






 文章深入探讨了ApacheKafka的内部存储机制,特别是日志分段、记录保留策略以及它们如何影响代理服务器性能。讨论了日志段的滚动、索引的工作原理,以及如何根据大小和时间滚动新段。此外,还解释了记录保留时间可能比预期更长的原因,涉及到清理线程、删除延迟等因素。
文章深入探讨了ApacheKafka的内部存储机制,特别是日志分段、记录保留策略以及它们如何影响代理服务器性能。讨论了日志段的滚动、索引的工作原理,以及如何根据大小和时间滚动新段。此外,还解释了记录保留时间可能比预期更长的原因,涉及到清理线程、删除延迟等因素。
深入理解Kafka内部存储机制:段、滚动及老化
Apache Kafka在处理存储记录时表现为提交日志。记录一个接一个地追加到每个日志的末尾,每个日志也被切分成多个段。段有助于删除较旧的记录,提高性能等。因此,日志是由段(文件)组成的记录的逻辑序列,而段存储了记录的子序列。代理服务器配置允许你调整与日志相关的参数。你可以通过配置来控制段的滚动,记录的保留等。
并非所有人都了解这些参数如何影响代理服务器的行为。例如,它们决定了记录被存储和向消费者提供的时间长度。在这篇博客文章中,我们将更深入地探讨当你的日志清理策略设置为删除时,日志分段和记录保留如何影响代理服务器的性能。当你更了解其工作原理时,你可能会想要调整你的日志配置。
当你使用压缩策略而不是删除策略时,日志保留的处理方式会有所不同。Kafka压缩使用键来标识消息,保留特定消息键的最新消息(具有最高偏移量)。具有相同键的早期消息将被丢弃。
磁盘上的主题分区结构
Apache Kafka主题被切分为多个分区,记录被追加到其中。每个分区可以被定义为工作单位,而不是存储单位,因为客户端用它来交换记录。分区进一步被切分为段,这些段是磁盘上的实际文件。分割成多个段可以极大地提高性能。当在磁盘上删除记录或消费者开始从特定偏移量消费时,一个大的、未分段的文件会更慢且更容易出错。
观察磁盘,每个主题分区是一个目录,包含相应的段文件和其他文件。使用Strimzi Canary组件及其生产者和消费者作为示例,下面是一个目录的例子:
├── __strimzi_canary-0
│ ├── 00000000000000000000.index
│ ├── 00000000000000000000.log
│ ├── 00000000000000000000.timeindex
│ ├── 00000000000000000109.index
│ ├── 00000000000000000109.log
│ ├── 00000000000000000109.snapshot
│ ├── 00000000000000000109.timeindex
-
.log文件是一个实际的段,包含到特定偏移量的记录。文件的名称定义了该日志中记录的起始偏移量。
-
.index文件包含一个索引,该索引将逻辑偏移量(实际上是记录的id)映射到.log文件中记录的字节偏移量。它用于在不必扫描整个.log文件的情况下访问日志中指定偏移量的记录。
-
.timeindex文件是另一个用于通过时间戳访问日志中记录的索引。
-
.snapshot文件包含有关用于避免重复记录的序列ID的生产者状态的快照。当新的领导者被选举出来后,leader需要这样一个状态以便再次成为领导者。
这个示例展示了Strimzi Canary组件使用的__strimzi_canary主题的分区0。目录包含以下文件: -
.log文件是一个实际的段,包含到特定偏移量的记录。文件的名称定义了该日志中记录的起始偏移量。
-
.index文件包含一个索引,该索引将逻辑偏移量(实际上是记录的id)映射到.log文件中记录的字节偏移量。它用于在不必扫描整个.log文件的情况下访问日志中指定偏移量的记录。
-
.timeindex文件是另一个用于通过时间戳访问日志中记录的索引。
-
.snapshot快照文件,用于新集群的快速启动(重放)
-
drwxrwxr-x. 2 ppatiern ppatiern 200 Nov 14 16:33 .
drwxrwxr-x. 55 ppatiern ppatiern 1220 Nov 14 16:33 ..
-rw-rw-r--. 1 ppatiern ppatiern 24 Nov 14 16:33 00000000000000000000.index
-rw-rw-r--. 1 ppatiern ppatiern 16314 Nov 14 16:33 00000000000000000000.log
-rw-rw-r--. 1 ppatiern ppatiern 48 Nov 14 16:33 00000000000000000000.timeindex
-rw-rw-r--. 1 ppatiern ppatiern 10485760 Nov 14 16:33 00000000000000000109.index
-rw-rw-r--. 1 ppatiern ppatiern 450 Nov 14 16:33 00000000000000000109.log
-rw-rw-r--. 1 ppatiern ppatiern 10 Nov 14 16:33 00000000000000000109.snapshot
-rw-rw-r--. 1 ppatiern ppatiern 10485756 Nov 14 16:33 00000000000000000109.timeindex
-rw-rw-r--. 1 ppatiern ppatiern 8 Nov 14 16:24 leader-epoch-checkpoint
从输出中,你可以看到第一个日志段00000000000000000000.log包含从偏移量0到偏移量108的记录。第二个段00000000000000000109.log包含从偏移量109开始的记录,被称为活动段(active)。
活动段是唯一一个用于读写操作的文件。它是新进入的记录被追加的段。一个分区只有一个活动段,它是唯一一个用于读写操作的文件。一个分区只有一个活动段。非活动段是只读的,被读取旧记录的消费者访问。当活动段满时,它会被滚动,这意味着它被关闭并以只读模式重新打开。一个新的段文件被创建并以读写模式打开,成为活动段。
从这个例子中,你可以看到当旧的段达到16314字节大小时被关闭。这是因为这个主题配置了segment.bytes=16384,这设置了一个段最大大小。150字节是Canary组件发送的每个单独记录的大小。所以,每个段将包含109个记录。109 * 150字节 = 16350字节,这接近于最大段大小。

你也可以使用Apache Kafka分发提供的DumpLogSegments工具来导出日志段中的记录。运行以下命令可以显示指定段日志内的记录。
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files /tmp/kafka-logs-0/__strimzi_canary-0/00000000000000000000.index
Dumping /tmp/kafka-logs-0/__strimzi_canary-0/00000000000000000000.index
offset: 28 position: 4169
offset: 56 position: 8364
offset: 84 position: 12564
从这个例子中,你可以看到从偏移量0到108的记录都存储在00000000000000000000.log段中。
分区索引是如何工作的
正如之前提到的,.index 文件包含一个索引,该索引将逻辑偏移量映射到 .log 文件中记录的字节偏移量。你可能期望这种映射对每个记录都可用,但它并不是这样工作的。从例子中可以看到,每条消息大小约为150字节。在下面的图表中,你可以看到对于存储在日志文件中的85条条消息,对应的索引只有三条。
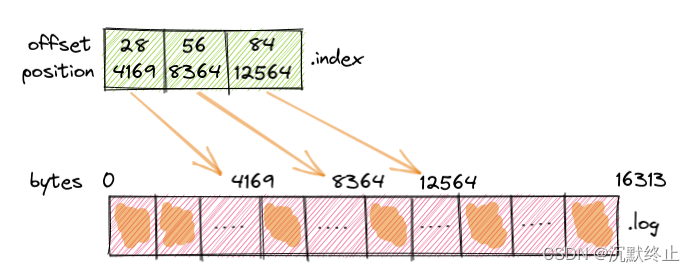
带有偏移量28的记录在日志文件的字节偏移量4169处,偏移量56的记录在字节偏移量8364处,以此类推。通过使用 DumpLogSegments 工具,可以将 .index 文件内容进行转储。
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files /tmp/kafka-logs-0/__strimzi_canary-0/00000000000000000000.index
Dumping /tmp/kafka-logs-0/__strimzi_canary-0/00000000000000000000.index
offset: 28 position: 4169
offset: 56 position: 8364
offset: 84 position: 12564
这就显示了每个索引条目中的逻辑偏移量(或记录ID)和对应的字节偏移量(即在日志文件中的位置)。这样,当需要查找具有特定偏移量的记录时,Kafka 可以首先查看索引文件以确定该记录在日志文件中的大致位置,然后只需要在该位置附近进行扫描,而不是扫描整个日志文件。
如何将这些条目添加到索引文件中是由参数 log.index.interval.bytes 定义的,默认值为 4096 字节。这意味着每在日志文件中添加了 4096 字节的记录,就会在相应的索引文件中添加一个条目。每个条目大小为8字节,4字节用于偏移量,4字节用于段内的字节位置。在这个例子中,我们每添加28条记录就会在索引中添加一个新条目,因为28 * 150 = 4200。
如果一个消费者想从特定的偏移量开始读取,会按照以下步骤搜索记录:
- 根据其名称搜索 .index 文件,该名称遵循与相应的 .log 文件相同的模式。文件中包含了该索引索引的记录的起始偏移量。
- 在 .index 文件中搜索请求偏移量所在的条目。使用对应的字节偏移量访问 .log 文件,并搜索消费者想要开始的偏移量。
- 使用对应的字节偏移量来访问.log文件,并查找消费者希望从哪个偏移量开始。
log.index.interval.bytes 参数可以进行调优,以加快记录的搜索速度,尽管索引文件会变大,反之亦然。如果你将 log.index.interval.bytes 设置为小于默认的 4096 字节,你将在索引中有更多的条目,用于更快速搜索。但更多的条目也会使文件的大小增长得更快。如果你将参数设置为大于默认的 4096 字节,你将在索引中有更少的条目,这将减慢搜索速度。这也意味着文件大小增长的速度也会慢些。(这就是说的时间换空间,也就是索引的意义)
Kafka 还允许你根据时间戳开始消费消息。这就是 .timeindex 文件的作用。.timeindex 文件中的每个条目定义了一个时间戳和偏移量的对,这个对指向相应的 .index 文件条目。
在下图中,你可以看到从时间戳 1638100314372 开始的记录开始于偏移量 28,从 1638100454372 开始的记录开始于偏移量 56,以此类推。
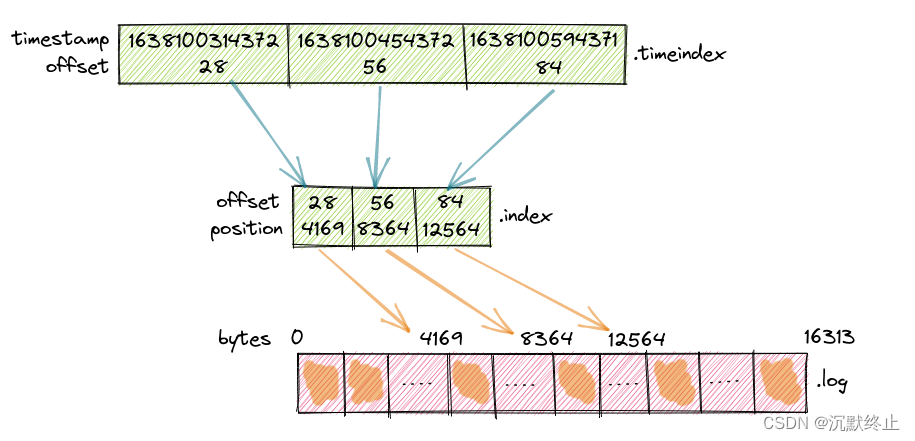
每个条目的大小是12字节,时间戳占8字节,偏移量占4字节。这正好反映了这个topic是如何生成消息的,因为它每5秒发送一条消息。28条消息将在140秒内发送(28 x 5),这正好是时间戳之间的差异:1638100454372 - 1638100314372 = 140000 毫秒。使用 DumpLogSegments 工具,可以将 .timeindex 文件内容导出。
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files /tmp/kafka-logs-0/__strimzi_canary-0/00000000000000000000.timeindex
Dumping /tmp/kafka-logs-0/__strimzi_canary-0/00000000000000000000.timeindex
timestamp: 1638100314372 offset: 28
timestamp: 1638100454372 offset: 56
timestamp: 1638100594371 offset: 84
日志滚动
当满足一些特定条件时,会滚动新的段。一种条件是当达到最大段大小,由配置参数 log.segment.bytes 指定(默认为1 GiB)。另一种条件基于 log.roll.ms 或 log.roll.hours(默认为7天)参数。在这种情况下,当段中第一条记录的生产者时间戳(或创建时间,如果没有时间戳)已经过去的配置时间时,将滚动该段。满足的第一个条件将触发滚动新的段。还值得注意的是,作为不太常见的使用情况,记录中的生产者时间戳可能不是有序的,因此不是将较旧的记录作为第一条,这是由于重试或生产者的特定业务逻辑。(生产乱序到达情况)
另一个有用的参数是 log.roll.jitter.ms,它在滚动段的时间设置一个最大抖动。抖动是时间间隔,用来避免许多段同时滚动,导致磁盘上的高争用。每个段都会随机生成一个抖动。(避免多个段同时老化,磁盘同时io)
上述条件,无论是按大小还是时间,都是众所周知的,但不是每个人都知道还有第三个条件:
当相应的索引(或时间索引)已满时,也会滚动段。
索引和时间索引共享相同的最大大小,由 log.index.size.max.bytes 配置参数定义,默认为10 MB。考虑默认的日志段最大大小,即1 GiB。我们知道,因为 log.index.interval.bytes 默认为4096字节,所以每添加4096字节的记录,在索引中就会添加一个条目。这意味着对于1 GiB的段大小,1 GiB / 4096字节 = 262144条目被添加到索引中。这等于2 MB的索引(262144 * 8字节)。默认的索引大小10 MB足以处理5 GiB的段大小。减小索引大小或增大段大小会导致在索引满时滚动新的段,而不是在达到请求的段大小时。因此,将段大小设置为大于5 GiB而不增加索引大小是无用的,因为当索引满时,broker会滚动新的段。
在增大5 GiB以上的段大小时,你可能还需要增加索引文件的大小。同样,如果你决定减小索引文件大小,可能需要按比例减小段大小。
时间索引可能也需要注意。因为每个时间索引条目比索引中的条目大1.5倍(12字节对比8字节),它可能会更早地填满并导致滚动新的段。
为了展示索引和时间索引文件大小对滚动新日志段的影响,让我们考虑一个集群,其 log.index.interval.bytes=150 和 log.index.size.max.bytes=300
-rw-rw-r--. 1 ppatiern ppatiern 192 Dec 10 16:23 00000000000000000000.index
-rw-rw-r--. 1 ppatiern ppatiern 7314 Dec 10 16:23 00000000000000000000.log
-rw-rw-r--. 1 ppatiern ppatiern 288 Dec 10 16:23 00000000000000000000.timeindex
-rw-rw-r--. 1 ppatiern ppatiern 296 Dec 10 16:23 00000000000000000049.index
-rw-rw-r--. 1 ppatiern ppatiern 4500 Dec 10 16:26 00000000000000000049.log
-rw-rw-r--. 1 ppatiern ppatiern 10 Dec 10 16:23 00000000000000000049.snapshot
-rw-rw-r--. 1 ppatiern ppatiern 300 Dec 10 16:23 00000000000000000049.timeindex
从这个例子中,我们可以看到,当活动的段仍然是7314字节时,新的段就被滚动了,没有达到配置的16384字节。同时,索引达到了192字节的大小,实际上有192 / 8 = 24个条目,而不是预期的37个。原因是因为时间索引首先达到了300字节的限制。它是288字节,包含288 / 12 = 24个条目 - 与相应的索引中的条目数相同。
你可以在broker级别设置这些参数,但它们也可以在主题级别被覆盖。
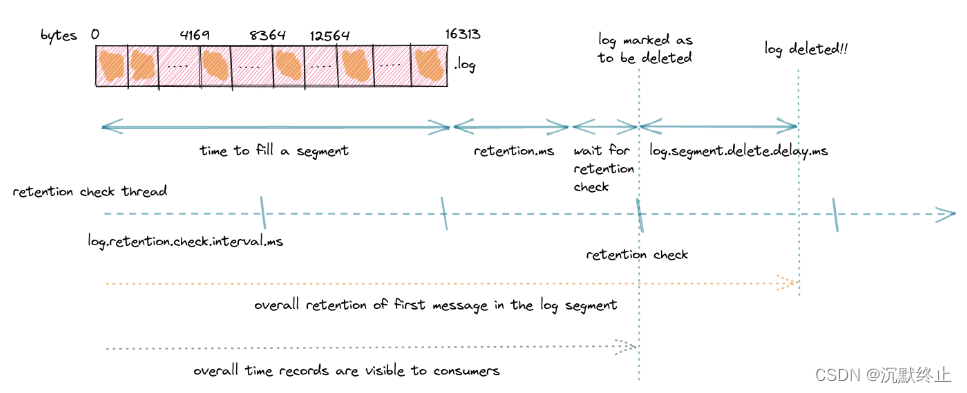
你的消息会保存多久——比你想象的久
在管理你的记录时,一个重要的方面是它们在被删除之前被保留多久。这可以在大小和持续时间方面进行配置。你可以使用log.retention.bytes参数指定要保留的最大字节数。如果你想设定一个保留期,你可以使用log.retention.ms,log.retention.minutes,或log.retention.hours(默认为7天)参数。像控制何时滚动一个段的参数一样,满足的第一个条件将导致从磁盘删除较旧的记录。
这些参数也可以在broker级别设置,并可以在主题级别被覆盖。
假设你通过指定保留时间为600000毫秒(10分钟)和段大小为16384字节来配置一个主题,使用TOPIC_CONFIG环境变量设置为retention.ms=600000;segment.bytes=16384。
对于这种配置,预期的情况是每次当前活动的段达到16384字节大小时,就滚动一个新的段。这可能并不总是发生。如果下一条记录不能存储在活动段中,因为它会超过最大段大小,那么新的段会提前滚动。Canary记录的大小约为150字节,预期每个段可以存储约16384 / 150 = 109条记录,然后才被关闭。假设Canary配置为每5秒生成一条记录,一个段需要109 * 5 = 545秒才能填充。换句话说,每9分钟就会滚动一个新的段。
关于记录保留,预期的是记录保留10分钟后才被删除。但实际上这并不那么简单。在添加一条记录后,我们还能读取它的最小和最大时间是多少?
只有当一个段被关闭时,才能删除它以及它包含的记录。这意味着如果生产者相当慢,并且在10分钟内没有达到16384字节的最大大小,那么旧的记录将不会被删除。因此,保留的时间实际上比预期的要长。
即使活动段很快就填满了,从段关闭之前追加的最后一条记录开始评估保留时间也是如此。最新的记录被保留了我们想要的10分钟,但段中的第一条记录被保留的时间更长。当然,这取决于填充段的速度以及第一条记录和最后一条记录之间经过了多少时间。
在我们的Canary示例中,填充和关闭一个段需要9分钟。当最后一条记录到达时,段中的第一条记录已经有9分钟了。在等待自最后一条记录到达后的10分钟保留期时,第一条记录“应该”在19分钟后被删除。
不过,即使我们认为最后一条记录的保留时间最后被评估,它可能仍然在那里!原因与一个在broker上定期运行以清理记录和检查哪些已关闭的段可以被删除的Apache Kafka线程有关。你可以配置这个线程运行的周期,默认为5分钟,使用log.retention.check.interval.ms参数。根据最后一条记录追加和一个段关闭的时间,定期检查删除可能导致错过保留期的10分钟截止时间。在下一次检查时,可能会延迟近5分钟才删除已关闭的段。
在我们的例子中,段中的第一条记录可能存活近24分钟!
假设某个时候,清理线程运行,并验证一个已关闭的段可以被删除。它给对应的文件添加一个.deleted扩展名,但实际上并没有从文件系统中删除该段。log.segment.delete.delay.ms broker参数定义了当文件被标记为“已删除”时,从文件系统中实际删除它的时间(默认为1分钟)。
-rw-rw-r--. 1 ppatiern ppatiern 192 Dec 10 16:23 00000000000000000000.index
-rw-rw-r--. 1 ppatiern ppatiern 7314 Dec 10 16:23 00000000000000000000.log
-rw-rw-r--. 1 ppatiern ppatiern 288 Dec 10 16:23 00000000000000000000.timeindex
-rw-rw-r--. 1 ppatiern ppatiern 296 Dec 10 16:23 00000000000000000049.index
-rw-rw-r--. 1 ppatiern ppatiern 4500 Dec 10 16:26 00000000000000000049.log
-rw-rw-r--. 1 ppatiern ppatiern 10 Dec 10 16:23 00000000000000000049.snapshot
-rw-rw-r--. 1 ppatiern ppatiern 300 Dec 10 16:23 00000000000000000049.timeindex
回到我们的例子,假设删除的延迟,我们段中的第一条记录在25分钟后仍然存活!这比预期的10分钟要长得多,不是吗?
正如你所看到的,很明显,保留机制并不真正符合初步的预期。实际上,一条记录可能比我们的10分钟还要长,这取决于broker的配置和内部机制。通常通过使用log.retention.ms设置的保留限制定义了一种下限。Kafka保证它不会删除任何年龄小于指定的记录,但任何更早的记录可能会在未来的任何时间被删除,具体取决于设置。
同时,值得提及的是消费者端的影响。消费者从已关闭的段中获取记录,但不从已删除的段中获取,即使它们只是被标记为“已删除”但实际上并没有从文件系统中删除。即使消费者从头开始读取分区,也是如此。较长的保留时间不会直接影响消费者,但会更多地影响磁盘使用。
总结
理解broker如何在磁盘上存储分区和相应的记录是非常重要的。配置参数可能对你的数据保留多长时间有着令人惊讶的大影响。了解这些参数以及你如何调整它们,将使你在处理数据时有更多的控制权。

















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









