







推荐一款Linux下的OCR软件–OCRFeeder,Ubuntu软件中心直接就能搜到。
首先需要依次安装tesseract引擎及所需编译包:
sudo apt-get install tesseract-ocr
sudo apt-get install tesseract-ocr-eng tesseract-ocr-chi-sim
sudo apt-get install autoconf automake libtool
sudo apt-get install libleptonica-dev
再安装OCRFeeder,一般在主流发行版应用商店里都有。

装好后,如果程序打不开的话,用管理员身份用编辑器打开/usr/share/applications/ocrfeeder.desktop文件, 将其中“exec=ocrfeeder -i %f”中后面的参数“-i %f”去掉,然后保存就能打开了。
sudo vim /usr/share/applications/ocrfeeder.desktop
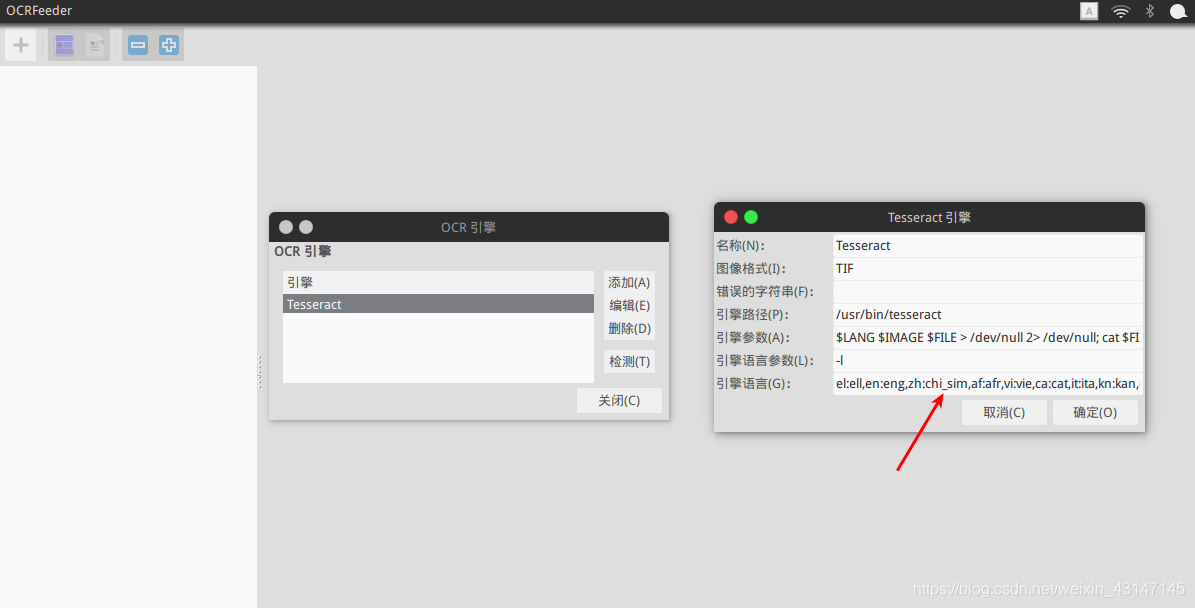
要想识别中文,有一个重要的更改需要做,要将软件工具中的OCR引擎编辑项中把“zh:chi-sim”改为“zh:chi_sim”,这样才能正确地识别中文。修改方式如下图。
识别效果:


















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









