中b又插入一条分数数据,A操作结束后发现还有一条数据没改过来,就像幻觉一样
-
序列化
4.2 事务的基本要素(ACID)
-
原子性:事务中的所有操作要么都成功,要么都失败,不会停留在中间环节,所有操作是一个整体,共进退
-
一致性:事务开始前和结束后,数据的完整性,A转账给B,不可能A扣了钱,B没收到
-
隔离性:同一时间,只允许一个事务处理同一条数据,不能A取钱的同时,B却向这张卡转了账
-
持久性:事务完成后事务对数据库的所有更新都将保存到数据库,既然事务完成了就不能再回滚了
4.3 mysql多表查询
可以通过子查询和表连接进行多表查询,
表连接分为内连和外联,
内连会返回两张表都符合条件的数据,null不会显示出来
外联会返回基准表的所有数据和另一张表符合条件的数据,没有会用null补全
例如左外联就是以左表为基准表
4.4 分页查询
limit offset,size 例如:limit 3,3 从第四条开始取3条记录
4.5 懒加载
懒加载就是延迟加载,当真正需要所需数据的时候才进行加载,而不是一开始就加载所有数据,懒加载跟缓存不是一回事
例如:
1.前端页面的懒加载,整个页面很大,较下方的页面还不在窗口中显示时就不需要加载进来,可以只是先加载同样的空白图片,而图片出现在窗口中时才加载
2.公司部门的结构查询,有很多部门,若是一次加载所有部门的结合信息显然不合理,所以当选定某个部门时才加载进来此部门的数据是更合理的选择
4.6 创建索引
- 创建索引:create index 索引名 on 表名(索引字段)
或者
create table test(
a int ,
b int,
c int,
d int,
key index_abc(a,b,c)
)engine=InnoDB default charset=utf8;
- 联合索引:最左匹配原则
类似于这种索引匹配规则,可以先看懂b+树的数据结构,这种很好理解。 因为在B+树种,联合索引(a,b,c) 是从左到右的。 此时,如果where b and c 这时 没有a,那么在B+树种无法找到第一个索引,所以无法走索引。 同理,如果where a and c 那么可以找到a开头的索引,所以可以走索引。
- 查看索引匹配情况
explain select * from test where b<10 and a <10;
4.7 存储引擎MyISAM和InnoDB的区别
InnoDB支持事务、外键、行锁;
MyISAM支持全文索引(select * from test where match(content) against('aaaa');)
清空整个表时,InnoDB是一行一行数据的删除,MyISAM是重新建表
4.8 索引是什么
索引就是对一个或多个列值的排序,帮助数据库高效获取数据的数据结构
4.9 索引类型
-
普通索引
-
唯一索引
-
主键索引
-
全文索引,只能在MyISAM存储引擎以及char、varchar、text类型的字段上使用全文索引
4.10 索引的缺点
增删改速度下降,因为每次增删改都要重建索引,而且占用空间
4.11 sql优化
- 建立索引
- 使用!=、or、in、not in、like(%通配符不在后面位置时)、算数运算会让存储引擎放弃索引
- 使用varchar代替char,节省存储空间
- 使用数字型字段,因为存储引擎在处理字符型字段的时候会比较每一个字符,而数字型比较一次就行了。
4.12 mysql中的锁
-
MyISAM支持表锁,InnoDB支持表锁和行锁,默认行锁
-
表锁:开销小,加锁快,不会出现死锁,锁定粒度大,发生锁冲突的概率较高,并发量低
-
行锁:开销大,加锁快,可能出现死锁,粒度小,所属锁冲突的概率较低,并发量高
第五章:Mybatis
5.1 $与#在mybatis中的区别
#是使用占位符,就是使用PreparedStatement预处理语句;
$是字符串拼接,就是使用Statement处理语句,容易导致sql注入
5.2 association与collection
association:一对一,多对一
collection:一对多
5.3 log4j2日志级别
all trace debug info warn error fatal off
5.4 实体类中的属性名和表中的字段名不一样,怎么办
-
使用别名
-
使用resultmap进行映射
5.5 xml文件与mapper接口的映射,工作原理是什么?Dao里面的方法可以重载吗?
原理是jdk动态代理为mapper接口生成代理类;
不可以重载,因为寻找策略是完全限定名+方法名;
namespace对应类,id对应方法,parameterType对应形参,resultType对应返回体.
5.6 在mapper中如何传递多个参数
包装类
多个参数封装成map集合
使用@param绑定参数
5.7 Mybatis的一级二级缓存
一级缓存是SqlSession级别的缓存(默认);
二级缓存是mapper级别的缓存;
当此级别的缓存执行cud操作时,默认该作用域下的select中的缓存将被清空.
5.8 mybatis是否支持延迟加载?如果支持,实现原理是什么?
Mybatis仅支持association和collection关联对象的延迟加载;
原理是使用cglib创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,拦截器方法如果发现a.getB().getName()中B为null,只会去执行sql语句,加载B对象信息,这就是延迟加载,真正用到的时候才加载.
第六章:Spring
6.1 AOP面向切面编程
增加一些统一的功能,比如日志,权限
原理:1.基于接口的jdk动态代理 2.基于子类的cglib动态代理
6.2 IOC控制反转
依赖注入,控制反转,将对象的创建交给apring容器,降低层与层直接的耦合度
6.3 Spring bean的作用域
-
prototype 原型,每次都会得到一个新的实例
-
singleten(默认) 单例,每次得到的都是同一个实例
-
request 每次请求创建一个实例,请求完成之后会被回收
-
session 每个session都有一个bean,session过期,bean失效
-
application 程序运行时bean就会一直生效
6.4 Spring常用注解
@Controller @Service @Repository @RequestMapping @RequestParam @RequestBody @ResponseBody @AutoWired @Scope @Transactional
6.5 Spring依赖注入方式
-
setter方法设值注入
-
构造器注入
-
接口注入,实现特定方法进行注入
6.6 BeanFactory和ApplicationContext区别
它们俩都是spring的核心接口,ApplicationContext是BeanFactory的子接口;
BeanFactory采用延迟加载注入bean,用到时才会加载具体bean;
ApplicationContext是在容器启动时,一次性创建所有bean.
6.7 Spring的自动装配
-
byName @Resource @Qualifier 按名称进行自动装配,其中@Resource名称不匹配会根据类型查找,使用setter方法按名称注入
-
byType @AutoWired 按类型自动装配,也是使用setter方法按形参类型注入
-
constructor 自动匹配构造器的参数
-
autodetect spring容器根据bean的内部结果,自行决定使用构造器或者setter方法注入
6.8 Spring事务的种类
1.声明式事务 2.声明式事务,入@Transactional
6.9 Spring的事务传播行为
-
PROPAGATION_REQUIRED:有事务则加入,没有事务则新建,这是最常用的设置
-
PROPAGATION_SUPPORTS:有事务则加入,没有事务就以非事务执行
-
PROPAGATION_MANDATORY:有事务就加入,没有事务就抛出异常
-
PROPAGATION_REQUITED_NEW:无论当前有没有事务,都新建
-
PROPAGATION_NOT_SUPPORTED:以非事务方式执行,有事务就挂起
-
PROPAGATION_NEVER:以非事务方式执行,有事务就跑异常
-
PROPAGATION_NESTED:有事务就新建一个内嵌事务,没有则新建
第七章:SpringMVC
7.1 SpringMVC的流程
用户请求发送到前端控制器DispatcherServlet,DispatcherServlet调用处理器映射器HandlerMapping,根据url返回具体的handler,DispatcherServlet调用
处理器适配器HandleAdapter,HandleAdapter调用handler生成ModelAndView返回给DispatcherServlet,DispatcherServlet调用视图解析器ViewResolver处理ModelAndView返回具体的view,然后DispatcherServlet对view进行渲染,最后响应用户
7.2 @RestController
@RestController相当于@Controller+@ResponseBody
第八章:Redis
-
redis是一个键值对的nosql非关系型数据库,mongodb是文档型数据库(云笔记leanode就是用的mongodb),查询效率更高
-
启动redis服务器:./src/redis-server
-
启动redis客户端:./src/redis-cli
-
redis端口:6379
-
redis数据类型
string(值最大512M) list hash set zset
-
常用命令
- select:挑选库,redis有16个库,编号0-15,默认是0库
- set get del
- setnx 在key不存在时设置key的值
- exists 检查key是否存在
- expire name 120 设置秒的过期时间
- pexpire 设置毫秒的过期时间
- ttl/pttl name 查看秒/毫秒过期时间
- keys * 通过正则表达式查找符合条件的key
- type 返回key的数据类型
- rename 修改key的名称
- flushdb 清空当前库
-
缓存穿透
一般缓存系统,按key去查找value,如果key不存在,就会去查数据库,且是大量恶意的请求,就会导致像是redis不起作用了,那么就会对数据库造成很大的压力,这叫做缓存穿透
解决办法:1.对结果为空的情况也进行缓存,多设置key,并且设置过期时间短;2.对key进行过滤
-
缓存雪崩
大量key同时失效,
解决办法:
1.对失效的key限制访问的线程数
2.做二级缓存,拷贝之前的缓存,之前缓存失效时使用
3.不同的key设置不同的过期时间
-
缓存击穿
就是key过期的瞬间,大量请求发过来
解决办法:设置永久key
-
redis持久化
rdb:(保存的是数据,且不是随时的)每隔一段时间将redis的数据保存起来,但是不安全,因为在两次保存时间节点之间redis宕机了,就会导致数据丢失, 一致性低,性能较好。
aof:(保存的是指令,随时)只要redis指令变了,就保存起来,数据更安全,一致性高,性能较差
-
过期策略
定期删除:没隔一段时间,随机选取一些设置了过期时间的key,如果过期了就进行删除
惰性删除:对设置了过期时间的key,当用到时发现过期了才进行删除
-
淘汰策略
- volatile-lru(less recently used):从设置过期时间的数据集中选出最少使用的key进行删除
- volatile-ttl(time to live):从设置过期时间的数据集中选出将要过期的数据进行删除
- volatile-random:从设置过期时间的数据集中随机挑选数据进行删除
- allkeys-lru:从所有数据集中选出最少使用的key进行删除
- allkeys-random:从所有数据集中选出将要过期的数据进行删除
- no-enviction(展望):不删除,这也是默认的策略
第九章:rabbitmq
第十章:docker
10.1 基本命令
- docker search 搜索镜像
- docker pull 拉取镜像
- docker run 运行镜像
- docker ps 查看正在运行的容器
- docker start 容器id 启动容器
- docker restart/stop/kill
- docker rm 容器id 删除容器
- docker rmi -f 镜像id 删除镜像
- docker cp 共享宿主机和容器的文件夹,达到文件可以直接在宿主机修改的目的
- docker exec -it 交互方式进入容器
- 重启策略:
1. no:默认策略
2. on-failure:3 :尝试重启三次
3. always:一直重启
10.2 名称解释
- dockerhub 镜像仓
- dockerfile 用来制作镜像
- 镜像运行后生成容器,这些容器共用一个kernel(系统内核)
- pod是kubernetes的最小控制单元,k8s是管理容器的
第十一章:iaas&paas&saas&daas
11.1 概念
一个程序真正运行起来需要四部分:
- 基础设施:服务器、磁盘、网络、机房设施 —iaas
- 平台软件:操作系统、数据库、中间件&运行库(flume、kafka、redis、jdk、看门狗等安装环境)—paas
- 应用软件 —saas
- 数据信息 —daas
11.2 iaas
Infrastructure as a server: 基础设施即服务。

11.3 paas
Platform as a Server: 平台即服务,即把运行用户所需的软件的平台作为服务出租。

11.4 saas
Software as a Server: 软件即服务。把软件租出去,用户连安装都不需要了。

11.5 daas
Date as a Server: 数据即服务。
云端公司负责建立全部的IT环境,收集用户需要的基础数据并且做数据分析,最后对分析结构或者算法提供编程接口,让数据成为服务。
















 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









