








文章目录
第一章 计算机基础
- 正数的原码、反码、补码相同,符号位为0,负数的符号位为1,反码符号位不变,其他位取反,补码在反码基础上加1。二进制整数最终都是以补码形式出现的。
- 二进制位运算:
1. 按位取反 :~
2. 与:&
3. 或:|
4. 异或:^ ,相同为0,不同为1 - 运算器、存储器、控制器、输入设备、输出设备
- TCP/IP(OSI已被淘汰):应用层(http/ftp)-> 传输层(端口tcp/udp)-> 网络层(ip)-> 链路层(MAC地址)-> 物理层
程序在发送消息时,应用层按既定的协议打包数据,随后由传输层加上端口,由网络层加上ip地址,由链路层加上mac地址后进行数据传输。 - 三次握手主要是用ack确认机制(四次挥手断开连接)

- sql注入
使用了字符串拼接的方式,这样可能导致一些请求里面含有恶意的sql语句
解决办法,mybatis使用#{},占位符的方式 - xss(cross-site scripting)跨站脚本攻击
用户执行了恶意的脚本
解决办法:
1. 使用spring的HtmlUtils对用户输入的字符串做html转义
2. 使用innerText(它会去除html标签),而不是使用innerHTML - csrf (cross-site request forgery)跨站请求伪造
黑客盗用了用户的登录信息,冒充用户进行操作
解决办法:
1. 鉴权,验证页面中或者cookie中的token
2. 人机交互,用手机验证码校验 - xss是用户执行了恶意的代码,csrf是用户的信息被盗用,黑客借此执行恶意操作。
第二章 面向对象
-
内部类
- 静态内部类
- 成员内部类
- 局部内部类
- 匿名内部类
内部类引用:外部类$内部类
protected:包外子类
嵌套循环退出外层循环使用标记位: c: break/continue c
-
重写:一大两小两同
子类的访问权限控制符只能相同或更大,子类抛出的异常或者返回类型只能更小,且要有继承关系,方法名和形参相同 -
成员变量有默认值,局部变量没有默认值且必须在声明的时候就初始化
-
int 默认值是0,Integer默认值是null
-
byte,short,int,long可以缓存 -128 ~ 127; char缓存0 ~ 127; boolean、float、double无缓存(包装类一样)
-
且Integer是唯一可以调整缓存范围的包装类,在vm options中加入参数
-
pojo以及返回类型和形参都使用包装类,局部变量使用基本类型
-
String是不可以修改的,每当改变时,若改变后的值在常量池中没有,都会创建一个新的String对象,然后引用重新指向新的对象,
并会将新的String对象缓存进常量池中,StringBuffer和StringBuilder则是在原来的对象上进行修改,StringBuilder线程不安全,效率高。
第三章 代码风格
嵌套循环不要超过三层
第四章 走进jvm
1. jdk,jre,jvm区别(4.1)

2. 字节码(4.2)
- 同样的字节码怎样在不同的机器上运行,或者说怎么做到跨平台,这
用到了不同的jvm,不同平台上的jvm是不同的,简而言之,有不同的
jvm来匹配不同的平台,然后执行同样的字节码文件,做到跨平台。
2. 字节码是二进制的,java一共有200个左右指令集,而一个字节可以
最多表示256种不同的指令信息,这也就说明了一个字节所能展示的指
令集大小是可以满足java需求的。
3. 字节码可以通过解释器解释执行,也可以通过JIT编译器将字节
码即时编译成本地机器码在cpu上运行。 - 机器码:机器码是离cpu指令集最近的编码,是cpu可以直接解读的指令。
- JIT编译器:just-in-time compilation
- 即时编译流程简单描述:字节码需要通过类加载过程加载到jvm环境(就是类加载将字节码文件加载到内存中然后才能与cpu进行交 互)后,才可以执行。java程序最初都是通过解释器进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为"热点代码(Hot Spot Code)",然后即时编译器把这些字节码编译成本地机器码。
- 执行有三种模式:
1. 解释器解释执行:解释器启动快(省去编译时间),不会造成大量额外内存,适合机器刚启动(冷机)和内存占用率较大时。
2. 即时编译器(JIT)编译执行:JIT编译效率高(因为复用编译后的本地机器码),适合机器已经启动完备(热机)和内存占用率不 大时。
3. 解释执行和JIT编译执行混合执行(默认),图如下:

3. 类加载过程(4.3)
需要将字节码文件加载到内存中,cpu才能与之交互执行,加载过程入下图:
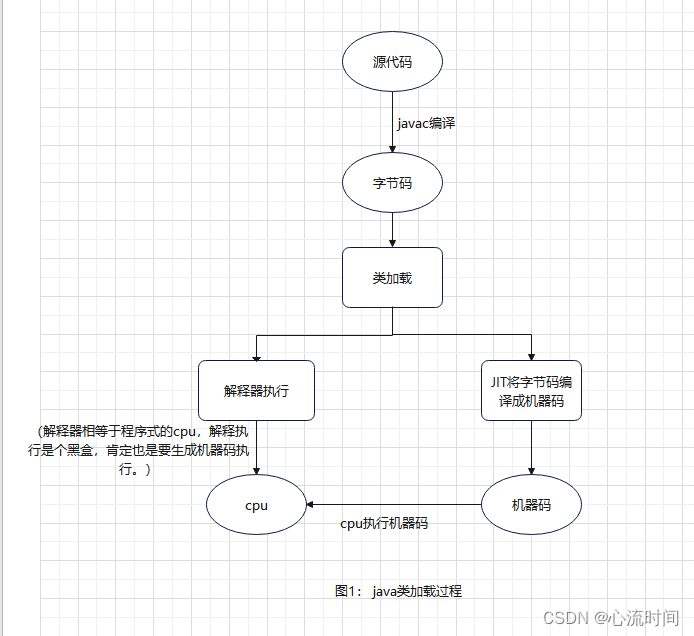
类加载采用双亲委派模型:
1. 从上到下:根类加载器–扩展类加载器–应用程序类加载器(classpath下的)–用户自定义加载器
2. 低层次的当前类加载器不能覆盖高层次类加载器已经加载的类
3. 加载过程是低层次的类加载器逐级向上询问,上级的类加载器没有加载过此类并且也不能加载此类才由当前这个低级别的类加载器加 载此类,假如曾经加载过或者可以加载,则继续向更高层次的类加载器询问,直到更高层次的类加载器没加载过且这次也不能加载,则由下级别的类加载器加载,如果一直到最上面,根类加载器可以加载,就由根类加载器进行加载。简而言之就是上面的类加载器加载不了才会由下面的类加载器加载,这是为了防止一些java自带的类被覆盖失去作用。
4. 根类加载器是由c/c++实现,其他类加载器是由java实现
5. 一个类的加载过程中所有父类的静态代码块和静态赋值语句都会执行
4. JVM内存布局(4.4)
结构:堆、元空间、虚拟机栈、本地方法栈、程序计数器、CodeCache
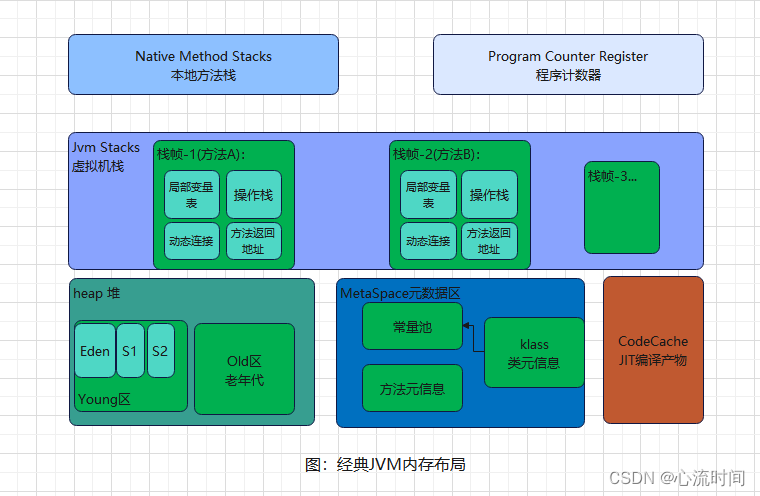
- Heap(堆)
- 堆是OOM(OutOfMemoryError)主要发源地,存放对象,由垃圾回收器 自动回收,内容由各子线程共享。
- 堆分为两块,新生代和老年代,新生代包括Eden和S0、S1。
- -Xms1024M -Xmx1024M -X代表它是JVM的运行参数,ms(memory start)最小堆容量,mx(memory max)最大堆容量,设置为相同,在服务器运行过程中,就不会频繁的对堆空间进行扩缩容,也算JVM调优的一个方法。
- 对象分配简要流程:
-
申请给新对象分配,新对象放到Eden区,如果放不下,Eden区满的时候会触发YGC(Young Garbage Collection),YGC将没有引用的对象直接清除,仍有引用的转移到空的那块Survivor区(S0,S1,两种状态:使用中和空未使用),然后也把正在使用的Survivor区的对象转移到这个空的Survivor区,接下来清除正在使用的Sruvivor区,将他们的使用状态交换,并且每个对象都有一个计数器,每次YGC都会加1,对象中计数器的值达到阈值就会被放入老年代,假如设置计数器的阈值为1,则会直接从Eden区晋升到老年代。Eden放不下的超大对象直接放到老年代,老年代也放不下会触发FGC(Full Garbage Collection),再次重试能否放入老年代,如果还放不下,则触发OOM。
-
图示:
-

2. Metaspace(元空间)
元空间的前身是Perm区(永久代),jdk8改为元空间,Perm中的字符串常量移到了堆内存,其他类元信息、方法元信息、其他常量等移到元空间中。
3. JVM Stack(虚拟机栈)
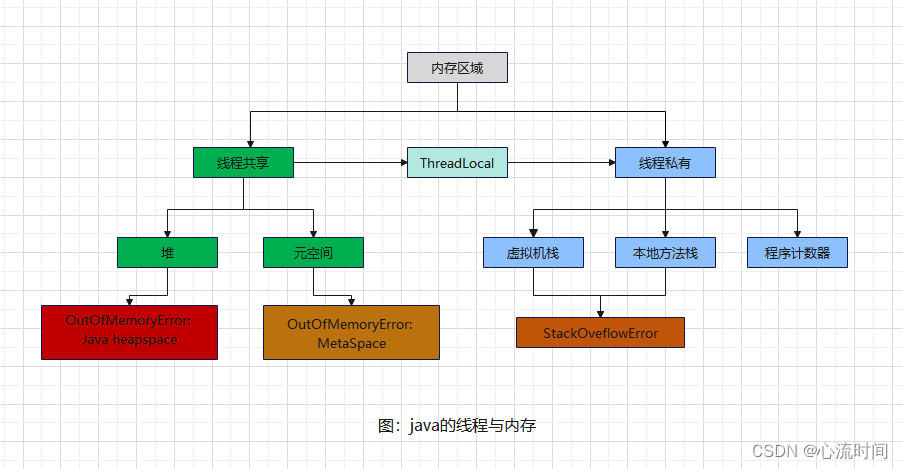
java虚拟机栈就是java方法执行的内存区域,线程私有,栈中的元素支持虚拟机进行方法调用,方法的执行就是入栈到出栈的的过程,栈溢出StackOverflowError导致内存耗尽,常出现在递归方法中;
结构:局部变量表、操作栈、动态连接、方法返回地址
局部变量表:存放方法参数和局部变量的区域。
操作栈:操作栈是先进后出的数据结构, JVM的执行引擎是基于栈的执行引擎,这个栈就是操作栈。
示例代码:
public int method1() {
int x = 13;
int y =14;
int z = x + y;
return z;
}
将元数据区常量池中的常量13压入操作栈(这里与常量池进行交互就用到了动态连接),并将数据保存到局部变量表位置1中,
14同样操作(位置2),将位置1和位置2的值压入操作栈,将上面两个栈帧的值取出去cpu中相加,得到的结果压入操作栈,
将栈顶栈的结果保存到局部变量表的位置3处。返回栈顶栈的数据。
a=i++ 和 a=++i 的区别
这里涉及三个指令
1. iload: 将局部变量表中的值压入加载到栈
2. istore: 将栈顶帧中的数据存储到局部变量表
3. iinc: 这个是可以在局部变量表自行操作的指令,不需要与操作栈交互,作用是对数据加1
a=i++过程:iload iinc iistore
描述:先将i的值压入操作栈,i的值在局部变量表加1,然后将栈顶元素值赋值给局部变量表中的a
a=++i过程:iinc iload iistore
描述:先i的值在局部变量表加1,将i的值压入操作栈,然后将栈顶元素值赋值给局部变量表中的a
总结:他们的区别就在于++i是先在局部变量表中执行iinc 的+1操作,然后才进行其他操作。
这里也说明了一个问题,那就是i++不是原子操作,因为,i的值和i++返回的值明显不一样。
动态连接:每个栈帧中都包含一个常量池对当前方法的引用,简而言之就是保持常量池和当前方法的连接。
方法返回地址:方法执行完,返回至方法当前被调用的位置。
4.Native Method Stacks(本地方法栈)
native方法,非java代码实现,通过JNI(Java Native Interface)来访问虚拟机中的数据,不在JVM的管辖范围,最出名的
JNI类本地方法是System.currentTimeMillis(),本地方法栈也是线程私有,为native方法服务,而虚拟机栈是为java代码服务。
5.Program Counter Register(程序计数器)
每个线程都有自己的程序计数器和栈帧,程序计数器用来存放指令的偏移量,线程的执行和恢复都要依赖程序计数器。简而言之,线程的上下文切换就是依赖程序计数器。
5 . 垃圾回收器(4.5)
a. GC Roots对象:类静态属性中引用的对象、常量引用的对象、虚拟机栈中引用的对象、本地方法栈中引用的对象等都可以作为GC Roots对象,然后垃圾回收算法会从每个GC Roots对象出发,依次标记与他们有引用关系的对象。
b. 垃圾回收器算法常见的三种:
1). 标记-清除算法:将没有标记的对象清除,但是这种算法容易造成大量空间碎片,容易引发FGC.
2). 标记-整理算法:为了解决标记-清除算法的空间碎片问题,此算法会将标记存活的对象整理到空间的一端,形成连续的空间。
3). 标记-复制算法:标记-整理算法是标记完成之后才整理,而此算法可以并行处理,实现是,将空间分为两块(S0、S1),一个已激活一个未激活,将所有标记使用的对象复制到未激活的空间中,然后交换两个空间的状态,清除刚才激活空间中的原对象,这也是现在YGC主流算法。
c. 垃圾回收器定义:是实现垃圾回收算法并应用在JVM环境中的内存管理模块。
d. STW(Stop The World):即垃圾回收的某个阶段会暂停应用程序的执行。
e: 垃圾回收器常见的三种:
1)Serial回收器:采用标记-复制算法,串行单线程完成gc任务,YGC和FGC时都会导致STW问题,影响系统性能。
2)CMS回收器(Concurrent Mark Sweep Collector):采用标记-清除算法,会造成空间碎片,此回收器共四个步骤,其中两个不会引发STW,相较于Serial回收器有很大进步。
3)G1回收器(Garbage-First Garbage Collector):采用标记-复制算法,对于程序的暂停时间更加可控,且不会产生空间碎片。
第五章 异常与日志
- 异常
-
所有异常都是Throwable的子类
-
异常分为Error和Exception,其中Error标志系统发生了不可控的错误,比如StackOverflowError、OutOfMemoryError;Exception又分为受检异常和非受检异常,受检异常在编译时就会发现,比如SQLException、ClassNotFoundException异常,非受检异常是在程序运行过程中才会发现的,比如空指针异常、数组下标越界异常等
-
finally中的代码没有执行的可能性为:
- 没有进入try代码块
- 进入try代码块,但是代码运行中出现了死循环或者死锁的现象
- 执行了System.exit()退出系统操作
-
为什么lock.lock()方法要在try代码块上面写:
- 如果.lock()方法在try代码块中,则finally中的.unlock()方法必然执行,若是.lock没有加锁成功,那么就会导致.unlock方法对一个没有加锁的对象释放锁,这种情况会引发运行时异常。
- 在 try-finally 外加锁的话,如果因为发生异常导致加锁失败,try-finally 块中的代码不会执行
- 这样做的好处是在2中我们就可以很清楚的定位到问题是是加锁失败,而1中可能会误导我们解锁失败引发异常导致的程序中断。
-
- 日志
- 日志框架分为三大类:日志门面、日志适配器、日志库
- 日志库:log4j、log4j2、logback
- 日志门面:slf4j、commons-logging 在代码中只需要写日志门面即可,日志具体的实现交给日志库完成,这样我们在切换日志库的时候就不需要更改代码了,实现了程序中的日志代码与具体日志实现库的解耦。
- 日志适配器:log4j-over-slf4j,有些日志库没有实现日志门面实现的接口,所有他们中间需要一个适配器。
第六章 数据结构与集合
第七章 并发与多线程
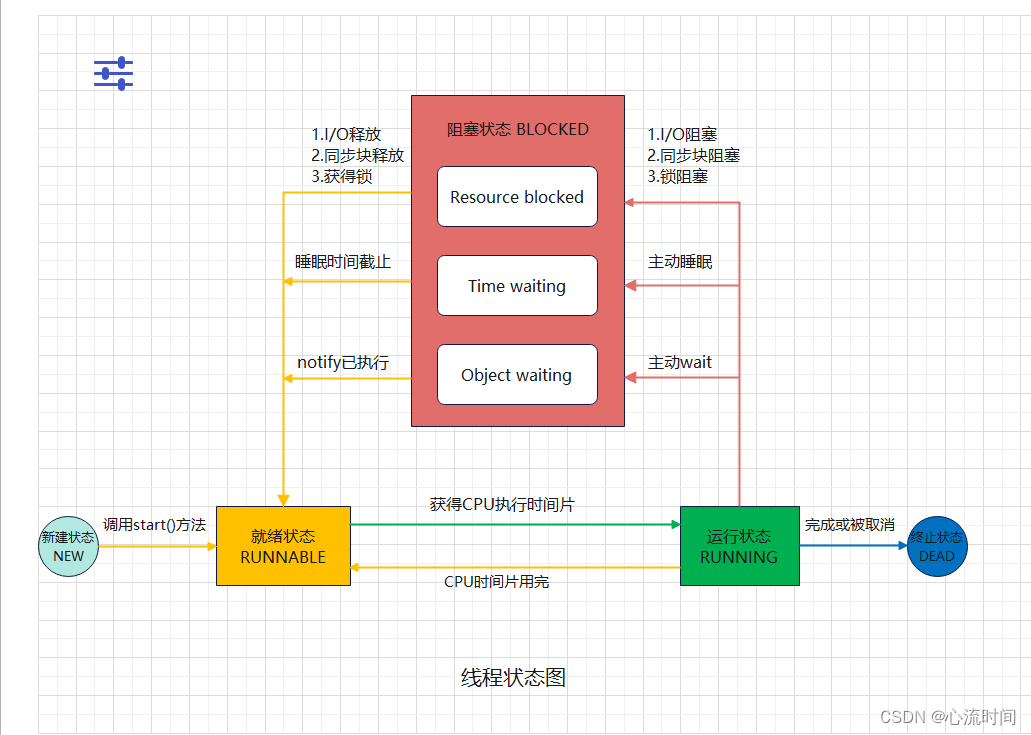
1.线程状态图














 1899
1899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









