







常见概念(2)
-
准确率的不足和混淆矩阵:
准确对越高就能说明模型的分类性能越好吗?举个例子,现在我开发了一套癌症检测系统,只要输入你的一些基本健康信息,就能预测出你现在是否患有癌症,并且分类的准确度为 0.999。这样的系统的预测性能好不好呢?
你可能会觉得,哇,这么高的准确度!这个系统肯定很牛逼!但是我们知道,一般年轻人患癌症的概率非常低,假设患癌症的概率为 0.001,那么其实我这个癌症检测系统只要一直输出您没有患癌症,准确度也可能能够达到 0.999。
假如现在有一个人本身已经患有癌症,但是他自己不知道自己患有癌症。这个时候用我的癌症检测系统检测发现他没有得癌症,那很显然我这个系统已经把他给坑了(耽误了治疗)。
看到这里您应该已经体会到了,一个分类模型如果光看准确度是不够的,尤其是对这种样本极度不平衡的情况( 10000 条健康信息数据中,只有 1 条的类别是患有癌症,其他的类别都是健康)。 -
混淆矩阵:
想进一步的考量分类模型的性能如何,可以使用其他的一些性能指标,例如精准率和召回率。但这些指标计算的基础是混淆矩阵。继续以癌症检测系统为例,癌症检测系统的输出不是有癌症就是健康,这里为了方便,就用 1 表示患有癌症,0 表示健康。假设现在拿 10000 条数据来进行测试,其中有 9978 条数据的真实类别是 0,系统预测的类别也是 0,有 2 条数据的真实类别是 1 却预测成了 0,有 12 条数据的真实类别是 0 但预测成了 1,有 8 条数据的真实类别是 1,预测结果也是 1。
如果我们把这些结果组成如下矩阵,则该矩阵就成为混淆矩阵。

混淆矩阵中每个格子所代表的的意义也很明显,意义如下:

如果将正确看成是 True,错误看成是 False, 0 看成是 Negtive, 1 看成是 Positive。然后将上表中的文字替换掉,混淆矩阵如下:
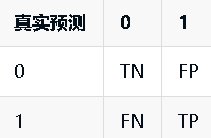
因此 TN 表示真实类别是 Negtive,预测结果也是 Negtive 的数量; FP 表示真实类别是 Negtive,预测结果是 Positive 的数量; FN 表示真实类别是 Positive,预测结果是 Negtive 的数量;TP 表示真实类别是 Positive,预测结果也是 Positive 的数量。
很明显,当 FN 和 FP 都等于 0 时,模型的性能应该是最好的,因为模型并没有在预测的时候犯错误。
用python 实现二分类混淆矩阵:
import numpy as np
def confusion_matrix(y_true, y_predict):
'''
构建二分类的混淆矩阵,并将其返回
:param y_true: 真实类别,类型为ndarray
:param y_predict: 预测类别,类型为ndarray
:return: shape为(2, 2)的ndarray
'''
def TN(y_true, y_predict):
return np.sum((y_true == 0) & (y_predict == 0))
def FP(y_true, y_predict):
return np.sum((y_true == 0) & (y_predict == 1))
def FN(y_true, y_predict):
return np.sum((y_true == 1) & (y_predict == 0))
def TP(y_true, y_predict):
return np.sum((y_true == 1) & (y_predict == 1))
return np.array([
[TN(y_true, y_predict), FP(y_true, y_predict)],
[FN(y_true, y_predict), TP(y_true, y_predict)]
])
- 精准率和召回率:
精准率(Precision)指的是模型预测为 Positive 时的预测准确度,其计算公式如下:
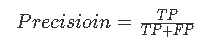
假如癌症检测系统的混淆矩阵如下:
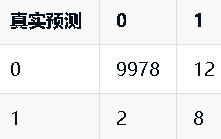
则该系统的精准率 =8/(8+12)=0.4。
0.4 这个值表示癌症检测系统的预测结果中如果有 100 个人被预测成患有癌症,那么其中有 40 人是真的患有癌症。也就是说,精准率越高,那么癌症检测系统预测某人患有癌症的可信度就越高。
召回率
召回率(Recall)指的是我们关注的事件发生了,并且模型预测正确了的比值,其计算公式如下:
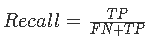
则该系统的召回率 =8/(8+2)=0.8。
从计算出的召回率可以看出,假设有 100 个患有癌症的病人使用这个系统进行癌症检测,系统能够检测出 80 人是患有癌症的。也就是说,召回率越高,那么我们感兴趣的对象成为漏网之鱼的可能性越低。
- 精准率与召回率之间的关系:
假设有这么一组数据,菱形代表 Positive,圆形代表 Negtive 。

现在需要训练一个模型对数据进行分类,假如该模型非常简单,就是在数据上画一条线作为分类边界。模型认为边界的左边是 Negtive,右边是 Positive。如果该模型的分类边界向左或者向右移动的话,模型所对应的精准率和召回率如下图所示:

从上图可知,模型的精准率变高,召回率会变低,精准率变低,召回率会变高。
应该选精准率还是召回率作为性能指标?
到底应该使用精准率还是召回率作为性能指标,其实是根据具体业务来决定的。
比如我现在想要训练一个模型来预测我关心的股票是涨( Positive )还是跌( Negtive ),那么我们应该主要使用精准率作为性能指标。因为精准率高的话,则模型预测该股票要涨的可信度就高(很有可能赚钱!)。
比如现在需要训练一个模型来预测人是( Positive )否( Negtive )患有艾滋病,那么我们应该主要使用召回率作为性能指标。因为召回率太低的话,很有可能存在漏网之鱼(可能一个人本身患有艾滋病,但预测成了健康),这样就很可能导致病人错过了最佳的治疗时间,这是非常致命的。
用python实现二分类的精准率和召回率:
import numpy as np
def precision_score(y_true, y_predict):
'''
计算精准率并返回
:param y_true: 真实类别,类型为ndarray
:param y_predict: 预测类别,类型为ndarray
:return: 精准率,类型为float
'''
def TP(y_true, y_predict):
return np.sum((y_true == 1) & (y_predict == 1))
def FP(y_true, y_predict):
return np.sum((y_true == 0) & (y_predict == 1))
tp = TP(y_true, y_predict)
fp = FP(y_true, y_predict)
try:
return tp / (tp + fp)
except:
return 0.0
def recall_score(y_true, y_predict):
'''
计算召回率并召回
:param y_true: 真实类别,类型为ndarray
:param y_predict: 预测类别,类型为ndarray
:return: 召回率,类型为float
'''
def FN(y_true, y_predict):
return np.sum((y_true == 1) & (y_predict == 0))
def TP(y_true, y_predict):
return np.sum((y_true == 1) & (y_predict == 1))
tp = TP(y_true, y_predict)
fn = FN(y_true, y_predict)
try:
return tp / (tp + fn)
except:
return 0.0
-
F1 score:
上面提到了精准率变高,召回率会变低,精准率变低,召回率会变高。那如果想要同时兼顾精准率和召回率,这个时候就可以使用 F1 Score 来作为性能度量指标了。
F1 Score 是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的准确率和召回率。 F1 Score 可以看作是模型准确率和召回率的一种加权平均,它的最大值是 1,最小值是 0。其公式如下:

假设模型 A 的精准率为 0.2,召回率为 0.7,那么模型 A 的 F1 Score 为 0.31111。
假设模型 B 的精准率为 0.7,召回率为 0.2,那么模型 B 的 F1 Score 为 0.31111。
假设模型 C 的精准率为 0.8,召回率为 0.7,那么模型 C 的 F1 Score 为 0.74667。
假设模型 D 的精准率为 0.2,召回率为 0.3,那么模型 D 的 F1 Score 为 0.24。
从上述 4 个模型的各种性能可以看出,模型C的精准率和召回率都比较高,因此它的 F1 Score 也比较高。而其他模型的精准率和召回率要么都比较低,要么一个低一个高,所以它们的 F1 Score 比较低。
这也说明了只有当模型的精准率和召回率都比较高时 F1 Score 才会比较高。这也是 F1 Score 能够同时兼顾精准率和召回率的原因。
使用python 实现:
import numpy as np
def f1_score(precision, recall):
'''
计算f1 score并返回
:param precision: 模型的精准率,类型为float
:param recall: 模型的召回率,类型为float
:return: 模型的f1 score,类型为float
'''
try:
return 2 * precision * recall / (precision + recall)
except:
return 0.0
- ROC曲线与AUC
ROC曲线( Receiver Operating Cha\fracteristic Curve )描述的 TPR ( True Positive Rate )与 FPR ( False Positive Rate )之间关系的曲线。
TPR 与 FPR 的计算公式如下:
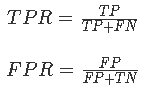
TPR(召回率) 描述的是模型预测 Positive 并且预测正确的数量占真实类别为 Positive 样本的比例。而 FPR 描述的模型预测 Positive 并且预测错了的数量占真实类别为 Negtive 样本的比例。
假设有这么一组数据,菱形代表 Positive,圆形代表 Negtive。

现在需要训练一个逻辑回归的模型对数据进行分类,假如将从 0 到 1 中的一些值作为模型的分类阈值。若模型认为当前数据是 Positive 的概率小于分类阈值则分类为 Negtive ,否则就分类为 Positive (*假设分类阈值为 0.8,模型认为这条数据是 Positive 的概率为 0.7, 0.7 小于 0.8,那么模型就认为这条数据是 Negtive *)。在不同的分类阈值下,模型所对应的 TPR 与 FPR 如下图所示(竖线代表分类阈值,模型会将竖线左边的数据分类成 Negtive,竖线右边的分类成 Positive ):

从图中可以看出,当模型的 TPR 越高 FPR 也会越高, TPR 越低 FPR 也会越低。这与精准率和召回率之间的关系刚好相反。并且,模型的分类阈值一但改变,就有一组对应的 TPR 与 FPR 。假设该模型在不同的分类阈值下其对应的 TPR 与 FPR 如下表所示:

若将 FPR 作为横轴, TPR 作为纵轴,将上面的表格以折线图的形式画出来就是 ROC曲线 。

假设现在有模型 A 和模型 B ,它们的 ROC 曲线如下图所示(其中模型 A 的 ROC曲线 为黄色,模型 B 的 ROC 曲线 为蓝色):

那么模型 A 的性能比模型 B 的性能好,因为模型 A 当 FPR 较低时所对应的 TPR 比模型 B 的低 FPR 所对应的 TPR 更高。由由于随着 FPR 的增大, TPR 也会增大。所以 ROC 曲线与横轴所围成的面积越大,模型的分类性能就越高。而 ROC曲线 的面积称为AUC。
很明显模型的 AUC 越高,模型的二分类性能就越强。AUC 的计算公式如下:
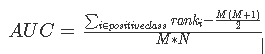
其中 M 为真实类别为 Positive 的样本数量,N 为真实类别为 Negtive 的样本数量。ranki 代表了真实类别为 Positive 的样本点额预测概率从小到大排序后,该预测概率排在第几。
举个例子,现有预测概率与真实类别的表格如下所示(其中 0 表示 Negtive, 1 表示 Positive ):
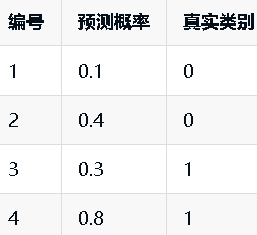
想要得到公式中的 rank,就需要将预测概率从小到大排序,排序后如下:

排序后的表格中,真实类别为 Positive 只有编号为 3 和编号为 4 的数据,并且编号为 3 的数据排在第 2 ,编号为 4 的数据排在第 4。所以 rank=[2, 4] 。又因表格中真实类别为 Positive 的数据有 2 条, Negtive 的数据有 2 条。因此 M 为2, N 为2。所以根据 AUC 的计算公式可知:
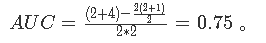
用python实现计算AUC并返回:
import numpy as np
def calAUC(prob, labels):
'''
计算AUC并返回
:param prob: 模型预测样本为Positive的概率列表,类型为ndarray
:param labels: 样本的真实类别列表,其中1表示Positive,0表示Negtive,类型为ndarray
:return: AUC,类型为float
'''
# 方法一:
rank = []
prob_copy = list(prob.copy())
M = np.sum(labels)
N = len(labels) - M
prob_list = list(zip(prob, labels))
prob_copy.sort()
for i in prob_list:
if i[1] == 1:
# 收集排序后列表的所有值为i[0]的元素的索引值
temp = [j for j, x in enumerate(prob_copy) if x == i[0]]
# 取最后一个
rank.append(temp[-1] + 1)
# 防止对后面的搜索造成干扰,将这个值赋为0
prob_copy[temp[-1]] = -1
return ((np.sum(rank)) - M * (M + 1) / 2) / (M * N)
# 方法二:
'''f = list(zip(prob, labels))
# 按概率从小到大排序
rank = [values2 for values1, values2 in sorted(f, key=lambda x:x[0])]
# 得到rank
rankList = [i+1 for i in range(len(rank)) if rank[i] == 1]
posNum = 0
negNum = 0
for i in range(len(labels)):
if(labels[i] == 1):
posNum += 1
else:
negNum += 1
# 根据公式计算AUC
auc = (sum(rankList) - (posNum*(posNum+1))/2)/(posNum*negNum)
return auc'''















 1863
1863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









