









XML格式文本解析(包含python和C#2种代码处理)
原始XML文本内容如下
<?xml version="1.0" encoding="UTF-8"?>
<SOAP-ENV:Envelope xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/" xmlns:SOAP-ENC="http://schemas.xmlsoap.org/soap/encoding/" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<SOAP-ENV:Header xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"></SOAP-ENV:Header><SOAP-ENV:Body>
<ser-root:trackShipmentRequestResponse xmlns:ser-root="http://scxgxtt.phx-dc.dhl.com/glDHLExpressTrack/providers/services/trackShipment">
<trackingResponse xmlns:ns="http://www.dhl.com">
<ns:TrackingResponse>
<Response>
<ServiceHeader>
<MessageTime>2022-07-11T08:29:29</MessageTime>
<MessageReference>TrackingShipmentFST_RIT_Data</MessageReference>
<ServiceInvocationID>20220711082929_52d4_8956d7a1-b491-4e36-99ac-9d9483c2eebe</ServiceInvocationID>
</ServiceHeader>
</Response>
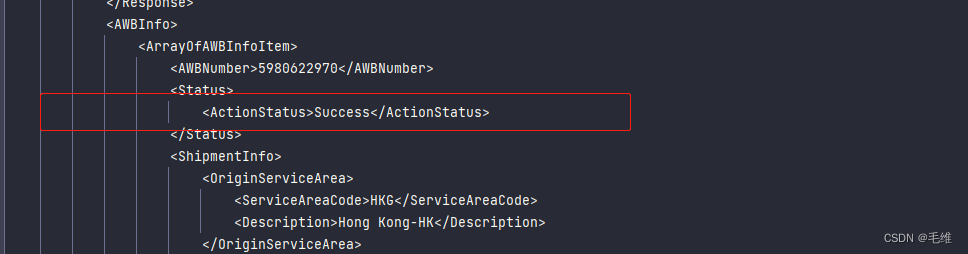
<AWBInfo>
<ArrayOfAWBInfoItem>
<AWBNumber>5980622970</AWBNumber>
<Status>
<ActionStatus>Success</ActionStatus>
</Status>
<ShipmentInfo>
<OriginServiceArea>
<ServiceAreaCode>HKG</ServiceAreaCode>
<Description>Hong Kong-HK</Description>
</OriginServiceArea>
<DestinationServiceArea>
<ServiceAreaCode>TSR</ServiceAreaCode>
<Description>Timisoara-RO</Description>
<FacilityCode>TSR</FacilityCode>
</DestinationServiceArea>
<ShipperName>EMPOWER SCM LTD</ShipperName>
<ConsigneeName>SC SOLAR POERR SOLUTIONS SRL</ConsigneeName>
<ShipmentDate>2021-10-05T16:23:48</ShipmentDate>
<Pieces>6</Pieces>
<Weight>102.000</Weight>
<WeightUnit>K</WeightUnit>
<ServiceType>P</ServiceType>
<ShipmentDescription>INVERTER</ShipmentDescription>
<Shipper>
<City>HONG KONG</City>
<Suburb>Fau Shan Road,NT,Hong Kong</Suburb>
<CountryCode>HK</CountryCode>
</Shipper>
<Consignee>
<City>LIPOVA</City>
<Suburb>315400 ROMANIA CUI:43855010</Suburb>
<StateOrProvinceCode>AR</StateOrProvinceCode>
<PostalCode>315400</PostalCode>
<CountryCode>RO</CountryCode>
</Consignee>
</ShipmentInfo>
<Pieces>
<PieceInfo>
<ArrayOfPieceInfoItem>
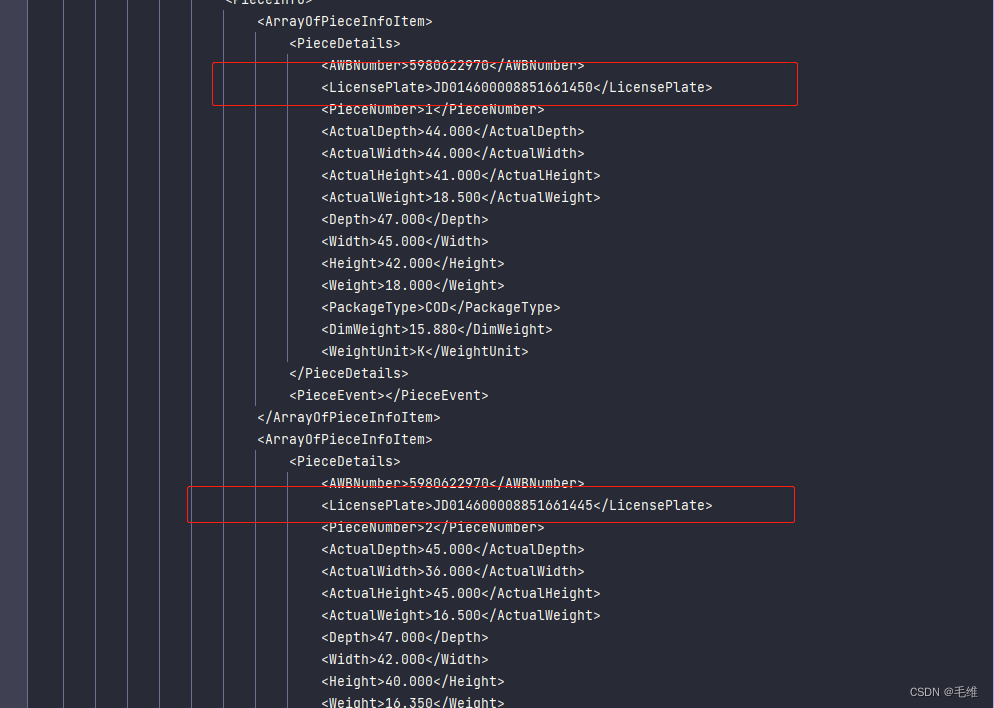
<PieceDetails>
<AWBNumber>5980622970</AWBNumber>
<LicensePlate>JD014600008851661450</LicensePlate>
<PieceNumber>1</PieceNumber>
<ActualDepth>44.000</ActualDepth>
<ActualWidth>44.000</ActualWidth>
<ActualHeight>41.000</ActualHeight>
<ActualWeight>18.500</ActualWeight>
<Depth>47.000</Depth>
<Width>45.000</Width>
<Height>42.000</Height>
<Weight>18.000</Weight>
<PackageType>COD</PackageType>
<DimWeight>15.880</DimWeight>
<WeightUnit>K</WeightUnit>
</PieceDetails>
<PieceEvent></PieceEvent>
</ArrayOfPieceInfoItem>
<ArrayOfPieceInfoItem>
<PieceDetails>
<AWBNumber>5980622970</AWBNumber>
<LicensePlate>JD014600008851661445</LicensePlate>
<PieceNumber>2</PieceNumber>
<ActualDepth>45.000</ActualDepth>
<ActualWidth>36.000</ActualWidth>
<ActualHeight>45.000</ActualHeight>
<ActualWeight>16.500</ActualWeight>
<Depth>47.000</Depth>
<Width>42.000</Width>
<Height>40.000</Height>
<Weight>16.350</Weight>
<PackageType>COD</PackageType>
<DimWeight>14.580</DimWeight>
<WeightUnit>K</WeightUnit>
</PieceDetails>
<PieceEvent></PieceEvent>
</ArrayOfPieceInfoItem>
</PieceInfo>
</Pieces>
</ArrayOfAWBInfoItem>
</AWBInfo>
</ns:TrackingResponse>
</trackingResponse>
</ser-root:trackShipmentRequestResponse>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
python处理
1. 正则匹配法
根据xml特性,每个标签都是以类似格式开头和结束,可以可以使用正则直接匹配出来。
代码如下:
import re
def get_file_content(filename):
try:
with open(file=filename, mode="r", encoding="utf-8") as f:
return f.read()
except:
return ""
"""正则匹配法来读取XML文件内容"""
def re_get_xml_value(text, start_str, end_str):
try:
return re.findall(".*%s(.*?)%s.*" % (start_str, end_str), text)
except:
return []
if __name__ == '__main__':
xml_str = get_file_content("xml.txt")
# 匹配唯一标签情况
start_str = "<ActionStatus>"
end_str = "</ActionStatus>"
print("ActionStatus:"+re_get_xml_value(xml_str, start_str, end_str)[0])
# 匹配多个标签情况
start_str1 = "<LicensePlate>"
end_str1 = "</LicensePlate>"
for lp in re_get_xml_value(xml_str, start_str1, end_str1):
print("LicensePlate:" + lp)
执行结果:

2. 使用xml.dom解析xml
根据xml特性,每个标签都是以类似格式开头和结束,可以可以使用正则直接匹配出来。
代码如下:
from xml.dom.minidom import parseString
def get_file_content(filename):
try:
with open(file=filename, mode="r", encoding="utf-8") as f:
return f.read()
except:
return ""
def xml_dom_content(xml_str, tag_name):
try:
"""使用xml.dom解析xml"""
# 使用minidom解析器打开 XML 文档
collection = parseString(xml_str).documentElement
return collection.getElementsByTagName(tag_name)
except:
return ""
if __name__ == '__main__':
xml_str = get_file_content("xml.txt")
# 单个标签情况
tag_name1 = "ActionStatus"
xml_result1 = xml_dom_content(xml_str, tag_name1)
for x in xml_result1:
print(tag_name1+":"+x.childNodes[0].data)
# 多个标签情况
tag_name2 = "LicensePlate"
xml_result2 = xml_dom_content(xml_str, tag_name2)
for x in xml_result2:
print(tag_name2 + ":" + x.childNodes[0].data)
执行结果:
C#处理
1. 正则匹配法
// 匹配单个标签情况
string startstr="<ActionStatus>";
string endstr="</ActionStatus>";
Regex rg = new Regex("(?<=(" + startstr + "))[.\\s\\S]*?(?=(" + endstr + "))", RegexOptions.Multiline | RegexOptions.Singleline);
if (rg.IsMatch(result))
{
MatchCollection matchCollection = rg.Matches(result);
foreach (Match match in matchCollection)
{
Console.WriteLine(startstr+":"+match.Value);
}
}
// 匹配多个标签情况
string startstr1="<LicensePlate>";
string endstr1="</LicensePlate>";
Regex rg1 = new Regex("(?<=(" + startstr1 + "))[.\\s\\S]*?(?=(" + endstr1 + "))", RegexOptions.Multiline | RegexOptions.Singleline);
if (rg1.IsMatch(result))
{
MatchCollection matchCollection1 = rg1.Matches(result);
foreach (Match match in matchCollection1)
{
Console.WriteLine(startstr1+":"+match.Value);
}
}
2. 将XML转换成Json
//XmlDocument读取xml文件
XmlDocument xmlDoc = new XmlDocument();
xmlDoc.Load(@"C:\Users\Administrator\Documents\测试结果反馈.txt");
//转换为json
string json = JsonConvert.SerializeXmlNode(xmlDoc);
//解析json
JObject jobj = JObject.Parse(json);
Console.WriteLine(jobj["SOAP-ENV:Envelope"]["SOAP-ENV:Body"]["ser-root:trackShipmentRequestResponse"]["trackingResponse"]["ns:TrackingResponse"]["AWBInfo"]["ArrayOfAWBInfoItem"]["Status"].ToString());















 2623
2623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









