







逻辑回归是一种线性由监督离散型分类模型
决策树是一种非线性有监督离散型分类模型
逻辑回归对于非线性的解决方案:映射到高维
决策树

决策树是一种非线性有监督离散型分类模型
随机森林是一种非线性有监督离散性分类模型
1.决策树
(1)决策树是一个有监督的机器学习算法,做分类用的,而且是非线性的。
(2)决策树的建模过程,不是创造一个方程了,而是构建一棵树。这棵树不一定只是二叉树
(3)损失函数

数据类型
- 离散的数据 需指明取值数量 2^M 种分割方式
天气 : 晴天 雨天 多云
学历: 高中 本科 研究生
- 连续的数据 需离散化, 需指明离散化后的数量
车速:
低速 (60)中速 (80 )高速
M+1种分割方式
决策树是通过固定的条件对类别进行判断

决策树的生成:数据在不断分裂的递归过程,每一次分裂,尽可能让类别一样的数据在树的一边,
当树的叶子节点的数据都是一类的时候,则停止分裂(if lese语句)

数据集:
分割方式一:
分割方式二:
计算纯度的方式:

one-hot划分方式:
决策树通过固定的条件对类别进行判断——非线性离散性数据
纯度越高,决策树越好——>熵大,方差大,基尼系数高。
熵:信息增益
决策树不一定是二叉树
纯度:当应用一个特征,对数据进行分类,如果这个特征能把数据分到一侧,则可说该特征的分类纯度高。
基尼系数,熵越大,方差越大,数据集越不一样,纯度越高
基尼系数是指国际上通用的、用以衡量一个国家或地区居民收入差距的常用指标
若低于0.2表示指数等级极低;(高度平均)
0.2-0.29表示指数等级低;(比较平均)
0.3-0.39表示指数等级中;(相对合理)
0.4-0.59表示指数等级高;(差距较大)
0.6以上表示指数等级极高。(差距悬殊)
一般发达国家的基尼指数在0.24到0.36之间,美国偏高,为0.45。中国国家统计局公布基尼系数2012年为0.474,2013年为0.473,2014年为0.469,2015年为0.462,2016年为0.465
决策树的分割方式:非线性

单棵决策树的缺点:
1.运算两大,需要一次加载所有数据进内存。并且找寻分割条件是一个极耗资源的工作。
2.训练应本中出现异常数据时,将会对决策树产生很大影响。抗干扰能力差
解决方法:
1.减少决策树所需训练样本
2.随机采样,降低异常数据的影响
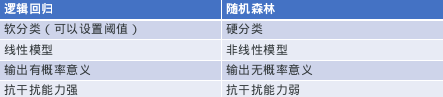
逻辑回归的优点:和逻辑回归比,逻辑回归可以告诉我们概率,二决策树只能0,1
抗干扰能力差举例:

不同深度决策树对比:
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
N = 100
x = np.random.rand(N) * 6 - 3
x.sort()
y = np.sin(x) + np.random.rand(N) * 0.05
# print(y)
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
N = 100
x = np.random.rand(N) * 6 - 3
x.sort()
y = np.sin(x) + np.random.rand(N) * 0.05
# print(y)
x = x.reshape(-1, 1)
# print(x)
dt_reg = DecisionTreeRegressor(criterion='mse', max_depth=3)
dt_reg.fit(x, y)
x_test = np.linspace(-3, 3, 50).reshape(-1, 1)
y_hat = dt_reg.predict(x_test)
x_test = np.linspace(-3, 3, 50).reshape(-1, 1)
y_hat = dt_reg.predict(x_test)
plt.plot(x, y, "y*", label="actual")
plt.plot(x_test, y_hat, "b-", linewidth=2, label="predict")
plt.legend(loc="upper left")
plt.grid()
plt.show()
#################################################
# 比较不同深度的决策树
depth = [2, 4, 6, 8, 10]
color = 'rgbmy'
dt_reg = DecisionTreeRegressor()
plt.plot(x, y, "ko", label="actual")
x_test = np.linspace(-3, 3, 50).reshape(-1, 1)
for d, c in zip(depth, color):
dt_reg.set_params(max_depth=d)
dt_reg.fit(x, y)
y_hat = dt_reg.predict(x_test)
plt.plot(x_test, y_hat, '-', color=c, linewidth=2, label="depth=%d" % d)
plt.legend(loc="upper left")
plt.grid(b=True)
plt.show()
x = x.reshape(-1, 1)
# print(x)
dt_reg = DecisionTreeRegressor(criterion='mse', max_depth=3)
dt_reg.fit(x, y)
x_test = np.linspace(-3, 3, 50).reshape(-1, 1)
y_hat = dt_reg.predict(x_test)
x_test = np.linspace(-3, 3, 50).reshape(-1, 1)
y_hat = dt_reg.predict(x_test)
plt.plot(x, y, "y*", label="actual")
plt.plot(x_test, y_hat, "b-", linewidth=2, label="predict")
plt.legend(loc="upper left")
plt.grid()
plt.show()
#################################################
# 比较不同深度的决策树
depth = [2, 4, 6, 8, 10]
color = 'rgbmy'
dt_reg = DecisionTreeRegressor()
plt.plot(x, y, "ko", label="actual")
x_test = np.linspace(-3, 3, 50).reshape(-1, 1)
for d, c in zip(depth, color):
dt_reg.set_params(max_depth=d)
dt_reg.fit(x, y)
y_hat = dt_reg.predict(x_test)
plt.plot(x_test, y_hat, '-', color=c, linewidth=2, label="depth=%d" % d)
plt.legend(loc="upper left")
plt.grid(b=True)
plt.show()
实验结果展示:

实验分析:黑色的点代表原始数据,我们可以看出,当深度很小的时候,决策树的分类效果相对不好,也就是纯度不高。随着层数的深入,分类效果越发明显。
随机森林
森林:由树组成。
随机:生成树的数据都是从数据集中随机选取的。
随机森林:当数据集很大的时候,我们随机选取数据集的一部分,生成一棵树,重复上述过程,我们可以生成一堆形态各异的数,这些树放在一起就叫森林。
并行思想:因为随机森林中的树都是相互独立的,所以这些树可以在不同的机器上,或者CPU,GPU上运行
这样能极大缩短建模的时间


随机森林和逻辑回归的对比:
剪枝
预剪枝: 在这棵树还没开始分裂的时候,提前设定好一些条件,在达到这些条件以后就不长了
后剪枝:先长,长完了再去掉(比如合并叶子节点)
预剪枝的方式:
(1)控制分裂的层次
(2)控制叶子节点的样本数量
剪枝保证了模型的通用性















 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









