







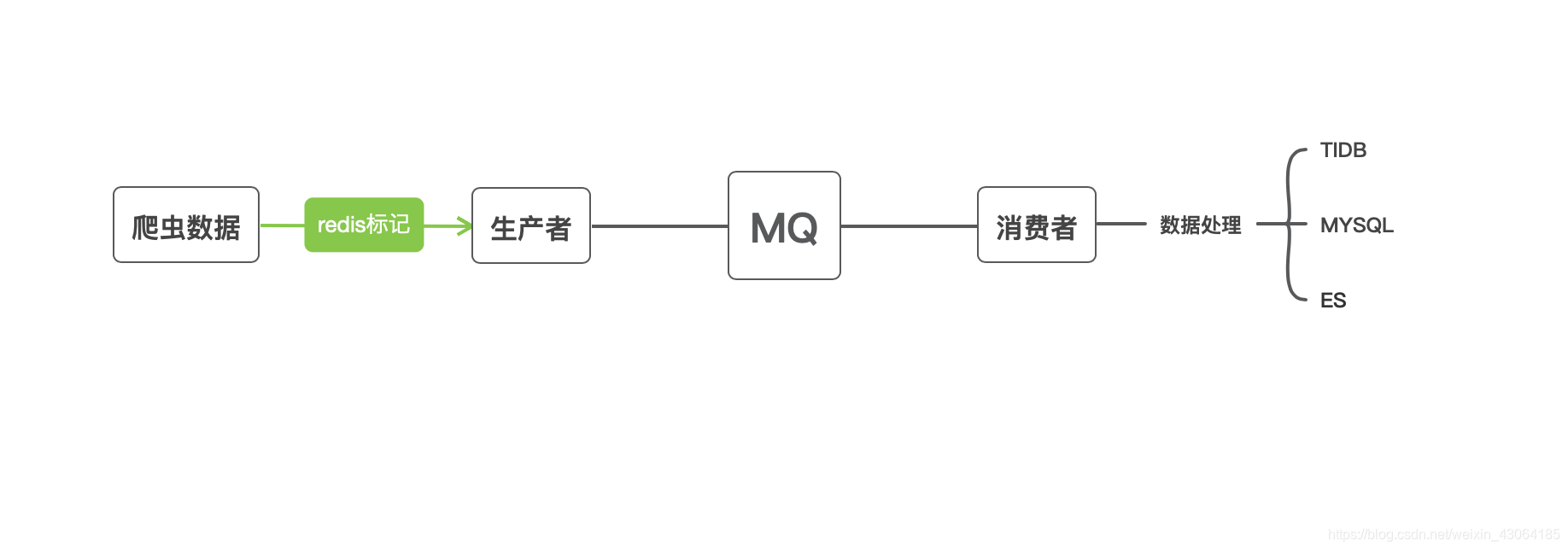
设计方案
1.如何解决获取同步mongo数据
- 爬虫程序在存数据时判断数据是否为新数据
- 确定为新存数据需要通过redis打个标记, 确定存入数据含有新数据
- 爬虫程序结束时需要在结束调用函数查询redis是否含有标记, 如果标记存在调用生产者通知MQ上游程序执行完让下游程序开始获取并处理数据
2.如何解决MQ实时获取数据
1. 使用MQ的发布/订阅一对一获取队列
2. 初步定为消费者判断获取增量数据并存储一个处理的时间日期节点
- 将之前的一对一获取队列改为按网站行业/类型/媒体创建多个队列, 提高并发
- 获取增量数据改为爬虫每次调用生产者发送给队列中
消息结构:{“start_time”:xxxx, “end_time”:xxxx, ''makr":xxx, "sort ":xxxxx}
start_time: 爬虫开始存入开始时间戳
end_time: 爬虫结束存入开始时间戳
makr: 标识
sort: 分类 (这个暂定, 需要在生产者之前去确认, MQ通过生产者在将消息发送给Exchange的时候,一般会指定一个routing key,来指定这个消息的路由规则)
3. 大体流程图:
4. 采用direct队列Queue:
- direct类型的Exchange路由规则也很简单,它会把消息路由到那些binding key与routing key完全匹配的Queue中
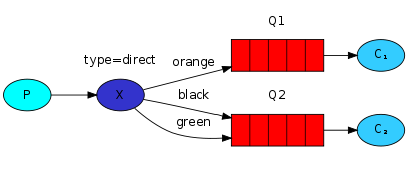
以routingKey=”error”发送消息到Exchange,则消息会路由到Queue1(amqp.gen-S9b…,这是由RabbitMQ自动生成的Queue名称)和Queue2(amqp.gen-Agl…)如果我们以routingKey=”info”或routingKey=”warning”来发送消息,则消息只会路由到Queue2。routingKey发送消息,则消息不会路由到这两个Queue中。
5. rebbitmq 管理和监视
- rebbitmq搭建采用docker容器部署在128服务器
- 外网采用docker安装nginx容器反向代理转发128服务器MQ管理页面
6. 消费者确认和发布者确认
消费者确认:
- MQ 消费消息的机制:在消费者收到消息的时候,会发送一个 ACK 给 MQ,告诉 MQ 这条消息被消费到了,这样 MQ 就会把消息删除
- 默认情况下这个发送 ACK 的操作是自动提交的, 自动提交会存在消费者数据丢失或者没有消费
- 针对这个问题的解决方案就是:关闭 MQ 消费者的自动提交 ACK,在消费者处理完这条消息之后再手动提交 ACK (手写代码确认)
发布者确认:
- 事务方式:在生产者发送消息之前,通过
channel.txSelect开启一个事务,接着发送消息。如果消息没有成功被 RabbitMQ 接收到,生产者会收到异常,此时就可以进行事务回滚channel.txRollback,然后重新发送。假如 RabbitMQ 收到了这个消息,就可以提交事务channel.txCommit。但是这样一来,生产者的吞吐量和性能都会降低很多. - Confirm 机制: 是在生产者那里设置, 每次写消息的时候会分配一个唯一的 ID,然后 RabbitMQ 收到之后会回传一个 ACK,告诉生产者这个消息 OK 了。如果 RabbitMQ 没有处理到这个消息,那么就回调一个 Nack 的接口,这个时候生产者就可以重发。


















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











