






第二章 认识数据
一、数据的属性
1.标称属性
值得特征:代表:某种类别、状态、编码。不必具有:有意义的顺序性、定量处理任务。
标称属性——分类的
标称属性值——枚举的
2.二元属性(布尔属性)
值得特征:只有两个类别或状态
3.序数属性(定序型)
值得特征:具有有意义的顺序性或秩的评定性。

4.数值属性
值得特征:整数或实数
5.离散属性
6.连续属性
二、数据的基本统计描述
1.均值
分类:①算数均值 ②加权算数均值 (每一个值xi,与一个权重wi相关联)
加权算数平均值扩展–频数(分布)表。


2.中位数
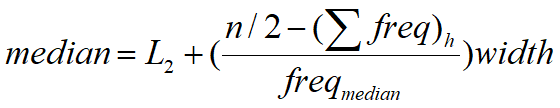

3**.众数**
含义:在集合中,出现次数最多的值。
数据集合的分类:单峰的→多峰的
4.中列数
在数据集中,最大值和最小值的平均值。

三、数据发散度量
1.极差
最大值和最小值的差
缺点:①小数据量的粗略分析②仅关注了最值的区间→其他数据的变异情况未知
2.分位数
- 有序数据被等份→每一个间隔点的值:分位数。(常见中位数(二分位数)、四分位数、百分位数)
- 数据分布的中心情况:中位数
- 数据分布的散布情况:一个百分位数Px(第X个百分位数)→数据被划成两部分
- (1)小于Px的值最多X%;或X%的值小于等于Px
- (2)大于Px的值最多1-X%,或1-X%的值大于等于Px。


3.方差与标准差 - 描述数据分布的散布程度
- 比标准差低→数据趋向于:非常靠近均值
- 比标准差高→数据散布于:大的值区域
- 计算公式
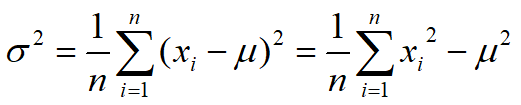
四、基本统计描述图形显示
1.直方图
2.散点图
3.分位数图
五、数据相似性和相异性度量
相似性和向异性统称:(邻近性)
1.相异性矩阵 - 存放n个对象、两两之前的邻近度
- 通常用n*n矩阵表示值
- d(i,j) 是对象i和j之间相异性的度量。对象i和j高度相似→值接近于0. 越不同→该值越大。
- 不匹配率的计算:d(i,j)=(p-m)/p (m:匹配的数目→对象i和j取值相同状态的属性数 )(p:对象的属性总数)


- 匹配率:sum(i,j)=1-d(i,j)
—————————————————————————
下次再更吧














 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









