







性能状态关键指标
QPS,Queries Per Second:每秒查询数,一台数据库每秒能够处理的查询次数
TPS,Transactions Per Second:每秒处理事务数
1. 什么是成本?
- I/O成本
表使用的MyISAM、InnoDB存储引擎都是将数据和索引都存储到磁盘上的,当查询表中的记录时,需先把数据或者索引加载到内存中然后再操作。从磁盘到内存这个加载的过程损耗的时间称之为I/O成本。 - CPU成本
读取以及检测记录是否满足搜索条件、对结果集进行排序等操作损耗的时间称之为CPU成本。
2 . 字段优化
- 尽量使用TINYINT、SMALLINT、MEDIUM_INT作为整数类型而非INT。
- VARCHAR的长度只分配真正需要的空间
- 使用枚举或整数代替字符串类型
- 尽量使用TIMESTAMP而非DATETIME
- 单表不要有太多字段,建议在20以内
- 避免使用NULL字段,很难查询优化且占用额外索引空间
- 用整型来存IP
3. order by优化
using filesort:有两种算法:双路排序,单路排序(根据IO次数)
数据库4.1版本之前:默认使用双路排序:扫描两次磁盘
- 从磁盘读取排序字段,在buffer缓冲区进行排序操作
- 扫描其它字段
数据库4.1之后:默认单路排序:一次性读取全部字段,在buffer区挑出排序字段进行排序。
如果数据量很大,无法将数据一次性读取,会分片处理。
如果buffer太小(小于排序的列的总数大小),MySQL会自动由单路—>双路
a. 根据情况选择使用单路、双路;调整buffer大小;
b. 尽量保持排序字段排序的一致性:在group by分组时,默认对分组字段排序,所以在order by中尽量对分组字段排序,避免二次排序。
4. 索引优化
- 索引并不是越多越好,要根据查询有针对性的创建,考虑在WHERE和ORDER BY后涉及的列建立索引,可根据EXPLAIN来查看是否用了索引还是全表扫描
- 应尽量避免在WHERE子句中对字段进行NULL值判断
- 值分布很稀少的字段不适合建索引,例如"性别"这种只有两三个值的字段
- 字符字段只建前缀索引、且最好不要做主键
- 不用外键,由程序保证约束
- 尽量不用UNIQUE,由程序保证约束
- 使用多列索引时注意顺序和查询条件保持一致,同时删除不必要的单列索引
5. 查询SQL优化
- 可通过开启慢查询日志来找出较慢的SQL
- 不做列运算:SELECT id WHERE age + 1 = 10,任何对列的操作都将导致表扫描,查询时要尽可能将操作移至等号右边.
- sql语句尽量简单:一条sql只能在一个cpu运算;大语句拆小语句,一条大sql可堵死整个库。
- OR改写成IN:OR的效率是n级别,IN的效率是log(n)级别,in的个数建议控制在200以内
- 避免%xxx式查询,可以使用索引覆盖挽救一部分
- 使用同类型进行比较,若name类型为varchar, name=123索引失效
- 尽量避免在WHERE子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描
- 列表数据不要拿全表,要使用LIMIT来分页,每页数量也不要太大
注意:在使用 OR 时,可能会导致 索引无法使用。
在为某个索引确定范围区间时,只需要把用不到相关索引的搜索条件替换为TRUE,该条件在回表后才会用到。
SELECT * FROM single_table WHERE key2 > 100 OR common_field = 'abc';
把使用不到idx_key2索引的搜索条件替换为TRUE:
SELECT * FROM single_table WHERE key2 > 100 OR TRUE;
即:SELECT * FROM single_table WHERE TRUE;
强制使用idx_key2执行查询的话,对应的范围区间就是(-∞, +∞),即需要将全部二级索引的记录进行回表,这个代定比全表扫描都大。一个使用到索引的搜索条件和没有使用该索引的搜索条件使用OR连接起来后是无法使用该索引的。
6. SQL性能检测
6.1 explain:见另一篇博客
6.2 慢查询日志:
记录响应时间超过参数long_query_time 设置值并且扫描记录数不小于min_exanined_row_limit 的SQL语句。默认该日志是关闭的。
-
show variables like ‘%slow_query_log%’:检查是否开启了慢查询日志
临时开启:set global slow_query_log = 1; (在内存中开启)
永久开启:/etc/my.cnf 配置 -
查询超过阈值的SQL个数:
show global status like ‘%slow_queries%’ -
查看具体的慢SQL:(通过 mysqldumpslow )设置一些过滤条件,快速查找
s:排序方式
r:逆序
l:锁定时间
g:正则匹配模式
举例如下:按照时间排序,前10条包含left join 查询语句的SQL
mysqldumpslow -s t -t 10 -g “left join” /var/lib/mysql/localhost-slow.log(日志位置)
6.3 全局查询日志:show profiles / show profile: 默认关闭
前序准备:
select @@have_profiling: 查看数据库是否支持
show @@profiling: 查看是否开启
set profiling = 1; 打开,会记录profiling打开之后,所有sql语句所花费的时间。
查询SQL语句执行的耗时:show profiles
7. 主从复制和读写分离
因为数据库大多都是读操作,所以部署一主多从架构,主数据库负责写操作,并做双击热备,多台从数据库做负载均衡,负责读操作。
常通过代理程序实现读写分离,常见代理程序有MySQL Proxy。可大大增加数据库高并发能力,解决单台性能瓶颈问题,数据库横向扩展性也很容易。
8. 缓存池和连接缓存
缓存有本地缓存和分布式缓存,本地缓存是将数据缓存到本地服务器内存中或者文件中。分布式缓存系统redis可以缓存海量数据,扩展性好,性能稳定,速度很快。
InnoDB存储引擎在处理客户端的请求时,当访问某个页的数据时,就会把完整的页的数据全部加载到内存中,即使我们只需要访问一个页的一条记录,那也需要先把整个页的数据加载到内存中。因此我们可以在读写之后把页缓存起来,将来有请求再次访问该页面时,就可以省去磁盘IO的开销。
在MySQL服务器启动的时候向操作系统申请了一片连续的内存,叫做Buffer Pool,并为每一个缓存页都创建了控制信息。把每个页对应的控制信息占用的一块内存称为一个控制块,控制块和缓存页是一一对应的。
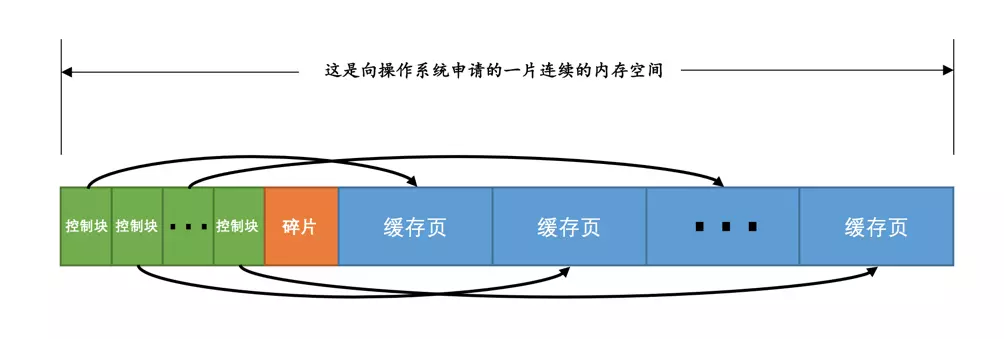
注:在Buffer Pool中被修改的页称为脏页,脏页并不是立即刷新,而是被加入到flush链表中,待之后的某个时刻同步到磁盘上。
join buffer: 关于连接时部分优化
扫描一个表的过程其实是先把这个表从磁盘上加载到内存中,每次访问被驱动表,都会把该表加载到内存,在内存中只会和驱动表的一条记录做匹配,之后从内存中清除掉。即驱动表中有多少条记录,就得把被驱动表从磁盘上加载到内存多少次。
为此,join buffer就是执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个join buffer中,然后开始扫描被驱动表,被驱动表的记录一次性和join buffer中的多条驱动表记录做匹配,显著减少被驱动表的I/O代价。
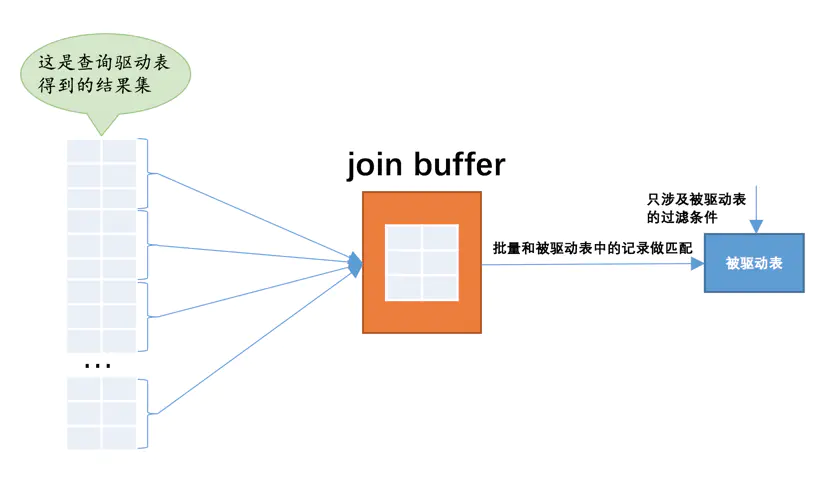
注:驱动表的记录并不是所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中。















 1297
1297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









