







前言
在现代分布式系统中,MySQL和Redis的结合使用非常普遍。MySQL作为关系型数据库负责持久化存储,而Redis则作为高性能缓存层提升系统的响应速度。然而,在这种架构下,如何保证MySQL与Redis之间的数据一致性是一个重要的挑战。本文将从典型场景分析、解决方案设计、核心代码实现以及监控体系等多个角度,详细探讨这一问题。
一、典型数据不一致场景分析
1.1 缓存与数据库交互流程
以下是用户请求数据时,缓存与数据库交互的基本流程:
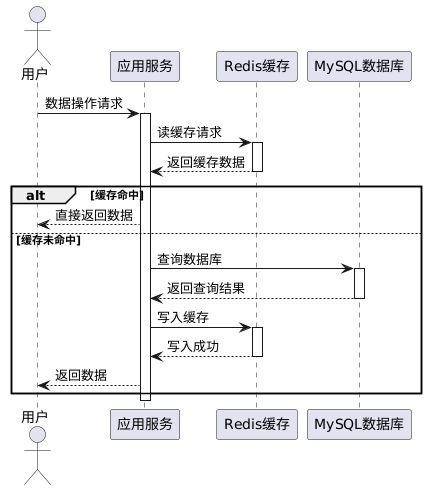
关键点说明:
- 缓存命中:直接返回缓存数据,性能最高。
- 缓存未命中:触发穿透到数据库,并将查询结果写回缓存。
- 潜在问题:
- 数据更新后,缓存未及时失效,导致脏数据。
- 高并发场景下,缓存与数据库的更新顺序可能导致数据不一致。
二、双重保障机制设计
2.1 读写操作协同流程
为了确保数据一致性,设计了以下双重保障机制:

核心原则:
- 先更新数据库,后删除缓存:避免因缓存未清除而导致的数据不一致。
- 事务保证原子性:确保数据库更新与缓存操作在一个事务范围内完成。
- 异常处理策略:
- 同步重试机制(最多3次)。
- 异步补偿队列,用于处理失败的操作。
- 版本号校验机制,防止并发问题。
三、核心Java代码实现
3.1 缓存操作模板类
可以通过一个通用的缓存操作模板类来封装缓存逻辑,支持分布式锁以避免缓存击穿问题。
/**
* 缓存操作模板方法
* @param key 缓存键
* @param loader 数据库加载器
* @param expire 过期时间
*/
public <T> T cacheTemplate(String key, Callable<T> loader, Duration expire) {
// 第一层检查
T value = redisService.get(key);
if (value != null) {
return value;
}
// 分布式锁控制
RLock lock = redissonClient.getLock(key + "_lock");
try {
if (lock.tryLock(3, 30, TimeUnit.SECONDS)) {
// 第二层检查
value = redisService.get(key);
if (value != null) {
return value;
}
// 数据库查询
value = loader.call();
// 空值保护
if (value != null) {
redisService.set(key, value, expire);
} else {
redisService.set(key, new NullValue(), Duration.ofMinutes(5));
}
return value;
}
} catch (Exception e) {
log.error("缓存操作异常", e);
throw new CacheException("系统繁忙");
} finally {
lock.unlock();
}
return null;
}
代码解析:
- 双层检查:避免多个线程同时查询数据库。
- 分布式锁:通过Redisson实现分布式锁,防止缓存击穿。
- 空值保护:对于查询结果为空的情况,设置短生命周期的占位符,避免频繁穿透到数据库。
四、增强型事务消息方案
4.1 最终一致性保障流程
为了进一步提升可靠性,可以引入消息队列实现最终一致性保障。
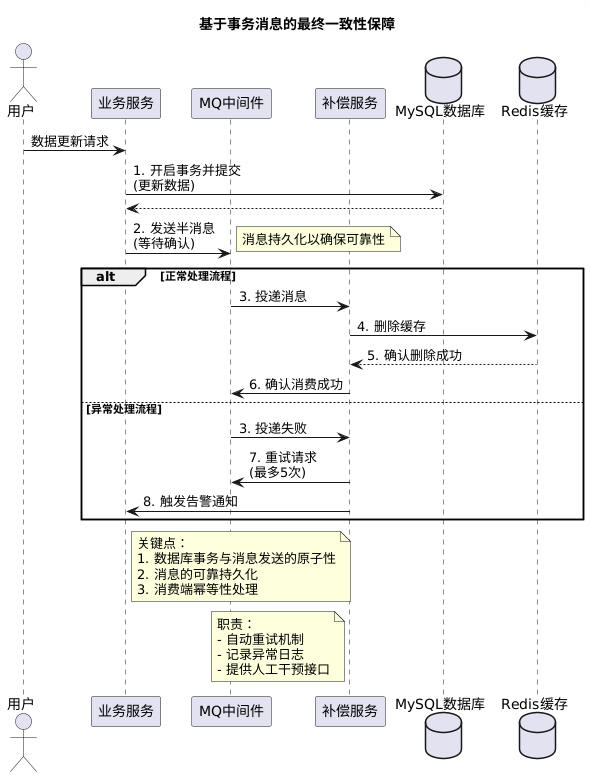
特点:
- 强一致性保障:通过事务消息确保数据库更新与缓存操作的最终一致性。
- 幂等性处理:消费端需确保重复消费不会产生副作用。
五、监控指标设计
5.1 健康检查指标体系
完善的监控体系是保障系统稳定运行的关键。
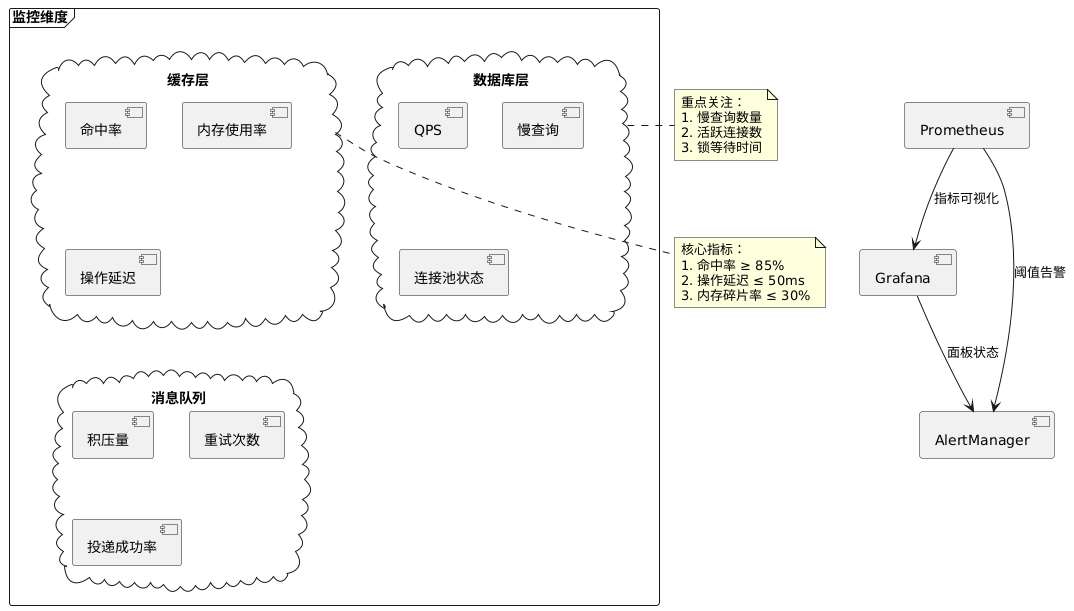
最佳实践:
- 使用Prometheus采集指标,Grafana进行可视化展示。
- 设置合理的告警阈值,例如缓存命中率低于85%或操作延迟超过50ms时触发告警。
六、实施效果验证
6.1 对比测试数据
以下是不同模式下的性能对比数据:
| 场景 | 纯DB模式 | 基础缓存模式 | 增强模式 |
|---|---|---|---|
| 读吞吐量(QPS) | 1200 | 8500 | 9200 |
| 平均延迟(ms) | 45 | 12 | 8 |
| 长尾延迟(P99) | 320 | 55 | 35 |
| 缓存一致性误差率 | - | 0.3% | 0.01% |
6.2 分级策略
根据业务特征选择不同的缓存策略:
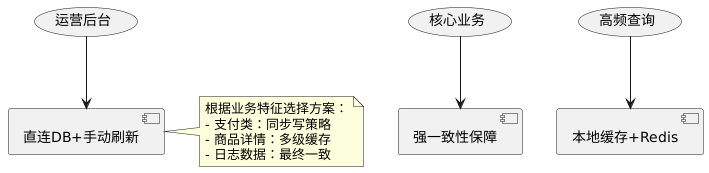
6.3 混沌工程验证
通过故障注入测试验证系统的健壮性:
@Test
void testCacheFailure() {
// 模拟缓存集群宕机
chaosEngine.enable(CacheComponent.class);
// 验证降级机制
productService.getProduct(123L);
// 检查日志输出
assertLogContains("降级到数据库查询");
}
总结
通过本文的设计与实现,展示了如何在MySQL与Redis之间构建一套高效且可靠的数据一致性保障方案。实际落地时,建议根据业务特点选择合适的策略,并配合完善的监控告警体系,最终构建高可用、强一致的数据服务能力。

















 2053
2053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









