








目录
二,Controller层(仅仅展示功能,没有写Service层)
前言(啥是PageHelper)
最近实习中,分配了一些分页功能的接口需要用到PageHelper来做,因此,一边做一遍学习一下这个插件的原理。
PageHelper是Mybatis的一个插件,PageHelper可以通过设置 PageHelper.startPage(pageNum,pageSize);来执行分页功能,非常的方便快捷,这条语句后紧跟的一条查询操作会进行分页。下面我们来分析一下pageHelper的使用。
//第一页,一页20条记录
PageHelper.startPage(1, 20);如何使用?(简单实现demo)
一,在SpringBoot工程Pom文件中添加如下依赖
<!-- mybatis 分页插件 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.10</version>
</dependency>二,Controller层(仅仅展示功能,没有写Service层)
@GetMapping(value = "/list")
public BaseResponse list(@RequestParam Integer pageNum) {
log.info("列表接口入参:{}", pageNum);
//设置分页,页码为前端传递,固定页码20页
PageHelper.startPage(pageNum, 5);
//查询记录,将记录存入PageInfo
List<InsMarketChannel> info = channelMapper.selectAll();
PageInfo<InsMarketChannel> pageInfo = new PageInfo<>(info);
if(result == null){
return BaseResponse.fail("查询分页失败");
}
return BaseResponse.ok(pageInfo ,"查询分页成功");
}三,mapper层
<select id="selectAll" resultMap="BaseResultMap">
select
*
from ins_market_channel
</select>使用Postman进行测试,查询第一页
四,执行结果
{
"code": 200,
"msg": "查询分页成功",
"data": {
"total": 14,
"list": [
{
"channelId": 198149,
"channelName": "Marbury",
"description": "你好",
"channelStatus": null,
"autoUnpacking": null,
"sendNumber": null,
"sendPeriod": null,
"timeUnit": null
},
{
"channelId": 198150,
"channelName": "Marburyy",
"description": "你好",
"channelStatus": null,
"autoUnpacking": null,
"sendNumber": null,
"sendPeriod": null,
"timeUnit": null
},
{
"channelId": 198151,
"channelName": "Marburyy",
"description": "你好",
"channelStatus": null,
"autoUnpacking": null,
"sendNumber": 2,
"sendPeriod": 2,
"timeUnit": null
},
{
"channelId": 198153,
"channelName": "Marburyy",
"description": "你好",
"channelStatus": null,
"autoUnpacking": null,
"sendNumber": 3,
"sendPeriod": 3,
"timeUnit": null
},
{
"channelId": 198154,
"channelName": "Marburyy",
"description": "你好",
"channelStatus": null,
"autoUnpacking": null,
"sendNumber": null,
"sendPeriod": null,
"timeUnit": null
}
],
"pageNum": 0,
"pageSize": 0,
"size": 0,
"startRow": 0,
"endRow": 0,
"pages": 0,
"prePage": 0,
"nextPage": 0,
"isFirstPage": false,
"isLastPage": false,
"hasPreviousPage": false,
"hasNextPage": false,
"navigatePages": 0,
"navigatepageNums": null,
"navigateFirstPage": 0,
"navigateLastPage": 0
},
"success": false
}
由此可见,我们不仅得到了第一页的5条数据(list中),也得到了总记录条数(total),其他参数均是PageInfo中的属性。

至此,我们可能会有些疑问:为啥执行了那句PageHelper.startPage(pageNum, 5)后,仅仅进行数据库查询操作,就可以进行分页处理,而且连总记录数都拿到了呢?接下来让我们一探究竟!
过程探究 (源码预警)

一,传统分页原理
首先我们要了解传统分页是怎么实现的。下面举个例子(查询第2页,每页5条记录):
select from ins_market_channel LIMIT 5, 5
通过Limit关键字,第一个参数为从第几条数据后开始,第二各参数为一共几条数据。第2页即为从第6条数据开始,一共截取5条,即获取第6到第10条数据。PageHelper的底层也是这样工作的。
二,流程分析
1,设置分页
PageHelper.startPage(pageNum, 5);调用这个方法后,再经过层层调用会将页码和页面大小封装成Page对象,存入ThreadLocal中,以便后续进行分页操作时获取。下面上代码。
/**
* 开始分页
*
* @param pageNum 页码
* @param pageSize 每页显示数量
* @param count 是否进行count查询
* @param reasonable 分页合理化,null时用默认配置
* @param pageSizeZero true且pageSize=0时返回全部结果,false时分页,null时用默认配置
*/
public static <E> Page<E> startPage(int pageNum, int pageSize, boolean count, Boolean reasonable, Boolean pageSizeZero) {
//封装Page对象
Page<E> page = new Page<E>(pageNum, pageSize, count);
page.setReasonable(reasonable);
page.setPageSizeZero(pageSizeZero);
//当已经执行过orderBy的时候
Page<E> oldPage = getLocalPage();
if (oldPage != null && oldPage.isOrderByOnly()) {
page.setOrderBy(oldPage.getOrderBy());
}
//存入ThreadLocal
setLocalPage(page);
return page;
}2,PageInterceptor拦截器以及流程
为什么进行普通数据库查询操作就会进行分页呢?因为PageHelper内部实现了一个PageInterceptor拦截器,在Spring项目启动时,会将这个拦截器加入到拦截器链中,当进行select操作时,会对该行为进行拦截,查询总条数并且重新拼接select语句(添加Limit关键字)再进行查询。后面会详细分析。下面上代码。
debug调试,从数据库查询语句开始不断step进入下一层 直到
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
Set<Method> methods = signatureMap.get(method.getDeclaringClass());
if (methods != null && methods.contains(method)) {
//这一句,对sql进行拦截
return interceptor.intercept(new Invocation(target, method, args));
}
return method.invoke(target, args);
} catch (Exception e) {
throw ExceptionUtil.unwrapThrowable(e);
}
}
step进入intercept方法,一路debug发现如果有参数则获取参数,查询列表总数(重要),查询分页数据(重要),最后调用afterPage方法进行分页后的处理。重要部分下面继续深入。
@Override
public Object intercept(Invocation invocation) throws Throwable {
try {
Object[] args = invocation.getArgs();
//如果controller层调用的selectAll方法传入了参数,将从下面获取
MappedStatement ms = (MappedStatement) args[0];
Object parameter = args[1];
RowBounds rowBounds = (RowBounds) args[2];
ResultHandler resultHandler = (ResultHandler) args[3];
Executor executor = (Executor) invocation.getTarget();
CacheKey cacheKey;
BoundSql boundSql;
//由于逻辑关系,只会进入一次
if (args.length == 4) {
//4 个参数时
//通过MappedStatement拿到要执行的sql语句
boundSql = ms.getBoundSql(parameter);
//拿到所有需要用的元素,将他们缓存起来,以备后续用到,下面附图1
cacheKey = executor.createCacheKey(ms, parameter, rowBounds, boundSql);
} else {
//6 个参数时
cacheKey = (CacheKey) args[4];
boundSql = (BoundSql) args[5];
}
checkDialectExists();
List resultList;
//调用方法判断是否需要进行分页,如果不需要,直接返回结果
if (!dialect.skip(ms, parameter, rowBounds)) {
//判断是否需要进行 count 查询
if (dialect.beforeCount(ms, parameter, rowBounds)) {
//查询总数,非常重要
Long count = count(executor, ms, parameter, rowBounds, resultHandler, boundSql);
//处理查询总数,返回 true 时继续分页查询,false 时直接返回
if (!dialect.afterCount(count, parameter, rowBounds)) {
//当查询总数为 0 时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
}
resultList = ExecutorUtil.pageQuery(dialect, executor,
ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
} else {
//rowBounds用参数值,不使用分页插件处理时,仍然支持默认的内存分页
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
return dialect.afterPage(resultList, parameter, rowBounds);
} finally {
dialect.afterAll();
}
} 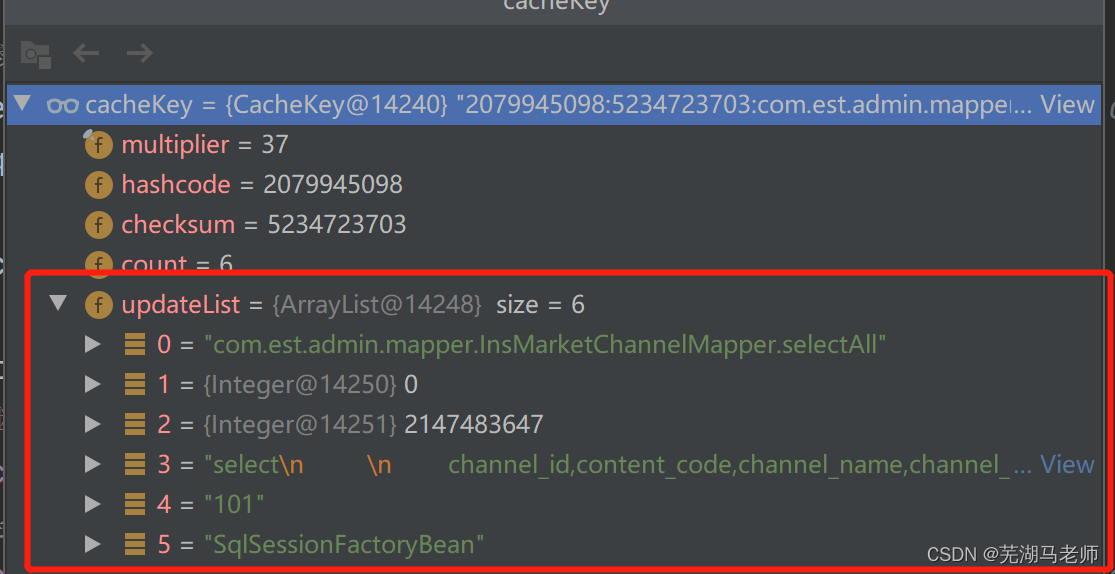
图-1
3,获取总条数
接下来我们进入Long count = count(executor, ms, parameter, rowBounds, resultHandler, boundSql);这一个方法,继续深入探索。上代码。
private Long count(Executor executor, MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler,
BoundSql boundSql) throws SQLException {
String countMsId = ms.getId() + countSuffix;
Long count;
//先判断是否存在手写的 count 查询,如果有,则使用手写count查询
MappedStatement countMs = ExecutorUtil.getExistedMappedStatement(ms.getConfiguration(), countMsId);
if (countMs != null) {
count = ExecutorUtil.executeManualCount(executor, countMs, parameter, boundSql, resultHandler);
} else {
countMs = msCountMap.get(countMsId);
//自动创建
if (countMs == null) {
//根据当前的 ms 创建一个返回值为 Long 类型的 ms
countMs = MSUtils.newCountMappedStatement(ms, countMsId);
msCountMap.put(countMsId, countMs);
}
//自动计算总条数关键代码
count = ExecutorUtil.executeAutoCount(dialect, executor, countMs, parameter, boundSql, rowBounds, resultHandler);
}
return count;
}
继续step入count = ExecutorUtil.executeAutoCount(dialect, executor, countMs, parameter, boundSql, rowBounds, resultHandler);方法
/**
* 执行自动生成的 count 查询
*
* @param dialect
* @param executor
* @param countMs
* @param parameter
* @param boundSql
* @param rowBounds
* @param resultHandler
* @return
* @throws SQLException
*/
public static Long executeAutoCount(Dialect dialect, Executor executor, MappedStatement countMs,
Object parameter, BoundSql boundSql,
RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
Map<String, Object> additionalParameters = getAdditionalParameter(boundSql);
//创建 count 查询的缓存 key,即是上面提前缓存好的CacheKey,里面存有分页查询的sql
CacheKey countKey = executor.createCacheKey(countMs, parameter, RowBounds.DEFAULT, boundSql);
//调用方言获取 count sql,获取总条数的sql,附在图2
String countSql = dialect.getCountSql(countMs, boundSql, parameter, rowBounds, countKey);
//countKey.update(countSql);
BoundSql countBoundSql = new BoundSql(countMs.getConfiguration(), countSql, boundSql.getParameterMappings(), parameter);
//当使用动态 SQL 时,可能会产生临时的参数,这些参数需要手动设置到新的 BoundSql 中
for (String key : additionalParameters.keySet()) {
countBoundSql.setAdditionalParameter(key, additionalParameters.get(key));
}
//执行 count 查询,重要!执行下面的query方法后,执行上面的select *....语句
Object countResultList = executor.query(countMs, parameter, RowBounds.DEFAULT, resultHandler, countKey, countBoundSql);
Long count = (Long) ((List) countResultList).get(0);
return count;
} 
图-2
执行executor.query(countMs, parameter, RowBounds.DEFAULT, resultHandler, countKey, countBoundSql);方法后,查询记录总数。如果开启sql日志,可在控制台看到以下输出。

回到上面的intercept方法,获取count后,调用afterCount方法,将count记录保存至之前缓存在ThreadLocal中的Page对象中。代码如下。
@Override
public boolean afterCount(long count, Object parameterObject, RowBounds rowBounds) {
//从ThreadLocal中拿到page对象
Page page = getLocalPage();
//将记录总数存入page对象
page.setTotal(count);
if (rowBounds instanceof PageRowBounds) {
((PageRowBounds) rowBounds).setTotal(count);
}
//pageSize < 0 的时候,不执行分页查询
//pageSize = 0 的时候,还需要执行后续查询,但是不会分页
if (page.getPageSize() < 0) {
return false;
}
return count > 0;
} 
4,获取分页数据
至此,记录总数我们已经拿到了,接下来就是分页记录们了。废话少说,继续回到上面的intercept方法,step进入ExecutorUtil.pageQuery(dialect, executor, ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);方法。代码如下。
/**
* 分页查询
*
* @param dialect
* @param executor
* @param ms
* @param parameter
* @param rowBounds
* @param resultHandler
* @param boundSql
* @param cacheKey
* @param <E>
* @return
* @throws SQLException
*/
public static <E> List<E> pageQuery(Dialect dialect, Executor executor, MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler,
BoundSql boundSql, CacheKey cacheKey) throws SQLException {
//判断是否需要进行分页查询
if (dialect.beforePage(ms, parameter, rowBounds)) {
//生成分页的缓存 key,即是上面提前缓存好的CacheKey,里面存有分页查询的sql
CacheKey pageKey = cacheKey;
//处理参数对象,从ThreadLocal中获取page对象(包含分页信息,前面已提到)
parameter = dialect.processParameterObject(ms, parameter, boundSql, pageKey);
//调用方言,拼接Limit关键字,获取分页 sql
String pageSql = dialect.getPageSql(ms, boundSql, parameter, rowBounds, pageKey);
BoundSql pageBoundSql = new BoundSql(ms.getConfiguration(), pageSql, boundSql.getParameterMappings(), parameter);
Map<String, Object> additionalParameters = getAdditionalParameter(boundSql);
//设置动态参数
for (String key : additionalParameters.keySet()) {
pageBoundSql.setAdditionalParameter(key, additionalParameters.get(key));
}
//执行分页查询
return executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, pageKey, pageBoundSql);
} else {
//不执行分页的情况下,也不执行内存分页
return executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, cacheKey, boundSql);
}
}
step进入dialect.processParameterObject(ms, parameter, boundSql, pageKey);
发现关键性代码如下。
@Override
public Object processParameterObject(MappedStatement ms, Object parameterObject, BoundSql boundSql, CacheKey pageKey) {
//处理参数,从ThreadLocal中获取page分页参数!!!!!!
Page page = getLocalPage();
//如果只是 order by 就不必处理参数
if (page.isOrderByOnly()) {
return parameterObject;
}
Map<String, Object> paramMap = null;
if (parameterObject == null) {
paramMap = new HashMap<String, Object>();
} else if (parameterObject instanceof Map) {
//解决不可变Map的情况
paramMap = new HashMap<String, Object>();
paramMap.putAll((Map) parameterObject);
} else {
paramMap = new HashMap<String, Object>();
//动态sql时的判断条件不会出现在ParameterMapping中,但是必须有,所以这里需要收集所有的getter属性
//TypeHandlerRegistry可以直接处理的会作为一个直接使用的对象进行处理
boolean hasTypeHandler = ms.getConfiguration().getTypeHandlerRegistry().hasTypeHandler(parameterObject.getClass());
MetaObject metaObject = MetaObjectUtil.forObject(parameterObject);
//需要针对注解形式的MyProviderSqlSource保存原值
if (!hasTypeHandler) {
for (String name : metaObject.getGetterNames()) {
paramMap.put(name, metaObject.getValue(name));
}
}
//下面这段方法,主要解决一个常见类型的参数时的问题
if (boundSql.getParameterMappings() != null && boundSql.getParameterMappings().size() > 0) {
for (ParameterMapping parameterMapping : boundSql.getParameterMappings()) {
String name = parameterMapping.getProperty();
if (!name.equals(PAGEPARAMETER_FIRST)
&& !name.equals(PAGEPARAMETER_SECOND)
&& paramMap.get(name) == null) {
if (hasTypeHandler
|| parameterMapping.getJavaType().equals(parameterObject.getClass())) {
paramMap.put(name, parameterObject);
break;
}
}
}
}
}
return processPageParameter(ms, paramMap, page, boundSql, pageKey);
}
至此,我们已经拿到了分页需要用到的参数(页码,每页条数),只需再修改sql语句,进行查询,即可得到分页数据。
回到pageQuery方法继续step进入dialect.getPageSql(ms, boundSql, parameter, rowBounds, pageKey);方法,不断step进入后发现其中奥妙(代码如下):
@Override
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 14);
sqlBuilder.append(sql);
//拼接分页sql
if (page.getStartRow() == 0) {
//如果第一页开始Limit只需要一个参数
sqlBuilder.append(" LIMIT ? ");
} else {
//如果不是第一页则需要两个参数(前面分析过)
sqlBuilder.append(" LIMIT ?, ? ");
}
return sqlBuilder.toString();
}
回到pageQuery中的executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, pageKey, pageBoundSql);方法进行分页查询(反射细节不再描述)。执行该语句之后发现控制台打印输出:

库表结构已打码 正常应该打印select * from ins_market_channel LIMIT ? ::: [ 5]
我懒得改业务代码了而已 - -
此时我们发现List中已经有了5条页面记录,如图3
总条数以及其他各种页面参数也存在了List对象中,如图4
5,查询结果

图-3

图-4
此时将该集合对象返回给前端,大功告成喽!!!

三,注意事项
在文章开头我已经提过了:这条语句后紧跟的一条查询操作会进行分页。也就是说,再执行这个分页操作后,如果还想再进行一次分页操作,需要重新执行 PageHelper.startPage(pageNum, pageSize);
这条语句才可以再次进行分页。通俗来说:
设置分页是一次性的!!
由于我们都有刨根问底的优良品质,所以我们要弄懂为啥子是这样的机制捏?
我们重新回到intercept方法,所有逻辑全部执行完之后,会调用afterAll方法,该方法会将ThreadLocal中的Page对象删除,详见如下代码:
@Override
public void afterAll() {
//这个方法即使不分页也会被执行,所以要判断 null
AbstractHelperDialect delegate = autoDialect.getDelegate();
if (delegate != null) {
delegate.afterAll();
autoDialect.clearDelegate();
}
//清楚分页信息
clearPage();
}step进入clearPage()方法
/**
* 移除本地变量
*/
public static void clearPage() {
//删除ThreadLocal中的数据
LOCAL_PAGE.remove();
}总结
至此,我们已经拿捏PageHelper了,难道不是么?

我是芜湖马老师,一个普普通通的22届毕业本科生。
如果觉得文章还不错,点赞关注不迷路。
后续会持续更新Java学习之路上遇到的问题以及解决方案,争取让大家都掰开了,吃透了。
有啥问题欢迎和我交流。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











