- 手机打开全部评论。
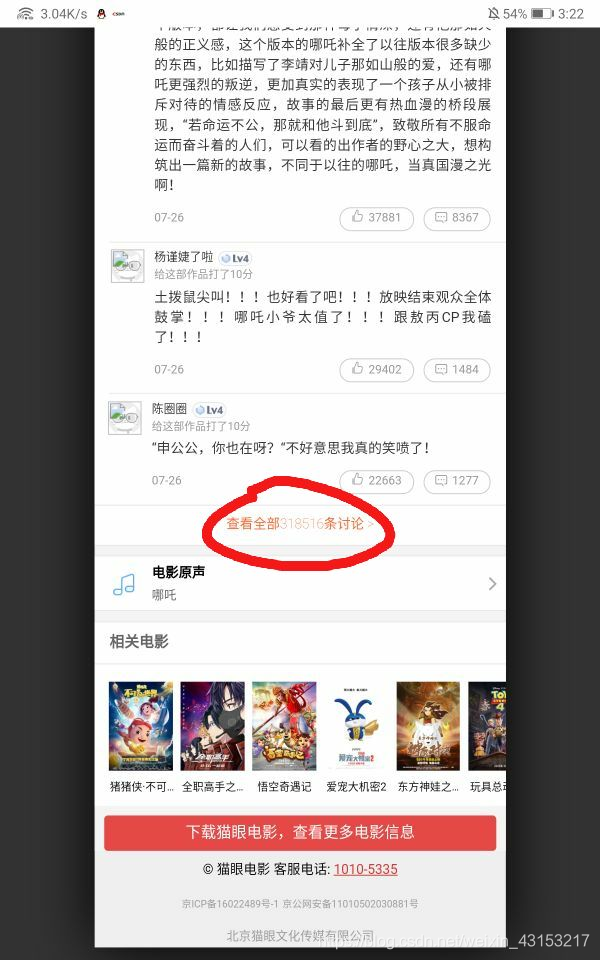
- 复制链接到电脑开发者选项打开。
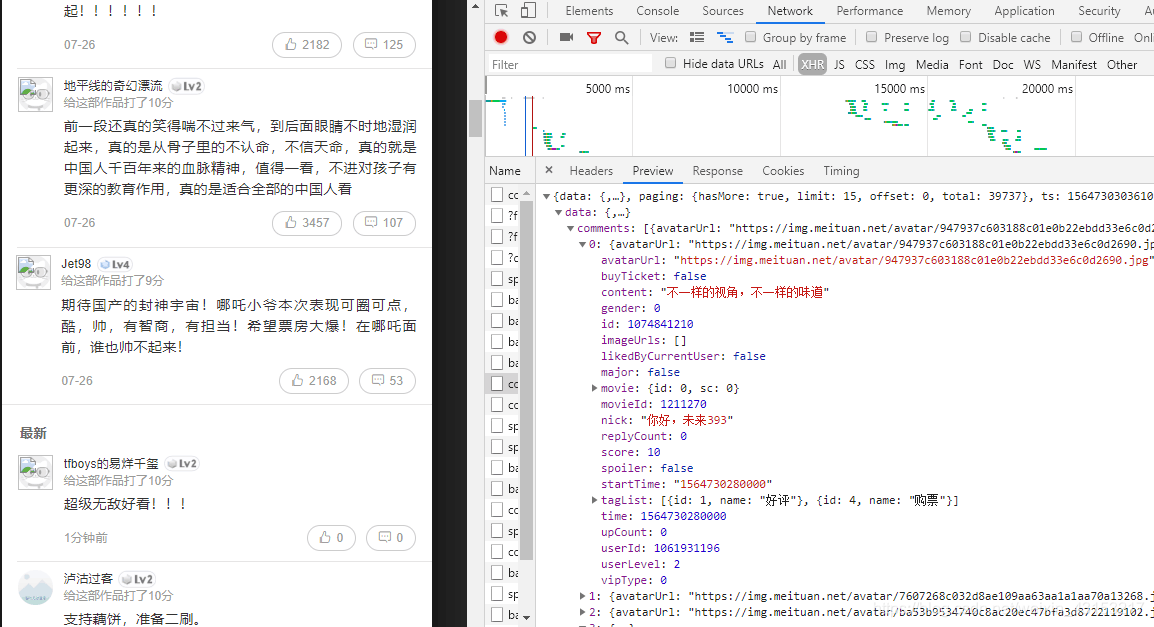
- 评论是动态加载的,向下滑动找到影评json数据。
- Python代码。
import pymongo
import requests
import json
#获取数据库的主机名,端口名和数据库名
host = "主机名"
port = 端口名
dbname = "Comments"
#创建数据库的连接
client = pymongo.MongoClient(host = host, port = port)
#指向指定的数据库
mdb = client[dbname]
#获取数据库里面存放数据的表名
post = mdb["Comment_items"]
def get_response(url):
"""
获取response
:param url: 地址
:return:
"""
User_Agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
headers = {"User-Agent":User_Agent}
response = requests.get(url=url,headers=headers)
if response.status_code == 200:
# print(response.text)
get_single_comments(response.text)
def get_single_comments(text):
"""
获取评论
:param text: response.text
:return:
"""
temp_store = {} #暂时存储一页的评论
# print(json.loads(text))
data = (json.loads(text)).get("data")
# print(data)
comments = data.get('comments')
for comment in comments:
# print(comment)
temp_store["nick"] = comment.get("nick")
temp_store["gender"] = comment.get("gender")
temp_store["score"] = comment.get("score")
temp_store["comments"] = comment.get("content")
temp_store["userLevel"] = comment.get("userLevel")
store.append(temp_store)
temp_store = {}
def store_comments(comment):
"""
保存评论
:param comments: comments
:return:
"""
post.insert(comment) #保存在MongoDB数据库
num = 15 #用来设置offset的值
store = []
for i in range(5):
num *= i+1
url = "http://m.maoyan.com/review/v2/comments.json?movieId=1211270&userId=-1&offset={}&limit=15&ts=1564738457916&type=3".format(num)
get_response(url=url)
num = 15
store_comments(store)
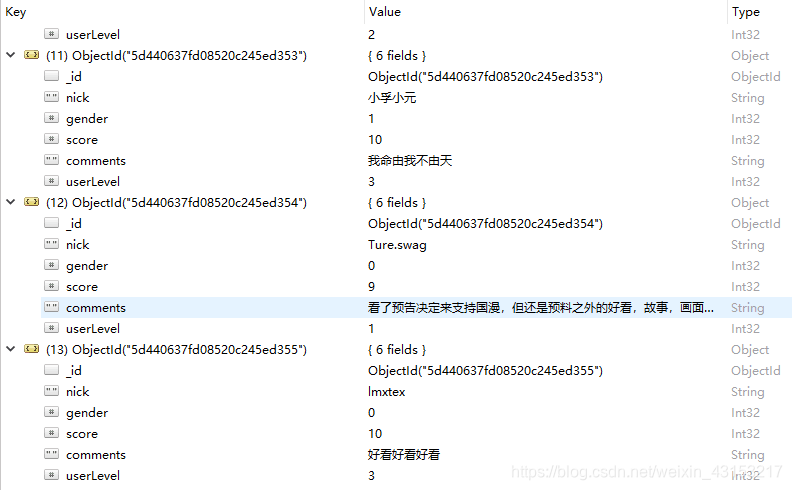
- 爬取效果。
- 简单分析(简单的数据可视化)
- 评分分析:
- 图表:
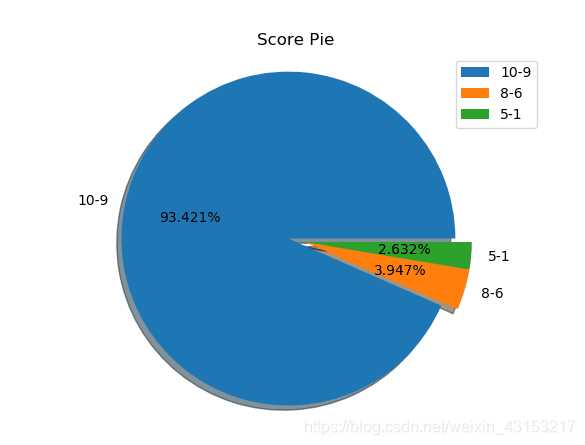
- 图表显示,评分9-10分占绝大多数,说明观众对这部动漫反响是极好的。
- 代码示例:
import pymongo
import matplotlib.pyplot as plt
#连接数据库
client = pymongo.MongoClient(host="localhost",port=27017)
db = client["Comments"]
doc = db["Comment_items"]
#找到全部的评论
data = doc.find()
all_score = []
for item in data:
#获取全部的分数
all_score.append(item["score"])
length = len(all_score)
#三个类别
labels = ["10-9","8-6","5-1"]
label_one = 0
label_two = 0
label_three = 0
sizes = []
for score in all_score:
if score >= 9:
label_one += 1
if score >= 6 and score <= 8:
label_two += 1
if score <= 5:
label_three += 1
sizes.append(label_one/ length)
sizes.append(label_two/ length)
sizes.append(label_three/ length)
plt.pie(sizes, labels=labels, explode=(0.1, 0, 0), shadow=True, autopct="%1.3f%%")
plt.title("Score Pie",loc='center')
plt.axis("equal") #画成圆
plt.legend()
plt.show()
- 性别比例:
- 图表:
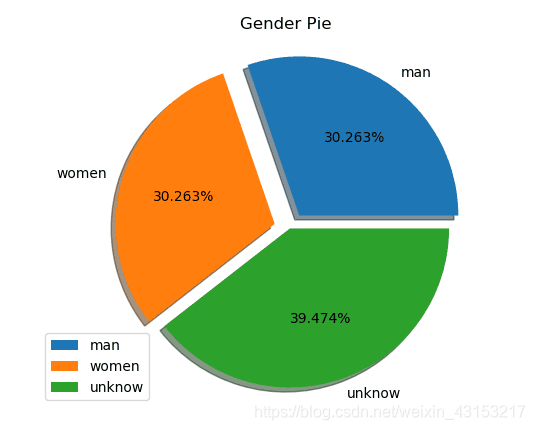
- 男女分配比较均匀,看来哪吒与敖丙这对cp男女通吃呀,哈哈哈。
- 代码示例:
import pymongo
import matplotlib.pyplot as plt
#连接数据库
client = pymongo.MongoClient(host="localhost",port=27017)
db = client["Comments"]
doc = db["Comment_items"]
#查找评论
data = doc.find()
all_gender = []
for item in data:
all_gender.append(item["gender"])
gender_length = len(all_gender)
labels = ["man","women","unknow"]
man = 0
women = 0
unknow = 0
sizes = []
for gender in all_gender:
if gender == 0:
man += 1
if gender == 1:
women += 1
if gender == 2:
unknow += 1
sizes.append(man/gender_length)
sizes.append(women/gender_length)
sizes.append(unknow/gender_length)
plt.pie(sizes,explode=(0.1,0.1,0),labels=labels,autopct="%1.3f%%",shadow=True)
plt.title("Gender Pie",loc="center")
plt.axis("equal")
plt.legend()
plt.show()
- 用户等级:
- 图表:
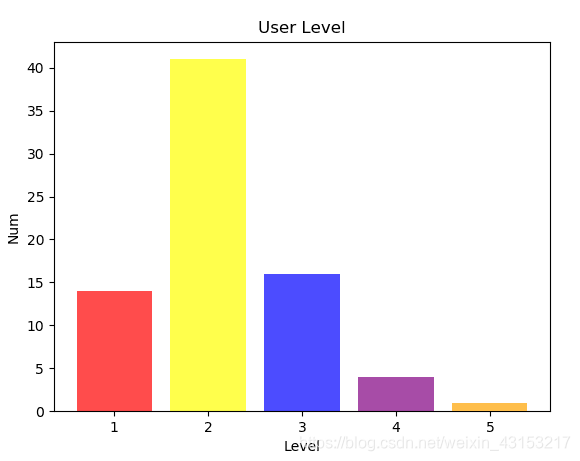
- 用户等级1-3级居多,4-5级较少。
- 代码示例:
import pymongo
import matplotlib.pyplot as plt
#连接数据库
client = pymongo.MongoClient(host="localhost",port=27017)
db = client["Comments"]
doc = db["Comment_items"]
#查询全部的评论
data = doc.find()
all_level = []
for item in data:
all_level.append(item["userLevel"])
level_length = len(all_level)
x = [1,2,3,4,5]
labels = ["1","2","3","4","5"]
sizes = [0,0,0,0,0]
for level in all_level: #对等级分类
sizes[level-1] += 1
plt.bar(x,sizes,alpha=0.7,color=["red","yellow","blue","purple","orange"],tick_label=labels)
#alpha表示透明度
plt.title("User Level")
plt.ylabel("Num")
plt.xlabel("Level")
plt.show()
- 热词展示:
- 图表:
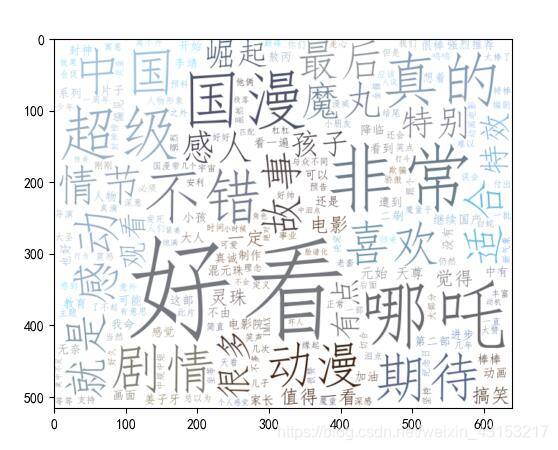
- 从热词图上看出评论极大部分是说这部动漫是好看的,之后是哪吒,不错等等。
- 代码示例:
# -*- coding:utf-8 -*-
import pymongo
import matplotlib.pyplot as plt
import jieba #jieba分词
from wordcloud import WordCloud,ImageColorGenerator
import numpy as np
import cv2 #用来读取图片
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
txt_path = "D:/test.txt" #txt文件位置
font_path = "C:/windows/fonts/simfang.ttf" #字体位置
img_path = "D:/beauty.jpg" #背景图片位置
background_image = np.array(cv2.imread(img_path))
#Click MongoDB database
client = pymongo.MongoClient(host="localhost",port=27017)
db = client["Comments"]
doc = db["Comment_items"]
#Find all data(Cursor)
data = doc.find()
all_comments = []
for item in data:
all_comments.append(item["comments"])
data = open("D:/test.txt","a",encoding="utf-8")
print(all_comments)
for comment in all_comments:
data.write(comment)
data.close()
print("写入完毕!")
t = open(txt_path,"r",encoding="utf-8").read()
cut_text = " ".join(jieba.cut(t))
wordcloud = WordCloud(font_path,mask=background_image,background_color="white").generate(cut_text)
image_color = ImageColorGenerator(background_image)
plt.imshow(wordcloud.recolor(color_func=image_color),interpolation="bilinear")
plt.show()
如果有任何疑问可下方留言给小g

























 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









