






最近因为要做命名实体识别(NER),看了很多文献都是使用BiLSTM-CRF,可是自己连初级的LSTM都不懂啊。于是打算对LSTM进行深入学习,再往后拓展,顺便分享一些自己的心得。
废话不多说,正文开始
RNN
为什么要提到RNN呢?主要是为了让大家了解一下LSTM的优势在哪里,其实这一部分可以不用详细了解。首先看一下RNN的结构
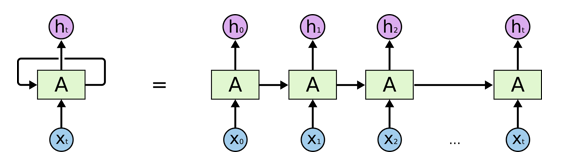
等号左边是一个RNN网络模型,右边是展开的一个形状。对于一般的神经网络来说,输入x到神经单元A直接就是输出h了,没有循环这个过程(即向右的箭头)。对于任意输入
X
i
X_i
Xi都有
h
i
=
f
A
(
x
i
)
h_i=f_A(x_i)
hi=fA(xi)。其中,
f
A
f_A
fA一般是tanh函数,如下图。而RNN加入了一条类似于记忆点的路径,将之前的信息考虑进来,此时
h
0
=
f
A
(
X
0
)
,
h
1
=
f
A
(
X
1
,
h
0
)
,
.
.
.
,
h
t
=
f
A
(
X
t
,
h
t
−
1
)
h_0=f_A(X_0), h_1=f_A(X_1,h_0),..., h_t=f_A(X_t,h_{t-1})
h0=fA(X0),h1=fA(X1,h0),...,ht=fA(Xt,ht−1),每一个输入都会考虑之前的输出。

LSTM
现在,RNN网络具有获取之前信息的作用,看起来挺不错,似乎能够处理句子序列了。但是如果我需要考虑更早之前的信息,那么RNN网络似乎就做不到了。于是人们设计了一个新的网络,就是今天的主角:LSTM。他的结构大体和RNN一样,只不过多了一些函数(人们将其称为Gate):

看起来很复杂,不过我相信很多博客都讲解了它的原理(参照这里),黄色框框代表的一个线性模型然后接激活函数(门单元一般接的是sigmoid函数)。红色框框代表着普通数学运算。第一个
σ
σ
σ单元表示的是遗忘门,当取值为1时,上一层的记忆会被保留;第二个
σ
σ
σ单元表示的是输入门,它决定着输入是否可取;输入值和记忆值相加后经过第三个
σ
σ
σ单元(输出门),由它来决定此时是否需要输出。下面我将举一个具体的例子来说明,为了计算简便,我用一元线性函数
f
(
x
)
=
x
f(x)=x
f(x)=x代替
t
a
n
h
tanh
tanh函数。
首先,假设我们的输入序列
X
=
[
X
1
,
X
2
,
X
3
,
X
4
]
X=[X_1,X_2,X_3,X_4]
X=[X1,X2,X3,X4]经过向量化后得到
X
1
=
[
2
,
−
1
,
1
]
,
X
2
=
[
3
,
1
,
−
1
]
,
X
3
=
[
2
,
1
,
1
]
,
X
4
=
[
1
,
0
,
−
1
]
X_1=[2,-1,1], X_2=[3,1,-1],X_3=[2,1,1],X_4=[1,0,-1]
X1=[2,−1,1],X2=[3,1,−1],X3=[2,1,1],X4=[1,0,−1]。那么这个序列经过一个训练好的LSTM后会输出什么呢?让我们来一步步计算看看,初始化
C
0
=
1
,
h
0
=
1
C_0=1,h_0=1
C0=1,h0=1。

s
t
e
p
1
:
X
1
step1:X_1
step1:X1和初始化
h
0
h_0
h0拼接后分别乘以权重矩阵
X
1
∗
W
σ
1
=
[
2
,
−
1
,
1
,
1
]
[
0
100
0
10
]
=
0
−
100
+
0
+
10
=
−
90
⟶
s
i
g
m
o
i
d
0
X_1*W_{\sigma1}=[2,-1,1,1]\begin{bmatrix} 0\\100\\0\\10 \end{bmatrix}=0-100+0+10=-90\overset{sigmoid}{\longrightarrow}0
X1∗Wσ1=[2,−1,1,1]⎣⎢⎢⎡0100010⎦⎥⎥⎤=0−100+0+10=−90⟶sigmoid0
X
1
∗
W
σ
2
=
[
2
,
−
1
,
1
,
1
]
[
0
0
100
−
10
]
=
0
+
0
+
100
−
10
=
90
⟶
s
i
g
m
o
i
d
1
X_1*W_{\sigma2}=[2,-1,1,1]\begin{bmatrix} 0\\0\\100\\-10 \end{bmatrix}=0+0+100-10=90\overset{sigmoid}{\longrightarrow}1
X1∗Wσ2=[2,−1,1,1]⎣⎢⎢⎡00100−10⎦⎥⎥⎤=0+0+100−10=90⟶sigmoid1
X
1
∗
W
∫
=
[
2
,
−
1
,
1
,
1
]
[
1
0
0
0
]
=
2
X_1*W_{\int}=[2,-1,1,1]\begin{bmatrix} 1\\0\\0\\0 \end{bmatrix}=2
X1∗W∫=[2,−1,1,1]⎣⎢⎢⎡1000⎦⎥⎥⎤=2
X
1
∗
W
σ
3
=
[
2
,
−
1
,
1
,
1
]
[
0
0
−
100
−
10
]
=
0
+
0
−
100
−
10
=
−
110
⟶
s
i
g
m
o
i
d
0
X_1*W_{\sigma3}=[2,-1,1,1]\begin{bmatrix} 0\\0\\-100\\-10 \end{bmatrix}=0+0-100-10=-110\overset{sigmoid}{\longrightarrow}0
X1∗Wσ3=[2,−1,1,1]⎣⎢⎢⎡00−100−10⎦⎥⎥⎤=0+0−100−10=−110⟶sigmoid0
遗忘门
σ
1
\sigma1
σ1关闭,输入门
σ
2
\sigma2
σ2打开,线性层输出为2,输出门
σ
3
\sigma3
σ3关闭,所以最终输出为0,记忆单元更新为2。然后添加到下一个LSTM单元。

s
t
e
p
2
:
X
2
step2:X_2
step2:X2和上一层输出
h
1
h_1
h1作为每个单元的输入,同样地,有如下结果:
X
2
∗
W
σ
1
=
[
3
,
1
,
−
1
,
0
]
[
0
100
0
10
]
=
0
+
100
+
0
+
0
=
100
⟶
s
i
g
m
o
i
d
1
X_2*W_{\sigma1}=[3,1,-1,0]\begin{bmatrix} 0\\100\\0\\10 \end{bmatrix}=0+100+0+0=100\overset{sigmoid}{\longrightarrow}1
X2∗Wσ1=[3,1,−1,0]⎣⎢⎢⎡0100010⎦⎥⎥⎤=0+100+0+0=100⟶sigmoid1
X
2
∗
W
σ
2
=
[
3
,
1
,
−
1
,
0
]
[
0
0
100
−
10
]
=
0
+
0
−
100
+
0
=
−
100
⟶
s
i
g
m
o
i
d
0
X_2*W_{\sigma2}=[3,1,-1,0]\begin{bmatrix} 0\\0\\100\\-10 \end{bmatrix}=0+0-100+0=-100\overset{sigmoid}{\longrightarrow}0
X2∗Wσ2=[3,1,−1,0]⎣⎢⎢⎡00100−10⎦⎥⎥⎤=0+0−100+0=−100⟶sigmoid0
X
2
∗
W
∫
=
[
3
,
1
,
−
1
,
0
]
[
1
0
0
0
]
=
3
X_2*W_{\int}=[3,1,-1,0]\begin{bmatrix} 1\\0\\0\\0 \end{bmatrix}=3
X2∗W∫=[3,1,−1,0]⎣⎢⎢⎡1000⎦⎥⎥⎤=3
X
2
∗
W
σ
3
=
[
3
,
1
,
−
1
,
0
]
[
0
0
−
100
−
10
]
=
0
+
0
+
100
+
0
=
100
⟶
s
i
g
m
o
i
d
1
X_2*W_{\sigma3}=[3,1,-1,0]\begin{bmatrix} 0\\0\\-100\\-10 \end{bmatrix}=0+0+100+0=100\overset{sigmoid}{\longrightarrow}1
X2∗Wσ3=[3,1,−1,0]⎣⎢⎢⎡00−100−10⎦⎥⎥⎤=0+0+100+0=100⟶sigmoid1
遗忘门打开,记忆保留,输入门关闭,记忆单元更新为2+0=2,输出门打开,输出为2。同样,下一层也是如此:

s
t
e
p
3
:
[
X
3
,
h
2
]
=
[
2
,
1
,
1
,
2
]
step3:[X_3,h_2]=[2,1,1,2]
step3:[X3,h2]=[2,1,1,2],简写为
X
3
X_3
X3
X
3
∗
W
σ
1
=
[
2
,
1
,
1
,
2
]
[
0
100
0
10
]
=
0
+
100
+
0
+
20
=
120
⟶
s
i
g
m
o
i
d
1
X_3*W_{\sigma1}=[2,1,1,2]\begin{bmatrix} 0\\100\\0\\10 \end{bmatrix}=0+100+0+20=120\overset{sigmoid}{\longrightarrow}1
X3∗Wσ1=[2,1,1,2]⎣⎢⎢⎡0100010⎦⎥⎥⎤=0+100+0+20=120⟶sigmoid1
X
3
∗
W
σ
2
=
[
2
,
1
,
1
,
2
]
[
0
0
100
−
10
]
=
0
+
0
+
100
−
20
=
80
⟶
s
i
g
m
o
i
d
1
X_3*W_{\sigma2}=[2,1,1,2]\begin{bmatrix} 0\\0\\100\\-10 \end{bmatrix}=0+0+100-20=80\overset{sigmoid}{\longrightarrow}1
X3∗Wσ2=[2,1,1,2]⎣⎢⎢⎡00100−10⎦⎥⎥⎤=0+0+100−20=80⟶sigmoid1
X
3
∗
W
∫
=
[
2
,
1
,
1
,
2
]
[
1
0
0
0
]
=
2
X_3*W_{\int}=[2,1,1,2]\begin{bmatrix} 1\\0\\0\\0 \end{bmatrix}=2
X3∗W∫=[2,1,1,2]⎣⎢⎢⎡1000⎦⎥⎥⎤=2
X
3
∗
W
σ
3
=
[
2
,
1
,
1
,
2
]
[
0
0
−
100
−
10
]
=
0
+
0
−
100
−
20
=
−
120
⟶
s
i
g
m
o
i
d
0
X_3*W_{\sigma3}=[2,1,1,2]\begin{bmatrix} 0\\0\\-100\\-10 \end{bmatrix}=0+0-100-20=-120\overset{sigmoid}{\longrightarrow}0
X3∗Wσ3=[2,1,1,2]⎣⎢⎢⎡00−100−10⎦⎥⎥⎤=0+0−100−20=−120⟶sigmoid0
最终输出为0,记忆单元更新为4。然后是最后一层:

s
t
e
p
4
:
step4:
step4:最后一个序列
[
X
4
,
h
3
]
=
[
1
,
0
,
−
1
,
0
]
[X_4,h_3]=[1,0,-1,0]
[X4,h3]=[1,0,−1,0]
X
4
∗
W
σ
1
=
[
1
,
0
,
−
1
,
0
]
[
0
100
0
10
]
=
0
+
0
+
0
+
0
=
0
⟶
s
i
g
m
o
i
d
0
X_4*W_{\sigma1}=[1,0,-1,0]\begin{bmatrix} 0\\100\\0\\10 \end{bmatrix}=0+0+0+0=0\overset{sigmoid}{\longrightarrow}0
X4∗Wσ1=[1,0,−1,0]⎣⎢⎢⎡0100010⎦⎥⎥⎤=0+0+0+0=0⟶sigmoid0
X
4
∗
W
σ
2
=
[
1
,
0
,
−
1
,
0
]
[
0
0
100
−
10
]
=
0
+
0
−
100
+
0
=
−
100
⟶
s
i
g
m
o
i
d
0
X_4*W_{\sigma2}=[1,0,-1,0]\begin{bmatrix} 0\\0\\100\\-10 \end{bmatrix}=0+0-100+0=-100\overset{sigmoid}{\longrightarrow}0
X4∗Wσ2=[1,0,−1,0]⎣⎢⎢⎡00100−10⎦⎥⎥⎤=0+0−100+0=−100⟶sigmoid0
X
4
∗
W
∫
=
[
1
,
0
,
−
1
,
0
]
[
1
0
0
0
]
=
1
X_4*W_{\int}=[1,0,-1,0]\begin{bmatrix} 1\\0\\0\\0 \end{bmatrix}=1
X4∗W∫=[1,0,−1,0]⎣⎢⎢⎡1000⎦⎥⎥⎤=1
X
4
∗
W
σ
3
=
[
1
,
0
,
−
1
,
0
]
[
0
0
−
100
−
10
]
=
0
+
0
+
100
+
0
=
100
⟶
s
i
g
m
o
i
d
1
X_4*W_{\sigma3}=[1,0,-1,0]\begin{bmatrix} 0\\0\\-100\\-10 \end{bmatrix}=0+0+100+0=100\overset{sigmoid}{\longrightarrow}1
X4∗Wσ3=[1,0,−1,0]⎣⎢⎢⎡00−100−10⎦⎥⎥⎤=0+0+100+0=100⟶sigmoid1
因此,最终的输出序列为
[
0
,
2
,
0
,
0
]
[0,2,0,0]
[0,2,0,0]。
总结
以上就是整个LSTM网络的工作流程,一般采用LSTM是为了处理连续序列,比如命名实体识别,词性标注,句子翻译等等。输入是处理后的词向量或者字向量,输出就是其对应的标签。比如一句话:我叫小明。经过词嵌入后的向量如上所述(假设而已,一般word embedding的维度没有那么低)
我
X
1
:
[
2
,
−
1
,
1
]
叫
X
2
:
[
3
,
1
,
−
1
]
小
X
3
:
[
2
,
1
,
1
]
明
X
4
:
[
1
,
0
,
−
1
]
我\qquad X_1:[2,-1,1]\\ 叫\qquad X_2:[3,1,-1]\\ 小\qquad X_3:[2,\,1,\,1]\\ 明\qquad X_4:[1,0,-1]
我X1:[2,−1,1]叫X2:[3,1,−1]小X3:[2,1,1]明X4:[1,0,−1]
最终经过LSTM输出的标签为
[
0
,
2
,
0
,
0
]
[0,2,0,0]
[0,2,0,0],假设0代表名词,2代表动词,结果如下所示:
我
X
1
:
[
2
,
−
1
,
1
]
⟶
L
S
T
M
0
⟶
名
词
叫
X
2
:
[
3
,
1
,
−
1
]
⟶
L
S
T
M
2
⟶
动
词
小
X
3
:
[
2
,
1
,
1
]
⟶
L
S
T
M
0
⟶
名
词
明
X
4
:
[
1
,
0
,
−
1
]
⟶
L
S
T
M
0
⟶
名
词
我\qquad X_1:[2,-1,1]\overset{LSTM}{\longrightarrow}0{\longrightarrow}名词\\ 叫\qquad X_2:[3,1,-1]\overset{LSTM}{\longrightarrow}2{\longrightarrow}动词\\ 小\qquad X_3:[2,\,1,\,1]\overset{LSTM}{\longrightarrow}0{\longrightarrow}名词\\ 明\qquad X_4:[1,0,-1]\overset{LSTM}{\longrightarrow}0{\longrightarrow}名词
我X1:[2,−1,1]⟶LSTM0⟶名词叫X2:[3,1,−1]⟶LSTM2⟶动词小X3:[2,1,1]⟶LSTM0⟶名词明X4:[1,0,−1]⟶LSTM0⟶名词
那么这就是一个词性标注的过程。一些拙见,欢迎指正~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









