










一、运行环境
windows10
cuda==10.1
python=3.7.x
二、步骤
1、下载SSD代码
SSD-pytorch 代码下载地址: https://github.com/amdegroot/ssd.pytorch
如果觉得下载比较慢可以参考https://blog.csdn.net/weixin_43218120/article/details/108253025
2、准备数据集
(1)想先测试的情况下可以使用VOC或者COCO数据集,数据集下载:
链接:https://pan.baidu.com/s/1roX0TULt2AXoppDQsf5zyQ
提取码:884r
将下载之后的数据集放在(./data/scripts目录下)
在该目录下新建coco文件夹并将./data 目录下的coco_labels.txt文件复制到该目录
具体data目录如下:
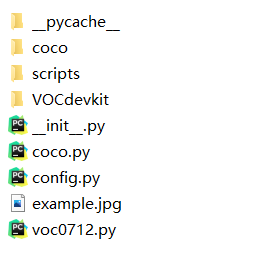
(2)准备自己的数据集
voc数据集的目录如下:
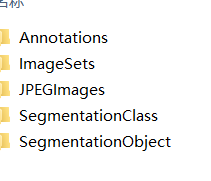
我们只需要对前三个文件夹中的内容进行修改
在Annotations中放置自己使用标记软件标记的xml文件。
在JPEGImages中放置自己的图片。
在ImageStes文件夹中我们只需要对Main文件夹进行修改
文件夹中只放置train.txt/val.txt/test.txt这三个文件。在文件中只要包含文件的名字,不要有后缀名。具体的方式可以参考:https://blog.csdn.net/weixin_43218120/article/details/109329834
3、修改代码
(1)config.py文件
①找到config.py文件,打开修改VOC中的num_classes,根据自己的情况修改:classes+1(背景算一类)
②修改HOME,将该文件的路径修改为自己的文件路径
(2)VOC0712.py
①找到VOC_CLASSES修改为自己的类别,当自己的类别为1的时候(不算背景)需要在()前面加上[]
②注意VOC_ROOT文件路径,不需要修改
(3)train.py
①根据自己的显存修改batch_size,建议一开始修改小一点
②将保存训练模型的参数调低一点,之前iter设置的1000,这里设置为500,之后根据自己情况在设置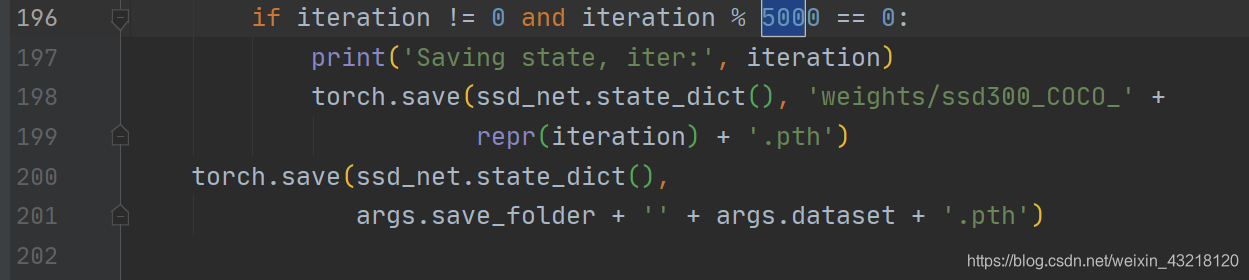
③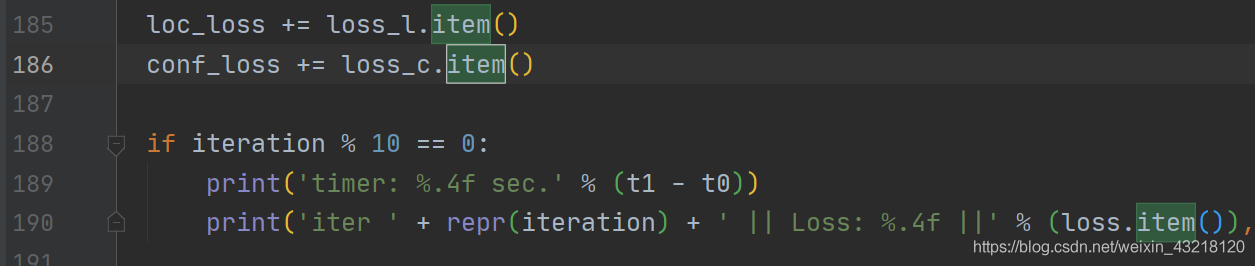
将loss后面修改为.item()否者会报bug
(4)multibox_loss.py
将该文件中的第97行和第98行代码互换一下,否者会报bug
(5)下载预训练模型
链接:https://pan.baidu.com/s/1zriDQ7v_ENvOmXfizNFF2w
提取码:v1r4
4.现在即可进行训练。















09-14
 7684
7684
7684
12-20
6195
6195
07-15
2401
2401
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









