






在工作与学习中,小伙伴们经常会遇到长段的txt格式数据,将这类数据入库非常麻烦,下面分享一个将长段表单格式txt数据转json的思路。
通常情况下,对于格式混乱的String类型的数据,无非就是通过各种手段截取有价值的数据段,再进行拼接,以下方法、集合必须得熟练使用:
1.String类中比较常用的方法
1.1String.length()
使用频繁程度★★★★★
作用:返回字符串的长度(字符数),重要程度无需多言。
1.2String.subString(int beginIndex,int endIndex)
使用频繁程度★★★★★
作用:返回一个新字符串,它是此字符串的一个子字符串。子字符串从指定的beginIndex开始,到指定的endIndex结束(不包含endIndex处的字符)。
1.3String.split(String regex)
使用频繁程度★★★★★
作用:根据给定正则表达式的匹配拆分此字符串,通常有两种用法:
第一种是要将字符串拆分为多个字串,则可存为数组,再挨个取数据即可:
String str = "apple,banana,orange";
String[] parts = str.split(",");
System.out.println(parts[0]); // 输出 "apple"
System.out.println(parts[1]); // 输出 "banana"
System.out.println(parts[2]); // 输出 "orange"第二种只需要截取其中的某一段:
String str = "apple,banana,orange";
String parts = str.split(",")[0]; // parts 将被赋值为 "apple"
System.out.println(parts); // 输出 "apple"1.4String.replace(char oldChar,char newChar)
使用频繁程度★★★★★
作用:返回一个新的字符串,其中的第一个oldChar被替换为newChar。
例如有多个段落,每个段落开头有一个*号,则可用replace("*","")将*去除掉。
1.5String.replaceAll(char oldChar,char newChar)
使用频繁程度★★★★★
作用:使用给定的replacement替换此字符串匹配给定正则表达式的所有子字符串。
例如想去掉字符串种多个不想要的字符,即可用replaceAll将其全部去掉。
1.6String.trim()
使用频繁程度★★★★★
作用:返回字符串的副本,忽略前导空白和尾部空白,任何场景都是必用的。
1.7String.indexOf(int ch, int fromIndex)/lastIndexOf(int ch, int fromIndex)
使用频繁程度★★★★★
作用:返回指定字符在此字符串中第一次/最后一次出现处的索引,从指定的索引fromIndex开始搜索。
截取的时候常有用到,例如将大段数据切割为几大段,利用此方法将更加方便,后续将具体讲到。
1.8String.equals(Object anObject)
使用频繁程度★★★★★
作用:比较两个String的内容,通常用在if判断中。
熟练用好上述8种基本已经可以处理好百分之90的特殊字符串了,针对一些特殊情况,以下方法可以丰富处理手段。
1.9String.charAt(int index)
使用频繁程度★★★
作用:返回指定索引处的字符,索引范围从0到length()-1。
这个方法在做字符串算法题时基本是必用的方法,但实际工作中用到的没有想象的多。
1.10String.concat(String str)
使用频繁程度★★★
作用:将指定字符串连接到此字符串的结尾。
这个方法在实际工作中用到的同样没有想象的多,一些需要自己构造新字段时会有用到。
1.11String.toLowerCase()/String.toUpperCase()
使用频繁程度★★
作用:使用默认语言环境的规则将此String中的所有字符都转换为小写/大写。
用的也不多,但还是要知道的。
1.12String.isEmpty()
使用频繁程度★★
作用:当且仅当长度为零时返回true。
1.13String.startsWith(String prefix)/lastIndexOf(int ch, int fromIndex)
使用频繁程度★★
作用:返回指定字符在此字符串中第一次/最后一次出现处的索引,从指定的索引开始搜索。
1.12、1.13通常用在检查字符串是否可用,主动抛出异常。
2.正则表达式
String.split(String regex) 其实也是使用了正则规则去切分字符串,但是对于更为复杂的字符串就非常无力了,因此还需掌握以下正则表达式的匹配方式。
Pattern 类
Pattern类的主要任务是编译正则表达式,并存储编译后的结果。这个类是不可变的,一旦编译了正则表达式,就不能更改它。Pattern类提供了以下方法(只是部分方法,并非全部):
compile(String regex): 编译正则表达式并返回一个Pattern对象。matcher(CharSequence input): 创建一个新的Matcher对象,用于在指定的输入序列上执行匹配操作。
Matcher 类概述
Matcher类用于执行匹配操作。一旦创建了一个Matcher对象,就可以使用它来在目标文本上执行各种匹配和查找操作。这个类是可变的,因为它保存了匹配的状态(如当前匹配位置)。Matcher类提供了以下方法(只是部分方法,并非全部):
matches(): 尝试将整个区域与模式匹配。 ★★★★★find(): 尝试查找下一个与子模式匹配的序列。 ★★★★★group(): 返回目前匹配的子序列。 ★★★★★replaceFirst(String replacement): 替换第一个与子模式匹配的序列。 ★★★replaceAll(String replacement): 替换所有与子模式匹配的序列。 ★★★start(),end(): 返回最近一次匹配操作的开始(包含)和结束(不包含)索引。 ★★★
示例代码:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexExample {
// 编译正则表达式
static Pattern pattern = Pattern.compile("\\d+"); // 匹配一个或多个数字
public static void main(String[] args) {
// 创建Matcher对象,用于在目标文本上执行匹配操作
String text = "我有10个苹果和5个橙子";
Matcher matcher = pattern.matcher(text);
// 查找所有匹配项并打印
while (matcher.find()) {
System.out.println("找到匹配项: " + matcher.group());
}
}
}输出为:

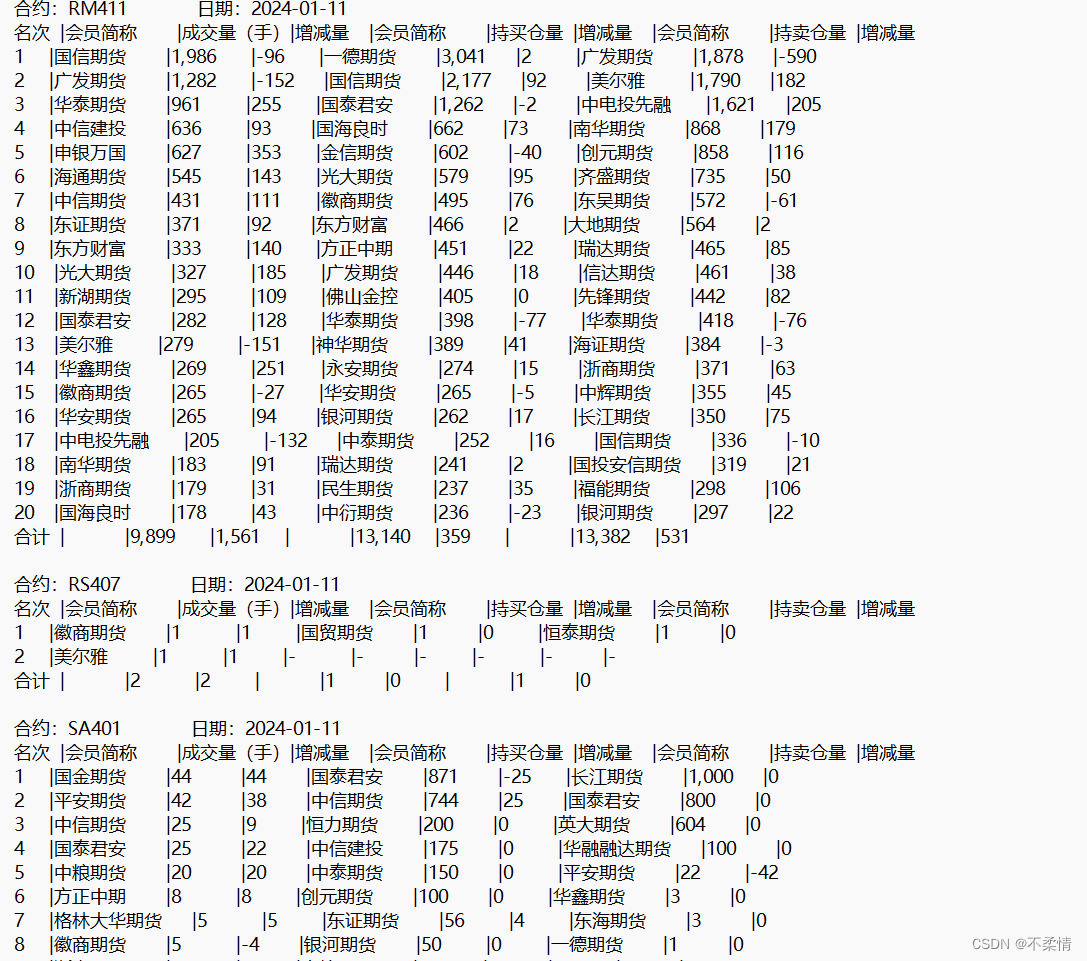
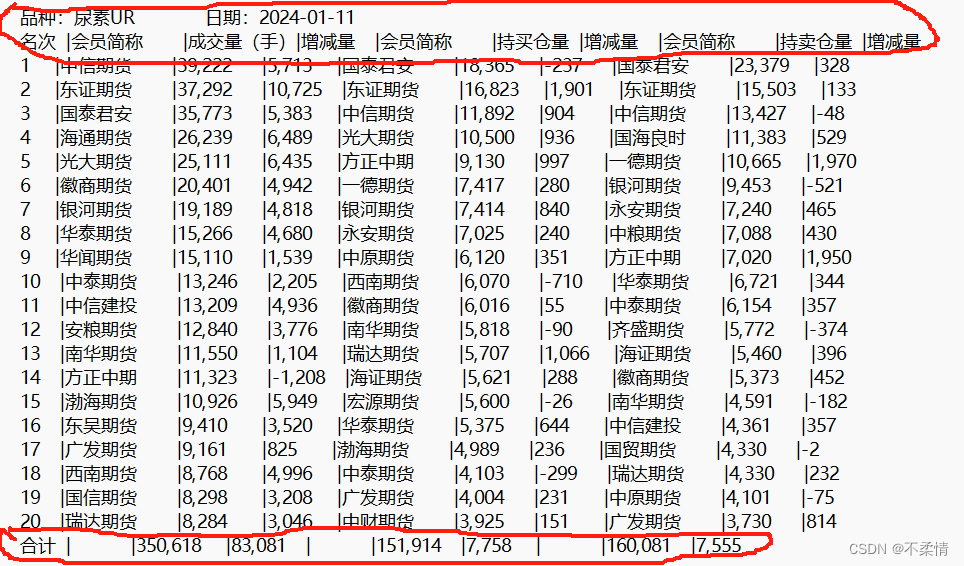
言归正传,为了更直观的讲解,我选取了郑州商品交易所2024-01-11日的公开成交数据作为示例,数据类型为txt表格如下: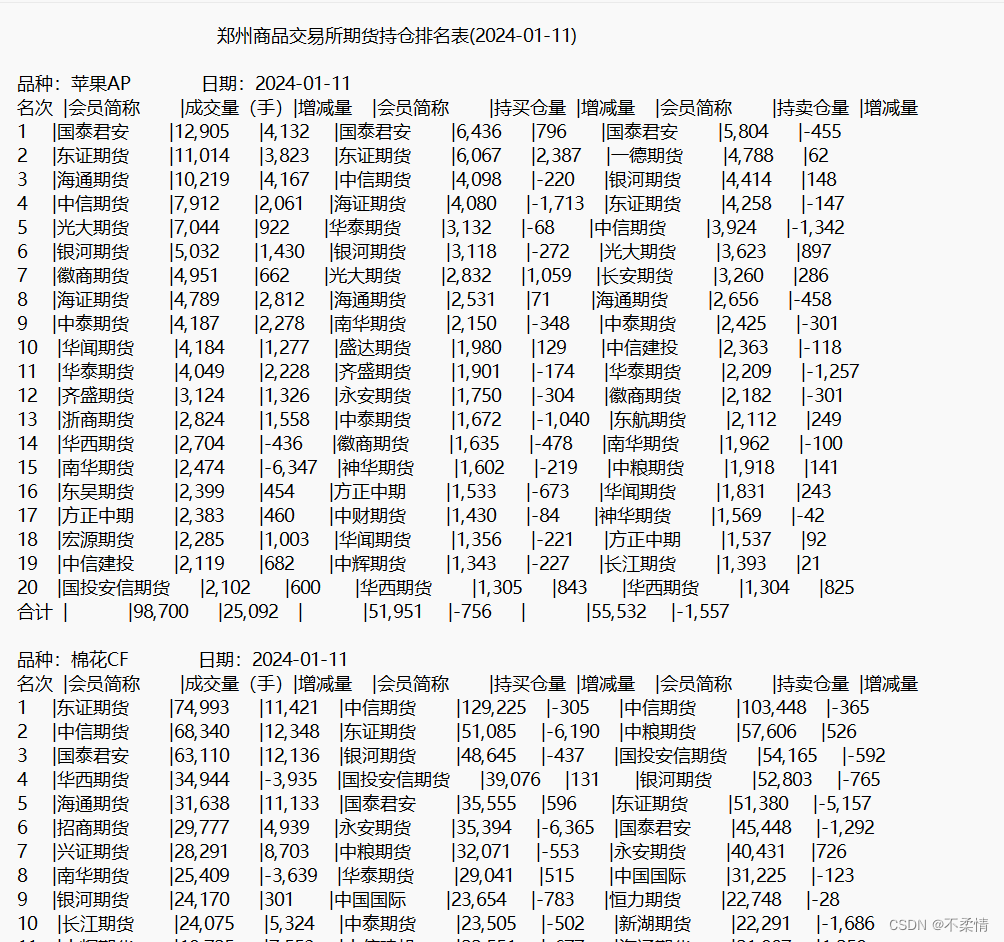
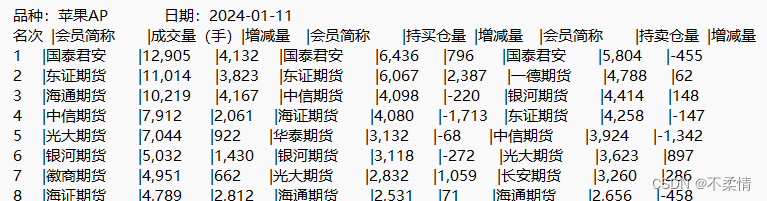
最终需要将数据有效的存入本地数据库中,表单如下:


一、数据格式分析
通常情况下,对任意文件中的标准格式Json数据进行交互都是非常方便的,但是若不是标准的Json格式呢?在处理这种数据时,首先要分析好数据格式,包括这类大段数据中需要处理的细节,并根据自己所需的目的,将数据转换为可以利用的标准格式,这样就能便利后续的使用和交互。
对于上述交易持仓数据可以总结以下几点:
1.表头的处理(裁剪无效数据)。
头部有着郑州商品交易所期货持仓排名表(2024-01-11)这一行数据,由于后续任意一段数据都有日期,所以这一段为无效数据,应对齐进行裁剪。
2.数据的形式与分布
该大表格由多个(上百个)子表格组成,前N个表格为品种的持仓排名,后M个表格为合约的持仓排名。(品种包含多个合约,类似于品种:苹果AP,就包含着AP401、AP405等多个合约,而品种表单中的数据为多个合约数据的总和。)故数据库创建两个字段,一个为品种variety,一个为合约contract_code,为了更好区分,对于品种的持仓排名,将其合约定为表格中的品种名称,类似于苹果AP,品种则为去掉中文之后的AP,而对于合约持仓排名,类似于AP401,合约定为表格中的合约名称AP401,而品种为去掉数字之后的AP,这样品种和合约的相同品种的表格将会具有相同的品种名称。
3.数据的有效列
由上述截图可看出,每一行数据都是由持仓成交、持仓买、持仓卖三个维度的数据,相当于三个排名,所以每一行应该拆分为三种数据,再入库,故数据库表单创建字段vol_type来表示此排名为成交排名(T)还是买排名(HB)还是卖排名(HS)。
4.是否有数据缺失、其他字符需要处理
4.1有上述合约持仓排名可看出,子表单的完整形式为前20排名,但是部分合约可能没有那么多期货公司进行买卖,所以部分合约的排名数据的行数可能小于20。
4.2部分排名由于交易、买、卖三个维度的数据行数不一致,导致行数少的数据以 |- |- |- 来进行填充,后续处理也应对其进行处理
4.3我们还可以看出数据每一个字段开始又有一个|字符,在入库前还需将其去掉。
二、数据处理
对数据的细节进行分析之后,就可以进行正式的数据处理。
1.数据获取
在工作学习中,对不同场景的数据进行获取,最终存入一个字符串内即可,我这里通过读取txt文件进行数据获取,就不过多说了,最终数据读入contentstr字符串。
String contentstr = content.toString();2.数据截取
根据数据,我第一步想到的就是按照两个表格开始部分的“品种:”,将两个品种间的数据进行截取,如下:
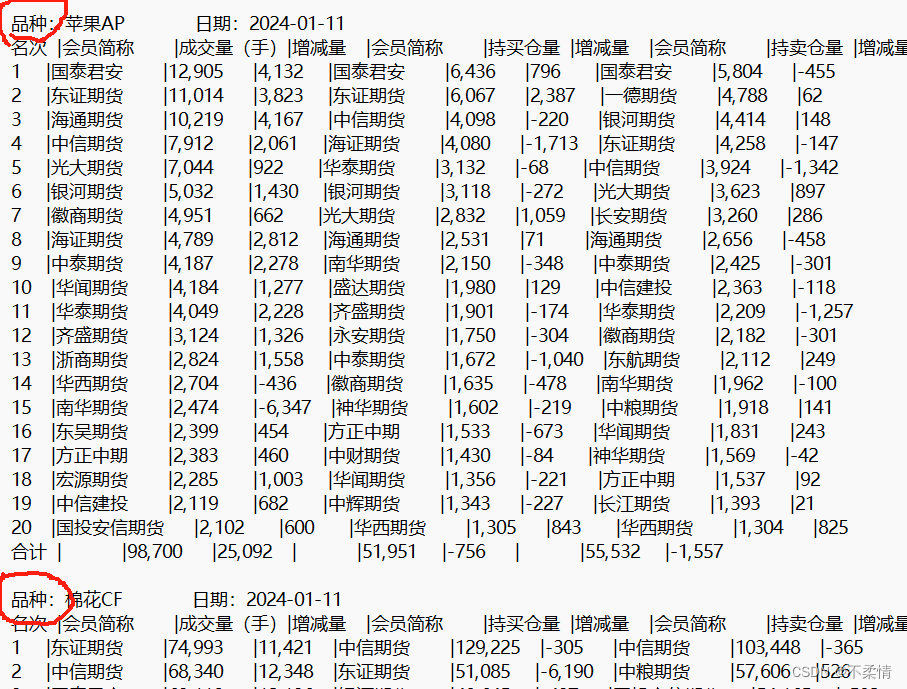
但是发现一个问题,整个String中,后半部分是合约排名,前部分是品种排名,所以就会出现最后一个品种和第一个合约交接处无法匹配。
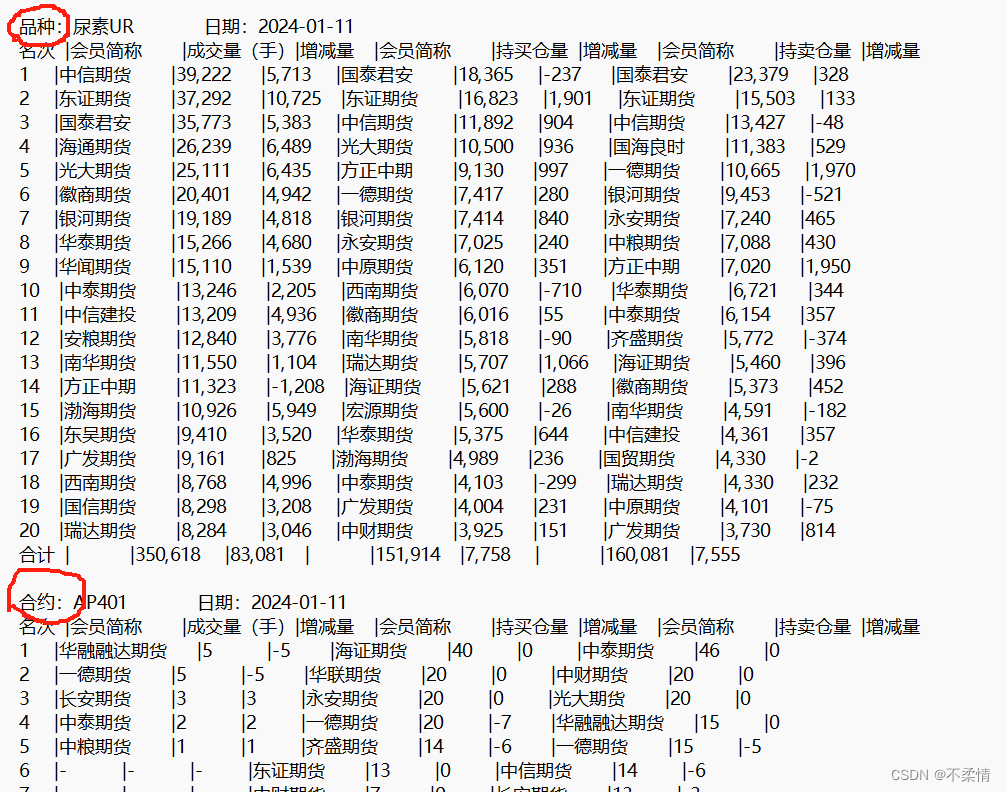
故想到的思路就是,先将除了最后一个品种表格之外的品种排名全部截取出来,然后剩下的部分,就是由最后一个品种排名和所有的合约排名。“(?<=品种:).*?(?=品种:|$)” 匹配两个品种间的任意长度内容区间,或至结尾|$。
代码:
// 正则表达式匹配“品种:”后直到下一个“品种:”或字符串结尾的所有内容
static Pattern pattern1 = Pattern.compile("(?<=品种:).*?(?=品种:|$)");
// 按照品种分割数据
Matcher matcher1 = pattern1.matcher(content);
//暂存品种段落,最后一个段落包含最后一个品种与所有合约数据
List<String> sections1 = new ArrayList<>();
while (matcher1.find()) {
sections1.add(matcher1.group().trim()); // 添加匹配到的每个品种的数据段到列表中
}为了更好的处理合约和品种两种排名,新建了一个ArrayList进行品种数据的暂存,取出section中除最后一个String加入ArrayList。
代码:
//截取的包括有品种的段落
List<String> sectionva = new ArrayList<>();
for(int i =0;i<sections1.size()-1;i++){
sectionva.add(sections1.get(i));
}接下来就可以将最后一个品种排名取出来了,取出section中最后一个String,利用indexOf()方法找到找到第一个合约出现的索引,那么这个索引之前就是最后一个品种排名。
代码:
String data = sections1.get(sections1.size()-1);
int contractIndex = data.indexOf("合约:");
if (contractIndex != -1) {
//最后一个品种数据
String beforeContract = data.substring(0, contractIndex);
sectionva.add(beforeContract);
} else {
LOGGER.info("读取最后一个品种出错");
}之后再将所有的品种排名利用正则进行切割即可,并也存入ArrayList,这样ArrayList中就存放着每一个单独的表格。
代码:
//截取的包括有合约的段落
List<String> sectionco = new ArrayList<>();
// 正则表达式匹配“合约:”后直到下一个“合约:”或字符串结尾的所有内容
static Pattern pattern3 = Pattern.compile("(?<=合约:).*?(?=合约:|$)");
//所有合约数据
String allContract = data.substring(contractIndex,data.length()-1);
//裁剪所有合约
Matcher matcher2 = pattern3.matcher(allContract);
while (matcher2.find()) {
sectionco.add(matcher2.group().trim());
}3.单个表格数据格式转换
通过观察,单个表单我们也可以看作三部分:标题部分,排名部分,合计部分,其中品种名称和日期数据在标题部分,名次、数量、增减量、会员简称等在排名部分,合计部分需要单独处理进行入库。
我最初的思路是通过先将表格按照行进行切割,代码:
String[] lines = data.split("\n");
for (String line : lines) {
if (line.trim().isEmpty() || line.startsWith("名次") || line.startsWith("合计")){ continue;} // 跳过空行、标题行和合计行
String[] columns = line.split("\\|"); // 分割每行数据
for(int i =0;i<columns.length;i++){
System.out.println(columns[i]);
}但是发现String中根本没有换行符,而且空格数量也固定,所以只好想别的方法。
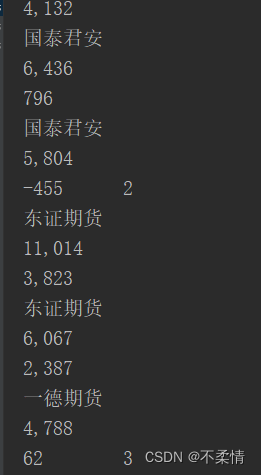
由于每个数值前面都有“|”符,其实最初想到的是采用split进行拆分每个字段,但是发现了问题,名次数据前没有“|”符,导致拆出来的数据出现了下面问题。
在输出中,名次和上一行的增减量揉成了一个数据。
所以这种方式后续还得做更精细的处理,暂时直接放弃。。。。
最后我决定先取品种名称和日期,再对表单进行切分为三部分--标题部分,排名部分,合计部分,然后再做精细处理。之前对于表格提取时,提取的时候两个合约(品种)间的内容,所以单个表单开头就是合约(品种)名称,末尾有若干空格。
所以,第一大段空格前的内容就是合约(品种)名称,日期:之后,名次之前的部分为日期+若干空格,所以通过indexOf方法与substring方法进行处理,截取(品种)名称与日期。
代码如下:
// 提取合约名称
// 合约名称位于字符串起始,直到遇到第一个大量空格为止
int contractEndIndex = firstformat.indexOf(" ");
String contractName = firstformat.substring(0, contractEndIndex).trim();
// 提取日期
// 日期格式为“日期:YYYY-MM-DD”,且紧随合约名称之后
int dateStartIndex = firstformat.indexOf("日期:");
String dateStr = firstformat.substring(dateStartIndex + "日期:".length(), dateStartIndex + "日期:".length() + 10).trim();
System.out.println("合约名称: " + contractName);
System.out.println("日期: " + dateStr);输出如下:

接下来进行切割,首先切割表头部分,利用正则找到标题部分末尾的|持卖仓量 |增减量,将整个表单切成两部分,再在第二部分找到“合计”,将这部分切割成合计之后部分与排名部分,对于排名部分,通过若干空格“ ”进行切割,将表格中每一行的每一个字段内容存储至一个数组内。
代码如下:
// 使用正则表达式定位标题结束,匹配"|持卖仓量"后面跟至少一个空格和"|增减量"
static Pattern headerEndPattern = Pattern.compile("\\|持卖仓量\\s+\\|增减量");
Matcher matcher = headerEndPattern.matcher(firstformat);
String header = "";
int headerEndIndex = 0; // 初始化变量
if (matcher.find()) {
headerEndIndex = matcher.end();
header = firstformat.substring(0, headerEndIndex).trim();
} else {
System.err.println("无法找到标题的结束标记。");
}
// 分割合计行和数据行
int totalStartIndex = firstformat.indexOf("合计");
String dataLines = "";
String totalPart = "";
if (totalStartIndex != -1) {
dataLines = firstformat.substring(headerEndIndex, totalStartIndex).trim();
totalPart = firstformat.substring(totalStartIndex).trim();
} else {
dataLines = firstformat.substring(headerEndIndex).trim();
}
// 数据行进一步处理(分割成单个的元素)
// 经过尝试之后发现数据行之间由至少两个空格分隔
String[] lines = dataLines.split("\\s{2,}");
System.out.println("标题: " + header);
System.out.println("合计及之后部分: " + (totalPart.isEmpty() ? "无合计行" : totalPart));
System.out.println("数据行数量: " + lines.length);
for(int i =0;i<lines.length;i++){
System.out.println("每一行数据:"+lines[i]);
}
结果如下,我们可以看出20行的排名数据被拆成了200个字段内容,其中每10行为一组数据。这10行中的第1行为排名,2-9行分别为:会员简称、成交量(手)、增减量、会员简称、持买仓量、增减量、会员简称、持卖仓量、增减量。
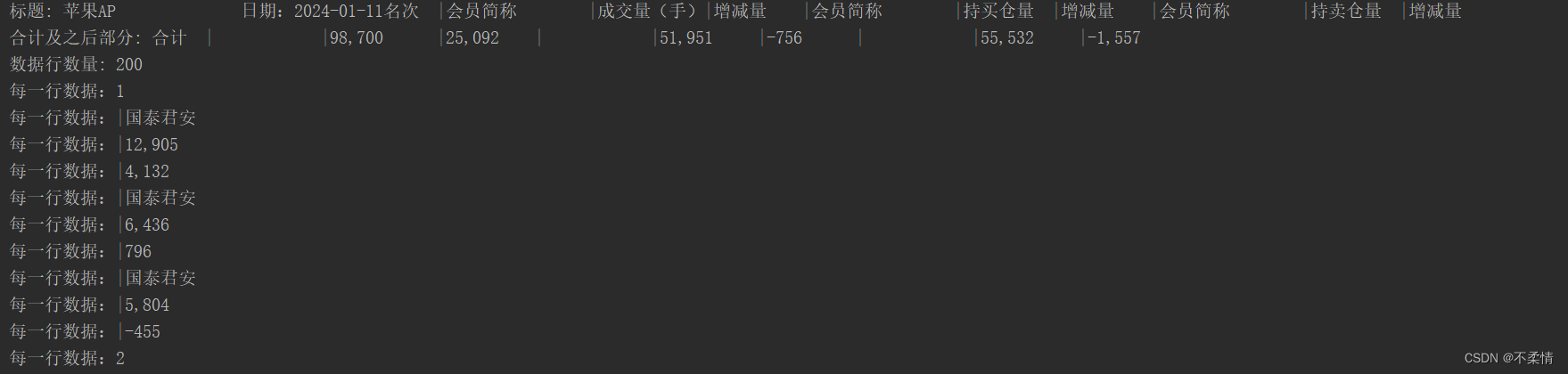
到这里我们只需要将每10行数据依次取出,索引为0123,0456,0789分别构建实例,构建实例时,去掉包含的“|”和空格就好了,通过实例就可以方便的进行如果或者转换为json数据进行转换了。
代码如下:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class MdTradeData implements Serializable {
private static final long serialVersionUID = -7083930889153298835L;
private int id;
/*交易所代码*/
private String exCode;
/*日期*/
private String tradeDate;
/*合约代码*/
private String contractCode;
/*品种*/
private String variety;
/*期货公司*/
private String brokerName;
/*排名*/
private int volOrder;
/*数量*/
private int volumn;
/*增量*/
private int volumnInc;
/*交易类型*/
private String volType;
} for (int i = 0; i < lines.length; i += 10) { // 每10行处理一次
if (i + 9 >= lines.length) {break;} // 防止越界
// 解析名次
int volOrder = Integer.parseInt(lines[i].trim());
// 创建成交量数据实例
MdTradeData volumeData = new MdTradeData();
//交易所名称
volumeData.setExCode("zce");
//日期
volumeData.setTradeDate(dateStr);
//合约名称
volumeData.setContractCode(contractName);
//品种
String Variety1 = contractName.replaceAll("[^A-Z]", ""); // 移除非大写A-Z的任何字符
volumeData.setVariety(Variety1);
//名次
volumeData.setVolOrder(volOrder);
//成交数量
if("-".equals(lines[i + 2].trim().replace("|", ""))){
}else {
volumeData.setVolumn(Integer.parseInt(lines[i + 2].trim().replace("|", "").replaceAll(",", "")));
}
//增减量
if("-".equals(lines[i + 3].trim().replace("|", ""))){
}else {
volumeData.setVolumnInc(Integer.parseInt(lines[i + 3].trim().replace("|", "").replaceAll(",", "")));
}
//买卖类型
volumeData.setVolType("T");
//期货公司名称 如果不存在则直接跳过了
if("-".equals(lines[i + 4].trim().replace("|", ""))){
}else{
volumeData.setBrokerName(lines[i + 1].trim().replace("|", ""));
alldata.add(volumeData);
}
// 创建持买仓量数据实例
MdTradeData buyPositionData = new MdTradeData();
//交易所名称
buyPositionData.setExCode("zce");
//日期
buyPositionData.setTradeDate(dateStr);
//合约名称
buyPositionData.setContractCode(contractName);
//品种
String Variety2 = contractName.replaceAll("[^A-Z]", ""); // 移除非大写A-Z的任何字符
buyPositionData.setVariety(Variety2);
//名次
buyPositionData.setVolOrder(volOrder);
//成交数量
if("-".equals(lines[i + 5].trim().replace("|", ""))){
}else {
buyPositionData.setVolumn(Integer.parseInt(lines[i + 5].trim().replace("|", "").replaceAll(",", "")));
}
//增减量
if("-".equals(lines[i + 6].trim().replace("|", ""))){
}else {
buyPositionData.setVolumnInc(Integer.parseInt(lines[i + 6].trim().replace("|", "").replaceAll(",", "")));
}
//买卖类型
buyPositionData.setVolType("HB");
//期货公司名称 如果不存在则直接跳过了
if("-".equals(lines[i + 4].trim().replace("|", ""))){
}else{
buyPositionData.setBrokerName(lines[i + 1].trim().replace("|", ""));
alldata.add(buyPositionData);
}
// 创建持卖仓量数据实例
MdTradeData sellPositionData = new MdTradeData();
//交易所名称
sellPositionData.setExCode("zce");
//日期
sellPositionData.setTradeDate(dateStr);
//合约名称
sellPositionData.setContractCode(contractName);
//品种
String Variety3 = contractName.replaceAll("[^A-Z]", ""); // 移除非大写A-Z的任何字符
sellPositionData.setVariety(Variety3);
//名次
sellPositionData.setVolOrder(volOrder);
//成交数量
if("-".equals(lines[i + 8].trim().replace("|", ""))){
}else {
sellPositionData.setVolumn(Integer.parseInt(lines[i + 8].trim().replace("|", "").replaceAll(",", "")));
}
//增减量
if("-".equals(lines[i + 9].trim().replace("|", ""))){
}else {
sellPositionData.setVolumnInc(Integer.parseInt(lines[i + 9].trim().replace("|", "").replaceAll(",", "")));
}
//买卖类型
sellPositionData.setVolType("HS");
//期货公司名称 如果不存在则直接跳过了
if("-".equals(lines[i + 7].trim().replace("|", ""))){
}else{
sellPositionData.setBrokerName(lines[i + 1].trim().replace("|", ""));
alldata.add(sellPositionData);
}
}输出: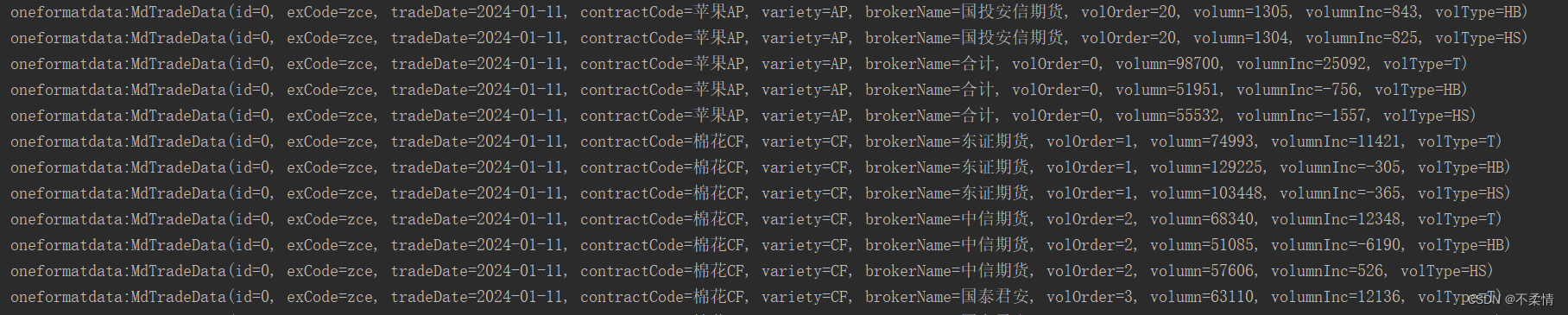
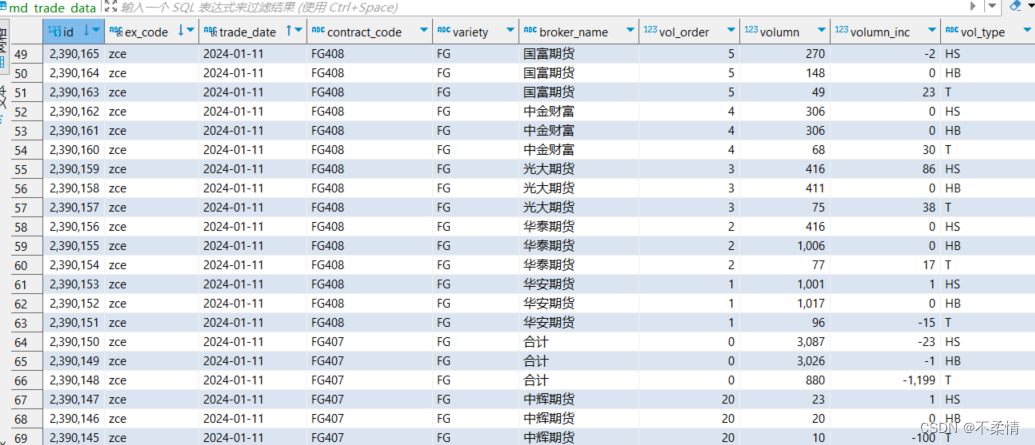
最后batchinsert插入数据库就大功告成:
总结:大字符串处理,必须要熟练使用String类的常用方法还有正则表达式,对于格式特别复杂的字符串不要慌,按照步骤一步一步分析应该如何处理,然后拆分成一个一个小问题逐个解决,还是一句话熟能生巧,任重而道远。
如需要完整代码和数据包自己练习的,可留言或私聊。
















 1670
1670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











