







目录
问题描述
测试同事反应出来,线上有个查询速度太慢了,查询要10几秒,不能接受,提了一个优化bug。
前提: T_ATTR_ABLE表180万左右。
代码如下:
select "v0" "FK_IN_ID"
from (select "x"."v0", rownum "rn"
from (select distinct "T_ATTR_ABLE"."FK_IN_ID" "v0"
from "T_ATTR_ABLE"
where ("T_ATTR_ABLE"."DELETE" = '0' and
"T_ATTR_ABLE"."STATE" = 'RUNNING')) "x"
where rownum <= (10 + 10))
where "rn" > 10
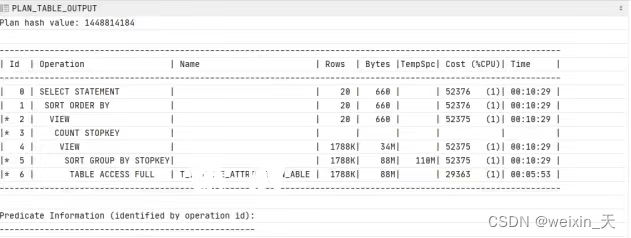
order by "rn";执行计划如下:
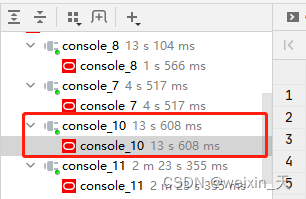
执行时间如下:用了13s 608ms
原因分析:
1 看来看执行计划,发现用distinct这种写法会生成一个很大的临时表,导致查询很慢
2 看见生成的sql 语句发现: 只有两个查询条件,DELETE 数据库只有0、1两种值,STATE 数据库只有三种值,开始尝试给这个这两个加索引,但是测试出来速度没有明显变化,值得种类太少,和全表扫描差不多。
解决方案:
修改一下写法,改成用in 的形式。
代码如下:
select x.PK_ID, x."rn"
from (
select PK_ID, rownum "rn"
from T_INFO_ABLE
where PK_ID in (
select FK_IN_ID
from T_ATTR_ABLE
where DELETE = '0'
and STATE = 'RUNNING'
)
AND rownum <= 20
) x
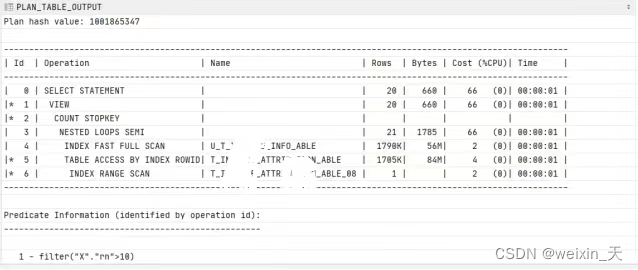
where x."rn" > 10;执行计划如下:
数据量如下:
select count(*) from T_INFO_ABLE; 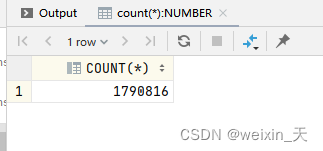
select count(*) from T_ATTR_ABLE;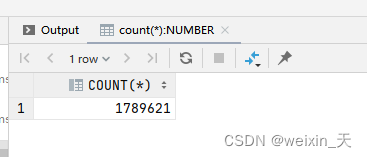
测试结果,执行时间如下:用了104ms
















 2423
2423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











