






1、解压

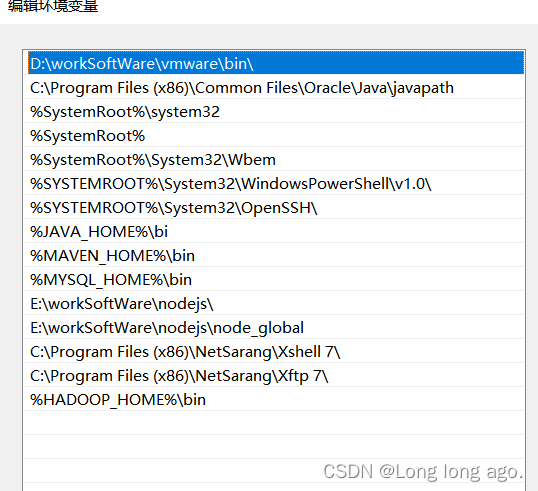
2、配置环境变量
你的解压路径
HADOOP_HOME
F:\学习文件2\Hadoop3.x\apache-hadoop-3.1.0-winutils-master\apache-hadoop-3.1.0-winutils-master

配置path
%HADOOP_HOME%\bin
3、以管理员身份运行你的ide(我的是idea),如果在配置环境变量前已经打开,关闭再重新打开
3.1、pom文件
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
4、编写Mapper
package longer.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* KEYIN, map阶段输入的key类型:LongWritable
* VALUE, map阶段输入balue类型:Text
* KEYOUT,map阶段输出的key类型: Text
* VALUEOUT,map阶段输出的value类型,IntWritable
* */
public class WordCountMapper extends Mapper<LongWritable,Text, Text, IntWritable> {
private Text outT = new Text();
private IntWritable outV=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、获取一行
String line=value.toString();
//2、切割
String[] words=line.split(" ");//
//3、循环写出
for(String word:words){
//封装outK
outT.set(word);
//写出
context.write(outT,outV);
}
}
}
5、编写reduce
package longer.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* KEYIN, reduce阶段输入的key类型:Text
* VALUE, reduce阶段输入balue类型:IntWritable
* KEYOUT,reduce阶段输出的key类型: Text
* VALUEOUT,reduce阶段输出的value类型,IntWritable
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable outV=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
//atguigu(1,1)
// 累加
for(IntWritable value:values){
sum+=value.get();
}
outV.set(sum);
//写出
context.write(key,outV);
}
}
6编写main测试
package longer.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1、获取job
Configuration conf = new Configuration();
Job job= Job.getInstance(conf);
//2、设置jar包途径
job.setJarByClass(WordCountDriver.class);
//3、关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4、设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5、设置最终输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6、设置输入路径和输出路径
FileInputFormat.setInputPaths(job,new Path("D:\\cls.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\hadoop\\output"));
//7、提交job
boolean result=job.waitForCompletion(true);
System.exit(result?0:1);
}
}
运行成功
报错
“org.apache.hadoop.io.nativeio.NativeIOException: 当文件已存在时,无法创建该文件”
可参考
https://blog.csdn.net/weixin_43205308/article/details/129876670
9、MapReduce运行原理
MapReuce数据处理分为split,map,shuffle,reduce
1)split
在执行任务前,把原始数据分割为若干的split,每个split作为map任务的输入,在map执行过程中,split会被分割成一个个记录(键值对)
2)map
对于文本文件,默认为文件里的一行是一条记录
map任务处理每个记录时,都会生成一个新的键值对,在每个map任务生成最终的输出文件前,先回根据键值分区,一边将同一分组的reduce交给同个reduce任务处理。
在有多个reduce任务的情况下,每个map任务会基于分区键生成多个输出文件,此时可以根据需求自己定制partitioner。
在应用程序中最好对map任务的输出文件进行压缩以获得最优的性能。
3)shuffle
Map步骤之后,Reduce步骤之前,还有一个重要步骤叫做Shuffle。系统对map任务的输出执行排序和转换并映射为reduce任务的输入,此过程就是Shuffle。
在Shuffle中,会把map任务输出的一组无规则的数据尽量转换成一组具有一定规则的数据,然后把数据传递给reduce任务运行的节点。
Shuffle横跨Map端和Reduce端,在Map端包括spill过程,在Reduce端包括copy和sort过程。
4)reduce
Reduce步骤负责数据的计算归并,它处理Shuffle后的每个键及其对应值的列表,并将一系列键/值对返回给客户端应用。Reduce对所有中间结果进行归并、聚合,最终生成一个汇总的结果。
概念参考
https://blog.csdn.net/weixin_43409127/article/details/123427628














 4172
4172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









