









1. Seata 简介
1.1 什么是 Seata
Seata(Simple Extensible Autonomous Transaction Architecture)是一个开源的分布式事务解决方案,旨在解决分布式系统中跨多个服务或数据库的事务一致性问题。由阿里巴巴于 2019 年开源,Seata 的设计目标是提供一个简单且高效的全局事务管理框架,使得开发者能够在微服务架构中轻松处理分布式事务。它主要包括三个核心组件:Transaction Coordinator (TC)、Transaction Manager ™、和 Resource Manager (RM)。
1.2 Seata 的应用场景
Seata 主要应用于以下场景:
-
跨数据库的事务管理:在一个系统中,有可能存在多个独立的数据库。Seata 能够保证在多个数据库操作中的一致性,确保数据不会因网络问题或服务失败而不一致。
-
跨服务的事务管理:在微服务架构下,服务间调用复杂,且每个服务可能会更新不同的数据源。Seata 通过全局事务管理,保证了服务间的原子性操作。
-
跨集群的事务管理:在分布式环境下,多个集群中的数据一致性问题同样难以解决。Seata 能够支持集群环境下的事务,适用于高可用和高并发的应用场景,如电商、支付系统等。
1.3 分布式事务的常见挑战
在分布式系统中,实现事务一致性会遇到诸多挑战:
-
数据一致性:分布式系统中的数据分布在不同节点上,需要确保在出现网络延迟、节点故障或服务异常时,所有节点的数据保持一致。
-
网络延迟与故障:网络环境复杂,延迟和故障频发,传统的事务模型难以适应分布式场景下的各种异常情况,容易导致数据丢失或不一致。
-
CAP 理论的限制:根据 CAP 理论,分布式系统无法同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)。分布式事务解决方案需要在 CAP 理论的约束下做出权衡,通常会牺牲一定的可用性来确保数据一致性。
-
事务的隔离性:不同服务间的数据访问容易发生冲突,需要对事务隔离性进行有效管理,以避免数据污染。
Seata 提供了多种事务模型,包括 AT 模式(自动补偿事务)、TCC 模式(Try-Confirm-Cancel)、SAGA 模式和 XA 模式,为不同场景下的分布式事务需求提供灵活的选择。
2. Seata 架构解析
Seata 采用模块化的架构设计,主要包括三个核心组件:Transaction Coordinator (TC)、Transaction Manager ™、Resource Manager (RM)。这些组件协同工作,通过协调不同服务或数据库间的分布式事务,保证数据一致性。
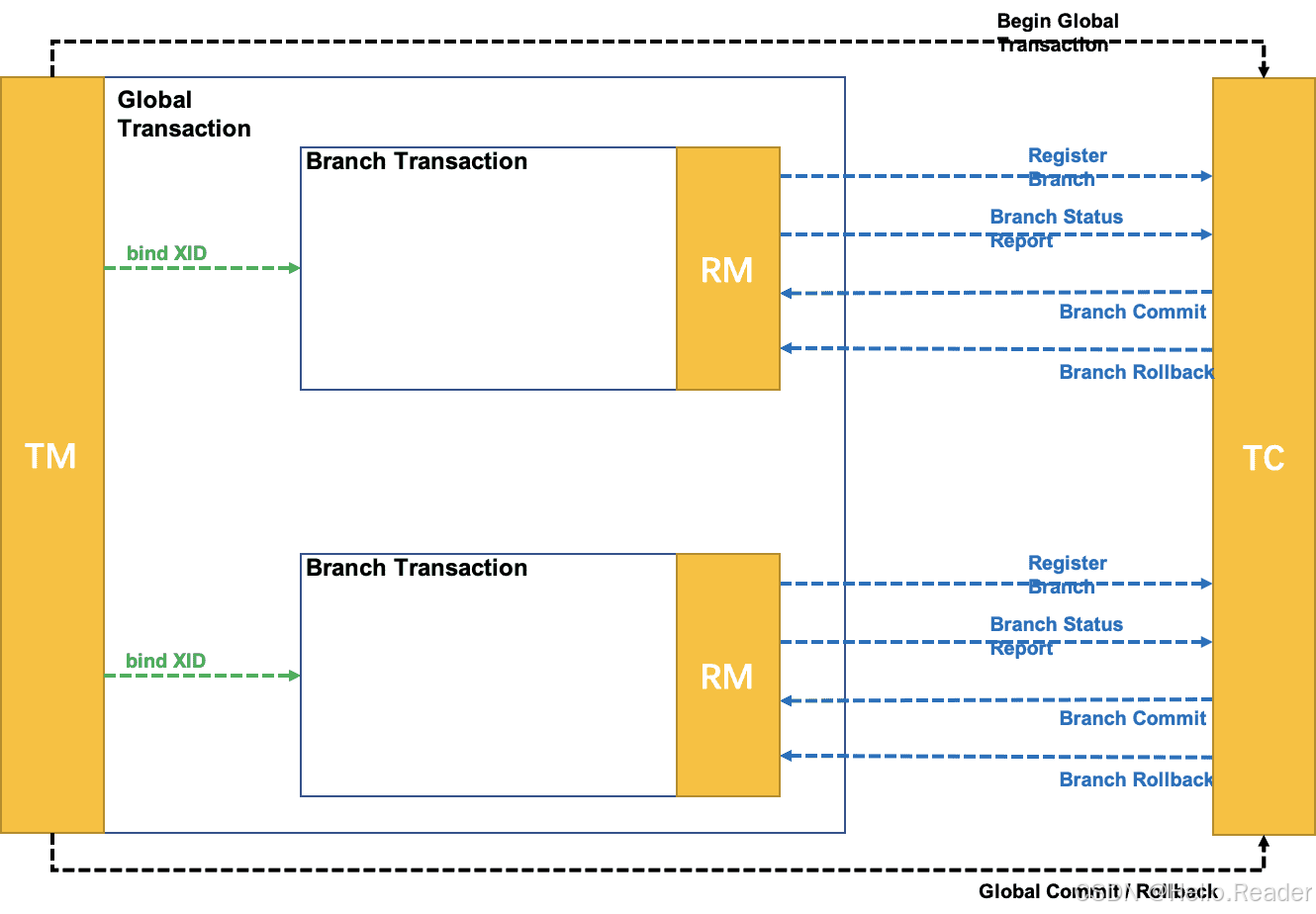
2.1 Seata 的基本架构
Seata 的架构基于全局事务的管理机制,主要包括以下部分:
- 事务协调器(Transaction Coordinator, TC):负责维护全局事务的状态,并协调事务的提交或回滚。
- 事务管理器(Transaction Manager, TM):负责定义和发起全局事务。
- 资源管理器(Resource Manager, RM):负责管理分支事务(Branch Transaction),并与本地数据库资源交互,确保各个分支事务的提交和回滚操作。
这种架构设计使 Seata 能够在微服务环境中有效地管理分布式事务,确保不同数据库和服务之间的数据一致性。
2.2 主要组件:TC、TM、RM
-
Transaction Coordinator (TC)
- 职责:负责全局事务的协调和管理,维护全局事务的状态,并跟踪每个分支事务的执行情况。
- 作用:TC 的作用类似于一个事务控制中心,在分布式事务的生命周期中决定各分支事务的提交或回滚操作。
- 运行方式:TC 通常作为独立服务运行,以保证高可用性和可靠性。
-
Transaction Manager ™
- 职责:TM 是事务的发起者,负责定义全局事务的边界(开始和结束),并通知 TC 启动或结束事务。
- 作用:每当一个业务需要分布式事务时,TM 会发起全局事务请求,并在事务结束时通知 TC 提交或回滚。
- 运行方式:TM 通常作为微服务中的一个组件,随业务应用一起部署,负责触发和管理分布式事务。
-
Resource Manager (RM)
- 职责:RM 管理分支事务,负责实际的资源操作(如数据库操作)以及向 TC 报告分支事务的执行情况。
- 作用:RM 与数据库等资源直接交互,确保事务过程中数据的提交或回滚操作。
- 运行方式:RM 也通常作为微服务中的一个组件,和应用服务一起运行,与本地资源交互。
2.3 Seata 的工作原理
Seata 的分布式事务管理通过以下步骤实现:
-
全局事务开始:当 TM 发起一个全局事务时,TC 创建一个全局事务 ID,并将该事务状态设置为“开始”状态。
-
注册分支事务:在全局事务的生命周期内,多个服务会分别执行属于自己的本地事务(即分支事务)。每个分支事务在执行前需要向 TC 注册,并绑定到全局事务 ID 上。
-
分支事务执行:每个服务的 RM 负责管理分支事务的执行,并与本地资源交互。执行完成后,RM 会向 TC 报告分支事务的执行结果。
-
全局提交或回滚:
- 提交:当所有分支事务都执行成功时,TM 通知 TC 提交事务,TC 依次通知各 RM 提交其分支事务。
- 回滚:如果任一分支事务执行失败或出现异常,TM 通知 TC 回滚事务,TC 会依次通知各 RM 进行回滚操作。
-
事务结束:TC 在收到所有分支事务的提交或回滚确认后,将全局事务状态标记为结束。
3. Seata 事务模式
Seata 提供了多种事务模式,以满足不同业务场景的分布式事务需求。这些模式包括 AT 模式、TCC 模式、SAGA 模式和 XA 模式。每种模式在事务执行、补偿机制和一致性保证方面有所不同。
3.1 AT 模式(Automatic Transaction)
- 简介:AT 模式是一种自动补偿事务模式,适合在关系型数据库中自动生成 SQL 的场景。它简化了事务管理,自动处理分支事务的回滚。
- 工作原理:
- 提交阶段:在业务操作成功时,事务直接提交。Seata 会生成提交 SQL 并执行。
- 回滚阶段:如果业务操作失败或全局事务需要回滚,Seata 根据在事务开始时记录的“快照”生成回滚 SQL,并将数据恢复到事务开始前的状态。
- 优点:易于使用,无需额外开发事务补偿逻辑。
- 缺点:主要适用于关系型数据库,适用范围受限,适合短事务。
3.2 TCC 模式(Try-Confirm-Cancel)
- 简介:TCC 模式提供了精细控制的分布式事务解决方案,每个分支事务定义了三个操作步骤:Try、Confirm 和 Cancel。适合复杂业务场景。
- 工作原理:
- Try 阶段:执行资源预留操作,确保业务资源能够执行后续操作。
- Confirm 阶段:提交资源,完成业务操作。如果 Try 阶段成功但全局事务提交,则执行 Confirm 操作。
- Cancel 阶段:释放资源并回滚操作。如果全局事务需要回滚,则执行 Cancel 操作撤销资源占用。
- 优点:能够处理复杂业务场景,实现精细的事务控制。
- 缺点:需要业务开发人员手动实现 Try、Confirm 和 Cancel 逻辑,增加了开发成本。
3.3 SAGA 模式
- 简介:SAGA 模式是一种基于长事务补偿的事务模型,适合长时间运行的事务。SAGA 模式将事务拆分为多个有序的子事务,保证每个子事务独立完成。
- 工作原理:
- 事务执行阶段:SAGA 模式将事务拆分为多个子事务,顺序执行,每个子事务执行完成后即提交。
- 补偿机制:如果某个子事务失败或出现异常,SAGA 会执行已完成子事务的补偿操作(反向操作),将系统恢复到初始状态。
- 优点:适用于长时间事务操作,降低了锁定资源的时间,提高系统吞吐量。
- 缺点:需要手动编写补偿逻辑,补偿机制复杂且不保证强一致性(仅最终一致性)。
3.4 XA 模式
- 简介:XA 模式是基于两阶段提交协议的分布式事务模式。该模式符合数据库的 XA 标准,通常用于支持 XA 事务的数据库环境。
- 工作原理:
- 第一阶段(准备阶段):每个参与的数据库先将操作写入本地日志,但不提交,等待事务协调者的指令。
- 第二阶段(提交阶段):协调者根据各数据库的准备情况决定是否提交。如果所有数据库都准备完成,事务将被提交;否则,事务将回滚。
- 优点:实现强一致性,适用于高一致性要求的场景。
- 缺点:由于锁住资源直到事务完成,可能会降低并发性能;XA 模式依赖于数据库的支持。
| 事务模式 | 场景 | 一致性 | 优缺点 |
|---|---|---|---|
| AT 模式 | 关系型数据库的短事务 | 强一致性 | 简化事务管理,自动 SQL 生成 |
| TCC 模式 | 复杂业务场景 | 强一致性 | 灵活性高,但开发成本高 |
| SAGA 模式 | 长事务、最终一致性 | 最终一致性 | 适合长时间运行的事务,需补偿逻辑 |
| XA 模式 | 高一致性要求 | 强一致性 | 数据库支持的两阶段提交,资源锁定时间长 |
4. Seata 的核心概念
在 Seata 的分布式事务管理中,理解以下核心概念对于掌握其工作原理至关重要:
4.1 全局事务 ID(XID)
全局事务 ID(XID)是 Seata 用于标识一个全局事务的唯一标识符。当事务管理器(TM)发起一个全局事务时,事务协调器(TC)会生成一个唯一的 XID,并在整个事务过程中进行传播。XID 的作用类似于传统数据库事务的事务 ID,但在分布式环境中,它用于关联多个分支事务,确保它们属于同一个全局事务。
XID 的结构通常包含以下部分:
- 全局事务 ID:由 TC 生成的唯一标识符。
- 分支事务 ID:由资源管理器(RM)在注册分支事务时生成,用于标识具体的分支事务。
通过 XID,Seata 能够在分布式系统中跟踪和管理全局事务及其关联的分支事务,确保事务的一致性和完整性。
4.2 全局锁
全局锁是 Seata 在分布式事务中实现数据一致性的重要机制。它用于防止多个全局事务同时修改同一数据,避免数据冲突和不一致。在 Seata 的 AT 模式下,全局锁的实现方式如下:
-
锁定机制:当一个分支事务执行更新操作时,Seata 会在本地事务提交前,向 TC 申请获取全局锁。如果获取成功,则允许提交本地事务;如果获取失败,则需要等待或回滚。
-
锁的粒度:全局锁的粒度通常是数据库中的行级别,即锁定特定记录。这有助于提高并发性能,减少锁冲突。
-
锁的管理:TC 负责管理全局锁的状态,确保同一时间只有一个全局事务持有特定数据的全局锁。
通过全局锁机制,Seata 能够在分布式环境中有效地控制并发访问,确保数据的一致性和完整性。
4.3 分支事务(Branch Transaction)和全局事务(Global Transaction)的关系
在 Seata 的架构中,全局事务和分支事务的关系如下:
-
全局事务(Global Transaction):由 TM 发起,代表一个跨多个服务或数据库的分布式事务。全局事务由 TC 进行管理,确保其一致性和完整性。
-
分支事务(Branch Transaction):在全局事务的上下文中,各服务或数据库执行的本地事务称为分支事务。每个分支事务由对应的 RM 管理,并与全局事务关联。
全局事务和分支事务的关系可以概括为:
-
关联关系:一个全局事务包含多个分支事务,每个分支事务在执行前需要向 TC 注册,并获取唯一的分支事务 ID,与全局事务的 XID 关联。
-
执行流程:当全局事务提交或回滚时,TC 会根据各分支事务的执行结果,协调它们的提交或回滚操作,确保全局事务的一致性。
-
状态管理:TC 维护全局事务和分支事务的状态,跟踪它们的执行进度,并在必要时进行重试或补偿操作。
5. Seata 数据一致性机制
在分布式系统中,确保数据一致性是关键挑战之一。Seata 通过读写隔离策略、锁定机制和数据回滚与恢复等手段,保障分布式事务中的数据一致性。
5.1 读写隔离策略
Seata 的 AT 模式在数据库本地事务隔离级别为读已提交(Read Committed)或以上的基础上,默认全局隔离级别为读未提交(Read Uncommitted)。这意味着在全局事务未提交之前,其他事务可能读取到未提交的数据。如果应用在特定场景下需要全局的读已提交隔离级别,Seata 提供了全局锁机制来实现。通过代理 SELECT FOR UPDATE 语句,Seata 确保在获取全局锁之前,查询操作被阻塞,直到读取到已提交的数据。
5.2 锁定机制
Seata 的锁定机制主要体现在全局锁的设计上。在 AT 模式下,Seata 使用全局写排他锁来保证事务间的写隔离。在本地事务提交前,Seata 会尝试获取全局锁,确保同一时间只有一个全局事务对特定数据进行修改。如果获取全局锁失败,本地事务将回滚,并重试获取全局锁,直到成功为止。这种机制有效防止了脏写问题,确保数据的一致性。
5.3 数据回滚与恢复
在 AT 模式下,Seata 通过记录回滚日志(undo_log)来实现数据的回滚与恢复。在本地事务执行过程中,Seata 会在同一个本地事务中记录业务数据和回滚日志。如果全局事务需要回滚,Seata 会根据回滚日志进行反向补偿操作,将数据恢复到初始状态。这种设计确保了在事务回滚时,数据能够准确恢复,维护数据的一致性。
6. Seata 的配置与部署
Seata 是一个开源的分布式事务解决方案,旨在解决微服务架构下的数据一致性问题。为了在项目中有效地应用 Seata,需要正确配置其相关文件、数据源,并选择合适的部署方式。
6.1 基本配置文件说明
Seata 的配置文件主要用于设置注册中心、配置中心、存储模式等参数。通常,Seata Server 的配置文件位于 seata-server/conf 目录下,主要包括:
registry.conf:用于配置注册中心的信息,如类型(nacos、eureka、zk等)和相应的地址。file.conf:用于配置存储模式(如db、file)以及相应的数据库连接信息。
在 registry.conf 中,常见的配置项包括:
registry:
type: nacos
nacos:
serverAddr: 127.0.0.1:8848
namespace: seata
cluster: default
在 file.conf 中,常见的配置项包括:
store:
mode: db
db:
datasource: druid
dbType: mysql
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/seata
user: root
password: password
这些配置项用于指定 Seata Server 的注册中心类型、地址,以及事务日志的存储方式和数据库连接信息。
6.2 数据源的配置
在使用 Seata 时,需要对应用程序的数据源进行配置,以确保 Seata 能够正确地代理数据源,实现分布式事务管理。如果使用 Spring Boot,可以在 application.yml 或 application.properties 文件中进行配置。
常见的配置项包括:
seata:
enabled: true
tx-service-group: my_tx_group
enable-auto-data-source-proxy: true
use-jdk-proxy: false
enabled:是否启用 Seata。tx-service-group:事务服务组名称,需要与 Seata Server 的配置一致。enable-auto-data-source-proxy:是否启用数据源自动代理。use-jdk-proxy:是否使用 JDK 动态代理,默认为false,即使用 CGLIB 代理。
需要注意的是,Seata 默认会开启数据源自动代理功能。如果项目中使用了多数据源或自定义的数据源代理机制,可能需要关闭 Seata 的自动代理功能,以避免冲突。可以通过设置 seata.enable-auto-data-source-proxy=false 来关闭自动代理功能。
6.3 Seata 的部署方式:单机和集群模式
根据项目的规模和需求,Seata 可以采用单机模式或集群模式进行部署。
-
单机模式:适用于开发和测试环境,部署简单。在单机模式下,Seata Server 作为一个独立的进程运行,所有的事务协调都在本地完成。
-
集群模式:适用于生产环境,提供高可用性和负载均衡。在集群模式下,部署多个 Seata Server 实例,并通过注册中心(如 Nacos、Eureka)进行服务注册和发现,实现负载均衡和故障转移。
在集群模式下,需要在 registry.conf 中配置注册中心的信息,以便各个 Seata Server 实例能够相互通信。例如,使用 Nacos 作为注册中心时,配置如下:
registry:
type: nacos
nacos:
serverAddr: 127.0.0.1:8848
namespace: seata
cluster: default
7. Seata 与 Spring 的集成
在微服务架构中,Seata 可以与 Spring Boot 无缝集成,实现分布式事务管理。通过使用注解和配置,开发者可以方便地管理全局事务,确保数据一致性。
7.1 Spring Boot 下的 Seata 集成
要在 Spring Boot 项目中集成 Seata,需要按照以下步骤进行:
-
添加依赖:在项目的
pom.xml文件中,引入 Seata 的相关依赖。<dependency> <groupId>io.seata</groupId> <artifactId>seata-spring-boot-starter</artifactId> <version>1.5.2</version> </dependency> -
配置 Seata:在
application.yml或application.properties文件中,添加 Seata 的相关配置。seata: enabled: true application-id: your-application-name tx-service-group: your-tx-service-group enable-auto-data-source-proxy: true service: vgroup-mapping: your-tx-service-group: default enable-degrade: false disable-global-transaction: false registry: type: nacos nacos: server-addr: 127.0.0.1:8848 namespace: your-namespace config: type: nacos nacos: server-addr: 127.0.0.1:8848 namespace: your-namespace上述配置中,需要根据实际情况填写
application-id、tx-service-group、nacos的server-addr和namespace等信息。 -
配置数据源代理:Seata 需要代理数据源以实现分布式事务管理。如果使用的是 Druid 数据源,可以在
application.yml中进行如下配置:spring: datasource: druid: url: jdbc:mysql://127.0.0.1:3306/your_database username: your_username password: your_password driver-class-name: com.mysql.cj.jdbc.Driver同时,确保 Seata 的数据源代理功能已启用:
seata: enable-auto-data-source-proxy: true如果使用其他数据源,请参考相应的配置方式。
7.2 使用注解管理 Seata 事务
在 Spring Boot 项目中,可以使用 Seata 提供的注解来管理全局事务。主要的注解有:
-
@GlobalTransactional:用于标注全局事务的入口方法。当该方法被调用时,Seata 会开启一个全局事务,并在方法执行完毕后根据执行结果决定提交或回滚全局事务。import io.seata.spring.annotation.GlobalTransactional; import org.springframework.stereotype.Service; @Service public class OrderService { @GlobalTransactional public void createOrder(Order order) { // 业务逻辑 } }在上述示例中,
createOrder方法被@GlobalTransactional注解标注,表示该方法的执行将被 Seata 管理为一个全局事务。 -
@GlobalLock:用于在查询方法上加锁,防止脏读。当该注解标注的方法被调用时,Seata 会在执行查询前获取全局锁,确保数据的一致性。import io.seata.spring.annotation.GlobalLock; import org.springframework.stereotype.Service; @Service public class ProductService { @GlobalLock public Product getProductById(Long productId) { // 查询逻辑 } }在上述示例中,
getProductById方法被@GlobalLock注解标注,表示在执行查询前,Seata 会获取全局锁,防止脏读。
7.3 配置示例与最佳实践
在实际项目中,集成 Seata 时需要注意以下最佳实践:
-
配置事务分组:确保
tx-service-group的配置在 Seata Server 和客户端一致,以便正确识别和管理全局事务。 -
配置注册中心和配置中心:如果使用 Nacos 作为注册中心和配置中心,需要在
registry.conf和file.conf中正确配置 Nacos 的地址和命名空间。 -
配置数据源代理:确保 Seata 能够正确代理数据源,以实现分布式事务管理。如果使用多数据源,可能需要关闭 Seata 的自动代理功能,并手动配置代理。
-
使用注解管理事务:在需要全局事务管理的方法上使用
@GlobalTransactional注解,确保 Seata 能够正确管理事务的提交和回滚。 -
处理异常:在全局事务方法中,捕获并处理可能的异常,确保在发生异常时,Seata 能够正确回滚事务,保持数据一致性。
8. Seata 与数据库的交互
Seata 在分布式事务管理中,通过自动 SQL 解析、数据库锁定机制和回滚日志的存储,与数据库进行深度交互,确保数据的一致性和完整性。
8.1 AT 模式下的自动 SQL 解析
在 AT(Automatic Transaction)模式下,Seata 通过拦截并解析业务 SQL,自动生成相应的回滚 SQL,实现事务的自动补偿。其工作流程如下:
-
解析业务 SQL:Seata 拦截业务层执行的 SQL 语句,解析其类型(如 INSERT、UPDATE、DELETE)、操作的表名和条件等信息。
-
获取数据镜像:
- 前镜像(Before Image):在执行业务 SQL 之前,查询并记录受影响数据的当前状态。
- 后镜像(After Image):执行业务 SQL 后,再次查询并记录受影响数据的状态。
-
生成回滚日志:根据前后镜像的数据,生成回滚所需的 SQL 语句,并将这些信息存储在
undo_log表中。
通过上述步骤,Seata 能够在事务回滚时,根据 undo_log 中的记录,自动生成并执行回滚 SQL,将数据恢复到事务开始前的状态。
8.2 数据库锁与回滚日志的存储
在 AT 模式下,Seata 通过以下机制确保数据一致性:
-
全局锁:在本地事务提交前,Seata 会尝试获取全局锁,确保同一时间只有一个全局事务对特定数据进行修改。如果获取全局锁失败,本地事务将回滚,并重试获取全局锁,直到成功为止。这种机制有效防止了脏写问题,确保数据的一致性。
-
回滚日志的存储:Seata 在每个参与分支事务的数据库中创建
undo_log表,用于存储回滚所需的信息。当事务需要回滚时,Seata 根据undo_log中的记录,生成并执行回滚 SQL,将数据恢复到初始状态。回滚日志的存储和管理对于事务的正确回滚至关重要。
8.3 多种数据库支持的情况
Seata 设计为与多种关系型数据库兼容,包括但不限于:
- MySQL
- PostgreSQL
- Oracle
- SQL Server
- MariaDB
在不同的数据库环境中,Seata 的工作机制基本一致,但在具体实现上可能会有细微差异。例如,undo_log 表的结构可能会根据数据库的特性进行调整。在使用 Seata 时,需要根据所使用的数据库类型,进行相应的配置和调整,以确保其正常运行。
9. Seata 的故障恢复机制
在分布式系统中,故障的发生是不可避免的。Seata 通过一系列机制,确保在故障发生时,系统能够自动恢复,保持数据一致性和事务完整性。
9.1 Seata 的失败恢复策略
Seata 设计了多层次的失败恢复策略,以应对不同类型的故障:
-
Session 状态管理:Seata 通过在集群中的各个节点之间复制 Session 状态,确保即使某个节点失效,其他节点仍然能够接管事务的管理。此外,Seata 可以将 Session 状态持久化到外部存储系统(如关系型数据库或 NoSQL 存储),以便在整个集群重启时,从持久化的 Session 状态中恢复事务。
-
故障检测与恢复:Seata 使用心跳检测机制来监控集群成员的状态。当某个节点长时间未响应心跳时,其他节点可以将其视为故障节点,并采取相应的措施(如重新选举主节点)。
-
重试机制:对于某些可恢复的故障(如网络抖动导致的短暂连接中断),Seata 可以配置自动重试机制,即在第一次操作失败后自动尝试再次执行该操作。
9.2 超时与重试机制
Seata 提供了灵活的超时与重试机制,以应对网络延迟、服务响应缓慢等情况:
-
全局事务超时:Seata 的默认全局事务超时时间是1分钟。当 Seata-server 检测到有超时的全局事务时,会向所有已提交的分支发起回滚。
-
重试策略:Seata 支持配置重试策略,包括重试次数、重试间隔等,以确保在遇到暂时性故障时能够有足够的时间和机会来恢复正常。
9.3 全局事务与分支事务的补偿
在 Seata 的事务模型中,全局事务由多个分支事务组成。为了确保事务的一致性,Seata 实现了以下补偿机制:
-
分支事务的回滚:当全局事务需要回滚时,Seata 会通知所有相关的 RM 回滚分支事务,RM 根据之前记录的快照数据进行数据回滚,恢复到初始状态。
-
全局事务的补偿:通过持久化 Session 状态,Seata 可以在重启或故障恢复时从存储系统中加载之前的事务状态,继续处理未完成的事务。
10. Seata 的性能优化
在分布式事务管理中,性能是关键考量因素。Seata 通过分析性能瓶颈、优化缓存策略和分布式锁,以及有效处理事务并发,提升整体性能。
10.1 性能瓶颈分析
Seata 的性能瓶颈主要集中在以下方面:
-
网络延迟:在分布式环境中,网络通信的延迟会影响事务的响应时间。
-
数据库操作:频繁的数据库读写操作,尤其是回滚日志的记录和查询,可能导致性能下降。
-
全局锁竞争:多个事务同时访问相同资源时,可能出现全局锁竞争,导致事务等待和性能降低。
针对这些瓶颈,需要采取相应的优化措施。
10.2 缓存策略和分布式锁优化
为了提升性能,Seata 在缓存策略和分布式锁方面进行了优化:
-
缓存策略:Seata 通过引入本地缓存,减少对数据库的直接访问,降低延迟。例如,在事务协调器(TC)中缓存全局事务的状态信息,减少对持久化存储的频繁读取。
-
分布式锁优化:Seata 在 AT 模式下使用全局锁机制来保证事务隔离性。为了减少锁冲突,Seata 优化了锁的粒度和获取策略。例如,针对
SELECT FOR UPDATE语句,Seata 通过代理机制实现全局锁的获取,避免了数据库层面的锁竞争。
10.3 事务并发的处理
Seata 通过以下方式有效处理事务并发,提升系统吞吐量:
-
异步提交:在分支事务提交时,Seata 支持异步提交策略,减少事务等待时间,提高并发性能。
-
批量处理:对于大量的分支事务,Seata 支持批量提交和回滚,减少网络通信次数,提升效率。
-
隔离级别调整:根据业务需求,适当调整事务的隔离级别,权衡一致性和性能。例如,在某些场景下,可以将全局事务的隔离级别设置为读未提交,以减少锁竞争。
11. Seata 的最佳实践
在微服务架构中,Seata 作为分布式事务解决方案,提供了多种事务模式,帮助开发者应对数据一致性挑战。以下是 Seata 在微服务架构中的应用、常见问题与解决方案,以及性能优化的注意事项。
11.1 在微服务架构中的应用
在微服务架构中,服务之间的调用可能涉及多个数据库或资源,传统的本地事务无法满足分布式场景下的数据一致性需求。Seata 提供了 AT、TCC、SAGA 和 XA 等多种事务模式,适用于不同的业务场景:
-
AT 模式:适用于对性能要求较高且业务逻辑相对简单的场景。Seata 自动管理事务的提交和回滚,开发者无需手动处理。
-
TCC 模式:适用于对业务流程有精细控制需求的场景。开发者需要实现 Try、Confirm 和 Cancel 三个阶段的逻辑,手动控制事务的提交和回滚。
-
SAGA 模式:适用于长时间运行的事务,允许每个子事务独立提交,并在需要时执行补偿操作。Seata 提供了状态机引擎,帮助开发者编排业务流程。
-
XA 模式:适用于需要严格遵循两阶段提交协议的场景。Seata 通过 XA 协议协调各个资源的提交和回滚。
在实际应用中,开发者应根据业务需求选择合适的事务模式,并结合 Seata 的特性进行设计和实现。
11.2 常见问题与解决方案
在使用 Seata 的过程中,可能会遇到以下常见问题:
-
事务隔离性问题:在 AT 模式下,Seata 默认的全局隔离级别为读未提交(Read Uncommitted),可能导致脏读等问题。为解决此问题,可以使用全局锁机制,通过代理
SELECT FOR UPDATE语句,确保读取到已提交的数据。 -
回滚失败:在事务回滚过程中,可能由于脏数据导致回滚失败。为避免此类问题,建议在业务逻辑中确保数据的一致性,并在必要时进行数据校验。
-
版本兼容性问题:在使用 Seata 时,可能会遇到与 Spring Boot 等框架版本不兼容的问题。建议参考 Seata 官方文档,选择与项目依赖版本兼容的 Seata 版本。
针对上述问题,开发者应在项目初期进行充分的测试和验证,确保 Seata 的配置和使用符合项目需求。
11.3 性能优化的注意事项
为了提升 Seata 的性能,开发者可以考虑以下优化措施:
-
合理选择事务模式:根据业务需求,选择合适的事务模式。例如,在对性能要求较高的场景下,选择 AT 模式;在需要精细控制的场景下,选择 TCC 模式。
-
优化数据库操作:在 AT 模式下,Seata 需要记录回滚日志。为减少对数据库的影响,建议对
undo_log表进行分区管理,定期清理历史数据。 -
配置合适的超时时间:根据业务场景,设置合理的全局事务超时时间,避免长时间占用资源。
-
监控和日志管理:建立完善的监控和日志机制,及时发现和处理性能瓶颈。
12. Seata 的社区生态
Seata 作为开源的分布式事务解决方案,拥有活跃的社区生态,提供丰富的扩展与插件,并有明确的开发路线。
12.1 常用的扩展与插件
Seata 采用微内核和插件化的设计,提供多种扩展点,方便业务进行灵活的扩展和技术组件的选择。主要的扩展点包括:
-
API 扩展:允许开发者根据业务需求自定义接口。
-
注册配置中心:支持多种注册中心和配置中心,如 Nacos、Eureka、Zookeeper 等。
-
存储模式:支持多种存储模式,包括数据库、文件等。
-
锁控制:提供灵活的锁机制,确保数据一致性。
-
SQL 解析器:支持多种数据库的 SQL 解析。
-
负载均衡:提供多种负载均衡策略,提升系统性能。
-
传输协议:支持多种传输协议,满足不同的网络环境需求。
-
可观察性:提供监控和日志功能,方便运维和调试。
这些扩展点使得 Seata 能够适应不同的业务场景和技术栈,提升了系统的灵活性和可扩展性。
12.2 社区支持和开发路线
Seata 社区自 2019 年开源以来,已有超过 300 位贡献者,项目收获了 24k+ 星标,成为一个非常成熟的社区。Seata 兼容 10 余种主流 RPC 框架和 RDBMS,与 20 多个社区存在集成和被集成的关系,被数千家客户应用到业务系统中。2023 年 10 月 29 日,Seata 正式捐赠给了 Apache 软件基金会,成为孵化项目。经过孵化之后,Seata 有望成为首个 Apache 软件基金会的分布式事务框架顶级项目。
Seata 的开发路线包括:
-
存储/协议/特性:探索存算分离的 Raft 集群模式;统一当前 4 种事务模式的 API;兼容 GTS 协议;支持 Saga 注解;支持分布式锁的控制;提供数据视角的洞察和治理。
-
生态:支持更多的数据库和服务框架,探索国产化信创生态的支持;支持 MQ 生态;完善 APM 的支持。
-
解决方案:支持微服务生态,探索多云方案;提供云原生的解决方案;增加安全和流量防护能力;实现架构上核心组件的自闭环收敛。
-
多语言生态:完善 Java 之外的编程语言支持,如 Golang、PHP、Python、JS 等。
-
研发效能/体验:提升测试覆盖率,保证质量、兼容性和稳定性;重构官网文档结构,提升文档搜索的命中率;简化运维部署,实现一键安装和配置元数据简化;控制台支持事务控制和在线分析能力。
总体而言,Seata 的规划是:更大的场景,更大的生态,从可用到好用。
12.3 参与开源项目的方法
参与 Seata 开源项目的方式包括:
-
贡献代码:在 GitHub 上 fork Seata 仓库,提交 Pull Request,贡献新功能或修复 bug。
-
撰写文档:完善 Seata 的文档,帮助新用户更快上手。
-
参与讨论:在社区论坛或 GitHub Issues 中,参与技术讨论,分享经验和见解。
-
推广应用:在自己的项目中使用 Seata,并分享使用经验,帮助更多人了解和使用 Seata。
通过以上方式,您可以为 Seata 社区的发展贡献力量。
13. 总结
Seata 作为开源的分布式事务解决方案,具有以下优势和不足,并有明确的未来改进方向。
13.1 Seata 的优势与不足
优势:
-
多事务模式支持:提供 AT、TCC、SAGA、XA 等多种事务模式,适应不同业务场景。
-
高性能:经过优化,Seata 在高并发场景下表现出色,满足企业级应用需求。
-
丰富的扩展点:采用微内核和插件化设计,提供多种扩展点,方便业务进行灵活的扩展和技术组件的选择。
-
活跃的社区:拥有庞大的用户和贡献者群体,社区支持和资源丰富。
不足:
-
学习曲线:对于初学者,理解和配置 Seata 可能需要一定的时间和精力。
-
生态完善度:虽然 Seata 已支持多种数据库和框架,但在某些特定场景下,可能需要额外的适配工作。
13.2 未来的改进方向
Seata 的未来改进方向包括:
-
存储模式优化:探索存算分离的 Raft 集群模式,提升存储性能和可靠性。
-
生态扩展:支持更多的数据库和服务框架,完善 APM 的支持,增强与其他系统的集成能力。
-
多语言支持:完善 Java 之外的编程语言支持,如 Golang、PHP、



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











