







准备工作
1、虚拟机Linux系统环境(CentOS)
这里我用的是VMware® Workstation 15 Pro,Linux系统用的是CentOS7,关于虚拟机下安装CentOS7具体步骤可以自行Google。
2、准备jdk环境
在虚拟机下配置jdk环境有很多种方法,这里我是直接在CentOS7系统下载了 jdk-8u221-linux-x64.tar.gz
3、准备Hadoop安装包
和 jdk 安装一样,都是直接在CentOS7系统里直接下载的,这里的版本是 :hadoop-3.2.0.tar.gz
Hadoop伪分布式配置
一、解压 jdk 和 hadoop 到新文件夹 software
首先,在根目录下创建 software 文件夹:
[helloworld@localhost ~]$ mkdir software
把下载好的 jdk 和 hadoop 压缩包移到 software文件夹下。
解压jdk:
[helloworld@localhost ~]$ tar -zxvf jdk-8u221-linux-x64.tar.gz
解压 hadoop :
[helloworld@localhost ~]$ tar -zxvf hadoop-3.2.0.tar.gz

二、配置环境变量
1、 配置 jdk 的环境变量:
打开 /etc/profile 文件夹:
[helloworld@localhost software]$ vim /etc/profile
在文件最后添加下面两行代码:
export JAVA_HOME=/home/helloworld/software/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
保存退出后(这个命令可以自己查),使 /etc/profile 生效:
[helloworld@localhost software]$ source /etc/profile
测试 jdk 环境是否安装成功:
[helloworld@localhost software]$ java -version

出现上述结果即表示 java 安装成功。
2、配置 hadoop 环境变量
在 /home/helloworld/software/hadoop-3.2.0/etc/hadoop/hadoop-env.sh 中添加java环境:
export JAVA_HOME=/home/helloworld/software/jdk1.8.0_221

再次打开 /etc/profile 文件夹:
[helloworld@localhost software]$ vim /etc/profile
在前面的基础上添加以下代码:
export HADOOP_HOME=/home/helloworld/software/hadoop-3.2.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
环境变量都添加完以后的代码如下:

改完环境变量后记得立即生效:
[helloworld@localhost software]$ source /etc/profile
检测环境变量是否设置成功:
[helloworld@localhost software]$ hadoop version

三、修改配置文件
1、修改配置文件 etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>

2、修改配置文件 etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>

3、修改配置文件 etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

这里要说明一下,下面这些多的代码的用处:这是在我运行WordCount实例时遇到的一个错误的解决方法,详细看这个网页:https://blog.csdn.net/weixin_43207025/article/details/100527859。在配置hadoop时可以不急着把这个加上,等遇到问题时再加上也可以。
<property>
<name>mapreduce.application.classpath</name>
<value>/home/helloworld/software/hadoop-3.2.0/share/hadoop/mapreduce/*, /home/helloworld/software/hadoop-3.2.0/share/hadoop/mapreduce/lib/*</value>
</property>
4、修改配置文件 etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

四、格式化NameNode
在 bin 目录下运行 hdfs namenode -format :
[helloworld@localhost bin]$ hdfs namenode -format
五、启动 Hadoop
1、启动 HDFS
[helloworld@localhost hadoop-3.2.0]$ ./sbin/start-dfs.sh
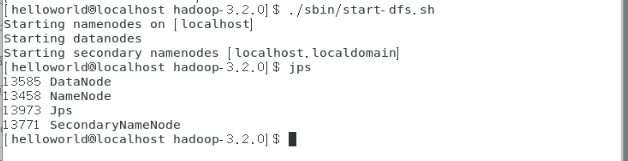
启动 HDFS 后会有三个进程 DataNode、SecondaryNameNode、NameNode
2、启动 yarn
[helloworld@localhost hadoop-3.2.0]$ ./sbin/start-yarn.sh

启动 yar n后会有两个进程NodeManager、ResourceManager
3、也可以直接启动全部进程
[helloworld@localhost hadoop-3.2.0]$ ./sbin/start-all.sh


六、访问网站检测
1、在终端下使用命令 vim /etc/hosts 查看自己的IP:

2、用IP地址 + 9870 端口 访问 http://127.0.0.1:9870/
(hadoop 3.x 的端口由 50070 变为 9870)

3、用IP地址 + 8088 端口 访问:http://127.0.0.1:8088

七、关闭 Hadoop
[helloworld@localhost hadoop-3.2.0]$ ./sbin/stop-all.sh
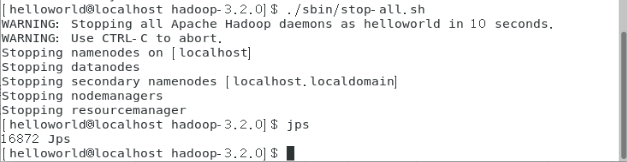
上图表明 hadoop 已经关闭。














 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









