







爬虫原理
顺着网络爬取各式各样的数据
分为垂直爬取和横向爬取
横向爬取
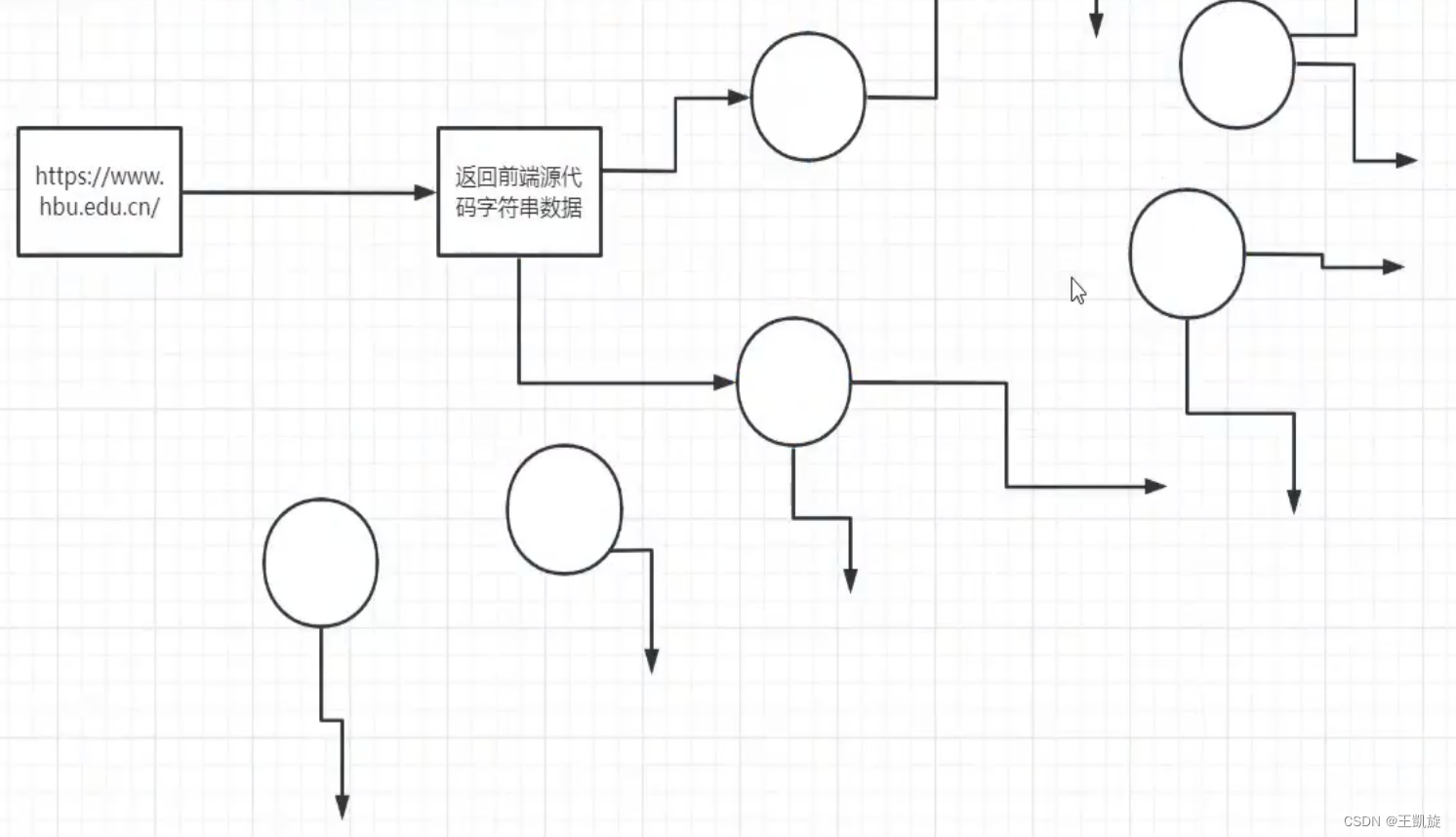
通过一个特定的域名 ---->爬取这个页面的源代码字符串 ---->源代码里会关联别的网站域名 ---->发散式爬取数据 这就是横向爬取(广度搜索)
垂直爬取
也叫定向抓取 特定抓几个网站的数据
通过域名抓取页面的源代码 , 不可以抓取二次请求获取的数据
比如ajax img herf src js css等等请求过来的数据都无法获取
所以想要获得二次请求的数据,我们需要在初次请求时拿到这些请求对应的链接,再次发送请求
一旦发现了src和href ,浏览器会自动再次发送请求
前端页面显示数据要包括从后端ajax请求来的数据
对于浏览器来说 只要返回一个符合格式的字符串就可以显示相应的数据 , 和后端是怎样的文件是无关的 .
垂直爬取时 , 不同的网站可能会有不同的匹配和处理规则
可能会爬取重复的数据 : 爬下来的数据和数据库的要对比 , 如果重复了就需要处理一下 或者是直接不再抓取
防重复的策略 :
每次插入完毕记录每个站点的上次爬取的最新数据时间, 当再次爬取的时候,把每个站点的最新数据从数据库读到内存中,然后新抓取的数据跟内存的这个最新数据做对比 , 看看是这个最新时间之前的还是之后的
避免新爬取的数据和数据库的数据频繁交互 , 故将数据库的最新的临界数据读到内存 , 让新爬取的数据在内存中和临界数据做对比 , 缓解时间开销
DNS
域名解析服务器
浏览器输入一个域名 通过dns解析后 就知道要访问哪个ip了
一个域名可能会对应多个ip :比如我们访问www.baidu.com 在不同的位置,可能会返回不同的ip
我们可以通过ping 域名来访问dns, 然后dns把对应的ip返回给我们, 一般是离我们最近的
ping www.baidu.com
如果可以ping到, 说明我们和这个ip是网络互通的
第一次请求域名才会访问dns , 之后会将域名对应的ip缓存到本地
dns记录了各个域名的访问次数 ; 也叫各个域名的全网访问权重
dns除了可以提供域名之外 , 也可以提供服务器的IP , 用户可以通过IP来访问服务器
但是域名的访问次数要比ip更多 , 因为一个域名可以对应多个ip , 域名的承载量更高
搜索优化
访问量少的域名可以内置百度提供的一段js代码 , 之后我们自己的域名便可主动告诉百度,可以来这里来抓取数据
如果不优化 , 个人网站配置了域名之后 且需要备案, 就可以被抓取(困难 抓取周期长)
HttpClient
基本的HttpClient get请求
public class HttpGetTest {
public static void main(String[] args) {
// 创建浏览器对象
// HttpClients.createDefault() 创建一个httpclient对象 这就相当于打开了浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
// 接收请求地址的对象
// 输入网址,发起get请求,创建HttpGet对象
HttpGet httpGet = new HttpGet("https://www.lagou.com/wn/jobs?kd=Java&city=全国");
// 提升response的作用域 , 为了在finally里关闭
CloseableHttpResponse response = null;
//获取响应
try {
// 发起请求 ,使用httpClient对象发起请求
response = httpClient.execute(httpGet);
//解析响应
// 首先判断响应状态码是否为200
if(response.getStatusLine().getStatusCode() ==200){
// response.getEntity() 是 响应体
// EntityUtils解析响应体数据
String content = EntityUtils.toString(response.getEntity(), "utf8");
System.out.println(content.length());
}
} catch (IOException e) {
e.printStackTrace();
}finally {
//关闭response
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}给get请求加一个参数
//通过URIBuilder来设置参数 1.创建URIBuilder 2.设置参数 3.通过build()方法将参数拼接进去
URIBuilder uriBuilder = new URIBuilder("https://www.lagou.com/wn/jobs");
uriBuilder.setParameter("kd","java");
//多个参数
uriBuilder.setParameter("kd","java").setParameter("city","全国");
// 接收请求地址的对象
// 输入网址,发起get请求,创建HttpGet对象
HttpGet httpGet = new HttpGet(uriBuilder.build());jsoup
jsoup解析并处理字符串
通过FileUtils类将文件解析成字符串 , 存储在content中
Jsoup.parse(content); 解析成dom树
解析文件
parse直接解析文件生成dom树
Document doc = Jsoup.parse(new File("D:/test.html"), "UTF-8");
//也可以解析字符串
String s = httpUtils.doGetHtml("https://www.lagou.com/wn/jobs?kd=Java&city=%E5%8C%97%E4%BA%AC", map);
Document document = Jsoup.parse(s, "utf8");dom操作
获取元素
常规的根据id class不写了
根据属性获取元素
//单纯根据属性来获取元素 Attribute
str = doc.getElementsByAttribute("abc").first().text();
//如果有多个相同的属性,就需要根据属性和属性值一起获取 AttributeValue
str = doc.getElementsByAttributeValue("abc", "123").first().text();获取元素中的数据和值
第一种:常规
Element wkx = document.getElementById("wkx");
//获取id
wkx.id()
//获取class
wkx.className()
//以set集合的形式获取所有的class
Set<String> classNames = wkx.classNames();
//从元素中获取属性的值attr
str = e.attr("abc");
//从元素中获取所有属性attributes
e.attributes()第二种:
选择器语法:doc.select()
// 使用选择器
// tagname: 通过标签查找元素,比如:
a str = doc.select("a").first().text();
// ns|tag: 通过标签在命名空间查找元素,比如:可以用 fb|name 语法来查找 <fb:name> 元素
str = doc.select("jsoup|li").first().text();
// #id: 通过ID查找元素,比如:#logo
str = doc.select("#auto-header-fenzhan").first().text();
// .class: 通过class名称查找元素,比如:.masthead
str = doc.select(".orangelink").first().text();
// [attribute]: 利用属性查找元素,比如:[href]
str = doc.select("[abc]").first().text();
// [attr=value]: 利用属性值来查找元素,比如:[width=500]
str = doc.select("[class=vlli]").first().text();
//利用匹配属性值开头、结尾或包含属性值来查找元素
[attr^=value], [attr$=value], [attr*=value]选择器组合
// 组合选择器
// el#id: 元素+ID,比如: div#logo
str = doc.select("li#auto-header-fenzhan").first().text();
// el.class: 元素+class,比如: div.masthead
str = doc.select("a.greylink").first().text();
// el[attr]: 元素+属性,比如: a[href]
str = doc.select("a[href]").first().attr("href");
// 任意组合,比如:a[href].highlight
str = doc.select("a[href].greylink").first().attr("href");
// ancestor child: 查找某个元素下子元素,比如:可以用.body p 查找"body" 下的所有 p
str = doc.select("div.mini-left a").text();
// parent > child: 查找某个父元素下的直接子元素,比如:div.content > p 查 找p
str = doc.select("div.mini-left ul > li").text();
// parent > * 查找某个父元素下所有直接子元素
Elements elements = doc.select("div.mini-left > *"); for (Element ele : elements) {
System.out.println(ele.tagName());
}封装HttpCilent 为一个HttpUtils类 爬虫的时候可以直接拿来用,很方便 只需修改保存的地址即可
package com.qcby.cast;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.apache.http.util.EntityUtils;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.UUID;
/**
* @author wangkx
*/
public class HttpUtils {
/**
*
* 声明连接池管理器变量cm
*/
private PoolingHttpClientConnectionManager cm;
/**
* 当我们new HttpUtils类时 , 连接池管理器就会被创建
*/
public HttpUtils() {
this.cm = new PoolingHttpClientConnectionManager();
// 设置最大连接数
this.cm.setMaxTotal(100);
// 设计每个主机的最大连接数
this.cm.setDefaultMaxPerRoute(10);
}
/**
* 根据请求地址下载页面数据
* @param url
* @return 页面数据
*/
public String doGetHtml(String url){
// 获取HttpClient对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(this.cm).build();
// 创建HttpGet请求 ,设置url地址
HttpGet httpGet = new HttpGet(url);
httpGet.setConfig(this.getConfig());
CloseableHttpResponse response =null;
try {
// 使用HttpClient发起请求,获取响应
response = httpClient.execute(httpGet);
//解析响应,返回结果
if (response.getStatusLine().getStatusCode() == 200) {
//判断响应体Entity是否不为空,如果不为空就可以使用EntityUtils
if (response.getEntity() != null) {
String content = EntityUtils.toString(response.getEntity(), "utf8");
return content;
}
}
} catch (IOException e) {
e.printStackTrace();
}finally {
// 关闭response
if(response != null){
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
;
}
}
// 只要有问题就返回空串
return "";
}
/**
* 下载图片
* @param url
* @return 图片名称
*/
public String doGetImage(String url){
// 获取HttpClient对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(this.cm).build();
// 创建HttpGet请求 ,设置url地址
HttpGet httpGet = new HttpGet(url);
httpGet.setConfig(this.getConfig());
CloseableHttpResponse response =null;
try {
// 使用HttpClient发起请求,获取响应
response = httpClient.execute(httpGet);
//解析响应,返回结果
if (response.getStatusLine().getStatusCode() == 200) {
//判断响应体Entity是否不为空
if (response.getEntity() != null) {
// 下载图片
// 获取图片的后缀
String extName = url.substring(url.lastIndexOf("."));
// 重命名图片
String picName = UUID.randomUUID().toString() + extName;
// 下载图片
// 声明OutPutStream
OutputStream outputStream = new FileOutputStream(new File("/Users/wangkx/Desktop/chunhan01/web/resourse/img" + picName));
response.getEntity().writeTo(outputStream);
// 返回图片名称
return picName;
}
}
} catch (IOException e) {
e.printStackTrace();
}finally {
// 关闭response
if(response != null){
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
;
}
}
// 下载失败就返回空串
return "";
}
/**
* 设置请求信息
* @return
*/
private RequestConfig getConfig() {
RequestConfig config = RequestConfig.custom()
//创建连接的最长时间
.setConnectTimeout(1000)
// 获取连接的最长时间
.setConnectionRequestTimeout(500)
// 数据传输的最长时间
.setSocketTimeout(10000)
.build();
return config;
}
}















 3203
3203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









