







模型结构图

Deep_Cross解决的问题:
-
离散类特征编码后过于系数,不利于直接输入到神经网路中进行训练
-
如何解决特征交叉组合的问题
-
如何在输出层达成问题设定的优化目标
模型设置
Embedding层:
作用:将类别型特征进行one-hot编码然后进行Embedding,将类别性特正转化为Embedding向量。
每一个特征(Feature1)进行Embedding层后会变成Embedding向量。
数值型特征不需要Embedding层,直接进入Stacking层即可。
Stacking层:
Stacking层可以理解为将Embedding后的类别型特征和直接进入Stacking层的数值型特征进行链接,这一层会包含全部的特征向量。
Multiple Residual Units层:多层残差网络层
这里的结构是MLP层,但是该模型使用了多层残差网络作为MLP的具体实现。
残差网络层的好处:对特征向量的各个维度进行充分的交叉组合,是模型能够抓住更多的非线性组合特征和组合特征的信息。
Scoring层:
预测层
具体的代码实现
思路: Deep_Cross输入的是特征,所以哦们在处理数据的时候就需要降数据集中的特征抽取出来。既然是CTR预估 ,那么我们最后预测出来的结果需要和数据集中的Label进行比较,计算loss和auc
代码如下:
步骤如下:
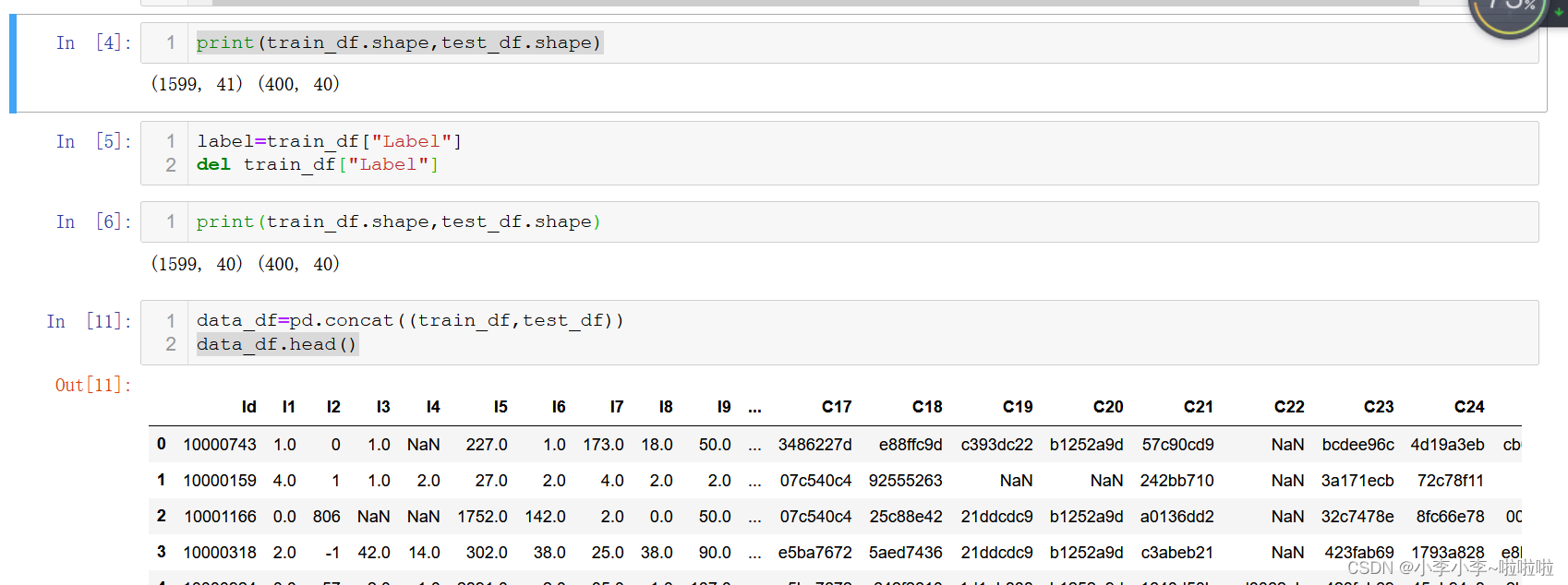
1.将训练集测试集的数据导入
 2. 将Label进行赋值并删除 以便测试集和训练集可以进行拼接
2. 将Label进行赋值并删除 以便测试集和训练集可以进行拼接
 3. 将类别型特征的列表示出来(Sparse_fea)
3. 将类别型特征的列表示出来(Sparse_fea)
同理 将数值型特征进行表示(dense_fea)
4.表示出来后,进行填补缺失值 sparse_fea填充字符-1 数值型特征填补0
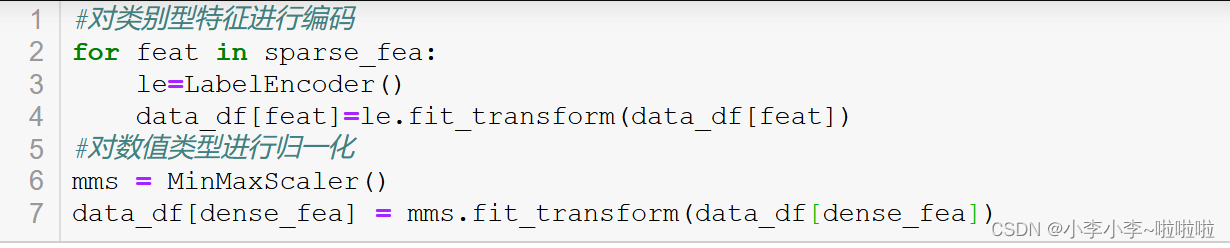
 5.将sparse_fea进行LabelEncoder
5.将sparse_fea进行LabelEncoder
将dense_fea进行归一化MinMaxScaler
 6.将合并数据集中的测试集和训练集进行分开 并在测试集中分测试集和验证集
6.将合并数据集中的测试集和训练集进行分开 并在测试集中分测试集和验证集
 7.保存文件 然后将数据读取
7.保存文件 然后将数据读取
8.定义sparse_map来存放特征key和数量,然后将sparse_fea dense_fea sparse_map进行拼接
 9.最后的步骤将数据封装成TESorDateset 和Dateloader
9.最后的步骤将数据封装成TESorDateset 和Dateloader
 好啦 到这里 我们的数据处理就结束啦 后续的工作是定义模型然后将features_info 传进去 在训练集中进行训练即可
好啦 到这里 我们的数据处理就结束啦 后续的工作是定义模型然后将features_info 传进去 在训练集中进行训练即可
模型的代码
1.因为模型中是使用多层残差网络来作为MLP的实现 所以我们要先定义出该结构
class Residual_block(nn.Module):
def __init__(self,hidden_unit,dim_stack):
super(Residual_block,self).__init__()
self.linear1=nn.Linear(dim_stack,hidden_unit)
self.linear2=nn.Linear(hidden_unit,dim_stack)
self.relu=nn.ReLU()
def forward(self,x):
orig_x=x.clone()
x=self.linear1(x)
x=self.linear2(x)
output=self.relu(x+orig_x)
return output
然后根据每层的定义来定义模型
# 定义deep Crossing 网络
class DeepCrossing(nn.Module):
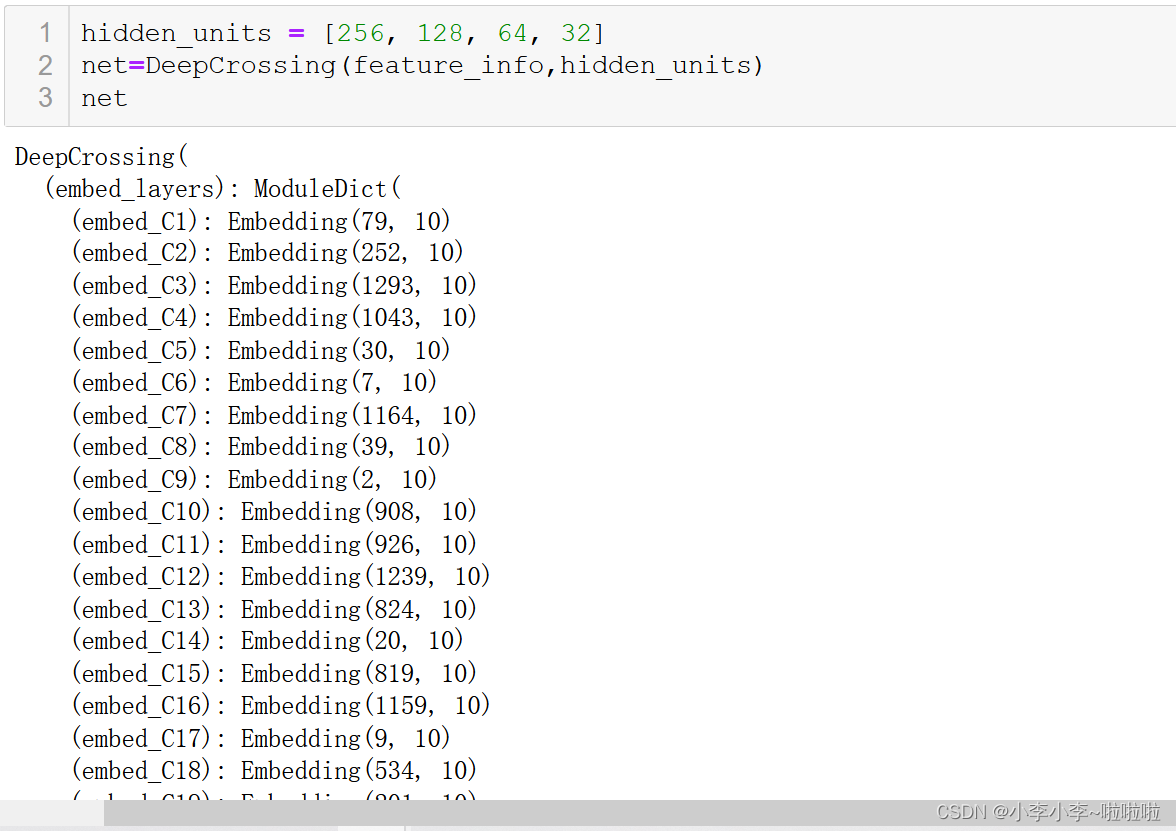
def __init__(self, feature_info, hidden_units, dropout=0., embed_dim=10, output_dim=1):
"""
DeepCrossing:
feature_info: 特征信息(数值特征, 类别特征, 类别特征embedding映射)
hidden_units: 列表, 隐藏单元的个数(多层残差那里的)
dropout: Dropout层的失活比例
embed_dim: embedding维度
"""
super(DeepCrossing, self).__init__()
self.dense_feas, self.sparse_feas, self.sparse_feas_map = feature_info
# embedding层, 这里需要一个列表的形式, 因为每个类别特征都需要embedding
self.embed_layers = nn.ModuleDict({
'embed_' + str(key): nn.Embedding(num_embeddings=val, embedding_dim=embed_dim)
for key, val in self.sparse_feas_map.items()
})
# 统计embedding_dim的总维度
embed_dim_sum = sum([embed_dim]*len(self.sparse_feas))
# stack layers的总维度
dim_stack = len(self.dense_feas) + embed_dim_sum
# 残差层
self.res_layers = nn.ModuleList([
Residual_block(unit, dim_stack) for unit in hidden_units
])
# dropout层
self.res_dropout = nn.Dropout(dropout)
# 线性层
self.linear = nn.Linear(dim_stack, output_dim)
def forward(self, x):
dense_inputs, sparse_inputs = x[:, :13], x[:, 13:]
sparse_inputs = sparse_inputs.long() # 需要转成长张量, 这个是embedding的输入要求格式
sparse_embeds = [self.embed_layers['embed_'+key](sparse_inputs[:, i]) for key, i in zip(self.sparse_feas_map.keys(), range(sparse_inputs.shape[1]))]
sparse_embed = torch.cat(sparse_embeds, axis=-1)
stack = torch.cat([sparse_embed, dense_inputs], axis=-1)
r = stack
for res in self.res_layers:
r = res(r)
r = self.res_dropout(r)
outputs = F.sigmoid(self.linear(r))
outputs = outputs.squeeze(-1)
return outputs
模型定义好后可以先来测试一下
训练
#训练
def auc(y_pred, y_true):
pred = y_pred.data
y = y_true.data
return roc_auc_score(y, pred) # 计算AUC, 但要注意如果y只有一个类别的时候, 会报错
loss_func = nn.BCELoss()
optimizer = torch.optim.Adam(params=net.parameters(), lr=0.001)
metric_func = auc
metric_name = 'auc'
epochs = 4
log_step_freq = 10
dfhistory = pd.DataFrame(columns=["epoch", "loss", metric_name, "val_loss", "val_"+metric_name])
print('Start Training...')
nowtime = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print('========='*8 + "%s" %nowtime)
train_loss=[]
train_auc=[]
test_loss=[]
test_auc=[]
for epoch in range(1, epochs+1):
# 训练阶段
net.train()
loss_sum = 0.0
metric_sum = 0.0
step = 1
total_len=0
for step, (features, labels) in enumerate(dl_train, 1):
# 梯度清零
optimizer.zero_grad()
# 正向传播
predictions = net(features)
loss = loss_func(predictions, labels)
try: # 这里就是如果当前批次里面的y只有一个类别, 跳过去
metric = metric_func(predictions, labels)
except ValueError:
pass
# 反向传播求梯度
loss.backward()
optimizer.step()
# 打印batch级别日志
loss_sum += loss.item()
metric_sum += metric.item()
if step % log_step_freq == 0:
train_loss.append(loss_sum/step)
train_auc.append(metric_sum/step)
print(("训练阶段[step = %d] loss: %.3f, "+metric_name+": %.3f") %
(step, loss_sum/step, metric_sum/step))
# 验证阶段
net.eval()
val_loss_sum = 0.0
val_metric_sum = 0.0
val_step = 1
for val_step, (features, labels) in enumerate(dl_vaild, 1):
with torch.no_grad():
predictions = net(features)
val_loss = loss_func(predictions, labels)
try:
val_metric = metric_func(predictions, labels)
except ValueError:
pass
val_loss_sum += val_loss.item()
val_metric_sum += val_metric.item()
# 记录日志
info = (epoch, loss_sum/step, metric_sum/step, val_loss_sum/val_step, val_metric_sum/val_step)
dfhistory.loc[epoch-1] = info
# 打印epoch级别日志
print(("\nEPOCH = %d, loss = %.3f,"+ metric_name + \
" = %.3f, val_loss = %.3f, "+"val_"+ metric_name+" = %.3f")
%info)
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
print('Finished Training...')
训练结果部分截图
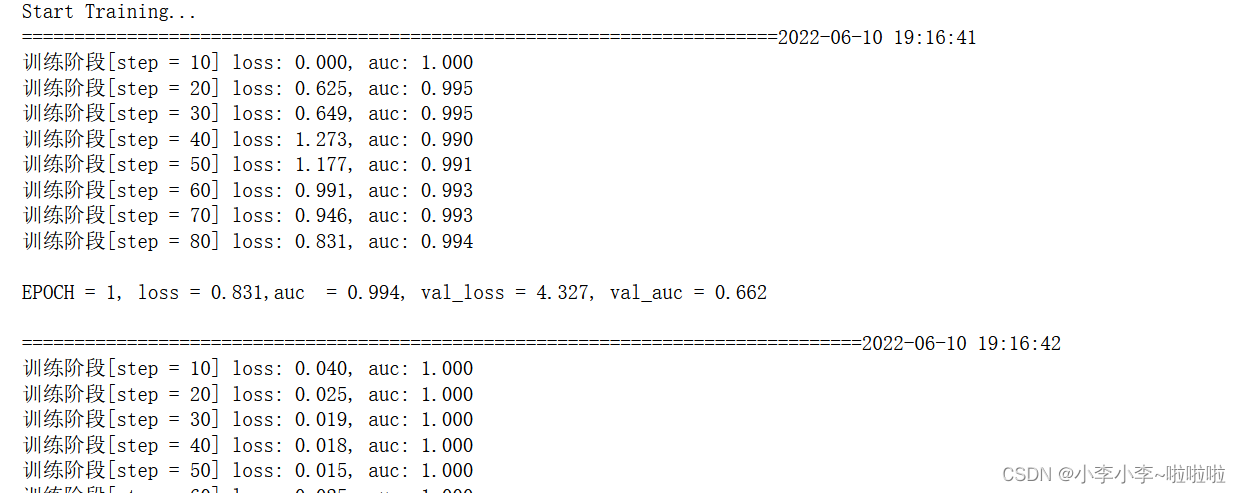
def plot_metric(dfhistory,metric):
train_metrics=dfhistory[metric]
val_metrics = dfhistory['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
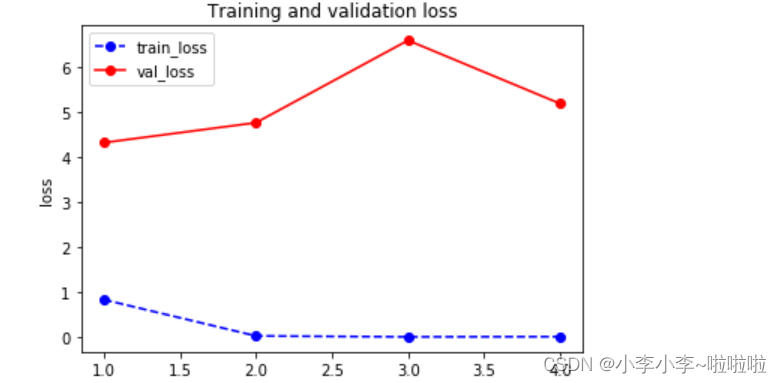
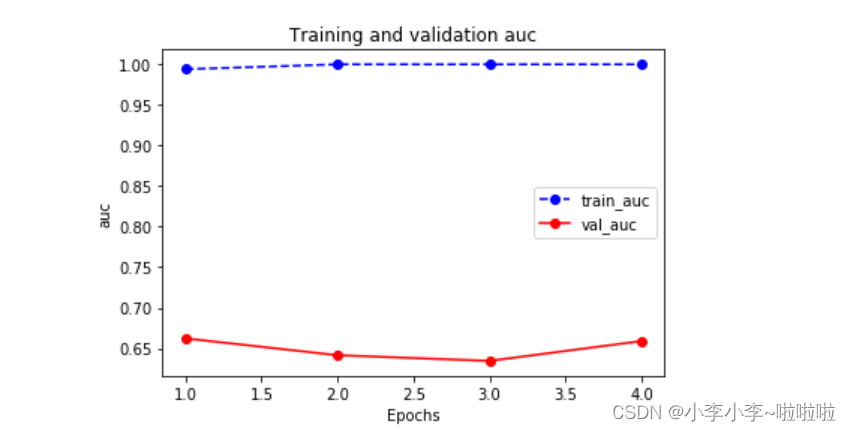
# 观察损失和准确率的变化
plot_metric(dfhistory,"loss")
plot_metric(dfhistory,"auc")
本人小白一枚 如有问题 请联系我 1531281593@qq.com















 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









