






Python入门:Python3基础练习题详解,从入门到熟练的 25 个实例(四)
Python入门:Python3基础练习题详解,从入门到熟练的 25 个实例(四),本文是关于Python3进阶练习题(76-100)的学习教程,涵盖面向对象编程、函数式编程、算法实现、文件操作、Web开发等领域。文中对每道题都提供了完整代码实现和详细解析,包括用魔术方法自定义对象打印、实现员工和学生管理系统、定义静态方法与类方法、构建图书馆管理系统,以及多继承、抽象类、生成器、迭代器、装饰器、上下文管理器、正则表达式验证、列表排序、数据处理、矩阵乘法、日期计算、排序与查找算法、CSV文件操作、元素筛选、迷宫求解、REST API实现、Flask应用创建和Web爬虫等内容,能帮助学习者巩固提升Python技能。

前言
Python作为一门简洁、易读、功能强大的编程语言,其基础语法是入门学习的核心。掌握好基础语法,能为后续的编程实践打下坚实的基础。本文将全面讲解Python3的基础语法知识,适合编程初学者系统学习。Python以其简洁优雅的语法和强大的通用性,成为当今最受欢迎的编程语言。本专栏旨在系统性地带你从零基础入门到精通Python核心。无论你是零基础小白还是希望进阶的专业开发者,都将通过清晰的讲解、丰富的实例和实战项目,逐步掌握语法基础、核心数据结构、函数与模块、面向对象编程、文件处理、主流库应用(如数据分析、Web开发、自动化)以及面向对象高级特性,最终具备独立开发能力和解决复杂问题的思维,高效应对数据分析、人工智能、Web应用、自动化脚本等广泛领域的实际需求。


🥇 点击进入Python入门专栏,Python凭借简洁易读的语法,是零基础学习编程的理想选择。本专栏专为初学者设计,系统讲解Python核心基础:变量、数据类型、流程控制、函数、文件操作及常用库入门。通过清晰示例与实用小项目,助你快速掌握编程思维,打下坚实根基,迈出自动化办公、数据分析或Web开发的第一步。
🥇 点击进入Python小游戏实战专栏, 寓教于乐,用Python亲手打造经典小游戏!本专栏通过开发贪吃蛇、飞机大战、猜数字、简易版俄罗斯方块等趣味项目,在实践中掌握Python核心语法、面向对象编程、事件处理、图形界面(如Pygame)等关键技能,将枯燥的代码学习转化为可见的成果,让学习编程充满乐趣与成就感,快速提升实战能力。
🥇 点击进入Python小工具实战专栏,告别重复劳动,用Python打造效率神器!本专栏教你开发文件批量处理、自动邮件通知、简易爬虫、桌面提醒、密码生成器、天气查询等实用小工具。聚焦os、shutil、requests、smtplib、schedule等核心库,通过真实场景案例,快速掌握自动化脚本编写技巧,解放双手,显著提升工作与生活效率,让代码真正服务于你的日常。
🥇 点击进入Python爬虫实战专栏,解锁网络数据宝库!本专栏手把手教你使用Python核心库(如requests、BeautifulSoup、Scrapy)构建高效爬虫。从基础网页解析到动态页面抓取、数据存储(CSV/数据库)、反爬策略应对及IP代理使用,通过实战项目(如电商比价、新闻聚合、图片采集、舆情监控),掌握合法合规获取并利用网络数据的核心技能,让数据成为你的超能力。
🥇 点击进入Python项目实战专栏,告别碎片化学习,挑战真实项目!本专栏精选Web应用开发(Flask/Django)、数据分析可视化、自动化办公系统、简易爬虫框架、API接口开发等综合项目。通过需求分析、架构设计、编码实现、测试部署的全流程,深入掌握工程化开发、代码复用、调试排错与团队协作核心能力,积累高质量作品集,真正具备解决复杂问题的Python实战经验。
🌐 前篇文章咱们练习了 Python3基础练习题详解,从入门到熟练的 25 个实例(三) ,如果忘记了,可以去重温一下,不停的重复敲击基础代码,有助于让你更加熟练掌握一门语言。今天咱们继续,八篇教程练习题实例 ,Python3基础练习题详解,从入门到熟练的 25 个实例(四),下面开始吧!
大家好!本文将针对 Python3 进阶练习题(76-100)进行详细讲解,包含完整代码实现和知识点解析。这些题目涵盖了面向对象编程、函数式编程、算法实现、文件操作等多个重要领域,非常适合有一定基础的 Python 学习者巩固提升。
76. 使用魔术方法__str__来自定义对象的打印输出
__str__ 是 Python 中的魔术方法,用于定义对象的字符串表示形式,当使用 print() 函数打印对象时会调用该方法。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# 自定义对象的字符串表示
def __str__(self):
return f"Person(name: {self.name}, age: {self.age})"
# 测试
person = Person("张三", 25)
print(person) # 输出:Person(name: 张三, age: 25)
控制台输出
解释:
- 未定义
__str__时,打印对象会显示类似<__main__.Person object at 0x000001>的内存地址 - 定义后,
print(person)会调用__str__方法,输出我们自定义的格式化字符串 - 该方法必须返回一个字符串,否则会报错
77. 实现一个员工管理系统类
员工管理系统通常需要包含添加、删除、查询员工信息等功能。
class Employee:
"""员工类,存储员工基本信息"""
def __init__(self, id, name, department, salary):
self.id = id
self.name = name
self.department = department
self.salary = salary
class EmployeeManagementSystem:
"""员工管理系统类"""
def __init__(self):
self.employees = [] # 存储员工对象的列表
def add_employee(self, employee):
"""添加员工"""
# 检查员工ID是否已存在
for emp in self.employees:
if emp.id == employee.id:
print(f"错误:ID为{employee.id}的员工已存在")
return
self.employees.append(employee)
print(f"员工{employee.name}添加成功")
def remove_employee(self, emp_id):
"""根据ID删除员工"""
for i, emp in enumerate(self.employees):
if emp.id == emp_id:
removed_emp = self.employees.pop(i)
print(f"员工{removed_emp.name}已删除")
return
print(f"错误:未找到ID为{emp_id}的员工")
def find_employee(self, emp_id):
"""根据ID查询员工"""
for emp in self.employees:
if emp.id == emp_id:
return emp
return None
def display_all(self):
"""显示所有员工信息"""
if not self.employees:
print("没有员工信息")
return
print("所有员工信息:")
for emp in self.employees:
print(f"ID: {emp.id}, 姓名: {emp.name}, 部门: {emp.department}, 薪资: {emp.salary}")
# 测试
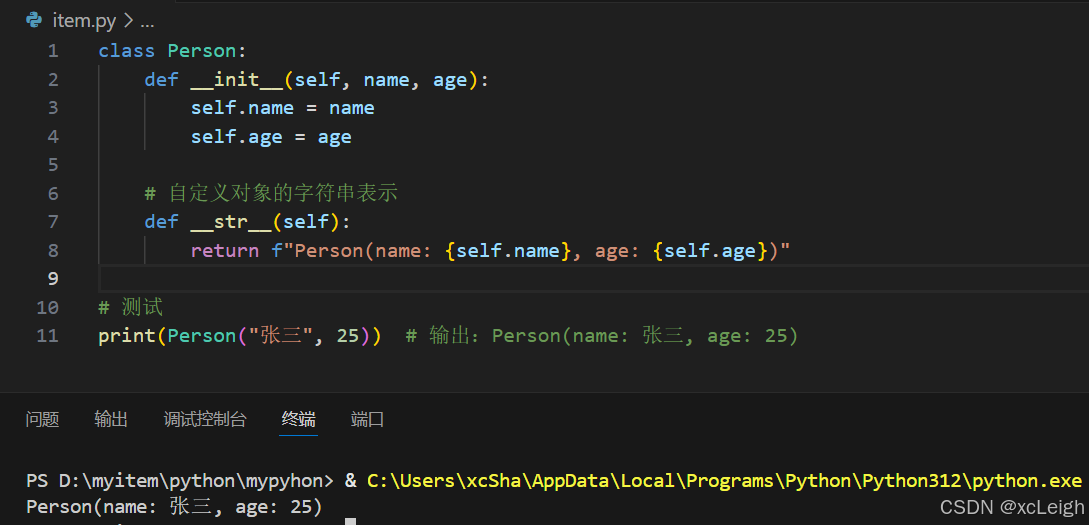
ems = EmployeeManagementSystem()
ems.add_employee(Employee(1, "张三", "技术部", 8000))
ems.add_employee(Employee(2, "李四", "市场部", 7000))
ems.display_all()
ems.remove_employee(1)
ems.display_all()
控制台输出
解释:
- 采用了类的封装思想,将员工信息和管理功能分离到两个类中
Employee类负责存储数据,EmployeeManagementSystem类负责业务逻辑- 实现了基本的 CRUD(增删改查)操作,实际应用中还可扩展排序、统计等功能
78. 使用类实现一个简单的学生成绩管理系统
学生成绩管理系统需要支持添加学生、录入成绩、查询成绩等功能。
class Student:
"""学生类,存储学生信息和成绩"""
def __init__(self, student_id, name):
self.student_id = student_id
self.name = name
self.grades = {} # 用字典存储课程成绩,键为课程名,值为分数
def add_grade(self, course, score):
"""添加课程成绩"""
if 0 <= score <= 100:
self.grades[course] = score
return True
print("成绩必须在0-100之间")
return False
def get_average(self):
"""计算平均成绩"""
if not self.grades:
return 0
return sum(self.grades.values()) / len(self.grades)
class GradeManagementSystem:
"""成绩管理系统类"""
def __init__(self):
self.students = {} # 用字典存储学生,键为学号
def add_student(self, student):
"""添加学生"""
if student.student_id in self.students:
print(f"学号{student.student_id}已存在")
return False
self.students[student.student_id] = student
print(f"学生{student.name}添加成功")
return True
def get_student(self, student_id):
"""获取学生信息"""
return self.students.get(student_id)
def display_student_grades(self, student_id):
"""显示学生所有成绩"""
student = self.get_student(student_id)
if not student:
print("未找到该学生")
return
print(f"{student.name}的成绩:")
for course, score in student.grades.items():
print(f"{course}: {score}分")
print(f"平均分:{student.get_average():.1f}分")
# 测试
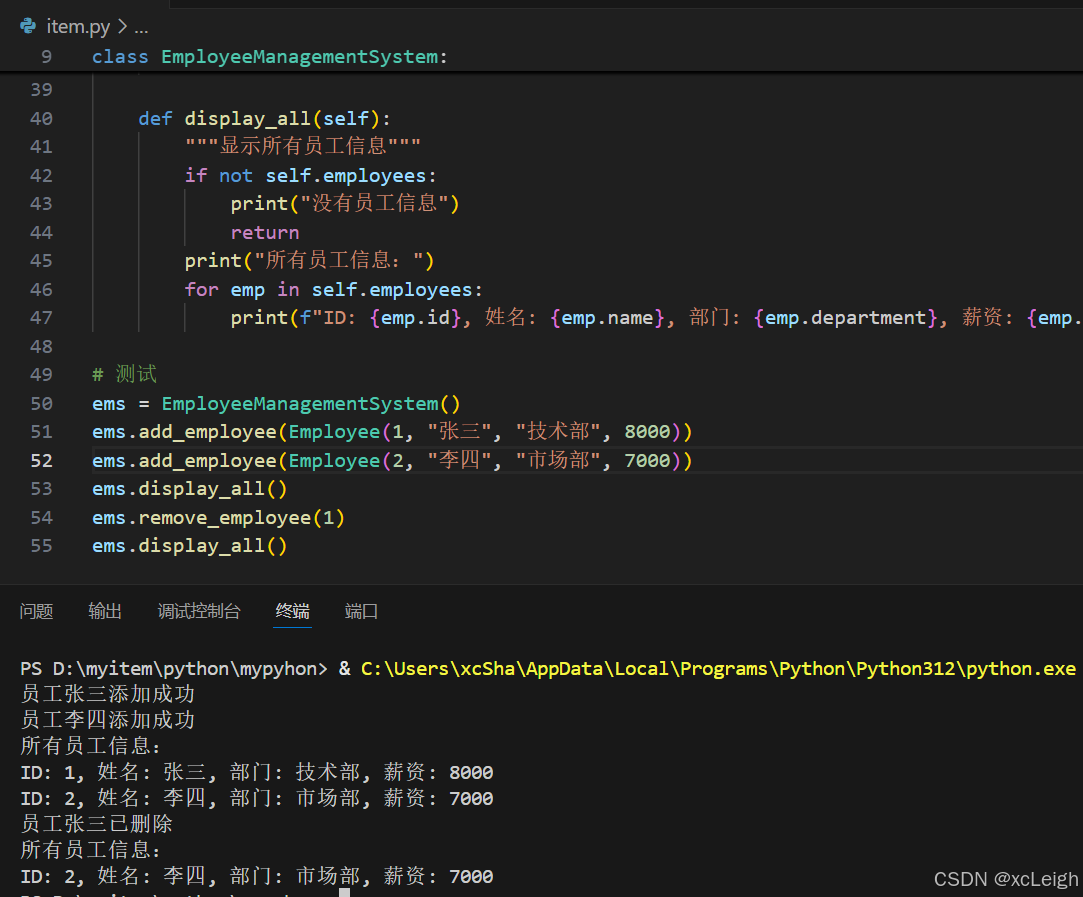
gms = GradeManagementSystem()
gms.add_student(Student(1001, "张三"))
student = gms.get_student(1001)
if student:
student.add_grade("数学", 90)
student.add_grade("英语", 85)
gms.display_student_grades(1001)
控制台输出
解释:
- 学生的成绩用字典存储,方便按课程名查询
- 实现了成绩有效性校验(0-100分)
- 提供了平均分计算功能,体现了面向对象的封装性
- 系统类使用学号作为键存储学生,提高查询效率
79. 使用 staticmethod 定义一个静态方法
静态方法是类中不需要访问实例变量或类变量的方法,使用 @staticmethod 装饰器定义。
class MathUtils:
# 静态方法:计算圆的面积
@staticmethod
def circle_area(radius):
"""根据半径计算圆的面积"""
if radius < 0:
raise ValueError("半径不能为负数")
return 3.14159 * radius ** 2
# 静态方法:计算矩形的面积
@staticmethod
def rectangle_area(length, width):
"""计算矩形的面积"""
if length < 0 or width < 0:
raise ValueError("长和宽不能为负数")
return length * width
# 调用静态方法:不需要创建类的实例,直接通过类名调用
print(f"半径为5的圆面积:{MathUtils.circle_area(5):.2f}")
print(f"长5宽3的矩形面积:{MathUtils.rectangle_area(5, 3)}")
控制台输出
解释:
- 静态方法不需要
self或cls参数 - 调用方式:
类名.方法名(),无需创建实例 - 适合定义工具类方法,即与类相关但不依赖类状态的功能
- 与普通函数相比,静态方法的优势是可以组织在类的命名空间下,使代码结构更清晰
80. 使用 classmethod 定义一个类方法
类方法是绑定到类的方法,使用 @classmethod 装饰器定义,第一个参数是类本身(通常命名为 cls)。
class Person:
species = "人类" # 类变量
def __init__(self, name, age):
self.name = name
self.age = age
# 类方法:创建成年人类实例
@classmethod
def adult(cls, name):
"""创建一个成年人类实例(年龄默认18岁)"""
return cls(name, 18)
# 类方法:获取物种信息
@classmethod
def get_species(cls):
"""返回物种信息"""
return cls.species
def __str__(self):
return f"{self.name}, {self.age}岁, {self.species}"
# 测试
# 创建普通实例
p1 = Person("张三", 20)
print(p1)
# 使用类方法创建实例
p2 = Person.adult("李四")
print(p2)
# 调用类方法获取类变量
print(f"物种:{Person.get_species()}")
解释:
- 类方法的第一个参数是类本身(
cls),通过它可以访问类变量或调用其他类方法 - 常用场景:
- 定义备选构造函数(如示例中的
adult方法) - 操作类变量
- 实现与类相关的工具方法
- 定义备选构造函数(如示例中的
- 调用方式:
类名.方法名()或实例.方法名()
81. 使用 Python 实现一个图书馆管理系统
图书馆管理系统需要支持图书的入库、借阅、归还等功能。
class Book:
"""图书类"""
def __init__(self, book_id, title, author, category):
self.book_id = book_id
self.title = title
self.author = author
self.category = category
self.is_borrowed = False # 是否被借出
def __str__(self):
status = "已借出" if self.is_borrowed else "可借阅"
return f"ID: {self.book_id}, 书名: {self.title}, 作者: {self.author}, 类别: {self.category}, 状态: {status}"
class Library:
"""图书馆类"""
def __init__(self):
self.books = {} # 存储图书,键为图书ID
self.borrow_records = {} # 借阅记录,键为图书ID,值为借阅人
def add_book(self, book):
"""添加图书"""
if book.book_id in self.books:
print(f"图书ID {book.book_id} 已存在")
return False
self.books[book.book_id] = book
print(f"图书《{book.title}》添加成功")
return True
def borrow_book(self, book_id, user):
"""借阅图书"""
book = self.books.get(book_id)
if not book:
print("未找到该图书")
return False
if book.is_borrowed:
print("该图书已被借出")
return False
book.is_borrowed = True
self.borrow_records[book_id] = user
print(f"用户{user}成功借阅《{book.title}》")
return True
def return_book(self, book_id):
"""归还图书"""
book = self.books.get(book_id)
if not book:
print("未找到该图书")
return False
if not book.is_borrowed:
print("该图书未被借出")
return False
book.is_borrowed = False
user = self.borrow_records.pop(book_id)
print(f"用户{user}成功归还《{book.title}》")
return True
def search_book(self, keyword):
"""根据关键词搜索图书"""
results = []
keyword = keyword.lower()
for book in self.books.values():
if (keyword in book.title.lower()) or (keyword in book.author.lower()) or (keyword in book.category.lower()):
results.append(book)
return results
# 测试
lib = Library()
lib.add_book(Book(1, "Python编程", "张三", "编程"))
lib.add_book(Book(2, "数据结构", "李四", "计算机"))
lib.borrow_book(1, "王五")
print(lib.search_book("python"))
lib.return_book(1)
解释:
- 系统包含
Book(图书)和Library(图书馆)两个核心类 - 实现了图书的添加、借阅、归还和搜索功能
- 使用字典存储图书和借阅记录,提高查询效率
- 搜索功能支持按书名、作者和类别进行模糊查询
82. 创建一个多继承的类
多继承指一个类同时继承多个父类,Python 支持多继承,继承顺序可通过 __mro__ 查看。
# 父类1:动物
class Animal:
def __init__(self, name):
self.name = name
def eat(self):
print(f"{self.name}在吃东西")
# 父类2:会跑的
class Runnable:
def run(self):
print(f"{self.name}在跑步")
# 父类3:会飞的
class Flyable:
def fly(self):
print(f"{self.name}在飞")
# 子类:鸟(继承Animal和Flyable)
class Bird(Animal, Flyable):
def __init__(self, name):
# 调用父类的构造方法
super().__init__(name)
def sing(self):
print(f"{self.name}在唱歌")
# 子类:蝙蝠(继承Animal、Runnable和Flyable)
class Bat(Animal, Runnable, Flyable):
def __init__(self, name):
super().__init__(name)
def sleep_by_day(self):
print(f"{self.name}白天睡觉")
# 测试
bird = Bird("麻雀")
bird.eat() # 继承自Animal
bird.fly() # 继承自Flyable
bird.sing() # 自身方法
bat = Bat("蝙蝠")
bat.eat() # 继承自Animal
bat.run() # 继承自Runnable
bat.fly() # 继承自Flyable
bat.sleep_by_day() # 自身方法
# 查看继承顺序
print("Bird类的继承顺序:", Bird.__mro__)
解释:
- 多继承的语法:
class 子类名(父类1, 父类2, ...): - 使用
super()调用父类的方法,Python 会按照__mro__(方法解析顺序)查找父类 - 多继承可能导致菱形问题(多个父类继承自同一个祖先类),使用时需谨慎设计类结构
- 建议:多继承优先使用接口(无实现的抽象类),避免多个有实现的类带来的冲突
83. 使用抽象类定义接口
抽象类是包含抽象方法的类,不能实例化,只能被继承,子类必须实现所有抽象方法。Python 中使用 abc 模块实现抽象类。
from abc import ABC, abstractmethod
# 抽象类(接口):形状
class Shape(ABC):
"""形状接口,定义所有形状都必须实现的方法"""
@abstractmethod
def area(self):
"""计算面积(抽象方法,子类必须实现)"""
pass
@abstractmethod
def perimeter(self):
"""计算周长(抽象方法,子类必须实现)"""
pass
# 实现类:圆形
class Circle(Shape):
def __init__(self, radius):
self.radius = radius
# 实现抽象方法:计算面积
def area(self):
return 3.14159 * self.radius ** 2
# 实现抽象方法:计算周长
def perimeter(self):
return 2 * 3.14159 * self.radius
# 实现类:矩形
class Rectangle(Shape):
def __init__(self, length, width):
self.length = length
self.width = width
def area(self):
return self.length * self.width
def perimeter(self):
return 2 * (self.length + self.width)
# 测试
shapes = [Circle(5), Rectangle(4, 6)]
for shape in shapes:
print(f"面积:{shape.area():.2f}, 周长:{shape.perimeter():.2f}")
# 以下代码会报错(抽象类不能实例化)
# shape = Shape() # TypeError: Can't instantiate abstract class Shape with abstract methods area, perimeter
解释:
- 定义抽象类需继承
ABC(Abstract Base Class) - 抽象方法用
@abstractmethod装饰器标记,只有方法声明,没有实现 - 子类必须实现所有抽象方法,否则也会被视为抽象类,不能实例化
- 抽象类的作用:
- 定义统一接口,强制子类遵循相同的方法规范
- 实现多态,不同子类可以有不同实现,但对外提供一致的调用方式
84. 使用生成器实现一个无限序列
生成器(Generator)是一种特殊的迭代器,使用 yield 关键字返回值,可用于创建无限序列。
def infinite_sequence(start=0):
"""生成从start开始的无限整数序列"""
current = start
while True:
yield current # 使用yield返回当前值,并暂停函数执行
current += 1
# 使用生成器
seq = infinite_sequence(5)
# 取前10个值
for _ in range(10):
print(next(seq), end=" ") # 输出:5 6 7 8 9 10 11 12 13 14
解释:
- 生成器函数通过
yield关键字返回值,每次调用next()时从上次暂停的地方继续执行 - 无限序列不会一次性生成所有值,而是按需生成,节省内存空间
- 常见应用场景:
- 生成无限数据流(如时间戳、计数器)
- 处理大型数据集(无需一次性加载到内存)
- 可通过
itertools模块的islice工具截取生成器的部分内容:from itertools import islice # 直接获取第10到20个元素 for num in islice(infinite_sequence(1), 10, 20): print(num, end=" ") # 输出:11 12 13 14 15 16 17 18 19 20
85. 定义一个迭代器类
迭代器(Iterator)是实现了 __iter__() 和 __next__() 方法的对象,可用于遍历数据集合。
class FibonacciIterator:
"""斐波那契数列迭代器"""
def __init__(self, max_count=None):
self.max_count = max_count # 最大生成数量(None表示无限)
self.count = 0 # 已生成数量
self.a, self.b = 0, 1 # 斐波那契数列的前两个数
def __iter__(self):
"""返回迭代器自身"""
return self
def __next__(self):
"""返回下一个值"""
# 检查是否达到最大数量
if self.max_count is not None and self.count >= self.max_count:
raise StopIteration # 触发迭代结束
# 生成下一个斐波那契数
current = self.a
self.a, self.b = self.b, self.a + self.b
self.count += 1
return current
# 测试有限迭代
print("前10个斐波那契数:")
for num in FibonacciIterator(10):
print(num, end=" ") # 输出:0 1 1 2 3 5 8 13 21 34
# 测试无限迭代(需手动控制终止条件)
print("\n\n取无限序列的前5个:")
fib_infinite = FibonacciIterator()
for _ in range(5):
print(next(fib_infinite), end=" ") # 输出:0 1 1 2 3
解释:
- 迭代器协议:必须实现
__iter__()(返回自身)和__next__()(返回下一个元素,无元素时抛出StopIteration) - 与生成器的区别:迭代器是类实现的,生成器是函数通过
yield实现的,生成器本质是特殊的迭代器 - 优势:
- 支持惰性计算,无需提前生成所有元素
- 适合遍历大型或无限数据集
- 可通过
iter()函数将可迭代对象(如列表、字符串)转换为迭代器
86. 实现一个装饰器函数
装饰器(Decorator)是用于修改函数或类行为的工具,本质是一个接受函数作为参数并返回新函数的高阶函数。
import time
from functools import wraps
def timer_decorator(func):
"""计算函数执行时间的装饰器"""
# 保留原函数的元信息(如函数名、文档字符串)
@wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time() # 记录开始时间
result = func(*args, **kwargs) # 执行原函数
end_time = time.time() # 记录结束时间
print(f"{func.__name__} 执行时间:{end_time - start_time:.6f}秒")
return result # 返回原函数的结果
return wrapper
def log_decorator(func):
"""记录函数调用日志的装饰器"""
@wraps(func)
def wrapper(*args, **kwargs):
print(f"调用 {func.__name__},参数:{args}, {kwargs}")
result = func(*args, **kwargs)
print(f"{func.__name__} 返回:{result}")
return result
return wrapper
# 使用装饰器(可叠加使用)
@log_decorator
@timer_decorator
def calculate_sum(n):
"""计算1到n的和"""
return sum(range(1, n+1))
# 测试
calculate_sum(1000000)
输出示例:
调用 calculate_sum,参数:(1000000,), {}
calculate_sum 执行时间:0.031250秒
calculate_sum 返回:500000500000
解释:
- 装饰器语法:
@装饰器名放在函数定义上方,等价于函数名 = 装饰器名(函数名) *args和**kwargs使装饰器可适配任意参数的函数functools.wraps用于保留原函数的元信息,避免装饰后函数名、文档字符串等被修改- 常见应用场景:
- 性能测试(计时)
- 日志记录
- 权限验证
- 缓存结果
- 装饰器可叠加使用,执行顺序为从里到外(靠近函数的装饰器先执行)
87. 使用上下文管理器管理文件读取
上下文管理器(Context Manager)用于管理资源(如文件、网络连接),确保资源在使用后正确释放,通过 with 语句使用。
# 方式1:使用内置的文件上下文管理器
with open("example.txt", "w", encoding="utf-8") as f:
f.write("Hello, 上下文管理器!")
# 方式2:自定义上下文管理器(实现__enter__和__exit__方法)
class FileManager:
def __init__(self, filename, mode, encoding="utf-8"):
self.filename = filename
self.mode = mode
self.encoding = encoding
self.file = None
def __enter__(self):
"""进入上下文时执行,返回资源对象"""
self.file = open(self.filename, self.mode, encoding=self.encoding)
return self.file
def __exit__(self, exc_type, exc_val, exc_tb):
"""退出上下文时执行,释放资源"""
if self.file:
self.file.close()
# 处理异常(返回True表示已处理,不会向上传播)
if exc_type:
print(f"发生异常:{exc_val}")
return False # 不处理异常,向上传播
# 使用自定义上下文管理器读取文件
with FileManager("example.txt", "r") as f:
content = f.read()
print(content) # 输出:Hello, 上下文管理器!
解释:
- 上下文管理器协议:实现
__enter__()(获取资源)和__exit__()(释放资源)方法 with语句的优势:- 自动释放资源,即使发生异常也能保证资源被正确关闭
- 代码更简洁,避免手动调用
close()方法
- 常见内置上下文管理器:文件对象、
threading.Lock、sqlite3.Connection等 - 也可通过
contextlib.contextmanager装饰器用生成器实现上下文管理器:from contextlib import contextmanager @contextmanager def file_manager(filename, mode): f = open(filename, mode) try: yield f # 相当于__enter__的返回值 finally: f.close() # 相当于__exit__的资源释放
88. 使用正则表达式实现邮箱验证
正则表达式(Regular Expression)是用于匹配字符串模式的工具,可高效验证、提取或替换文本。
import re
def is_valid_email(email):
"""验证邮箱格式是否合法"""
# 邮箱正则表达式模式
# 规则:
# - 用户名:可包含字母、数字、下划线、点、加号、减号
# - @符号:必须有且仅有一个
# - 域名:包含字母、数字、点、减号,最后有一个点和至少2个字母的后缀
pattern = r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$'
# 使用re.match检查是否完全匹配
return re.fullmatch(pattern, email) is not None
# 测试
test_emails = [
"test@example.com", # 合法
"user.name+tag@example.co.uk", # 合法
"invalid-email.com", # 不合法(缺少@)
"user@.com", # 不合法(域名开头为.)
"user@com", # 不合法(缺少域名后缀)
"user@-example.com" # 不合法(域名开头为-)
]
for email in test_emails:
print(f"{email}: {'有效' if is_valid_email(email) else '无效'}")
输出:
test@example.com: 有效
user.name+tag@example.co.uk: 有效
invalid-email.com: 无效
user@.com: 无效
user@com: 无效
user@-example.com: 无效
解释:
- 正则表达式常用符号:
^:匹配字符串开头$:匹配字符串结尾[]:字符集,匹配其中任意一个字符+:匹配前面的元素1次或多次*:匹配前面的元素0次或多次?:匹配前面的元素0次或1次\.:匹配点号(.本身是特殊字符,需转义)
re.fullmatch()用于检查整个字符串是否完全匹配模式- 邮箱验证规则可根据实际需求调整,以上模式仅为通用规则,实际应用中可能需要更严格或宽松的匹配
- 正则表达式调试工具:可使用 RegExr 等在线工具测试模式
89. 使用 lambda 表达式进行列表排序
lambda 表达式用于创建匿名函数,常与 sorted() 等函数结合使用,简化排序逻辑。
# 示例1:对字典列表按指定键排序
students = [
{"name": "张三", "age": 20, "score": 85},
{"name": "李四", "age": 19, "score": 92},
{"name": "王五", "age": 21, "score": 78}
]
# 按年龄升序排序
sorted_by_age = sorted(students, key=lambda x: x["age"])
print("按年龄升序:", sorted_by_age)
# 按分数降序排序
sorted_by_score = sorted(students, key=lambda x: x["score"], reverse=True)
print("按分数降序:", sorted_by_score)
# 示例2:对元组列表按第二个元素排序
products = [("苹果", 5.99), ("香蕉", 3.99), ("橙子", 4.99)]
# 按价格升序排序
sorted_by_price = sorted(products, key=lambda x: x[1])
print("按价格升序:", sorted_by_price)
# 示例3:对字符串列表按长度排序
words = ["apple", "banana", "cherry", "date"]
sorted_by_length = sorted(words, key=lambda x: len(x))
print("按长度升序:", sorted_by_length)
输出:
按年龄升序: [{'name': '李四', 'age': 19, 'score': 92}, {'name': '张三', 'age': 20, 'score': 85}, {'name': '王五', 'age': 21, 'score': 78}]
按分数降序: [{'name': '李四', 'age': 19, 'score': 92}, {'name': '张三', 'age': 20, 'score': 85}, {'name': '王五', 'age': 21, 'score': 78}]
按价格升序: [('香蕉', 3.99), ('橙子', 4.99), ('苹果', 5.99)]
按长度升序: ['date', 'apple', 'cherry', 'banana']
解释:
lambda表达式语法:lambda 参数: 表达式,返回一个函数对象sorted()函数的key参数接受一个函数,用于生成排序依据的值reverse=True表示降序排序(默认reverse=False为升序)- 优势:
- 简化代码,无需单独定义排序函数
- 适合简单的排序逻辑,复杂逻辑建议使用普通函数
- 也可用于
list.sort()方法(会修改原列表):students.sort(key=lambda x: x["name"]) # 按姓名排序
90. 使用 filter 和 map 函数处理数据
filter() 和 map() 是函数式编程中的常用工具,filter() 用于筛选数据,map() 用于转换数据。
# 示例数据
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
people = [
{"name": "张三", "age": 17},
{"name": "李四", "age": 22},
{"name": "王五", "age": 19},
{"name": "赵六", "age": 15}
]
# 1. 使用filter()筛选数据
# filter(函数, 可迭代对象):返回符合条件(函数返回True)的元素
adults = list(filter(lambda x: x["age"] >= 18, people))
print("成年人:", adults)
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print("偶数:", even_numbers)
# 2. 使用map()转换数据
# map(函数, 可迭代对象):对每个元素应用函数,返回转换后的结果
squares = list(map(lambda x: x **2, numbers))
print("平方数:", squares)
names = list(map(lambda x: x["name"], people))
print("姓名列表:", names)
# 3. 结合使用filter()和map()
# 筛选偶数并计算平方
even_squares = list(map(lambda x: x** 2, filter(lambda x: x % 2 == 0, numbers)))
print("偶数的平方:", even_squares)
输出:
成年人: [{'name': '李四', 'age': 22}, {'name': '王五', 'age': 19}]
偶数: [2, 4, 6, 8, 10]
平方数: [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
姓名列表: ['张三', '李四', '王五', '赵六']
偶数的平方: [4, 16, 36, 64, 100]
解释:
filter()工作原理:对可迭代对象中的每个元素应用函数,保留函数返回True的元素map()工作原理:对可迭代对象中的每个元素应用函数,返回所有函数调用结果组成的迭代器- 两者都返回迭代器,需通过
list()转换为列表查看结果 - 与列表推导式的对比:
- 简单场景下,列表推导式更易读(如
[x for x in numbers if x % 2 == 0]等价于filter示例) filter()和map()更适合函数式编程风格,且可与其他函数式工具(如reduce)结合使用
- 简单场景下,列表推导式更易读(如
functools.reduce()可用于对序列进行累积计算(如求和、求积)
91. 编写一个程序实现矩阵乘法
矩阵乘法是线性代数中的基本运算,两个矩阵 A(m×n)和 B(n×p)的乘积是一个 m×p 的矩阵 C,其中 C[i][j] = ΣA[i][k]×B[k][j](k从0到n-1)。
def matrix_multiply(a, b):
"""
实现矩阵乘法
:param a: 第一个矩阵(m×n)
:param b: 第二个矩阵(n×p)
:return: 乘积矩阵(m×p)
"""
# 获取矩阵维度
m = len(a) # a的行数
n = len(b) # b的行数(需等于a的列数)
p = len(b[0]) # b的列数
# 检查矩阵维度是否兼容
if len(a[0]) != n:
raise ValueError("第一个矩阵的列数必须等于第二个矩阵的行数")
# 初始化结果矩阵(m×p)
result = [[0 for _ in range(p)] for _ in range(m)]
# 矩阵乘法核心逻辑
for i in range(m): # 遍历a的行
for j in range(p): # 遍历b的列
# 计算result[i][j]:a的第i行与b的第j列对应元素相乘后求和
total = 0
for k in range(n): # 遍历a的列(或b的行)
total += a[i][k] * b[k][j]
result[i][j] = total
return result
# 测试
a = [
[1, 2, 3],
[4, 5, 6]
] # 2×3矩阵
b = [
[7, 8],
[9, 10],
[11, 12]
] # 3×2矩阵
c = matrix_multiply(a, b)
print("矩阵乘积:")
for row in c:
print(row) # 输出:[58, 64], [139, 154]
解释:
- 矩阵乘法的前提条件:第一个矩阵的列数必须等于第二个矩阵的行数
- 结果矩阵的行数等于第一个矩阵的行数,列数等于第二个矩阵的列数
- 核心公式:
result[i][j] = a[i][0]*b[0][j] + a[i][1]*b[1][j] + ... + a[i][n-1]*b[n-1][j] - 优化方向:
- 对于大型矩阵,可使用
numpy库的dot()方法(基于C实现,效率更高) - 示例:
import numpy; print(numpy.dot(a, b))
- 对于大型矩阵,可使用
92. 使用 Python 计算两个日期之间的天数差
Python 的 datetime 模块提供了日期时间处理功能,可方便计算两个日期的差值。
from datetime import date, datetime
def days_between_dates(date1, date2):
"""
计算两个日期之间的天数差(绝对值)
:param date1: 第一个日期(date或datetime对象)
:param date2: 第二个日期(date或datetime对象)
:return: 天数差
"""
delta = date1 - date2
return abs(delta.days)
# 方法1:使用date对象(仅日期)
d1 = date(2023, 1, 1)
d2 = date(2023, 12, 31)
print(f"2023年1月1日到2023年12月31日相差:{days_between_dates(d1, d2)}天")
# 方法2:使用datetime对象(包含时间,时间部分不影响天数差)
dt1 = datetime(2023, 2, 1)
dt2 = datetime(2023, 3, 1)
print(f"2023年2月1日到2023年3月1日相差:{days_between_dates(dt1, dt2)}天")
# 方法3:从字符串解析日期
date_str1 = "2024-02-28"
date_str2 = "2024-03-01" # 2024是闰年,2月有29天
dt1 = datetime.strptime(date_str1, "%Y-%m-%d").date()
dt2 = datetime.strptime(date_str2, "%Y-%m-%d").date()
print(f"{date_str1}到{date_str2}相差:{days_between_dates(dt1, dt2)}天")
输出:
2023年1月1日到2023年12月31日相差:364天
2023年2月1日到2023年3月1日相差:28天
2024-02-28到2024-03-01相差:2天
解释:
date类用于处理日期(年、月、日),datetime类用于处理日期和时间- 两个日期对象相减得到
timedelta对象,其days属性即为天数差 strptime()用于将字符串解析为日期对象,格式符说明:%Y:四位数年份(如2023)%m:两位数月份(01-12)%d:两位数日期(01-31)
- 常见需求扩展:
- 计算n天后的日期:
new_date = d1 + timedelta(days=n) - 格式化日期为字符串:
d1.strftime("%Y年%m月%d日")
- 计算n天后的日期:
93. 使用 Python 实现冒泡排序算法
冒泡排序是一种简单的排序算法,通过重复比较相邻元素并交换位置,使较大的元素"浮"到末尾。
def bubble_sort(arr):
"""
冒泡排序算法
:param arr: 待排序的列表
:return: 排序后的列表(从小到大)
"""
# 复制原列表,避免修改输入数据
arr = arr.copy()
n = len(arr)
# 外层循环:控制需要进行多少轮比较
for i in range(n - 1):
# 标记本轮是否发生交换,优化算法
swapped = False
# 内层循环:每轮比较相邻元素
# 每轮结束后,最大的元素已"浮"到末尾,无需再比较
for j in range(n - 1 - i):
if arr[j] > arr[j + 1]:
# 交换相邻元素
arr[j], arr[j + 1] = arr[j + 1], arr[j]
swapped = True
# 如果本轮没有交换,说明列表已有序,提前退出
if not swapped:
break
return arr
# 测试
test_arrays = [
[3, 1, 4, 1, 5, 9, 2, 6],
[5, 4, 3, 2, 1],
[1, 2, 3, 4, 5] # 已排序,测试优化效果
]
for arr in test_arrays:
sorted_arr = bubble_sort(arr)
print(f"原始列表:{arr},排序后:{sorted_arr}")
输出:
原始列表:[3, 1, 4, 1, 5, 9, 2, 6],排序后:[1, 1, 2, 3, 4, 5, 6, 9]
原始列表:[5, 4, 3, 2, 1],排序后:[1, 2, 3, 4, 5]
原始列表:[1, 2, 3, 4, 5],排序后:[1, 2, 3, 4, 5]
解释:
- 算法特点:
- 时间复杂度:平均和最坏情况为 O(n²),最好情况(已排序)为 O(n)
- 空间复杂度:O(1)(原地排序)
- 稳定性:稳定排序(相等元素的相对位置不变)
- 优化点:
- 加入
swapped标记,当一轮比较中没有交换时,说明列表已有序,可提前终止 - 每轮循环的范围逐渐缩小(
n-1-i),因为尾部的元素已排好序
- 加入
- 适用场景:小规模数据集或接近有序的数据集
94. 编写一个程序实现二分查找
二分查找(Binary Search)是一种高效的查找算法,适用于已排序的数据集,通过不断缩小查找范围来定位目标值。
def binary_search(arr, target):
"""
二分查找算法(迭代实现)
:param arr: 已排序的列表(从小到大)
:param target: 目标值
:return: 目标值在列表中的索引,未找到返回-1
"""
left = 0 # 左边界索引
right = len(arr) - 1 # 右边界索引
while left <= right:
mid = (left + right) // 2 # 计算中间索引
mid_val = arr[mid]
if mid_val == target:
return mid # 找到目标,返回索引
elif mid_val < target:
left = mid + 1 # 目标在右半部分,调整左边界
else:
right = mid - 1 # 目标在左半部分,调整右边界
return -1 # 未找到目标
# 递归实现(可选)
def binary_search_recursive(arr, target, left, right):
if left > right:
return -1
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
return binary_search_recursive(arr, target, mid + 1, right)
else:
return binary_search_recursive(arr, target, left, mid - 1)
# 测试
sorted_arr = [2, 5, 8, 12, 16, 23, 38, 56, 72, 91]
targets = [23, 5, 100, 8]
for target in targets:
index = binary_search(sorted_arr, target)
if index != -1:
print(f"找到 {target},索引为 {index}")
else:
print(f"未找到 {target}")
# 测试递归版本
print("\n递归版本测试:")
print(binary_search_recursive(sorted_arr, 16, 0, len(sorted_arr)-1)) # 输出:4
输出:
找到 23,索引为 5
找到 5,索引为 1
未找到 100
找到 8,索引为 2
递归版本测试:
4
解释:
- 算法步骤:
- 确定查找范围的左右边界(
left和right) - 计算中间索引
mid,比较中间值与目标值 - 根据比较结果调整边界(左半部分或右半部分)
- 重复步骤2-3,直到找到目标或范围为空
- 确定查找范围的左右边界(
- 算法特点:
- 时间复杂度:O(log n)(远优于线性查找的 O(n))
- 空间复杂度:迭代实现 O(1),递归实现 O(log n)(递归栈开销)
- 前提:数据集必须已排序
- 适用场景:静态数据(不常修改)的查找,如字典查询、数据库索引等
95. 使用 Python 读取并写入 CSV 文件
CSV(逗号分隔值)是一种常见的表格数据格式,Python 的 csv 模块提供了专门的处理工具。
import csv
# 1. 写入CSV文件
data = [
["姓名", "年龄", "城市"],
["张三", 25, "北京"],
["李四", 30, "上海"],
["王五", 28, "广州"]
]
with open("people.csv", "w", encoding="utf-8", newline="") as f:
# 创建CSV写入器
writer = csv.writer(f)
# 写入多行数据
writer.writerows(data)
# 也可单行写入:writer.writerow(["赵六", 35, "深圳"])
# 2. 读取CSV文件
print("读取CSV文件内容:")
with open("people.csv", "r", encoding="utf-8") as f:
# 创建CSV阅读器
reader = csv.reader(f)
# 遍历所有行
for row in reader:
print(row)
# 3. 读写字典格式的CSV(带表头)
fieldnames = ["姓名", "年龄", "城市"]
dict_data = [
{"姓名": "孙七", "年龄": 40, "城市": "杭州"},
{"姓名": "周八", "年龄": 33, "城市": "成都"}
]
# 写入字典数据
with open("people_dict.csv", "w", encoding="utf-8", newline="") as f:
# 创建字典写入器(指定表头)
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader() # 写入表头
writer.writerows(dict_data) # 写入数据行
# 读取字典数据
print("\n读取字典格式CSV:")
with open("people_dict.csv", "r", encoding="utf-8") as f:
reader = csv.DictReader(f) # 自动使用第一行作为表头
for row in reader:
print(f"{row['姓名']},{row['年龄']}岁,来自{row['城市']}")
解释:
newline=""用于避免写入时出现空行(Windows系统特有的问题)csv.writer适用于列表形式的数据,csv.DictWriter适用于字典形式的数据(需指定表头)- 读取时,
csv.reader返回列表,csv.DictReader返回字典(键为表头) - 高级用法:
- 自定义分隔符:
csv.reader(f, delimiter=";")(如处理分号分隔的文件) - 处理带引号的字段:默认支持带引号的字段(如包含逗号的内容)
- 对于大型CSV文件,可使用
pandas库(pd.read_csv()和pd.to_csv())更高效处理
- 自定义分隔符:
96. 实现一个函数找出列表中所有符合条件的元素
通过自定义条件函数,可灵活筛选列表中符合要求的元素。
def find_elements(lst, condition):
"""
找出列表中所有符合条件的元素
:param lst: 待筛选的列表
:param condition: 条件函数(返回布尔值)
:return: 符合条件的元素组成的新列表
"""
return [item for item in lst if condition(item)]
# 示例1:筛选偶数
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
even_numbers = find_elements(numbers, lambda x: x % 2 == 0)
print("偶数:", even_numbers)
# 示例2:筛选长度大于3的字符串
words = ["apple", "cat", "banana", "dog", "cherry"]
long_words = find_elements(words, lambda x: len(x) > 3)
print("长度大于3的单词:", long_words)
# 示例3:筛选年龄大于等于18的成年人
people = [
{"name": "张三", "age": 17},
{"name": "李四", "age": 22},
{"name": "王五", "age": 19}
]
adults = find_elements(people, lambda x: x["age"] >= 18)
print("成年人:", adults)
# 示例4:使用自定义函数作为条件
def is_prime(n):
"""判断是否为质数"""
if n <= 1:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
primes = find_elements(range(1, 30), is_prime)
print("1-30中的质数:", primes)
输出:
偶数: [2, 4, 6, 8, 10]
长度大于3的单词: ['apple', 'banana', 'cherry']
成年人: [{'name': '李四', 'age': 22}, {'name': '王五', 'age': 19}]
1-30中的质数: [2, 3, 5, 7, 11, 13, 17, 19, 23, 29]
解释:
- 核心思想:通过回调函数(
condition参数)定义筛选规则,使函数具有通用性 - 实现方式:使用列表推导式遍历元素,仅保留
condition(item)为True的元素 - 优势:
- 代码复用:一个函数可以应对各种筛选需求,无需为每种条件单独编写函数
- 灵活性高:条件函数可以是简单的
lambda表达式,也可以是复杂的自定义函数
- 与
filter()函数的对比:- 功能相似,但
find_elements直接返回列表,而filter()返回迭代器 - 列表推导式的可读性通常优于
filter()与lambda的组合
- 功能相似,但
- 扩展场景:
- 可添加
reverse参数控制结果顺序 - 可添加
limit参数限制返回元素数量
- 可添加
97. 实现一个迷宫求解算法
迷宫求解是经典的路径搜索问题,常用深度优先搜索(DFS)或广度优先搜索(BFS)算法。以下实现基于DFS。
def solve_maze(maze, start, end):
"""
深度优先搜索求解迷宫
:param maze: 迷宫矩阵(0表示通路,1表示墙壁)
:param start: 起点坐标 (row, col)
:param end: 终点坐标 (row, col)
:return: 从起点到终点的路径列表,无解则返回空列表
"""
# 获取迷宫尺寸
rows = len(maze)
cols = len(maze[0]) if rows > 0 else 0
# 记录已访问的位置
visited = [[False for _ in range(cols)] for _ in range(rows)]
# 可能的移动方向:上、右、下、左
directions = [(-1, 0), (0, 1), (1, 0), (0, -1)]
# 深度优先搜索递归函数
def dfs(current, path):
# 到达终点,返回路径
if current == end:
return path + [current]
row, col = current
# 检查当前位置是否合法(在迷宫内、不是墙壁、未访问)
if (0 <= row < rows and 0 <= col < cols and
maze[row][col] == 0 and not visited[row][col]):
visited[row][col] = True # 标记为已访问
# 尝试所有方向
for dr, dc in directions:
next_row, next_col = row + dr, col + dc
result = dfs((next_row, next_col), path + [current])
if result: # 找到路径则返回
return result
# 回溯:如果所有方向都走不通,取消标记
visited[row][col] = False
return None # 无有效路径
# 开始搜索
return dfs(start, [])
# 测试迷宫
maze = [
[0, 1, 0, 0, 0],
[0, 1, 0, 1, 0],
[0, 0, 0, 1, 0],
[0, 1, 1, 1, 0],
[0, 0, 0, 0, 0]
]
start = (0, 0) # 起点:左上角
end = (4, 4) # 终点:右下角
path = solve_maze(maze, start, end)
if path:
print("找到路径:")
for step in path:
print(step, end=" -> ")
print("终点")
else:
print("未找到路径")
输出:
找到路径:
(0, 0) -> (1, 0) -> (2, 0) -> (2, 1) -> (2, 2) -> (3, 2) -> (4, 2) -> (4, 3) -> (4, 4) -> 终点
解释:
- 迷宫表示:二维列表,
0表示可通行,1表示障碍物 - DFS 算法核心:
- 从起点开始,尝试所有可能的移动方向
- 标记已访问的位置,避免重复探索
- 若到达终点则返回路径,否则回溯到上一步继续尝试其他方向
- 关键数据结构:
visited矩阵:记录已访问的位置,防止死循环directions列表:定义上下左右四个移动方向
- 优化方向:
- BFS 算法可找到最短路径(DFS 不一定是最短路径)
- 可添加路径标记功能,在迷宫矩阵中标记出求解路径
98. 使用 Python 模块实现 REST API
使用 Flask 框架可快速实现 REST API,以下示例创建一个简单的图书管理 API。
首先安装 Flask:pip install flask
from flask import Flask, jsonify, request
app = Flask(__name__)
# 模拟数据库
books = [
{"id": 1, "title": "Python编程", "author": "张三"},
{"id": 2, "title": "数据结构", "author": "李四"}
]
next_id = 3 # 下一个可用ID
# 获取所有图书
@app.route('/api/books', methods=['GET'])
def get_books():
return jsonify({"books": books})
# 获取单本图书
@app.route('/api/books/<int:book_id>', methods=['GET'])
def get_book(book_id):
book = next((b for b in books if b['id'] == book_id), None)
if book:
return jsonify(book)
return jsonify({"error": "图书不存在"}), 404
# 添加图书
@app.route('/api/books', methods=['POST'])
def add_book():
global next_id
if not request.json or 'title' not in request.json:
return jsonify({"error": "标题不能为空"}), 400
book = {
"id": next_id,
"title": request.json['title'],
"author": request.json.get('author', "")
}
books.append(book)
next_id += 1
return jsonify(book), 201 # 201表示创建成功
# 更新图书
@app.route('/api/books/<int:book_id>', methods=['PUT'])
def update_book(book_id):
book = next((b for b in books if b['id'] == book_id), None)
if not book:
return jsonify({"error": "图书不存在"}), 404
if not request.json:
return jsonify({"error": "无效数据"}), 400
book['title'] = request.json.get('title', book['title'])
book['author'] = request.json.get('author', book['author'])
return jsonify(book)
# 删除图书
@app.route('/api/books/<int:book_id>', methods=['DELETE'])
def delete_book(book_id):
global books
book = next((b for b in books if b['id'] == book_id), None)
if not book:
return jsonify({"error": "图书不存在"}), 404
books = [b for b in books if b['id'] != book_id]
return jsonify({"result": "删除成功"}), 200
if __name__ == '__main__':
app.run(debug=True) # 启动服务器,debug模式便于开发
使用方法:
- 启动服务器后,可通过工具(如 Postman、curl)测试 API:
- 获取所有图书:
GET http://localhost:5000/api/books - 添加图书:
POST http://localhost:5000/api/books,请求体为{"title": "新图书", "author": "作者"} - 更新图书:
PUT http://localhost:5000/api/books/1 - 删除图书:
DELETE http://localhost:5000/api/books/1
- 获取所有图书:
解释:
- REST API 设计原则:使用 HTTP 方法(GET/POST/PUT/DELETE)对应 CRUD 操作
jsonify()用于将 Python 字典转换为 JSON 响应request.json用于获取请求体中的 JSON 数据- 状态码说明:
- 200:成功
- 201:创建成功
- 400:请求错误
- 404:资源不存在
- 生产环境优化:
- 使用数据库(如 SQLAlchemy 连接 MySQL)替代模拟数据
- 添加身份验证(如 JWT)
- 处理异常和输入验证
99. 创建一个 Flask 或 Django 应用
以下创建一个简单的 Flask 应用,实现用户注册和登录功能(基于会话的认证)。
from flask import Flask, render_template_string, request, redirect, url_for, session
import hashlib
app = Flask(__name__)
app.secret_key = 'supersecretkey' # 用于会话加密,生产环境需更换为随机字符串
# 模拟用户数据库(实际应用使用数据库)
users = {
# 密码使用MD5哈希存储(实际应用建议使用更安全的算法如bcrypt)
"admin": hashlib.md5("admin123".encode()).hexdigest()
}
# HTML模板(实际应用使用单独的templates文件夹)
REGISTER_TEMPLATE = """
<h1>注册</h1>
<form method="post">
用户名: <input type="text" name="username" required><br>
密码: <input type="password" name="password" required><br>
<button type="submit">注册</button>
</form>
{% if error %}
<p style="color: red;">{{ error }}</p>
{% endif %}
<p>已有账号?<a href="{{ url_for('login') }}">登录</a></p>
"""
LOGIN_TEMPLATE = """
<h1>登录</h1>
<form method="post">
用户名: <input type="text" name="username" required><br>
密码: <input type="password" name="password" required><br>
<button type="submit">登录</button>
</form>
{% if error %}
<p style="color: red;">{{ error }}</p>
{% endif %}
<p>没有账号?<a href="{{ url_for('register') }}">注册</a></p>
"""
HOME_TEMPLATE = """
<h1>欢迎回来,{{ username }}!</h1>
<a href="{{ url_for('logout') }}">退出登录</a>
"""
# 路由
@app.route('/')
def home():
# 检查用户是否登录
if 'username' in session:
return render_template_string(HOME_TEMPLATE, username=session['username'])
return redirect(url_for('login'))
@app.route('/register', methods=['GET', 'POST'])
def register():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
if username in users:
return render_template_string(REGISTER_TEMPLATE, error="用户名已存在")
# 存储密码哈希
users[username] = hashlib.md5(password.encode()).hexdigest()
return redirect(url_for('login'))
return render_template_string(REGISTER_TEMPLATE)
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
password_hash = hashlib.md5(password.encode()).hexdigest()
if username in users and users[username] == password_hash:
# 登录成功,设置会话
session['username'] = username
return redirect(url_for('home'))
else:
return render_template_string(LOGIN_TEMPLATE, error="用户名或密码错误")
return render_template_string(LOGIN_TEMPLATE)
@app.route('/logout')
def logout():
# 清除会话
session.pop('username', None)
return redirect(url_for('login'))
if __name__ == '__main__':
app.run(debug=True)
功能说明:
- 访问
http://localhost:5000会自动跳转至登录页 - 支持用户注册(用户名和密码)
- 登录后保存会话状态,可访问主页
- 提供退出登录功能
解释:
- 会话管理:
session对象用于存储用户状态,依赖secret_key加密 - 密码安全:示例使用 MD5 哈希存储密码(仅演示用),实际应用应使用
bcrypt等带盐值的哈希算法 - 模板系统:示例使用内联模板,实际项目建议将模板文件放在
templates文件夹中 - 扩展功能:
- 添加邮箱验证
- 实现密码重置
- 连接数据库(如 SQLite、MySQL)
100. 使用 Python 实现一个简单的 web 爬虫
使用 requests 和 BeautifulSoup 库爬取网页内容,以下示例爬取豆瓣电影 Top250 的电影名称和评分。
首先安装依赖:pip install requests beautifulsoup4
import requests
from bs4 import BeautifulSoup
import time
def crawl_douban_top250(page=0):
"""
爬取豆瓣电影Top250
:param page: 页码(0开始,每页25部电影)
:return: 电影列表,每个元素为字典{"title": 标题, "rating": 评分}
"""
url = f"https://movie.douban.com/top250?start={page*25}&filter="
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
try:
# 发送请求
response = requests.get(url, headers=headers)
response.raise_for_status() # 抛出HTTP错误状态码
# 解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
items = soup.find_all('div', class_='item')
movies = []
for item in items:
# 提取电影标题
title = item.find('span', class_='title').text
# 提取评分
rating = item.find('span', class_='rating_num').text
movies.append({
"title": title,
"rating": rating
})
return movies
except requests.exceptions.RequestException as e:
print(f"爬取失败:{e}")
return []
# 爬取前100部电影(4页)
all_movies = []
for page in range(4):
print(f"爬取第{page+1}页...")
movies = crawl_douban_top250(page)
all_movies.extend(movies)
time.sleep(1) # 休眠1秒,避免请求过于频繁
# 保存结果
with open("douban_top250.txt", "w", encoding="utf-8") as f:
for i, movie in enumerate(all_movies, 1):
f.write(f"{i}. {movie['title']} 评分:{movie['rating']}\n")
print("爬取完成,结果已保存到 douban_top250.txt")
解释:
- 核心库作用:
requests:发送 HTTP 请求,获取网页内容BeautifulSoup:解析 HTML 文档,提取所需数据
- 反爬措施:
- 设置
User-Agent头,模拟浏览器请求 - 加入延迟(
time.sleep),避免短时间内发送大量请求
- 设置
- 数据提取:
- 使用
find()和find_all()查找 HTML 元素 - 通过
class_参数匹配特定类名的元素
- 使用
- 注意事项:
- 遵守网站的
robots.txt协议 - 不要过度爬取,以免给服务器造成负担
- 部分网站需要登录或处理验证码,需额外处理
- 遵守网站的
扩展功能:
- 爬取更多字段(导演、主演、上映年份等)
- 实现分页爬取全部250部电影
- 将结果保存为 CSV 或 JSON 格式
总结
本文涵盖了 Python3 进阶练习题 76-100 的实现,涉及面向对象编程、函数式编程、算法、文件操作、Web 开发等多个领域。这些题目不仅能帮助巩固基础知识,还能培养解决实际问题的能力。
建议学习时结合实际场景练习,例如:
- 将学生管理系统与文件存储结合,实现数据持久化
- 使用爬虫收集数据后,用数据分析库(如 pandas)进行处理
- 尝试优化算法,比较不同实现的效率差异
希望本文对大家的 Python 学习有所帮助,祝大家编程愉快!
💡下一篇咱们学习 Python3基础练习题详解,从入门到熟练的 25 个实例(五)!
附录:扩展学习资源
- 官方资源:
- Python官网:https://www.python.org
- PyPI:https://pypi.org(查找第三方库)
- 安装包等相关文件(另附带pycharm工具),网盘下载地址:https://pan.quark.cn/s/649af731037c
- 学习资料视频和文档资源,网盘下载地址: https://pan.quark.cn/s/ee16901a8954
- 本专栏特色资源:
- 代码资源仓库:CSDN专属资源在线获取
- 海量Python教程:关注公众号:xcLeigh,获取网盘地址
- 一对一答疑:添加微信与博主在线沟通(
备注“Python专栏”)
联系博主
xcLeigh 博主,全栈领域优质创作者,博客专家,目前,活跃在CSDN、微信公众号、小红书、知乎、掘金、快手、思否、微博、51CTO、B站、腾讯云开发者社区、阿里云开发者社区等平台,全网拥有几十万的粉丝,全网统一IP为 xcLeigh。希望通过我的分享,让大家能在喜悦的情况下收获到有用的知识。主要分享编程、开发工具、算法、技术学习心得等内容。很多读者评价他的文章简洁易懂,尤其对于一些复杂的技术话题,他能通过通俗的语言来解释,帮助初学者更好地理解。博客通常也会涉及一些实践经验,项目分享以及解决实际开发中遇到的问题。如果你是开发领域的初学者,或者在学习一些新的编程语言或框架,关注他的文章对你有很大帮助。
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
💞 关注博主 🌀 带你实现畅游前后端!
🏰 大屏可视化 🌀 带你体验酷炫大屏!
💯 神秘个人简介 🌀 带你体验不一样得介绍!
🥇 从零到一学习Python 🌀 带你玩转Python技术流!
🏆 前沿应用深度测评 🌀 前沿AI产品热门应用在线等你来发掘!
💦 注:本文撰写于CSDN平台,作者:xcLeigh(所有权归作者所有) ,https://xcleigh.blog.csdn.net/,如果相关下载没有跳转,请查看这个地址,相关链接没有跳转,皆是抄袭本文,转载请备注本文原地址。

📣 亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 🈶 问题请留言(或者关注下方公众号,看见后第一时间回复,还有海量编程资料等你来领!),博主看见后一定及时给您答复 💌💌💌



















 40万+
40万+













 到【灌水乐园】发言
到【灌水乐园】发言









