






一、GROUP BY和HAVING的介绍
GROUP BY: 类似于其他编程语言中的循环结构,用于按照一个或多个列对数据进行分组。它的作用有点像 Python 中的 groupby 函数或者 Pandas 库中的 groupby 方法。
Group By与聚合函数
在示例3中提到group by语句中select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中,常见的聚合函数如下表:
函数 作用 支持性
sum(列名) 求和
max(列名) 最大值
min(列名) 最小值
avg(列名) 平均值
first(列名) 第一条记录 仅Access支持
last(列名) 最后一条记录 仅Access支持
count(列名) 统计记录数 注意和count(*)的区别.
HAVING: 在数据分组后,用于过滤满足特定条件的组。这与 WHERE 子句相似,但 HAVING 是在聚合后进行过滤,通常与聚合函数(如 COUNT, SUM 等)一起使用。
select
dist_interdddress ,
COUNT (
*
)
from
distribute_logs
GROUP by
dist_interdddress
HAVING
COUNT (
*
) >= 1
结果:
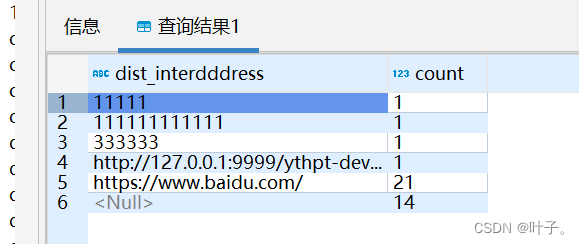 统计了以dist_interdddress 字段为分组条件的,各分组条数。
统计了以dist_interdddress 字段为分组条件的,各分组条数。
1、满足“SELECT子句中的列名必须为分组列或列函数”,因为SELECT有group by中包含的列
2、having必须和group by一起用,且在group by后面
3、group by、having、order by的使用顺序:group by 、having、order by
SELECT *|字段列表 [as 别名] FROM 表名 [WHERE 子句] [GROUP BY 子句][HAVING 子句][ORDER BY 子句][LIMIT 子句]
4、having是在分好组后找出特定的分组,通常是以筛选聚合函数的结果,如sum(a) > 100等,使用了having必须使用group by,但是使用group by 不一定使用having。
5、分组函数常用到的聚合函数:
MIN 最小值
MAX 最大值
SUM 求和
AVG 求平均
COUNT 计数
不允许使用双重聚合函数,所以在对分组进行筛选的时候,可以用order by 排序,然后用limit也可以找到极值。
二、where/having区别
1、where 子句
-
对查询结果进行分组前,将不符合 where 条件的行去掉,即在分组之前过滤数据,即先过滤再分组。
-
where 后面不可以使用聚合函数
-
过滤行
2、having 子句
-
having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,即先分组再过滤。
-
having 后面可以使用聚合函数
-
过滤组
-
支持所有WHERE操作符
三、limit用法
LIMIT offset,length;
offset:起始行数,从 0 开始计数,如果省略,默认就是 0
length: 返回的行数
查询学生表中数据,从第 3 条开始显示,显示 6 条。
select * from student3 limit 2,6
分页:比如我们登录京东,淘宝,返回的商品信息可能有几万条,不是一次全部显示出来。是一页显示固定的条数。
假设我们每页显示 5 条记录的方式来分页。
如果第一个参数是 0 可以省略写
select * from student3 limit 5
最后如果不够 5 条,有多少显示多少
select * from student3 limit 10,5















 788
788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









