







scrapy爬虫
1.scrapy是什么?
1.简介
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。运用多进程,多进程,队列等技术。
2.scrapy安装
pip install scrapy
如果报错:Command "c:\python3.6.0\python.exe -u -c "import setuptools, tokenize;file='C:\Users\admin\Ap
**解决方法:**https://blog.csdn.net/weixin_43097301/article/details/88060348
3.框架介绍
1.框架由五部分组成:引擎,下载器,蜘蛛爬虫(spiders),调度器(scheduler),管道(pipeline)
2.我们主要书写spiders(爬虫文件),管道。spiders实现文件内容解析,url提取。管道:处理数据连接数据库进行储存,比如mysql,mongo,redis等
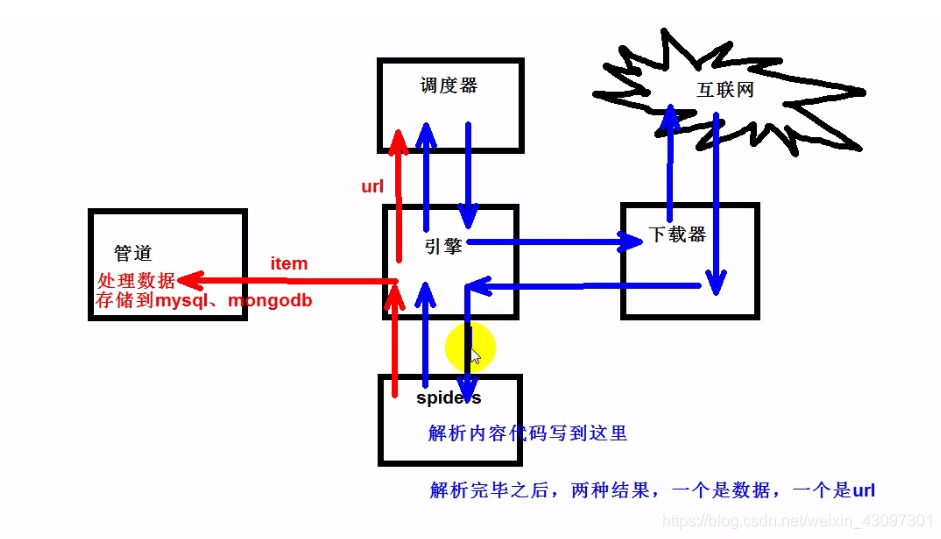
首先spiders将url传给–>引擎–>调度器(管理url队列)–>引擎–>下载器–>互联网–>下载器–>引擎–>spiders解析(url继续循环这个循环,而数据内容将进行储存)–>引擎–>管代处理数据存储(数据库)
3.创建项目
(1)scrapy startproject 项目名称
打开cmd (命令窗口 , 或者 git), cd 到所要创建项目的目录下,
scrapy startproject first_work

(2)目录结构
first_work
first_work #真正的项目文件
_pycache_ #缓存文件
spiders #爬虫文件
__pycache__ #缓存
__init__.py
爬虫文件.py #自己写的爬虫文件
_init_.py #包的标志
items.py #定义数据结构
middlewares.py #中间件
pipelines.py #管道文件(怎么存储)
settings.py #配置文件
scrapy.cfg
(3)生成爬虫文件
cd first_work(新建的项目)
scrapy genspider one_spider(自己爬虫的名称) example.com(爬取的网址,这里先默认)
pycharm:
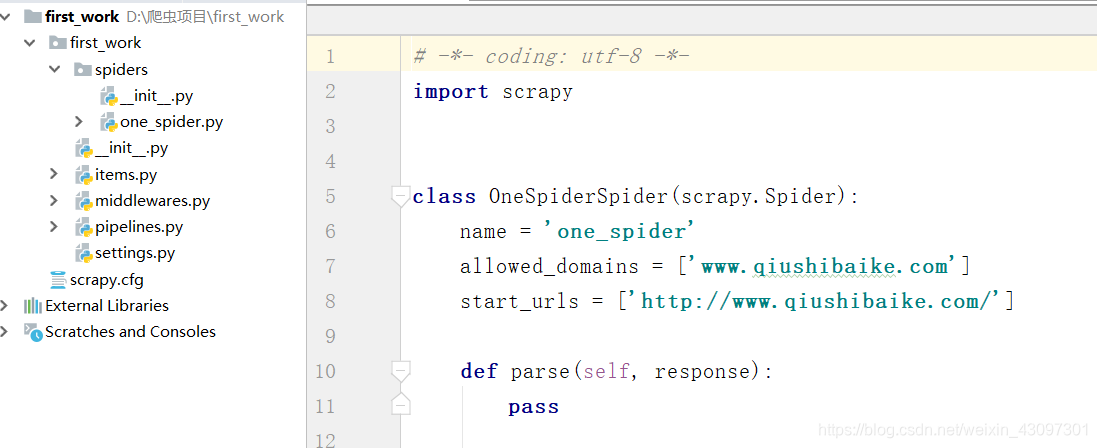
打开one_spider.py 后,我把之前默认的example.com网址修改成我们将要爬取的www.qiushibaike.com,如图:
(4)response响应对象
运行爬虫:
1.cd first_work/first_work/spiders(进入爬虫文件的目录下)
2.scrapy crawl one_spider(自定义的爬虫的名字)
单词crawl:爬行
# -*- coding: utf-8 -*-
import scrapy
class OneSpiderSpider(scrapy.Spider):
name = 'one_spider' # 自定义的爬虫名字
allowed_domains = ['www.qiushibaike.com'] # 允许爬取的域名,限制爬取的范围必须为域名下的,可以为多个
start_urls = ['http://www.qiushibaike.com/'] #给定一个起始的url
def parse(self, response): #parse解析函数,这是一个父类的方法,这里就是重写这个方法
#参数response就是响应后的内容
#这里必须返回一个可迭代对象(生成器,列表等)
print("-------------------------------------\n")
print(response)
print("-------------------------------------\n")
运行后有可能报错:ModuleNotFoundError: No module named ‘win32api’(缺少win32api模块)
解决错误:https://blog.csdn.net/weixin_43097301/article/details/83243760 (就是安装pywin32)
运行后py文件后:
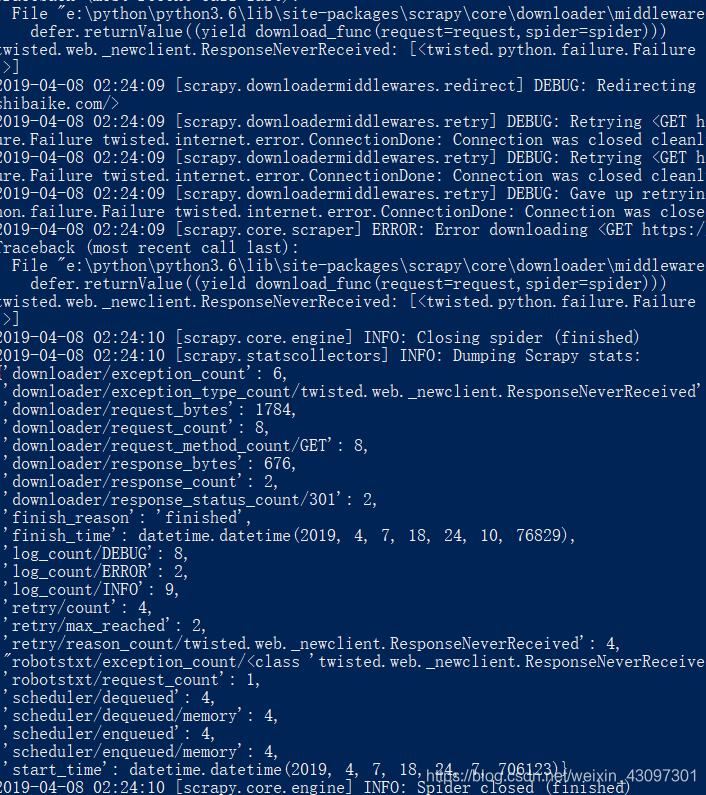
可以看到上面这里并没有返回我们打印内容,说明请求是有问题的。
查看网站的robots.txt协议: www.qiushibaike.com/robots.txt
(robots.txt协议:协议规定,那些网站可以爬取,那些不能爬取 (allow允许,disallow不允许))
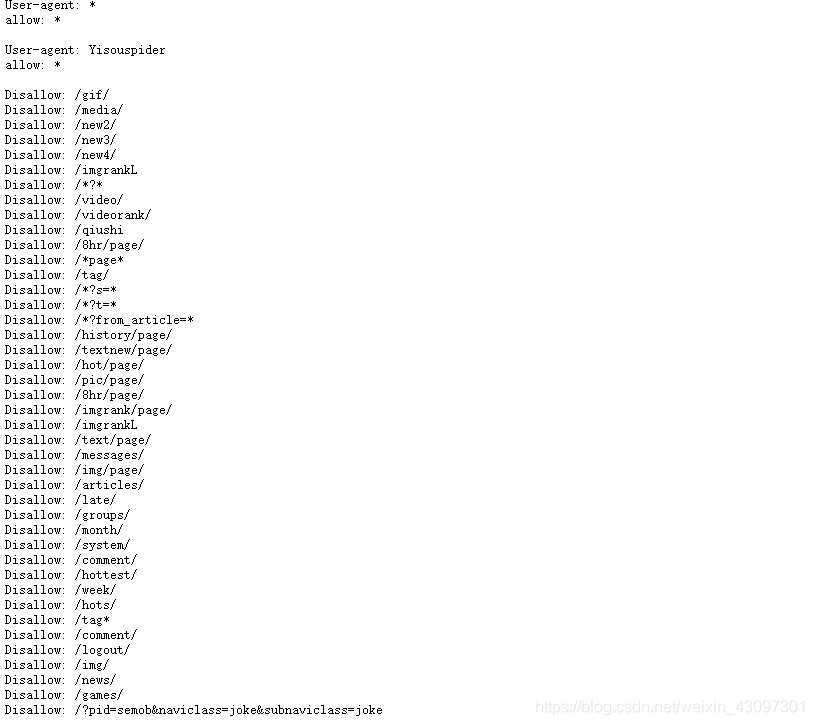
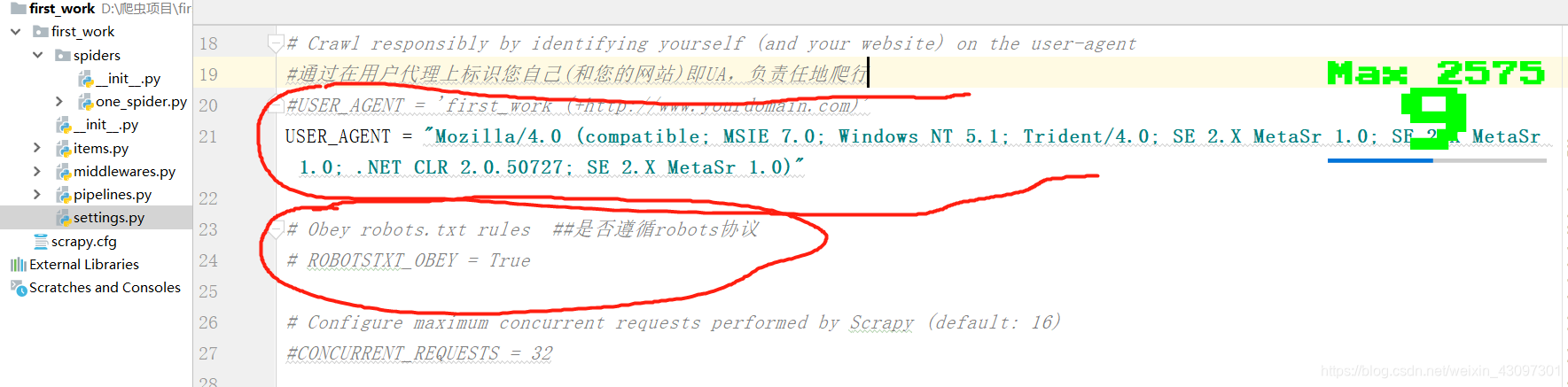
我们这里就修改项目里面的setting配置文件
如图,我们不遵循robots协议,伪装自己的UA(百度UA大全,找一个即可)
https://blog.csdn.net/weixin_43097301/article/details/89079270
再次运行:
请求成功
3.response的常用方法和属性
text:字符创类型 (response.text)
body:字节类型(response.body)
xpath():scrapy内部已经集成了xpath,和原版的xpath略微不同
# -*- coding: utf-8 -*-
import scrapy
class OneSpiderSpider(scrapy.Spider):
name = 'one_spider' # 自定义的爬虫名字
allowed_domains = ['www.qiushibaike.com'] # 允许爬取的域名,限制爬取的范围必须为域名下的,可以为多个
start_urls = ['https://www.qiushibaike.com/'] #给定一个起始的url
def parse(self, response): #parse解析函数,这是一个父类的方法,这里就是重写这个方法
#参数response就是响应后的内容
#这里必须返回一个可迭代对象(生成器,列表等)
print("-------------------------------------\n")
print(response.text) #print(response.body)
print("-------------------------------------\n")
print(response.text):如下图
print(response.body):如下图
xpath()
目标网址https://www.qiushibaike.com/hot/
开发工具查看一波:
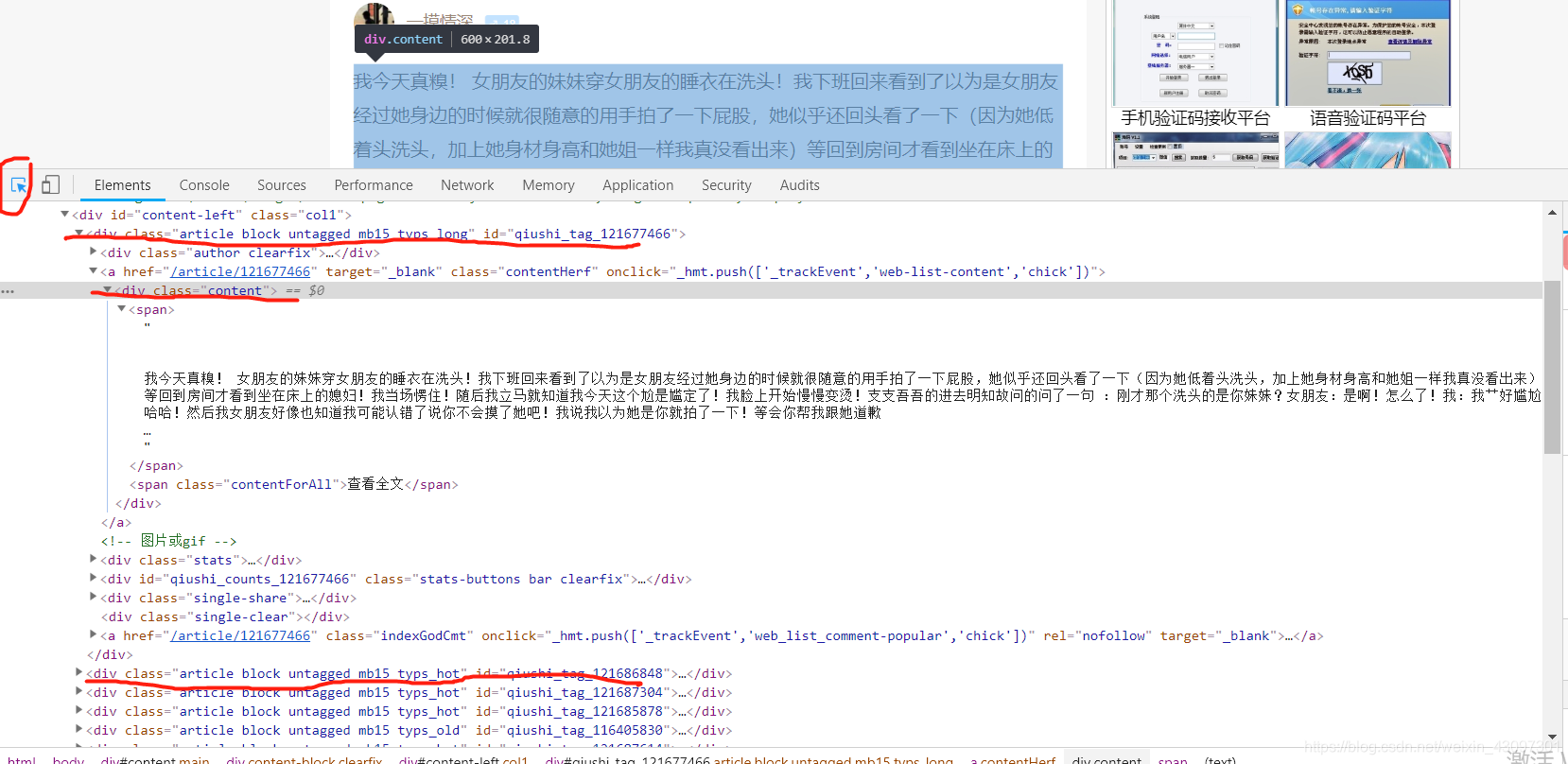
import scrapy
class OneSpiderSpider(scrapy.Spider):
name = 'one_spider' # 自定义的爬虫名字
allowed_domains = ['www.qiushibaike.com'] # 允许爬取的域名,限制爬取的范围必须为域名下的,可以为多个
start_urls = ['https://www.qiushibaike.com/hot/'] #给定一个起始的url
def parse(self, response): #parse解析函数,这是一个父类的方法,这里就是重写这个方法
#参数response就是响应后的内容
#这里必须返回一个可迭代对象(生成器,列表等)
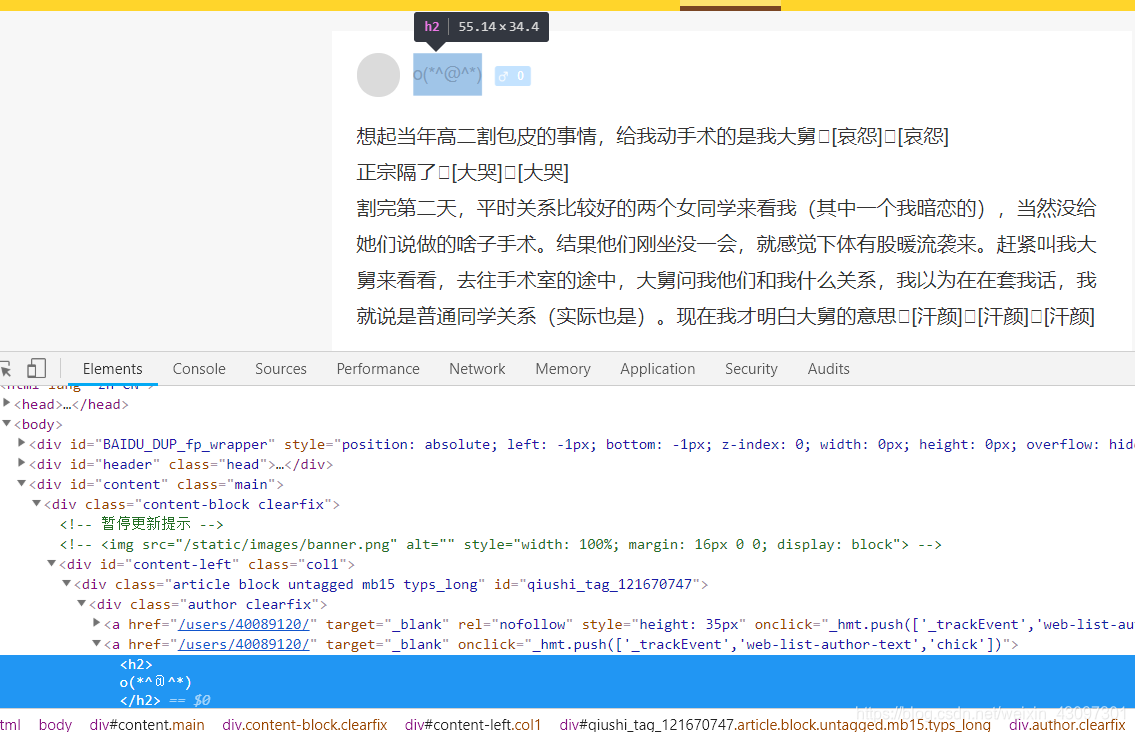
div_list = response.xpath("//div[@id='content-left']/div")
print(div_list)
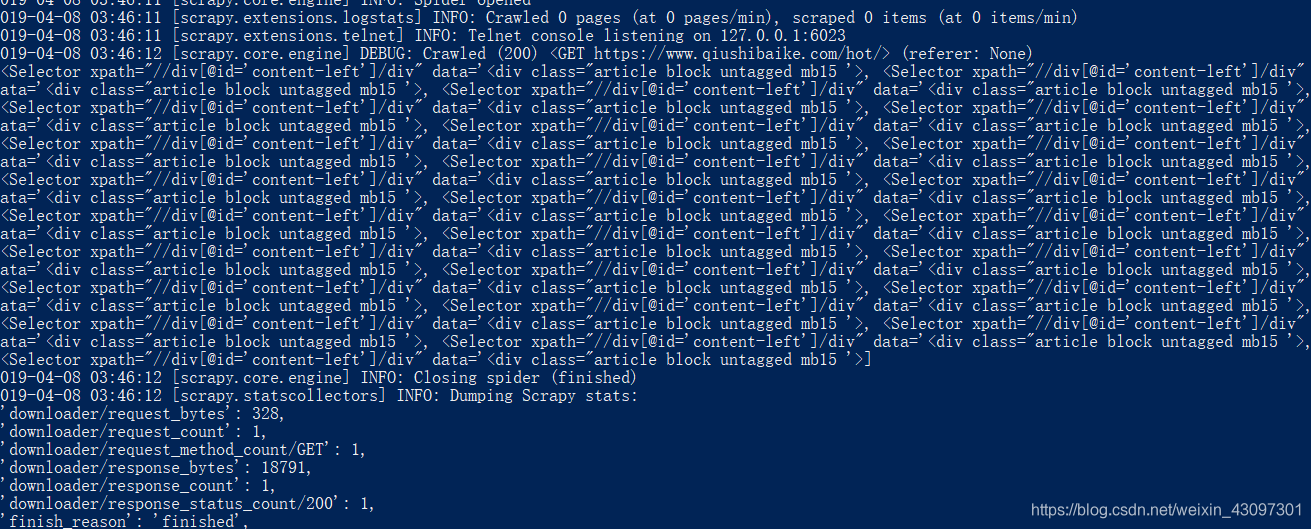
返回列表中为Selector对象:
这里我们获取用户的头像,开发工具中进行查看标签xpath匹配(ctrl+f 打开匹配工具)
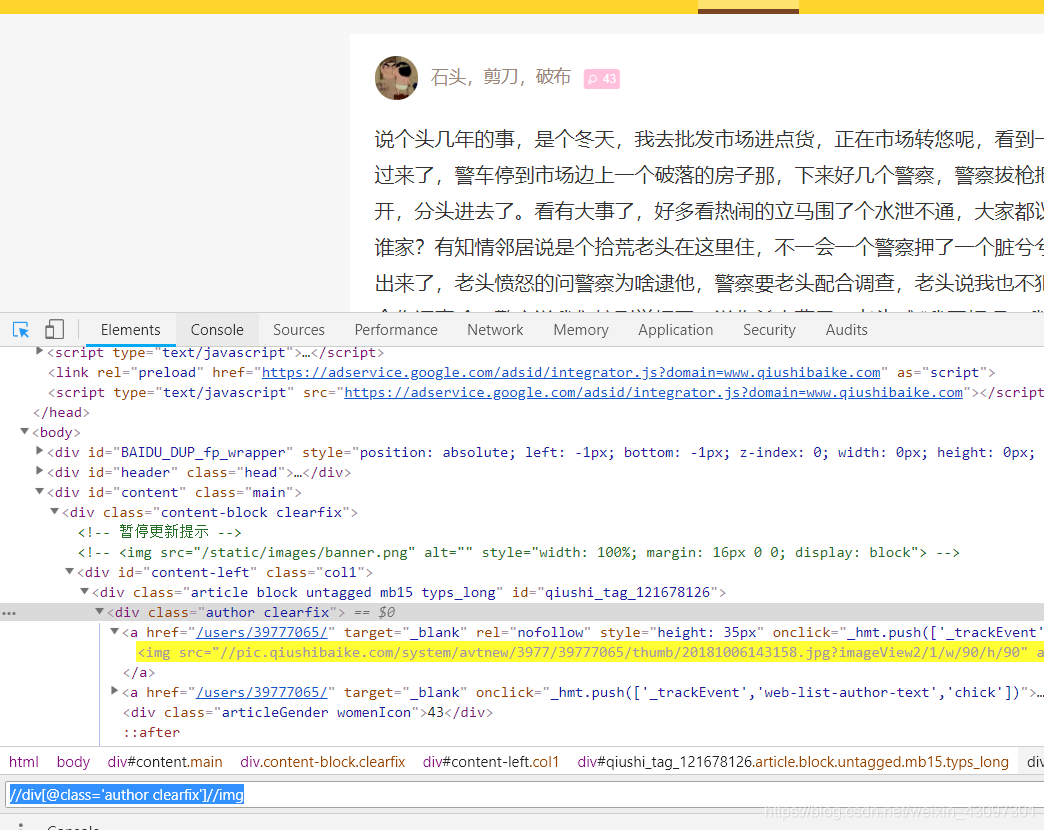
extract() 输出匹配内容
head_photo = i.xpath("//div[@class=‘author clearfix’]//img/@src")[n].extract()
#n为下标,因为返回的是列表,
# -*- coding: utf-8 -*-
import scrapy
class OneSpiderSpider(scrapy.Spider):
name = 'one_spider' # 自定义的爬虫名字
allowed_domains = ['www.qiushibaike.com'] # 允许爬取的域名,限制爬取的范围必须为域名下的,可以为多个
start_urls = ['https://www.qiushibaike.com/hot/'] #给定一个起始的url
def parse(self, response): #parse解析函数,这是一个父类的方法,这里就是重写这个方法
#参数response就是响应后的内容
#这里必须返回一个可迭代对象(生成器,列表等)
div_list = response.xpath("//div[@id='content-left']/div")
# div_listli 放的是selector(选择器)对象< Selector xpath = "//div[@id='content-left']/div" data = '<div class="article block untagged mb15 ' >
item_dates=[]
print("-------------------------------------")
for i in div_list:
head_photo = i.xpath(".//div[@class='author clearfix']//img/@src").extract() # 获取头像
head_name = i.xpath(".//div[@class='author clearfix']//h2/text()").extract() # 获取名字
item_date={
"头像":head_photo,
"用户名": head_name,
}
item_dates.append(item_date)
return item_dates
print("-------------------------------------")
4.将数据输出指定格式的文件
注意要在setting文件中配置编码方式:
FEED_EXPORT_ENCODING = 'utf-8'
【不设置会造成错乱,详情:https://blog.csdn.net/weixin_43097301/article/details/89099834】
cmd命令行:
scrapy crawl 爬虫名字 -o 自定义文件名.格式
默认文件放在spiders目录下
scrapy输出格式
json 类型:scrapy crawl one_spider -o one_spider.json
xml 类型:scrapy crawl one_spider -o one_spider.xml
csv 类型:scrapy crawl one_spider -o one_spider.csv
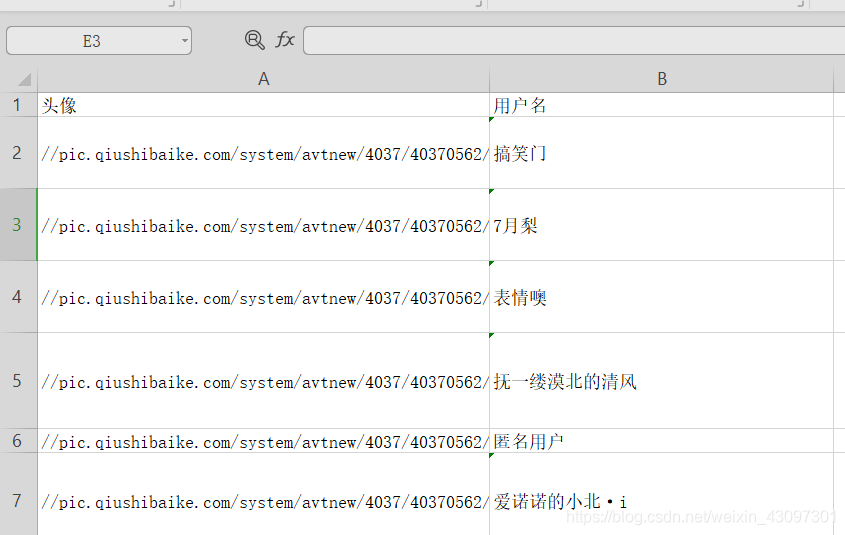
例如:csv格式
2.scrapy shell(Scrapy终端)
1.scrapy shell
scrapy shell调试工具,常用来调试xpath
Scrapy终端是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。 其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码。
该终端是用来测试XPath或CSS表达式,查看他们的工作方式及从爬取的网页中提取的数据。 在编写您的spider时,该终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。
2.安装
1.ipython库:pip install ipython
相对于cmd Python中书写代码 来说 更加智能 的交互环境(tab 键 提示代码)
默认启动时打印日志:
scrapy shell "https://www.qiushibaike.com/hot/"
或者不打印日志:
scrapy shell 'https://www.qiushibaike.com/hot/' --nolog
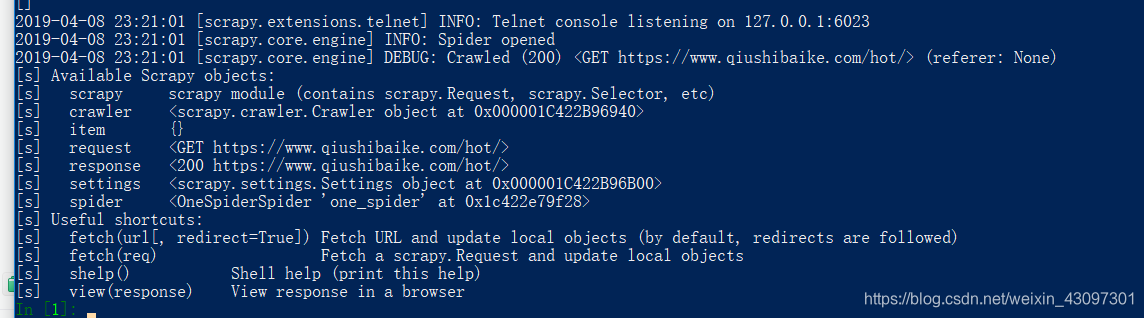
这样就说明成功进入了
3.response
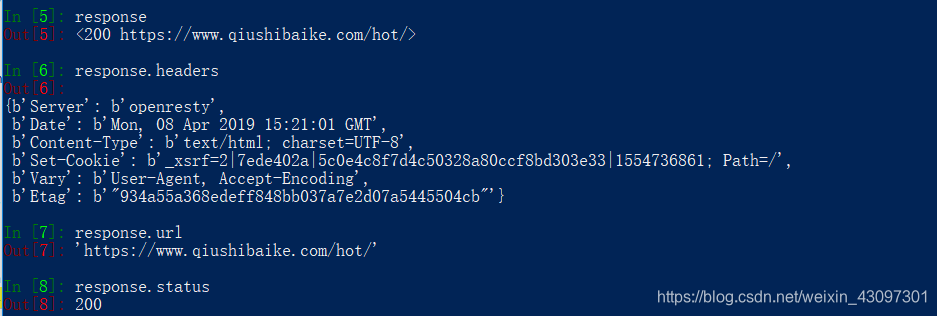
1.response属性:
text: 字符串类型
body: 字节类型
url: 请求的url
status: 响应的状态码
headers: 响应头


2.方法
xpath(): 提取出来的都是selector(选择器)对象,需要进行extract()提取内容
css(): 根据选择器进行获取指定的内容
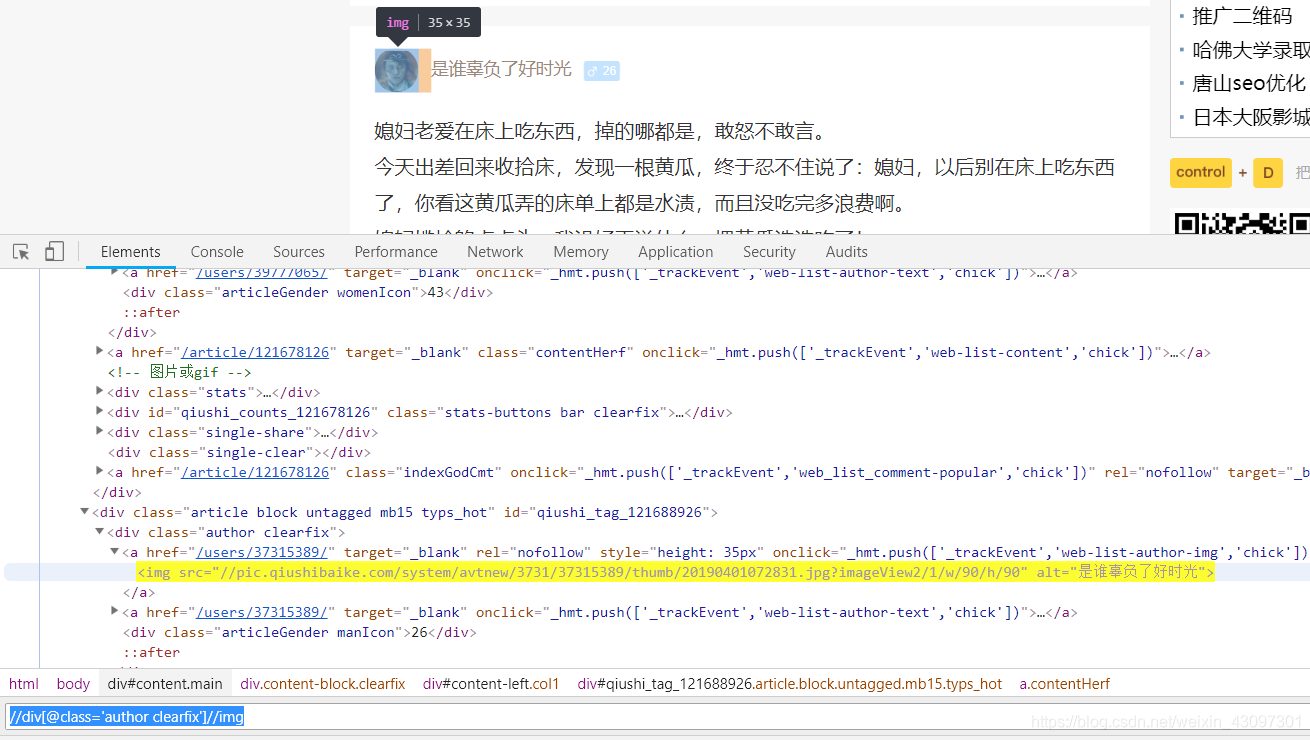
抓取页面头像
spath():
response.xpath("//div[@class=‘author clearfix’]//img")

css():
msg = response.css("#content-left > div > .author img")

这里因为之前爬虫匹配过,就是25个头像,所以直接判断len就行了。可以看出两种都是可以的
如果我们要获取src连接:
spath():
response.xpath("//div[@class=‘author clearfix’]//img/@src")

css():
response.css("#content-left > div > .author img::attr(src)")
注意:这种获取属性的方式只能在scrapy中使用,bs中不能

如果我们要获取的为文本内容而不是属性时
页面不同时间内容都在变,所以抓取的内容以实际为准
spath():
response.xpath("//div[@class=‘author clearfix’]//img/@src")

css():
response.css("#content-left > div > .author h2::text")

4,selector对象
是scrapy自己封装的一个对象,不论你上面使用过xpathhaishi css,获取的都是这个对象
xpath()
css()
extract(): 将selector对象转化为字符串
extract_first(): 功能就等同于 selector对象 .extract_first() =selector对象[0].extract()=selector对象.extract()[0]
但是,如果xpath和 css 匹配错误,则xpath和css 会报错,而extract_first不会,内容为null
5.item对象
爬取数据的时候,第一步要定义数据结构,在items.py中定义
通过这个类创建的对象非常特殊,这个对象使用的时候类似字典,但不是字典

class FirstWorkItem(scrapy.Item):
name = scrapy.Field()
age = scrapy.Field()
#使用如上图:
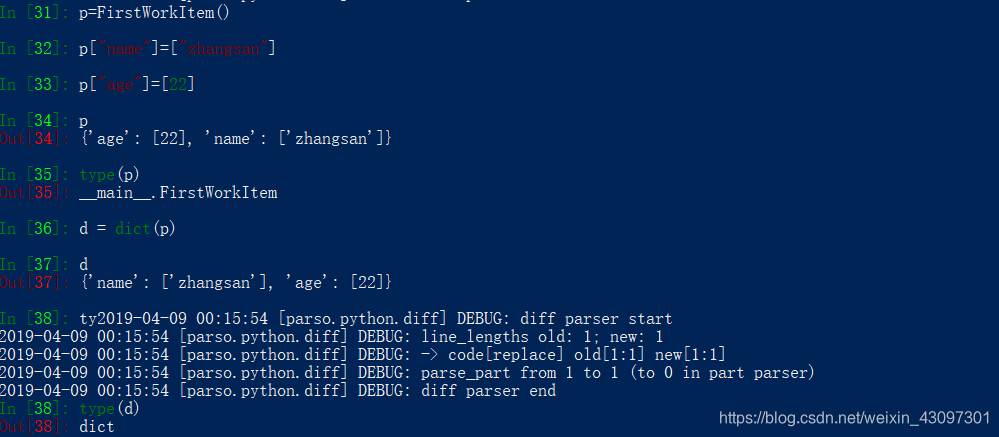
p["name"]=["zhangsan"] #赋值
p["age"]=[22]
p["age"] #取值
p["name"]
d = dict(p) #转化字典
**6.yield **
yield 生成器 :https://blog.csdn.net/weixin_43097301/article/details/84762006
3.用scrapy爬取糗事百科
打开cmd (命令窗口 , 或者 git), cd 到所要创建项目的目录下,
scrapy startproject first_work
cd first_work(新建的项目)
scrapy genspider one_spider(自己爬虫的名称) www.qiushibaike.com(爬取的网站)
1.首先配置一下settings.py
https://blog.csdn.net/weixin_43097301/article/details/89079270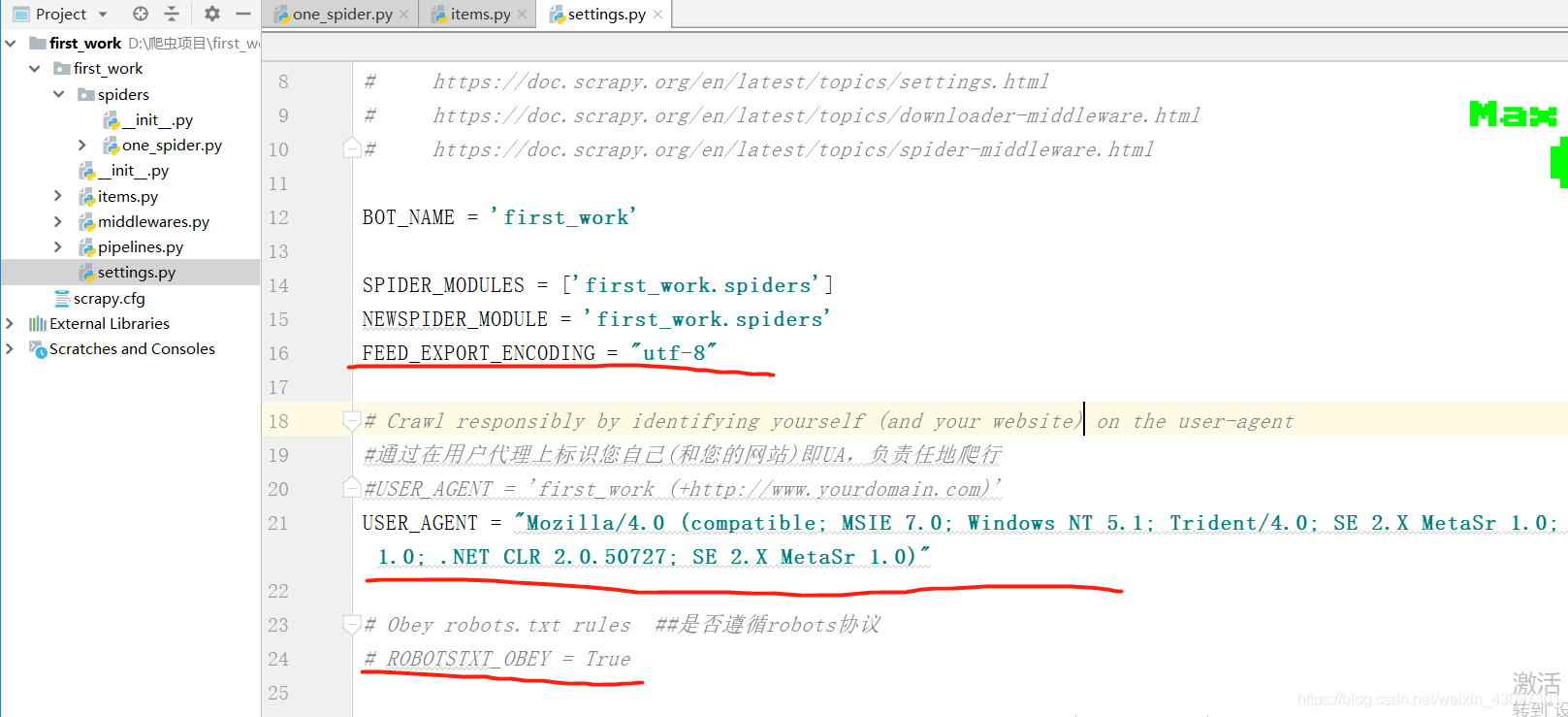
浏览器UA:https://blog.csdn.net/weixin_43097301/article/details/89079270


2.需求实现
获取头像,用户名,用户年龄,内容,好笑点赞数,评论的个数
1.定义数据结构:
# -*- coding: utf-8 -*-
# https://doc.scrapy.org/en/latest/topics/items.html
#items.py文件
import scrapy
class FirstWorkItem(scrapy.Item):
# define the fields for your item here like:
#在这里为您的项目定义字段,如下所示:
# name = scrapy.Field()
chat_head = scrapy.Field() #头像
user_name = scrapy.Field() #用户名
user_age = scrapy.Field() #用户年龄
content = scrapy.Field() #内容
funny_num = scrapy.Field() #好笑点赞数
comment_num = scrapy.Field() #评论的个数
2.爬取内容
# -*- coding: utf-8 -*-
#one_spider.py文件
import scrapy
from first_work.items import FirstWorkItem #导入itemes数据结构
class OneSpiderSpider(scrapy.Spider):
name = 'one_spider' # 自定义的爬虫名字
allowed_domains = ['www.qiushibaike.com'] # 允许爬取的域名,限制爬取的范围必须为域名下的,可以为多个
start_urls = ['https://www.qiushibaike.com/hot/'] #给定一个起始的url
url = "https://www.qiushibaike.com/hot/page/{
}/"
page = 1 #爬取多页
def parse(self, response): #parse解析函数,这是一个父类的方法,这里就是重写这个方法
#参数response就是响应后的内容
#这里必须返回一个可迭代对象(生成器,列表等)
div_list = response.xpath("//div[@id='content-left']/div")
# div_listli 放的是selector(选择器)对象< Selector xpath = "//div[@id='content-left']/div" data = '<div class="article block untagged mb15 ' >
for i in div_list:
#获取头像,用户名,用户年龄,内容,好笑点赞数,评论的个数
#extract_first(): 功能就等同于 selector对象 .extract_first() =selector对象[0].extract()=selector对象.extract()[0]
# 但是,如果xpath和 css 匹配错误,则xpath和css 会报错,而extract_first不会,内容为null
chat_head = i.xpath(".//div[@class='author clearfix']//img/@src").extract_first() # 获取头像
chat_head = "https:" +chat_head
user_name = i.xpath(".//div[@class='author clearfix']//h2/text()").extract_first() # 获取名字
user_name = user_name.strip("\n")
user_age = i.xpath(".//div[@class='author clearfix']//div/text()").extract_first() #获取年龄
content = i.xpath(".//div[@ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









