







 本文记录了学习Doris的过程,包括其作为实时数据仓库的特性、组件介绍、安装步骤以及遇到的问题和解决方案。Doris是一个基于MPP架构的分布式SQL数据库,适合PB级别的秒级查询。在部署过程中,遇到了IP变化导致的FE重启失败、Doris的连接与使用、各种报错及解决办法,如数据导入问题、元数据更新限制等。此外,文章还讨论了Doris的高可用部署和用户授权。
本文记录了学习Doris的过程,包括其作为实时数据仓库的特性、组件介绍、安装步骤以及遇到的问题和解决方案。Doris是一个基于MPP架构的分布式SQL数据库,适合PB级别的秒级查询。在部署过程中,遇到了IP变化导致的FE重启失败、Doris的连接与使用、各种报错及解决办法,如数据导入问题、元数据更新限制等。此外,文章还讨论了Doris的高可用部署和用户授权。
Doris 学习日常记录
- (记录学习过程和遇到的坑,仅是个人学习使用)
-
- Doris浅略介绍
- DORIS 组成
- 安装Doris步骤
- 由于IP地址变换,导致的 doris FE 重启失败问题
- Doris 连接与可视化使用
- Doris 避坑
- **1.Doris 采用 insert into 表 values 报错一堆:**
- 2.Doris 报错:errCode = 2, detailMessage = Unknown column 'ROUTINE_SCHEMA' in 'ROUTINES'
- 3.配置文件
- FE 配置更改:
- 4.连接
- 5.报错:Dask Dataframe read_parquet: OSError: Couldn't deserialize thrift: TProtocolException: Invalid data
- 6.报错report TASK failed. status: -1, master host:
- 7.开通Doris 用户 并授权只读数据库:
(记录学习过程和遇到的坑,仅是个人学习使用)
怕自己忘记特来记录一下学习Doris 的学习过程和遇到的各种坑。文中图片,文字知识点大多来自网络,如果有不妥之处,请指出,马上修改或是删除;
Doris浅略介绍
关键词:实时数据仓库 ( 之前叫百度 Palo,2018年贡献到 Apache 社区后,更名为 Doris )
身份:基于大规模并行处理技术的分布式 SQL 数据库,百度在 2017 年开源,2018 年 进入 Apache 孵化器。新浪微博,美团,小米都有使用。
定位:
MPP 架构 ( Massively Parallel Processing ),即大规模并行处理。将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果 ( 与 Hadoop 相似 )。每个执行器有单独的CPU,内存和硬盘资源。节点之间的信息交互只能通过节点互联网络实现的,这个过程称为数据重分配。
其优点:MPP架构不用将中间数据写入磁盘,单一的执行器只会处理一个单一的任务,直接将数据stream到下一个执行阶段。这个过程称为流水线技术(时间并行),它提供了很大的性能提升。
也有缺陷:对于MPP架构来说,因为任务和节点的绑定,如果某个执行器执行过慢或故障,会导致整个集群的性能限于这个故障节点的执行速度(就是木桶短板效应)。另集群中的节点越多,则某个节点出现问题的概率越大,而一旦有节点出现问题,对于MPP架构来说,将导致整个集群性能受限,所以一般实际生产中MPP架构的集群节点不易过多。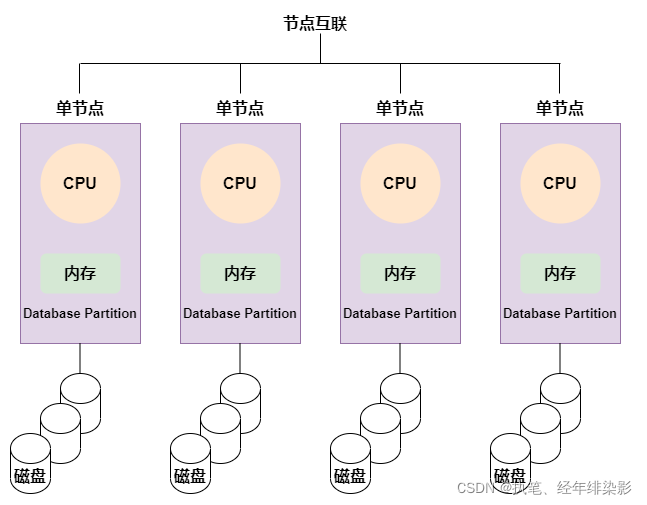
PB (2的50次方)级别大数据集,秒级/毫秒级查询。(如果高于 PB 级别,不推荐使用 Doris 解决,可以考虑用 Hive 等工具),解决结构化数据,查询时间一般在秒级或毫秒级。
doris 优点:
通过扩建集群实现高并发,可扩展200台机器以上;
兼容mysql,不依赖外部存储系统多副本,元数据高可用;
主要用于多维分析和报表查询;
MPP的运行框架,充分挖掘多核CPU的并行计算能力;
分布式架构支持多副本支撑高可用;
采取分区分桶的机制,支持多种索引技术,满足PB级的存储和分析能力;
支持Mysql协作,简单、易用;
列式存储和压缩技术,提升查询性能;
Doris 主要整合了
Google Mesa(取 数据模型): Mesa是 2014年 Google 内部,为解决其在线广告报表和分析业务,拥有准实时的数据更新能力和低延迟的数据查询性能,实现的可扩展的分析型数据仓库系统。**Doris用它来支撑 PB 级别数据上亿次查询和数万亿次数据读取服务,同时提供每秒完成数百万行数据的更新性能。**另外,Mesa能够提供全球复制功能,可以跨多个数据中心备份,并且在低延时提供一致的和可重复的请求响应,即使其中一个整个数据中心挂掉也没问题。
Apache Impala(取 MPP Query Engine): Impala是架构在hadoop上的开源MPP查询引擎,它可以直接访问数据,提供低延迟、高并发以读为主的查询且还支持SQL语法,ODBC驱动。Doris 可以通过Impala,让你可以使用SELECT、DELETE和聚合函数SUM等sql 语句。 impala只需要几秒钟或者分钟级别就能返回数据
Apache ORCFile (取 存储格式,编码和压缩) : ORC 格式在 2013 年 1 月提出,目的是提高 Hadoop Hive 的计算性能和存储效率。做为一种为大规模流式读取而专门设计优化的自描述列存储格式,可以根据不同的列类型选择不同的压缩算法。
DORIS 组成
FrontEnd DorisDB简称 FE:前端节点负责管理元数据、管理客户端的连接、进行查询规划和调度等工作;接收、解析查询请求,规划查询计划,调度查询执行,返回查询结果;执行SQL DDL命令, 用Catalog记录库, 表, 分区, tablet副本等信息。
FE介绍:FE 主要有有三个角色,一个是 leader,一个是 follower,还有一个 observer。leader 跟 follower,主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。follower 节点通过 bdbje(BerkeleyDB Java Edition (opens new window))进行 leader 选举,其中一个 follower 成为 leader 节点,负责元数据的写入操作。当 leader 节点宕机后,其他 follower 节点会重新选举出一个 leader,保证服务的高可用,完成各个 FE 之间数据同步等工作。
observer 节点仅从 leader 节点进行元数据同步,不参与选举。发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加 observer 的节点。observer 不参与任何的写入,只参与读取。
- 管理元数据, 执行SQL DDL命令, 用Catalog记录库, 表, 分区, tablet副本等信息。
- FE高可用部署, 使用复制协议选主和主从同步元数据, 所有的元数据修改操作, 由FE leader节点完成, FE follower节点可执行读操作。 元数据的读写满足顺序一致性。 FE的节点数目采用2n+1, 可容忍n个节点故障。 当FE leader故障时, 从现有的follower节点重新选主, 完成故障切换。
- FE的SQL layer对用户提交的SQL进行解析, 分析, 改写, 语义分析和关系代数优化, 生产逻辑执行计划。
- FE的Planner负责把逻辑计划转化为可分布式执行的物理计划, 分发给一组BE。
- FE监督BE, 管理BE的上下线, 根据BE的存活和健康状态, 维持tablet副本的数量。
- FE协调数据导入, 保证数据导入的一致性。

BackEnd DorisDB简称 BE:后端节点负责数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









